 NVIDIA使用Qwen3系列模型的最佳實踐
NVIDIA使用Qwen3系列模型的最佳實踐
阿里巴巴近期發布了其開源的混合推理大語言模型 (LLM)通義千問 Qwen3,此次 Qwen3 開源模型系列包含兩款混合專家模型 (MoE),235B-A22B(總參數 2,350 億,激活參數 220 億)和 30B-A3B,以及六款稠密 (Dense) 模型 0.6B、1.7B、4B、8B、14B、32B。
現在,開發者能夠基于 NVIDIA GPU,使用NVIDIA TensorRT-LLM、Ollama、SGLang、vLLM等推理框架高效集成和部署 Qwen3 模型,從而實現極快的詞元 (token) 生成,以及生產級別的應用研發。
本文提供使用 Qwen3 系列模型的最佳實踐,我們會展示如何使用上述框架來部署模型實現高效推理。開發者可以根據他們的應用場景需求來選擇合適的框架,例如高吞吐量、低延遲、或是 GPU 內存占用 (GPU footprint)。
Qwen3 模型
Qwen3 是中國首個混合推理模型,在 AIME、LiveCodeBench、ArenaHard、BFCL 等權威評測集上均獲得出色的表現(信息來源于阿里巴巴官方微信公眾號)。Qwen3 提供的系列開源稠密和 MoE 模型在推理、指令遵循、Agent 能力、多語言支持等方面均大幅增強,是全球領先的開源模型。
大語言模型的推理性能對于實時、經濟高效的生產級部署至關重要
LLM 生態系統快速演進,新模型和新技術不斷更新迭代,需要一種高性能且靈活的解決方案來優化模型。
推理系統設計頗具挑戰,要求也不斷提升,這些挑戰包括 LLM 推理計算預填充 (prefill) 和解碼 (decode) 兩個階段對于計算能力和顯存大小 / 帶寬的需求差異,超大尺寸模型并行分布式推理,海量并發請求,輸入輸出長度高度動態請求等。
目前在推理引擎上有許多優化技術可用,包括高性能 kernel、低精度量化、Batch 調度、采樣優化、KV 緩存 (KV cache) 優化等等,選擇最適合自己應用場景的技術組合需要耗費開發者大量精力。
NVIDIA TensorRT-LLM提供了最新的極致優化的計算 kernel、高性能 Attention 實現、多機多卡通信分布式支持、豐富的并行和量化策略等,從而在 NVIDIA GPU 上實現高效的 LLM 推理。此外,TensorRT-LLM 采用PyTorch 的新架構還提供了直觀、簡潔且高效的模型推理配置 LLM API,從而能夠兼顧極佳性能和靈活友好的工作流。
通過使用 TensorRT-LLM,開發者可以迅速上手先進的優化技術,其中包括定制的 Attention kernel、連續批處理 (in-flight batching)、分頁KV 緩存 (Paged KV cache)、量化 (FP8、FP4、INT4 AWQ、INT8 SmoothQuant)、投機采樣等諸多技術。
使用 TensorRT-LLM運行 Qwen3 的推理部署優化
下面以使用 Qwen3-4B 模型配置 PyTorch backend為例,描述如何快捷進行基準測試以及服務化的工作。采用類似的步驟,也可以實現 Qwen3 其他 Dense 和 MoE 模型的推理部署優化。
1. 首先準備 benchmark 測試數據集合和extra-llm-api-config.yml
配置文件:
python3/path/to/TensorRT-LLM/benchmarks/cpp/prepare_dataset.py --tokenizer=/path/to/Qwen3-4B --stdout token-norm-dist--num-requests=32768 --input-mean=1024--output-mean=1024 --input-stdev=0--output-stdev=0>/path/to/dataset.txt cat>/path/to/extra-llm-api-config.yml<
2. 通過trtllm-bench運行 benchmark 指令:
trtllm-bench --modelQwen/Qwen3-4B --model_path/path/to/Qwen3-4B throughput --backendpytorch --max_batch_size128 --max_num_tokens16384 --dataset/path/to/dataset.txt --kv_cache_free_gpu_mem_fraction0.9 --extra_llm_api_options/path/to/extra-llm-api-config.yml --concurrency128 --num_requests32768 --streaming
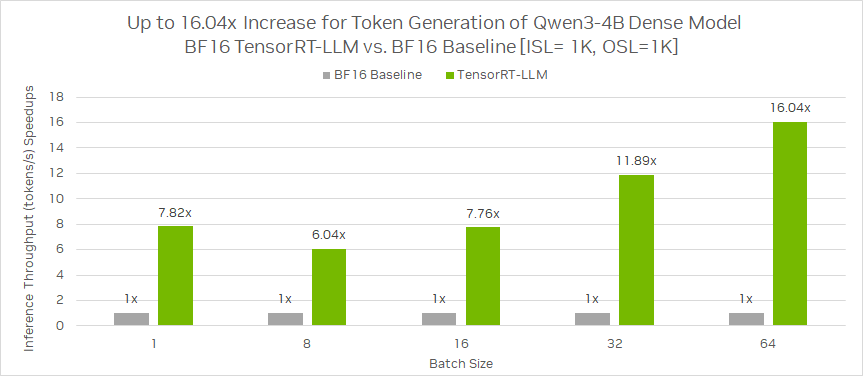
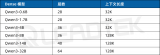
相同 GPU 環境配置下,基于 ISL = 1K,OSL = 1K,相較 BF16 基準,Qwen3-4B 稠密模型使用 TensorRT-LLM 在 BF16 的推理吞吐(每秒生成的 token 數)加速比最高可達 16.04 倍。
圖 1:Qwen3-4B 稠密模型在 TensorRT-LLM BF16 與 BF16 基準的推理吞吐性能比較
該圖片來源于 NVIDIA Blog:Integrate and Deploy Tongyi Qwen3 Models into Production Applications with NVIDIA,若您有任何疑問或需要使用該圖片,請聯系 NVIDIA
3. 通過trtllm-serve運行 serve 指令:
trtllm-serve /path/to/Qwen3-4B --hostlocalhost --port8000 --backendpytorch --max_batch_size128 --max_num_tokens16384 --kv_cache_free_gpu_memory_fraction0.95 --extra_llm_api_options/path/to/extra-llm-api-config.yml
4. 模型啟動成功后,便可通過標準 OpenAI API 進行模型推理調用。
curl -X POST"http://localhost:8000/v1/chat/completions" -H"Content-Type: application/json" --data '{ "model":"Qwen/Qwen3-4B", "Max_tokens": 1024, "Temperature": 0, "messages": [ { "role":"user", "content":"What is the capital of France?" } ] }'
使用 Ollama,SGLang,vLLM 框架運行 Qwen3-4B
除了 TensorRT-LLM,Qwen 模型也可以使用諸如 Ollama,SGLang,vLLM 等框架,通過簡單幾步部署到 NVIDIA GPU。Qwen3 提供了多種模型可以運行在終端和設備上,例如NVIDIA Jeston以及適用于 Windows 開發者的NVIDIA RTX。
使用 Ollama 在本地運行 Qwen3-4B:
1. 從以下網址下載和安裝最新版本的 Ollama: ollama.com/download。
2. 使用ollama run命令運行模型,此操作將加載并初始化模型用于后續與用戶交互。
ollamarun qwen3:4b
3. 在用戶提示詞或系統消息中添加/think(默認值)和/no_think可在模型的思考模式之間切換。運行ollama run命令后,可以直接在終端中使用以下的示例提示詞,來測試思考模式:
"Writeapython lambda functiontoadd two numbers" - Thinking mode enabled "Writeapython lambda functiontoadd two numbers /no_think" - Non-thinking mode
4. 參考ollama.com/library/qwen3查看更多模型變量,這些變量基于 NVIDIA GPU 完成了優化。
使用 SGLang 運行 Qwen3-4B:
1. 安裝 SGLang 庫
pipinstall"sglang[all]"
2. 下載模型,在這個演示中,我們使用的是 Hugging Face 上的 huggingfaceCLI 命令提示符執行,請注意需要提供一個 API key 來下載模型。
huggingface-cli download--resume-downloadQwen/Qwen3-4B--local-dir./
3. 加載和運行模型,請注意,根據不同的需求,可以傳遞額外的參數。更多詳細信息可以參考相關文檔。
python-m sglang.launch_server --model-path /ssd4TB/huggingface/hub/models/ --trust-remote-code --device "cuda:0" --port 30000 --host 0.0.0.0
4. 調用模型推理
curl -X POST"http://localhost:30000/v1/chat/completions" -H"Content-Type: application/json" --data '{ "model":"Qwen/Qwen3-4B", "messages": [ { "role":"user", "content":"What is the capital of France?" } ] }'
使用 vLLM 運行 Qwen3-4B:
1. 安裝 vLLM 庫
pipinstall vllm
2. 通過vllm serve加載和運行模型,請注意,根據不同的需求,可以傳遞額外的參數。更多詳細信息可以參考相關文檔。
vllm serve "Qwen/Qwen3-4B" --tensor-parallel-size 1 --gpu-memory-utilization 0.85 --device "cuda:0" --max-num-batched-tokens 8192 --max-num-seqs 256
3. 調用模型推理
curl -X POST"http://localhost:8000/v1/chat/completions" -H"Content-Type: application/json" --data '{ "model":"Qwen/Qwen3-4B", "messages": [ { "role":"user", "content":"What is the capital of France?" } ] }'
總結
僅通過幾行代碼,開發者即可通過包括 TensorRT-LLM 在內的流行推理框架來使用最新的 Qwen 系列模型。
此外,對模型推理和部署框架的技術選型需要考慮到諸多關鍵因素,尤其是在把 AI 模型部署到生產環境中時,對性能、資源和成本的平衡。
作者
Ankit Patel
NVIDIA 資深總監,負責軟件開發工具包、應用程序編程接口以及開發者工具方面的開發者拓展工作。2011 年作為 GPU 產品經理加入 NVIDIA,之后從事虛擬化、光線追蹤和 AI 等產品在軟件產品管理方面的工作。Ankit 畢業于康考迪亞大學 (Concordia University),獲計算機科學學士學位,并在康奈爾大學 (Cornell University) 取得工商管理碩士學位 (MBA)。
劉川
NVIDIA 解決方案架構經理,整體負責中國區云計算行業 GPU 解決方案。于南京大學獲計算機科學與技術專業碩士學位。帶領團隊主要從事大語言模型、生成式 AI 以及搜索推薦等重點 AI 任務的 GPU 適配、優化和加速方案的設計、部署和落地,幫助多家頭部互聯網公司在諸多業務中大幅降本增效。
金國強
NVIDIA 資深解決方案架構師,主要負責深度學習生成式 AI 領域模型訓練、推理優化以及大模型開發與應用云端落地等技術方向合作。
郝尚榮
NVIDIA 深度學習解決方案架構師,2021 年加入 NVIDIA 解決方案架構團隊,主要從事模型推理優化加速的工作,目前主要支持國內 CSP 客戶在大語言模型推理加速的工作。
谷鋆
NVIDIA 深度學習解決方案架構師,于 2022 年加入 NVIDIA 解決方案架構師團隊,專門為國內 CSP 進行 LLM 模型推理優化。
高慧怡
NVIDIA 深度學習解決方案架構師,2020 年加入 NVIDIA 解決方案架構團隊,從事深度學習應用在異構系統的加速工作,目前主要支持國內 CSP 客戶在大語言模型的訓練加速工作。
-
NVIDIA
+關注
關注
14文章
5200瀏覽量
105597 -
阿里巴巴
+關注
關注
7文章
1635瀏覽量
48025 -
模型
+關注
關注
1文章
3474瀏覽量
49892 -
通義千問
+關注
關注
1文章
34瀏覽量
378
原文標題:NVIDIA 實現通義千問 Qwen3 的生產級應用集成和部署
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Intel OpenVINO? Day0 實現阿里通義 Qwen3 快速部署
在openEuler上基于vLLM Ascend部署Qwen3
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 第10期:2025.05.6--2025.05.9
號稱全球最強開源模型 ——Qwen2.5 系列震撼來襲!PerfXCloud同步上線,快來體驗!
阿里云開源Qwen2.5-Coder代碼模型系列
壁仞科技完成阿里巴巴通義千問Qwen3全系列模型支持
上新:小米首個推理大模型開源 馬斯克:下周推出Grok 3.5
幾B都有!BM1684X一鍵適配全系列Qwen3

中科曙光DeepAI深算智能引擎全面支持Qwen3
摩爾線程GPU率先支持Qwen3全系列模型
后摩智能NPU適配通義千問Qwen3系列模型
MediaTek天璣9400率先完成阿里Qwen3模型部署
NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告





 工商網監
工商網監
評論