") NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告
NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告
近日,阿里巴巴通義千問團隊正式推出新一代開源大語言模型——Qwen3 系列,該系列包含 6 款 Dense 稠密模型和 2 款 MoE 混合專家模型,參數規(guī)模覆蓋 0.6B 至 235B,構建了覆蓋全場景的 AI 模型矩陣。其中旗艦模型 Qwen3-235B-A22B 在代碼、數學及通用能力基準測試中,展現出與 DeepSeek-R1、OpenAI-o1、Grok-3、Gemini-2.5-Pro 等頂級模型比肩的實力。
而對于Qwen3-30B-A3B,其激活量只有 QwQ-32B 的 10%,表現超過 DeepSeek V3/GPT-4o。就中小型企業(yè)的定制化需求而已,從部署成本角度看,Qwen3-30B-A3B 相較于先前熱門 Deepseek-R1-70B(BF16),部署成本降低約 40%,其模型性能表現接近 Qwen2.5-72B 級別的性能。使得中小企業(yè)在有限預算下即可實現高水準的 AI 應用定制,進一步降低了技術落地門檻。
Qwen3 集合 6 款 Dense 稠密模型:從適用于輕量級任務的 Qwen3-0.6B、1.7B,到應對中大型復雜場景的 4B、8B、14B,再到超大規(guī)模算力需求的 32B,以及 2 款 MoE 模型 Qwen3-30B-A3B、Qwen3-235B-A22B,形成豐富完備的模型體系,全方位滿足不同層次、不同類型的應用需求。
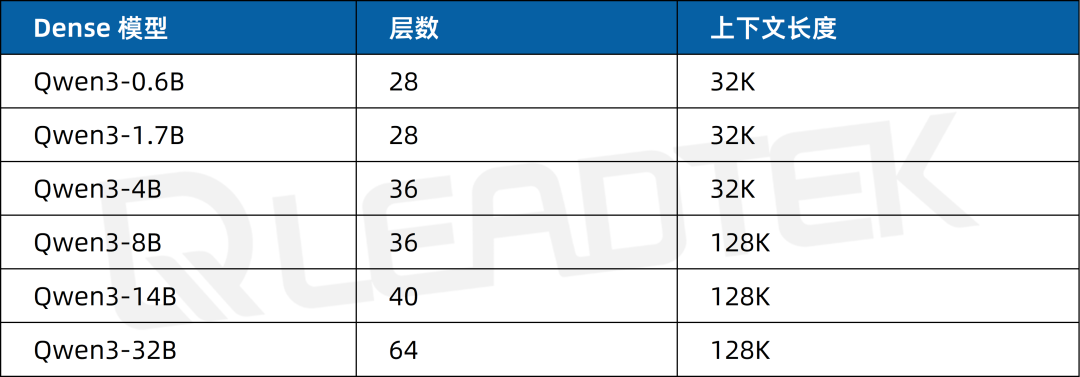

▲ Qwen3 系列模型一覽
1 Qwen3 技術突破與核心優(yōu)勢
作為實現"雙模推理"的開源模型,Qwen3 創(chuàng)新性融合了深度思考與快速響應機制:混合推理模型,具備思考和快速回答雙模式。
思考模式:模型通過多步推理和深度分析以解決復雜問題,類似人類理性決策過程。這種模式適用于需要深入思考的復雜問題。
快速回答(非思考模式):模型提供快速、近乎即時的響應,直接基于已有的知識和簡單的邏輯關系生成答案,而不會進行深入的多步推理。這種模式適用于那些對速度要求高于深度的簡單問題。
簡單來說,類似于將 DeepSeek-R1 和 V3 揉在一起。既可以當沒有思維鏈的普通模型,又可以開啟深度思考模式變成推理模型。用戶可以通過設置enable_thinking參數來實現兩種模式的切換。
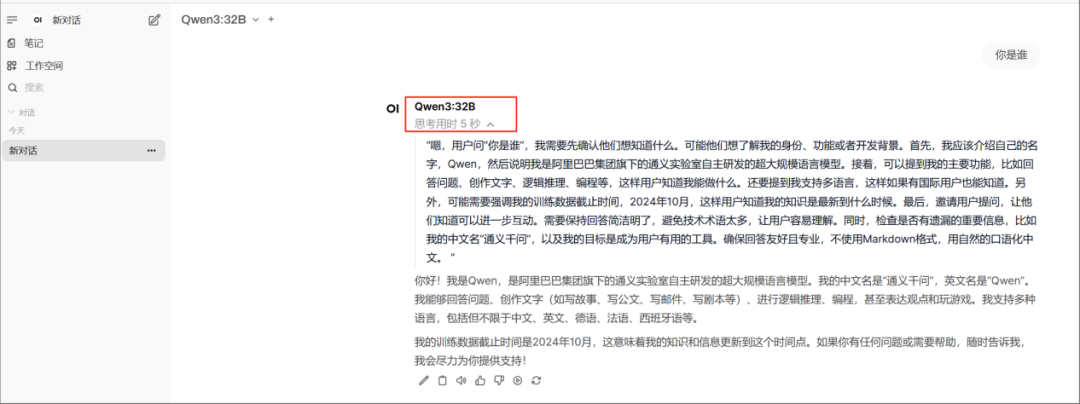
▲ Qwen3 思考模式

▲ Qwen3 快速回答
此外,Qwen3 還具備以下優(yōu)勢:
模型能力躋身全球 top。
MoE 和 Dense 兩種架構共 8 款模型,基本覆蓋所有應用場景。
Agent 能力升級:優(yōu)化了 Qwen3 模型的 Agent 和代碼能力,同時支持最新的 MCP(模型上下文協議)。
支持 119 種語言。
海量訓練數據:Qwen3 使用的數據量達到了約 36 萬億個 token。
Qwen3 系列通過"小而強大"的技術突破(如 30B 模型超越 72B 前輩),為中小企業(yè)提供高性價比 AI 解決方案。其 Apache2.0 開源協議和免費商用特性,能夠配合 AI 一體機基礎設施支持,推動 AI 應用進入"平民化"時代。隨著混合推理模式的普及,Qwen3 或將重新定義大模型在智能客服、代碼開發(fā)、科研創(chuàng)新等領域的應用范式。
2 2/4 卡 RTX 5880 Ada 實測報告
2.1 測試環(huán)境
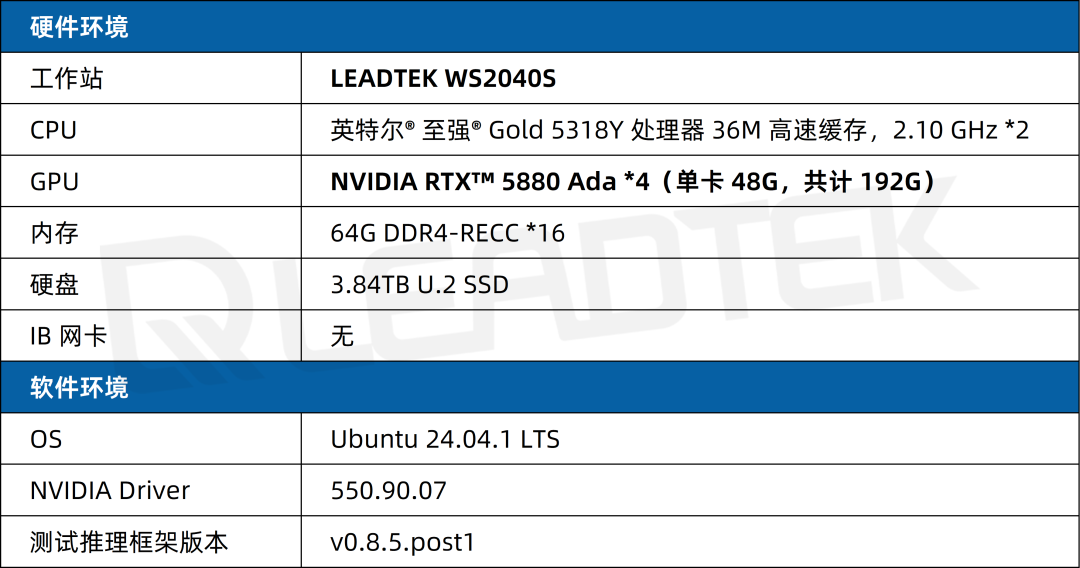
2.2 測試指標
首次 token 生成時間(Time to First Token, TTFT(s))越低,模型響應速度越快;每個輸出 token 的生成時間(Time Per Output Token, TPOT(s))越低,模型生成文本的速度越快。
輸出 Token 吞吐量(Output Token Per Sec, TPS):反映系統每秒能夠生成的輸出 token 數量,是評估系統響應速度的關鍵指標。多并發(fā)情況下,使用單個請求的平均吞吐量作為參考指標。
首次 Token 生成時間(Time to First Token, TTFT(s)):指從發(fā)出請求到接收到第一個輸出 token 所需的時間,這對實時交互要求較高的應用尤為重要。多并發(fā)情況下,平均首次 token 時間 (s) 作為參考指標。
單 Token 生成時間(Time Per Output Token,TPOT(s)):系統生成每個輸出 token 所需的時間,直接影響了整個請求的完成速度。多并發(fā)情況下,使用平均每個輸出 token 的時間 (s) 作為參考指標。這里多并發(fā)時跟單個請求的 TPOT 不一樣,多并發(fā) TPOT 計算不包括生成第一個 token 的時間。
并發(fā)數(Concurrency):指的是系統同時處理的任務數量。適當的并發(fā)設置可以在保證響應速度的同時最大化資源利用率,但過高的并發(fā)數可能導致請求打包過多,從而增加單個請求的處理時間,影響用戶體驗。
2.3 測試場景
在實際業(yè)務部署中,輸入/輸出 token 的數量直接影響服務性能與資源利用率。本次測試針對兩種不同應用場景設計了具體的輸入 token 和輸出 token 配置,以評估模型在不同任務中的表現。具體如下:

2.4 測試結果
4 卡 NVIDIA RTX 5880 Ada 測試
文本生成場景測試中,單請求吞吐量約39.07tokens/s,并發(fā) 200 時降至約10.59tokens/s。
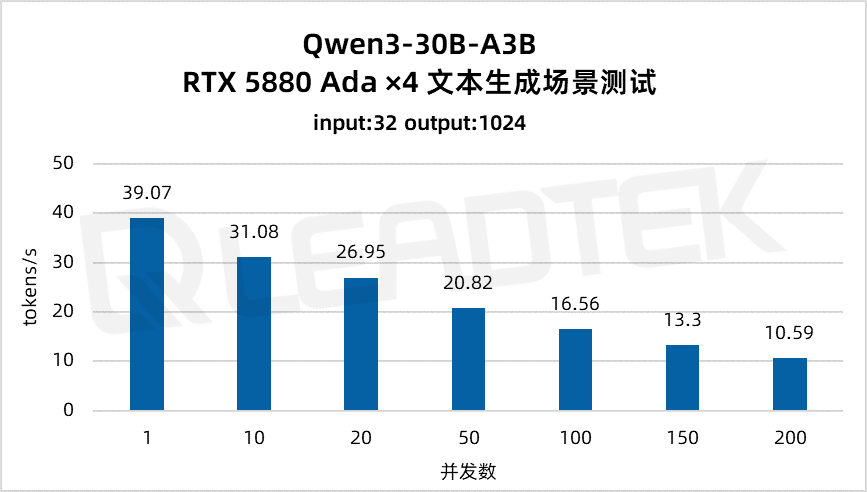
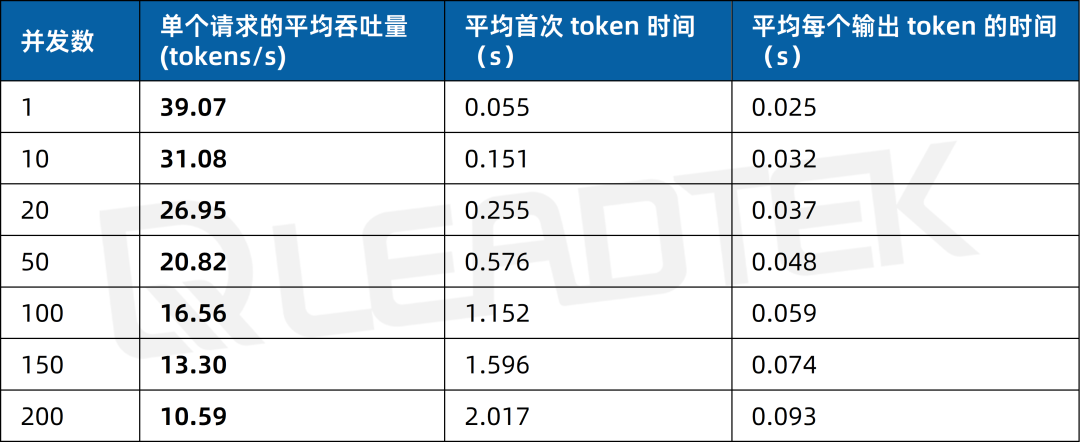
▲ 4 卡 RTX 5880 Ada 文本生成場景測試結果圖表
2025 麗臺(上海)信息科技有限公司
本文所有測試結果均由麗臺科技實測得出,如果您有任何疑問或需要使用此測試結果,請聯系麗臺科技(下同)
文本總結場景測試中,單請求吞吐量約38.35tokens/s,并發(fā) 150 時降至約10.78tokens/s。
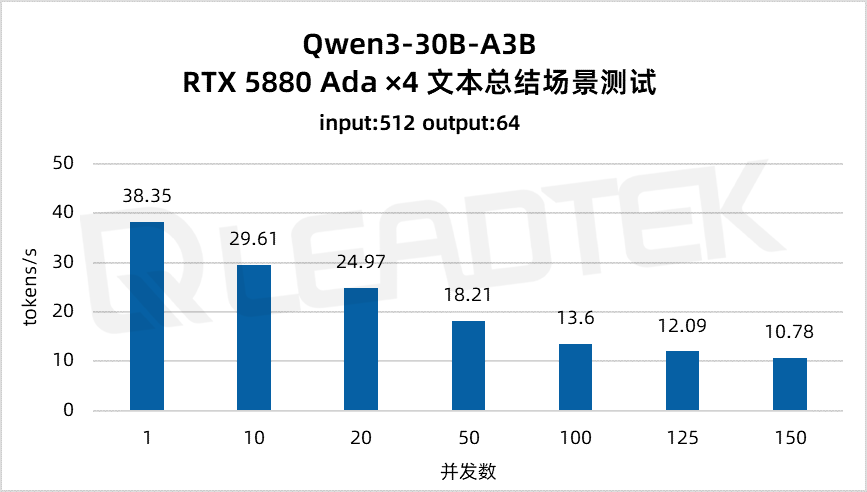
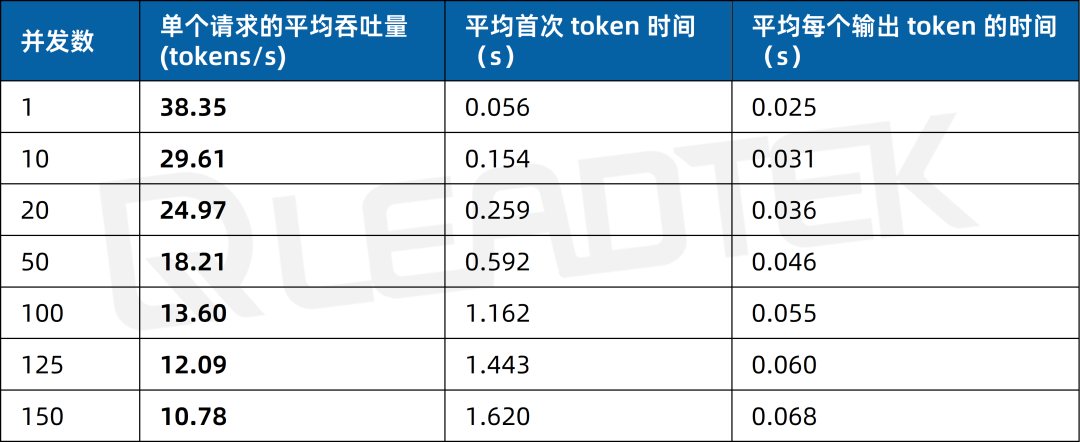
▲ 4 卡 RTX 5880 Ada 文本總結場景測試結果圖表
2 卡 NVIDIA RTX 5880 Ada 測試
文本生成場景測試中,單請求吞吐量約25.14tokens/s,并發(fā) 150 時降至約9.24tokens/s。
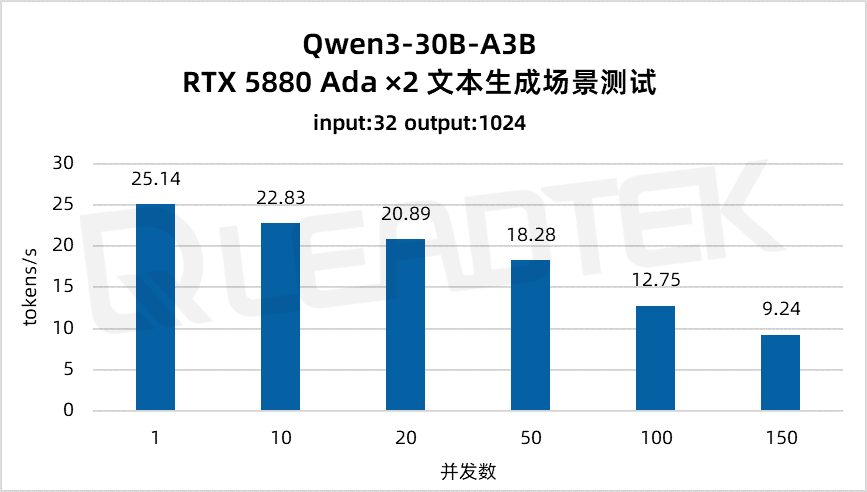
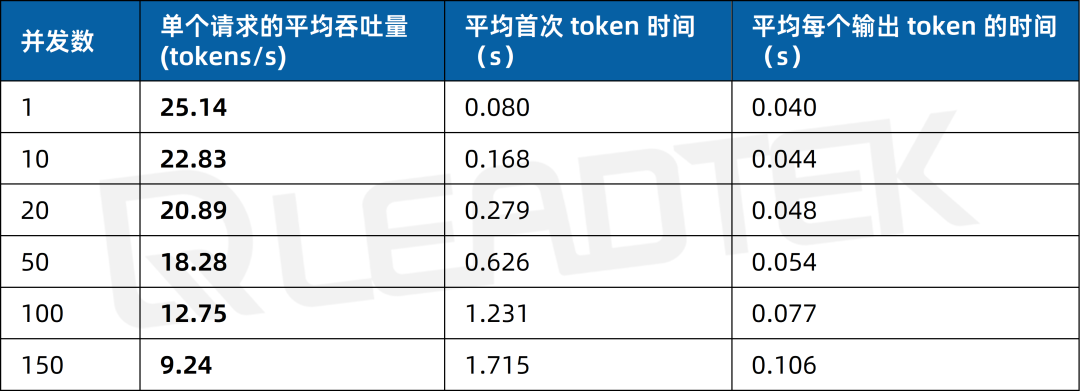
▲ 2 卡 RTX 5880 Ada 文本生成場景測試結果圖表
文本總結場景測試中,單請求吞吐量約23.63tokens/s,并發(fā) 150 時降至約8.75tokens/s。
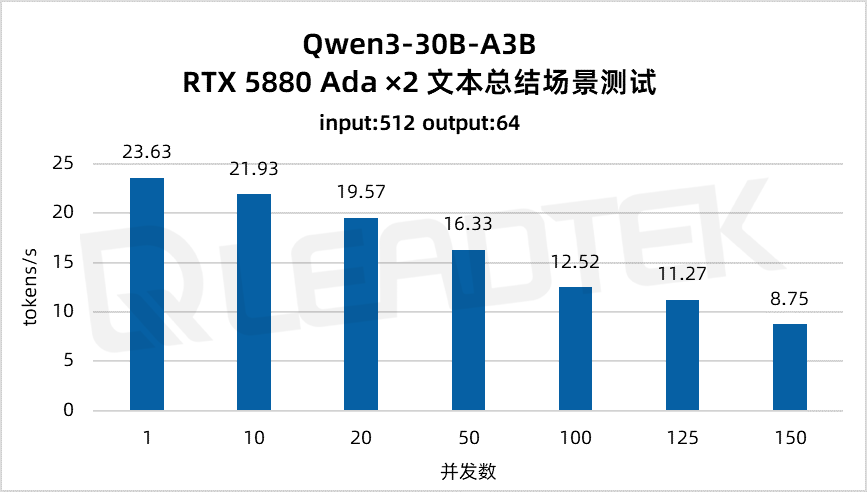
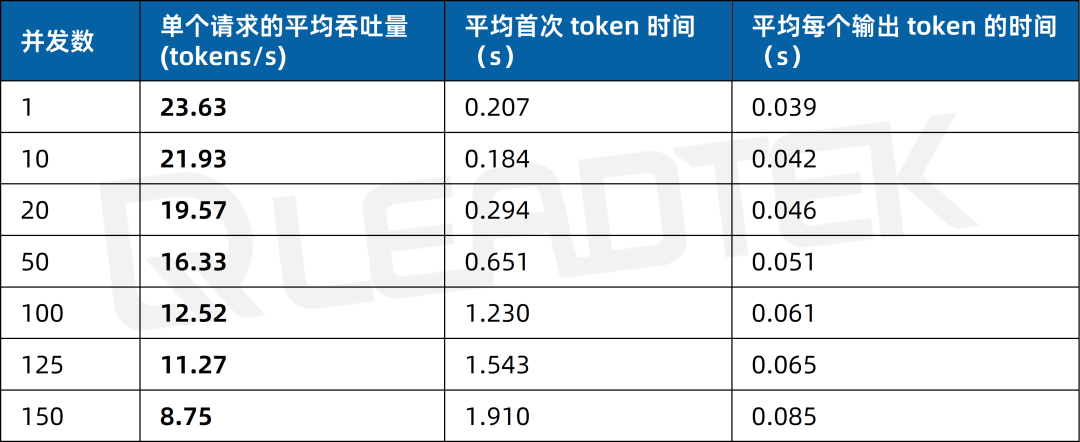
▲ 2 卡 RTX 5880 Ada 文本總結場景測試結果圖表
3 總結
3.1 性能亮點速覽
高并發(fā)文本生成場景:4 卡優(yōu)勢顯著
輸入 32 tokens + 輸出 1024 tokens(文本生成)
4 卡配置:150 并發(fā)下吞吐量13.30tokens/s,較 2 卡(9.24 tokens/s)提升43.94%;
延遲表現:4 卡的“首次 token 時間”顯著低于 2 卡,響應更敏捷。
文本總結場景:吞吐與延遲平衡
輸入 512 tokens + 輸出 64 tokens(文本總結)
4 卡配置:150 并發(fā)下吞吐量10.78tokens/s,延遲控制在1.62s內;
2 卡配置:適配 100 并發(fā)以內場景,吞吐量12.52tokens/s,滿足日常推理需求。
吞吐量衰減率:4 卡更穩(wěn)定
隨著并發(fā)數從 1 增至 200,并發(fā)量翻倍時,4 卡吞吐量衰減率(63%),體現更強的負載均衡能力。
3.2 Leadtek AI 一體機

▲ Leadtek AI 一體機
基于NVIDIA RTX 5880 Ada顯卡的 Leadtek AI 一體機,搭配通義千問 Qwen3-30B-A3B 模型,在大模型推理場景中展現出卓越性能:
4 卡配置:在高并發(fā)(200 并發(fā))下仍能保持10.59 tokens/s的吞吐量,且單請求延遲可控;
2 卡配置:在中低并發(fā)場景下表現穩(wěn)定,滿足中小型任務需求;
NVIDIA RTX 5880 Ada完美適配 Qwen3-30B-A3B 的 MoE 結構(激活參數僅 30 億,性能超越 QwQ-32B),實現高效能比。
適用場景
智能辦公與教育:智能辦公助手(如日程管理、文檔生成);個性化學習輔導(根據學生進度定制內容);教育領域的智能答疑與內容創(chuàng)作。
企業(yè)級應用與開發(fā):智能客服(高效處理用戶咨詢);復雜任務推理(數學計算、編程分析,需思考模式);API 集成與微調(適配特定業(yè)務需求,如工具調用)。
目前,麗臺訓推一體機、大模型一體機等都已集成 Qwen3 系列模型。
Leadtek AI 一體機憑借NVIDIA RTX 5880 Ada的硬核性能與Qwen3-30B-A3B的卓越優(yōu)化,重新定義了本地化大模型推理的天花板。無論是追求極限吞吐的商業(yè)場景,還是注重成本效益的中小團隊,都能尋求到最優(yōu)解。
-
AI
+關注
關注
87文章
33789瀏覽量
274613 -
開源
+關注
關注
3文章
3551瀏覽量
43356 -
大模型
+關注
關注
2文章
2972瀏覽量
3730
原文標題:Qwen3 正式發(fā)布!30B 大模型 4 卡 RTX 5880 Ada 實測
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
Intel OpenVINO? Day0 實現阿里通義 Qwen3 快速部署
在openEuler上基于vLLM Ascend部署Qwen3
NVIDIA使用Qwen3系列模型的最佳實踐

NVIDIA RTX 5000 Ada顯卡性能實測報告

RTX 5880 Ada Generation GPU與RTX? A6000 GPU對比

NVIDIA RTX 4500 Ada與NVIDIA RTX A5000的對比
NVIDIA RTX 5880 Ada顯卡部署DeepSeek-R1模型實測報告

壁仞科技完成阿里巴巴通義千問Qwen3全系列模型支持
幾B都有!BM1684X一鍵適配全系列Qwen3






 工商網監(jiān)
工商網監(jiān)
評論