 壁仞科技完成Qwen3旗艦模型適配
壁仞科技完成Qwen3旗艦模型適配
近日,在高效適配Qwen3系列模型推理后,壁仞科技宣布完成旗艦版Qwen3-235B-A22B模型的訓練適配和優化。由此,壁仞科技已實現Qwen3系列模型在國產GPU平臺的高效全棧式訓練與推理支持。
近日,阿里巴巴通義千問正式發布并開源8款新版Qwen3系列“混合推理模型”。從官方披露的數據來看,旗艦模型Qwen3-235B-A22B在代碼、數學、通用能力等基準測試中,與DeepSeek-R1等頂級模型相比,表現出極具競爭力的結果。
壁仞科技在Qwen3發布后數小時內完成了全系列模型的推理支持。受益于前期適配DeepSeek-V3滿血版訓練的關鍵技術和成功經驗,壁仞科技進一步升級快速實現Qwen3-235B-A22B旗艦版最大參數量模型的訓練適配與優化支持。基于壁仞科技自研Megatron-LM-BR訓練插件,用戶可實現大模型零代碼修改下無縫運行,開箱即用。
值得關注的是,Megatron-LM-BR融合了壁仞科技自主知識產權的三大核心技術:虛擬層+動態重排、Async Offload、多維算子融合,實現了適配通用性與訓練性能的雙重保障。
01業界首創"虛擬層+動態重排"技術
顯著降低流水線氣泡
阿里開源的Pai-Megatron-Patch發布了Qwen3 MoE 模型的最佳實踐,但Qwen3-235B-A22B模型包含94個Transformer Layer,其默認的策略如PP8無法均衡切分Layer導致無法使用Interleave with Virtual Pipeline高效流水線機制,因此造成流水線等待問題。壁仞科技基于Megatron-LM-BR自主研發了"虛擬層+動態重排"技術:通過插入兩個虛擬層將總層數擴展至96層,實現均勻切分以支持Interleave with Virtual Pipeline機制;同時對部分Layer進行動態重排,使流水線計算通信負載均衡,從而顯著降低流水線氣泡率。
02業界首創Async Offload技術
實現精度無損極速預訓練
為發揮算力優勢和提升顯存效率,壁仞科技自主研發Async Offload(異步卸載)機制:將大量激活張量和優化器狀態異步遷移至CPU內存,僅使用64張GPU卡即可支持Qwen3-235B-A22B精度無損的全參模型高效預訓練;而業界其他已發布案例至少需要256卡,另外其他方案如FP8可以降低顯存消耗,但容易對精度產生影響。壁仞科技同時還支持智能重計算策略,動態識別顯存瓶頸層,實現"算力換空間"智能決策。通過Async Offload和重計算顯存優化雙擎技術,壁仞科技實現了算力開銷和顯存節約的最佳均衡。
03融合算子多維加速體系
充分釋放算力潛能
針對GroupedMLP、Permutation、Unpermutation等關鍵耗時算子,壁仞科技基于其GPU架構特點實現了泛化的圖算/通算融合優化。支持多計算操作極致的片上融合、張量處理器與矢量處理器極致異步融合、多級緩存的流水融合、以及計算與通信融合,并進一步引入自動化的Kernel Selection技術,基于硬件計算/通信/訪存建模的Cost Model針對不同工作負載自適應選擇最優內核實現,將芯片綜合能效發揮到極致,同時也確保了通用的泛化能力。在保持精度無損的同時,達成計算效率、硬件利用率與內存帶寬的多維度協同優化。
-
gpu
+關注
關注
28文章
4910瀏覽量
130660 -
模型
+關注
關注
1文章
3486瀏覽量
49992 -
壁仞科技
+關注
關注
1文章
67瀏覽量
3067 -
DeepSeek
+關注
關注
1文章
773瀏覽量
1340
原文標題:憑借三大核心技術,壁仞科技完成Qwen3旗艦模型訓練適配與優化
文章出處:【微信號:Birentech,微信公眾號:壁仞科技Birentech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Arm CPU適配通義千問Qwen3系列模型
Intel OpenVINO? Day0 實現阿里通義 Qwen3 快速部署
NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告
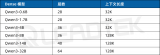
NVIDIA使用Qwen3系列模型的最佳實踐

MediaTek天璣9400率先完成阿里Qwen3模型部署
后摩智能NPU適配通義千問Qwen3系列模型
摩爾線程GPU率先支持Qwen3全系列模型
在openEuler上基于vLLM Ascend部署Qwen3
中科曙光DeepAI深算智能引擎全面支持Qwen3
幾B都有!BM1684X一鍵適配全系列Qwen3

上新:小米首個推理大模型開源 馬斯克:下周推出Grok 3.5
壁仞科技完成阿里巴巴通義千問Qwen3全系列模型支持
壁仞科技推出阿里QWQ-32B大模型一體機






 工商網監
工商網監
評論