 幾B都有!BM1684X一鍵適配全系列Qwen3
幾B都有!BM1684X一鍵適配全系列Qwen3
Qwen3發布,大小尺寸通吃
Qwen3一發布,登頂開源大模型排行榜!235B、32B、8B、4B、1.7B云邊端全尺寸模型,BF16和FP8兩種精度,一次性發布,無論云端大卡還是邊緣AI設備,都可體驗最新的大模型能力。
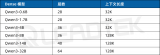
來看下Qwen3各個模型的benchmark得分:
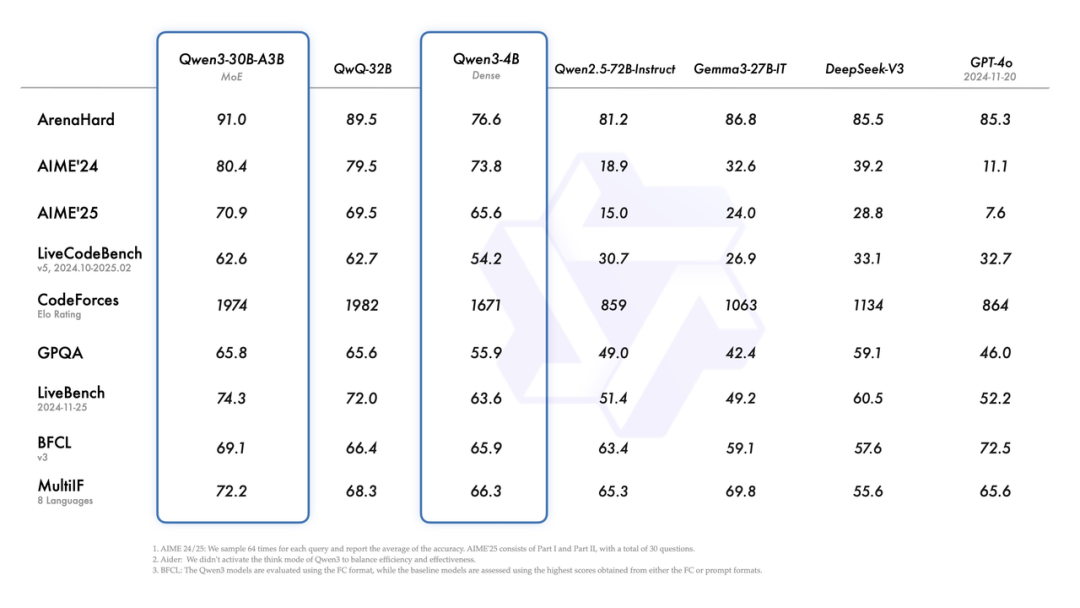
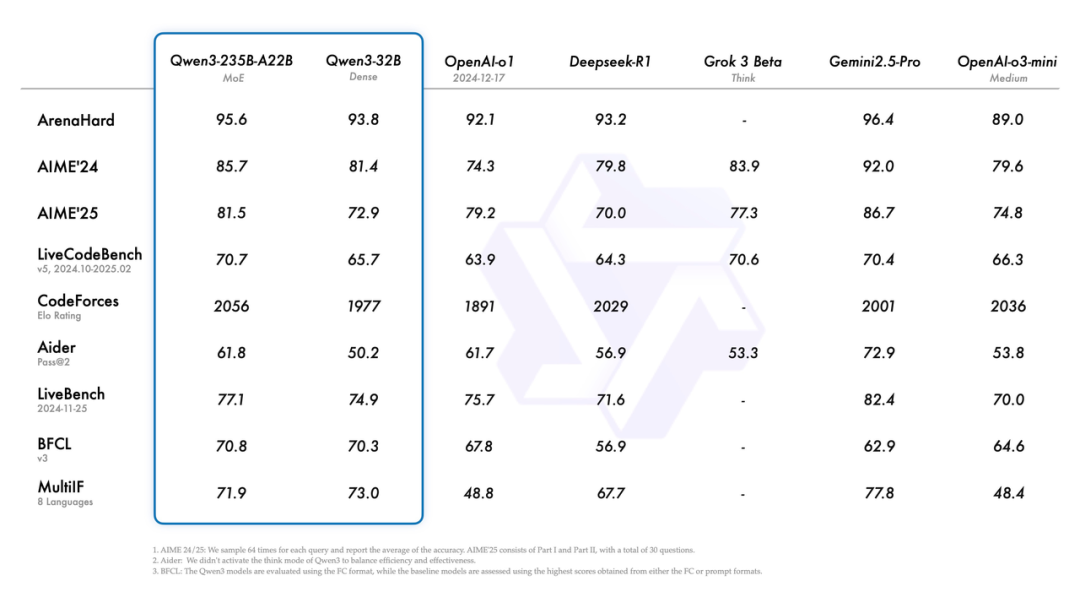
這些年看多了大模型的迭代,各家都在玩參數競賽和架構魔術,但阿里這次Qwen3的設計有點意思——它搞了個"混合模式"的機制,讓模型能自己決定什么時候該"慢慢想",什么時候該"快速答"。這玩意兒本質上是在延遲和精度之間做動態權衡,技術上不算新鮮(OpenAI的o3就玩過這套),但阿里的實現方式更像個老會計——給你個"思考預算"的開關,讓用戶自己把控成本。
BM1684X,Qwen3部署性價比之王
這種設計背后是典型的工程思維:既然大模型的推理成本居高不下,不如把選擇權交給用戶。就像當年CPU的動態調頻技術,與其無腦跑滿頻,不如讓系統根據負載靈活調節,但這種模式切換要在硬件層面做好流水線調度,否則切換時的上下文保存就能吃掉那點省下來的算力。
現在的大模型就像過度教育的孩子,解得了奧數題但算不清買菜賬。Qwen3給"孩子"裝了個手動擋,讓用戶自己決定什么時候該掛高檔位沖刺,什么時候該低檔省油,這種策略下每瓦特的性價比自然就上去了,而邊緣和端側的設備對成本更是敏感,那作為邊緣大模型部署的性價比之王,BM1684X表現如何?
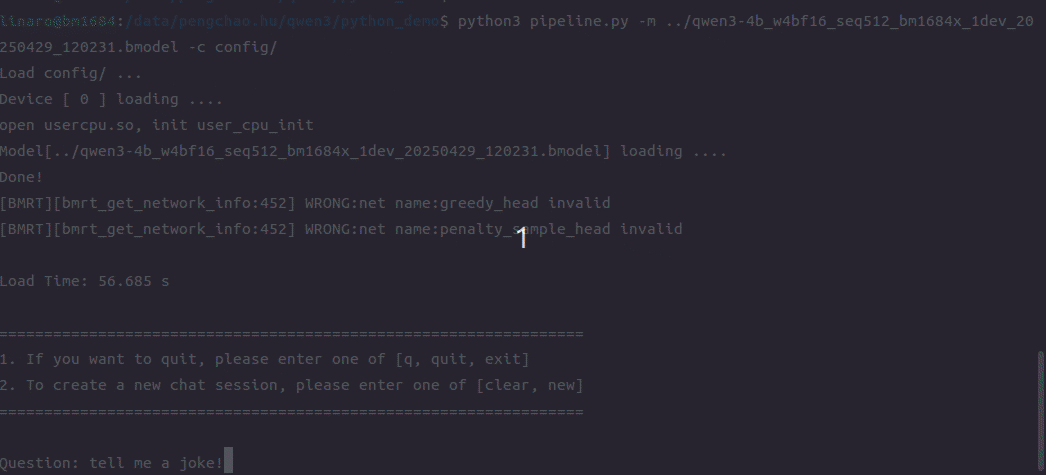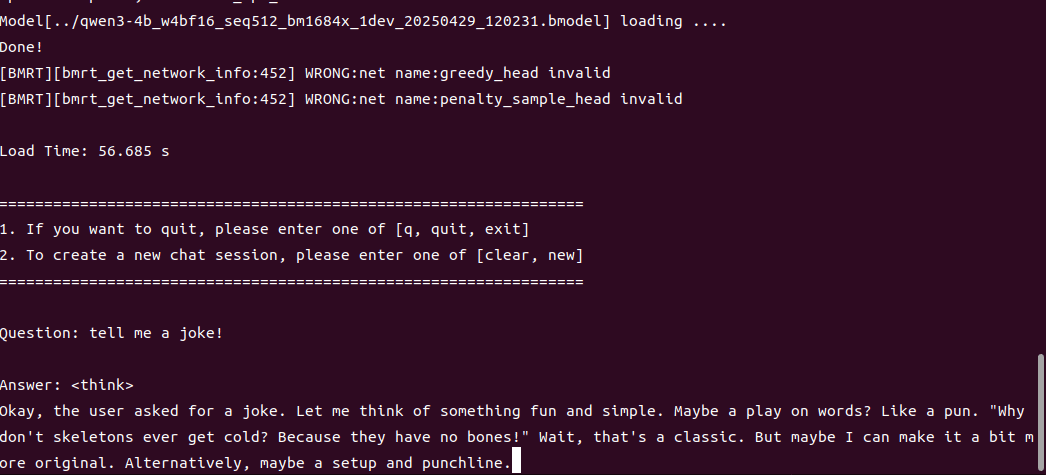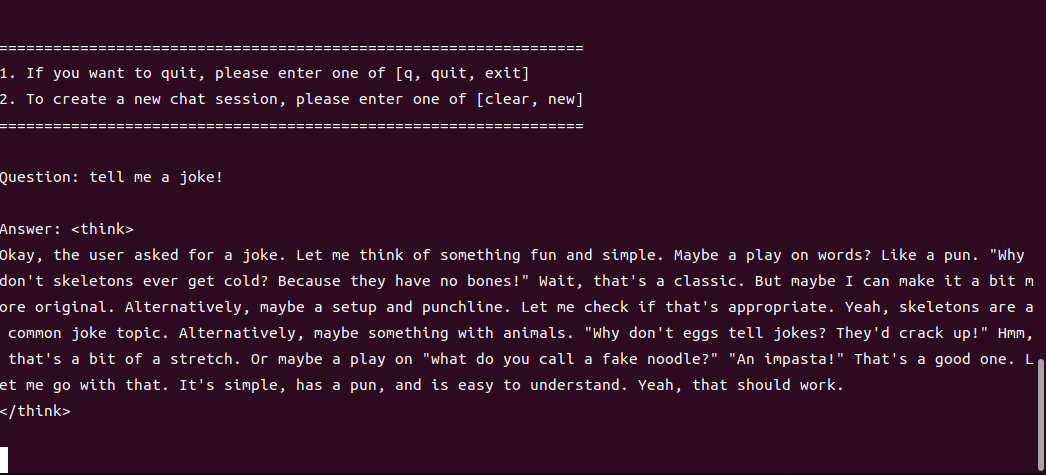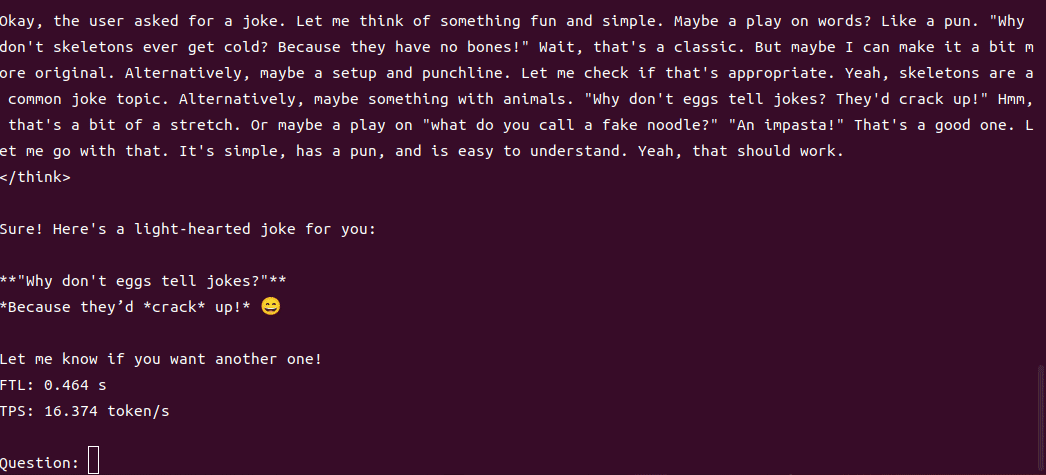
4B運行demo(SOC模式950Mhz 16.4tokens/s)
1.7B運行demo(SOC模式950Mhz 30.3 tokens/s)
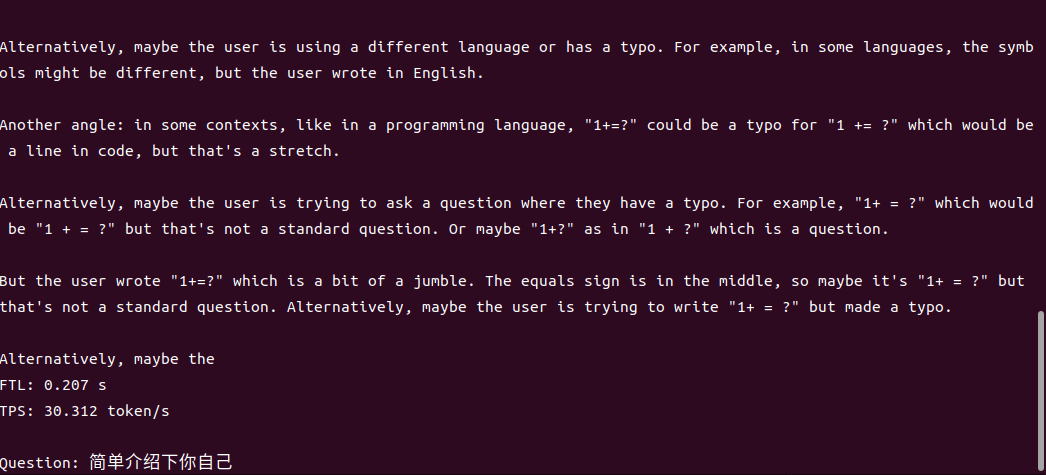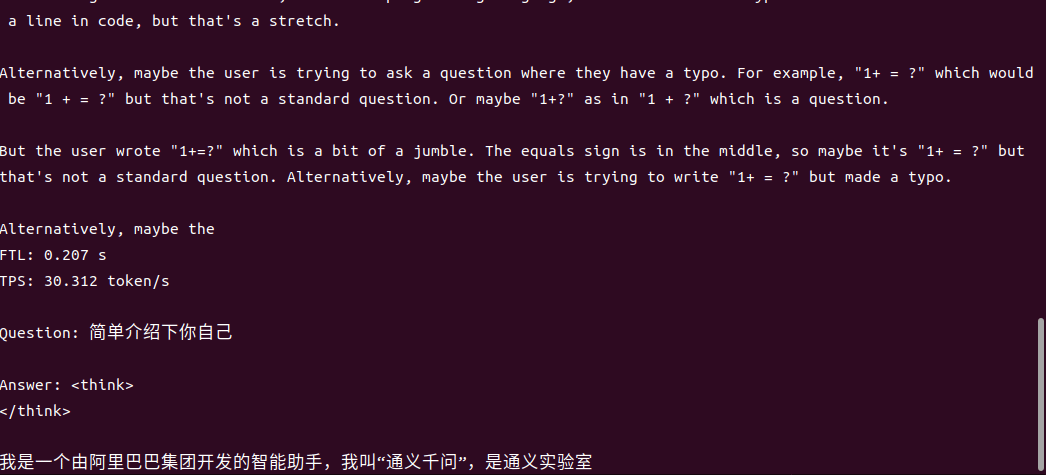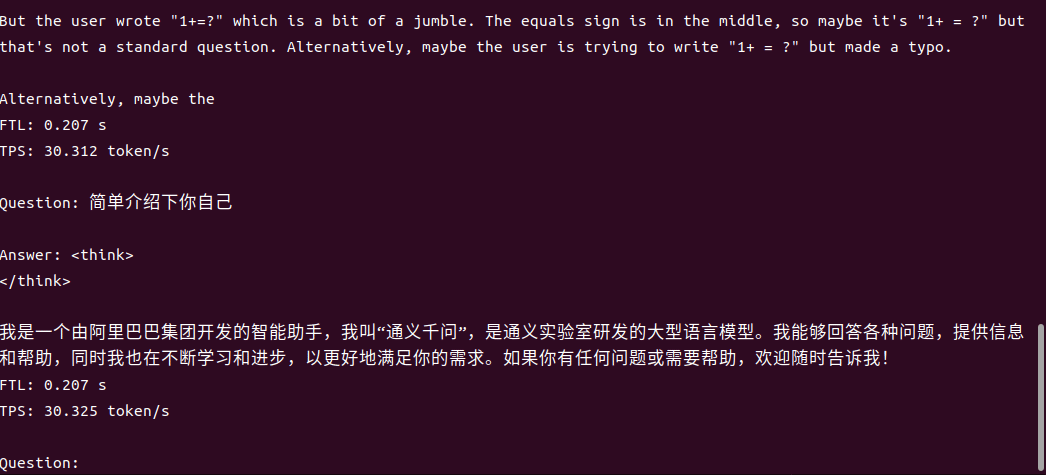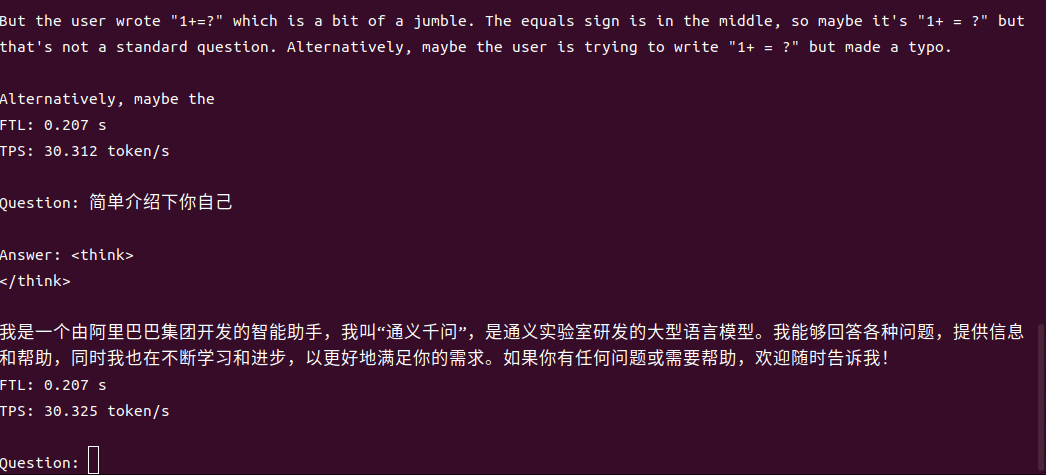
一行代碼適配,解鎖全系模型
BM1684X 單芯配置16GB內存,20B以下的都可以在一顆芯片跑,32B用2顆就可以(32B dense模型性能約5 tokens/s)。
更詳細的適配流程參考:https://github.com/sophgo/LLM-TPU/tree/main/models/Qwen3,拉取最新的tpu-mlir代碼后,只需要一行代碼即可轉出bmodel,不用再通過onnx中介。

bmodel轉好之后,可以用python或者cpp來跑:
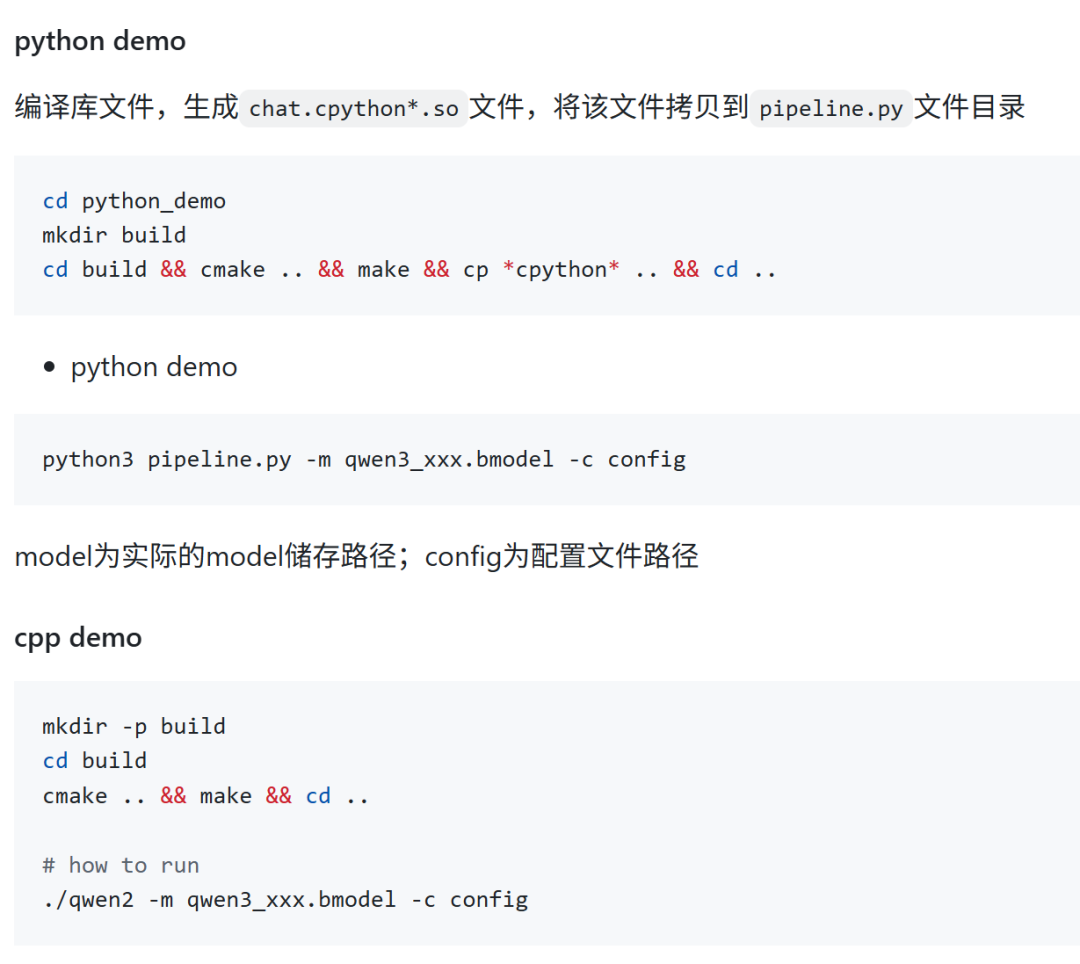
限制我們適配新模型速度的不是工具鏈,而是模型下載速度,歡迎關注算能產品,解鎖更多大模型部署方案,手中有BM1684X的同學可以玩起來了!
-
邊緣AI
+關注
關注
0文章
146瀏覽量
5334 -
大模型
+關注
關注
2文章
3021瀏覽量
3815
發布評論請先 登錄
壁仞科技完成Qwen3旗艦模型適配
Arm CPU適配通義千問Qwen3系列模型
Intel OpenVINO? Day0 實現阿里通義 Qwen3 快速部署
NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告
NVIDIA使用Qwen3系列模型的最佳實踐

MediaTek天璣9400率先完成阿里Qwen3模型部署
后摩智能NPU適配通義千問Qwen3系列模型
摩爾線程GPU率先支持Qwen3全系列模型
在openEuler上基于vLLM Ascend部署Qwen3





 工商網監
工商網監
評論