 愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型
Qwen2.5-VL:the new flagship vision-language model of Qwen and also a significant leap from the previous Qwen2-VL.
愛芯通元:以算子為原子指令集的AI計算處理器。高效支持混合精度算法設計和Transformer,為大模型(DeepSeek、Qwen、MiniCPM……)在“云—邊—端”的AI應用提供強力基礎。
https://www.axera-tech.com/Skill/166.html
TLDR
背景
熟悉愛芯通元NPU的網友很清楚,從去年開始我們在端側多模態大模型適配上一直處于主動緊跟的節奏。先后適配了國內最早開源的多模態大模MiniCPM V 2.0,上海人工智能實驗室的書生多模態大模型 InternVL2.5-1B/8B/MPO,Huggingface推出的全球最小多模態大模型SmloVLM-256M。為工業界提供了離線部署多模態大模型(VLM)實現圖片本地高效率理解的可行性方案。
從本文開始,我們將逐漸探索基于VLM的視頻理解方案,讓端側/邊緣設備智能化升級有更大的想象空間。
本文基于Qwen2.5-VL-3B走馬觀花介紹VLM是如何從圖片理解(Image Understand)延伸到視頻理解(Video Understand),并展示基于愛芯通元NPU平臺的最新適配情況,最后“腦洞”一些可能存在的產品落地場景。
Qwen2.5-VL
Qwen2.5-VL是由通義千問團隊開源的視覺多模態大模型。到目前為止已經開源了3B、7B、32B、72B四種尺度,滿足不同算力設備靈活部署。
官方鏈接:https://github.com/QwenLM/Qwen2.5-VL
Huggingface:https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
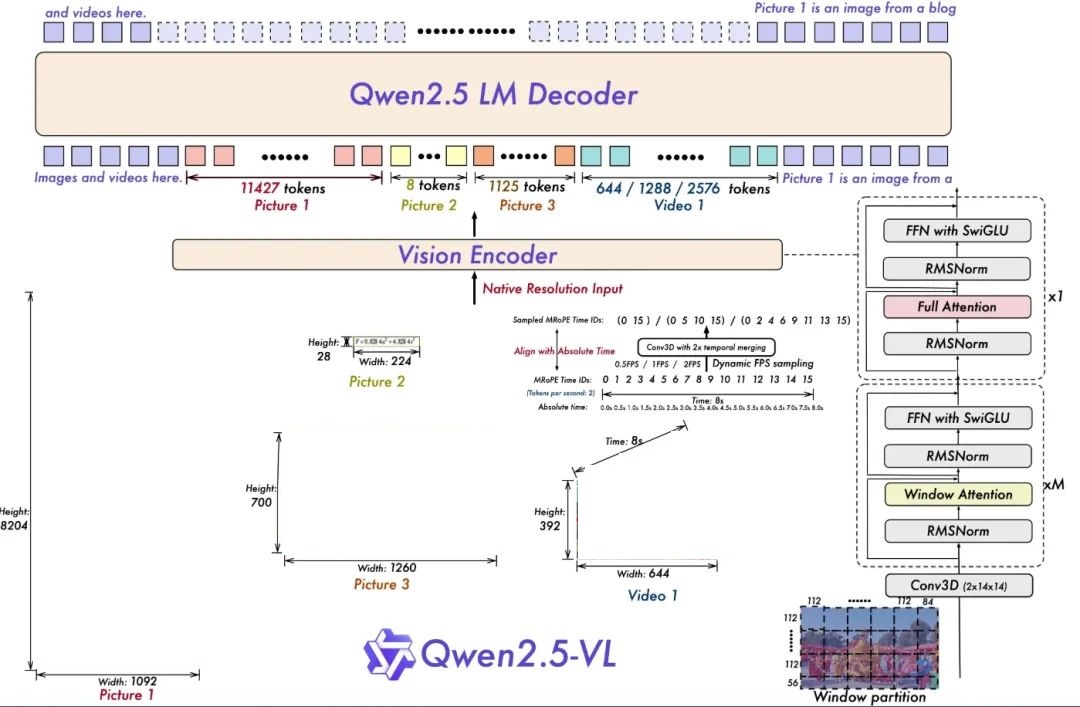
Qwen2.5-VL是Qwen2-VL的版本更新,以下功能更新展示了Qwen2.5-VL在視覺-語言處理領域的強大功能和廣泛應用前景。
增強功能
視覺理解能力:Qwen2.5-VL不僅擅長識別常見的物體如花、鳥、魚和昆蟲,還能高效地分析圖像中的文本、圖表、圖標、圖形和布局;
作為視覺代理的能力:該模型能夠直接充當一個視覺代理,具備推理能力和動態工具指導能力,適用于計算機和手機的使用;
長視頻理解和事件捕捉:Qwen2.5-VL能夠理解超過一小時的視頻內容,并新增了通過精確定位相關視頻段來捕捉事件的能力;
不同格式的視覺定位能力:該模型能通過生成邊界框或點準確地在圖像中定位對象,并提供包含坐標和屬性的穩定JSON輸出;
結構化輸出:針對發票掃描件、表格、表單等數據,Qwen2.5-VL支持其內容的結構化輸出,這在金融、商業等領域具有重要應用價值。
架構更新
為視頻理解進行的動態分辨率和幀率訓練:通過采用動態FPS采樣將動態分辨率擴展到時間維度,使模型能夠在各種采樣率下理解視頻。相應地,我們在時間維度上用ID和絕對時間對齊更新了mRoPE,讓模型能夠學習時間序列和速度,最終獲得定位特定時刻的能力。
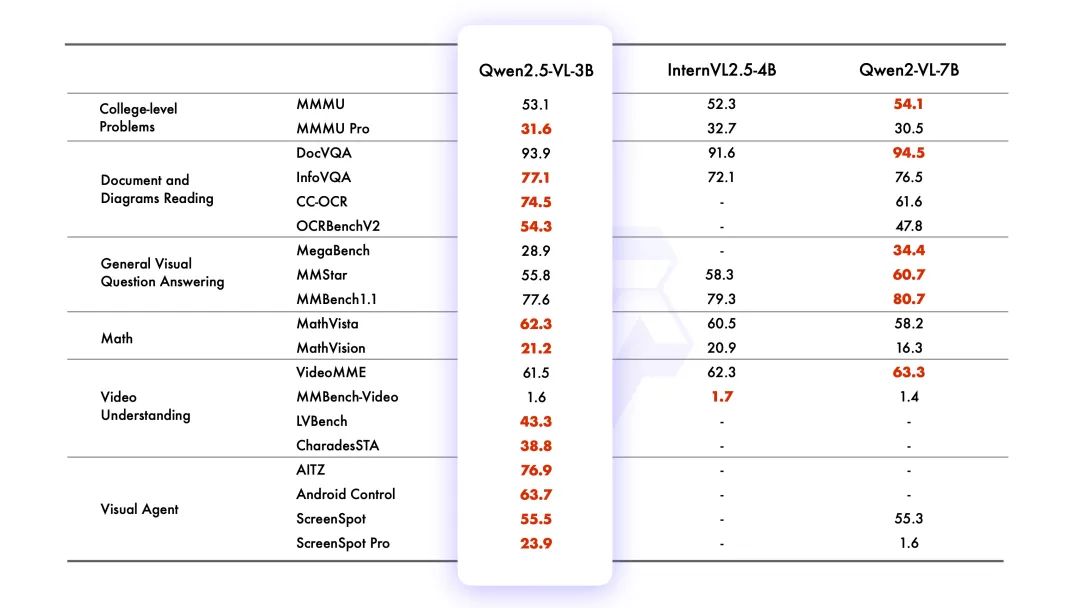
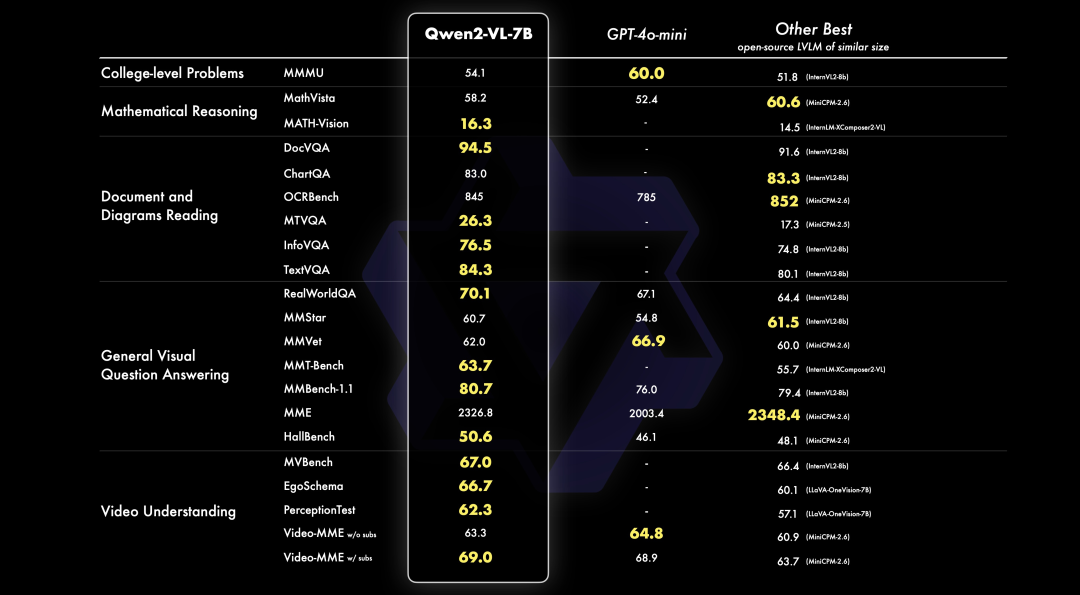
跑分情況
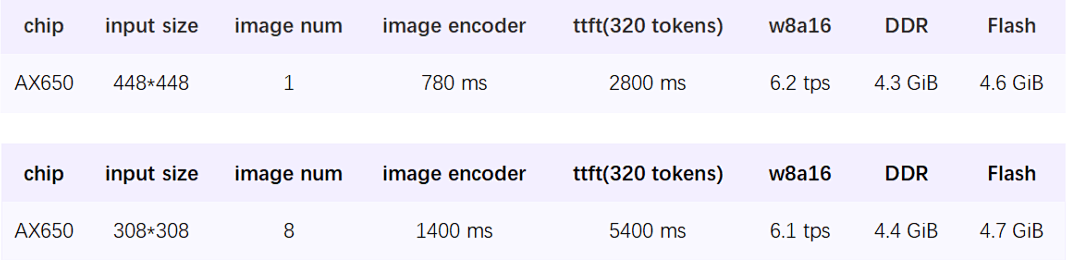
愛芯通元
愛芯通元是愛芯元智自研的NPU IP品牌。本文基于內置愛芯通元NPUv3架構的愛芯派Pro(AX650N)進行示例展示。
愛芯派Pro
搭載愛芯元智第三代高能效比智能視覺芯片AX650N。集成了八核Cortex-A55 CPU,18TOPs@INT8 NPU以及H.264、H.265 編解碼的VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI輸入,千兆Ethernet、USB、以及HDMI 2.0b輸出,并支持32路1080p@30fps解碼內置高算力和超強編解碼能力,滿足行業對高性能邊緣智能計算的需求。通過內置多種深度學習算法,實現視覺結構化、行為分析、狀態檢測等應用,高效率支持Transformer結構的大模型。提供豐富的開發文檔,方便用戶進行二次開發。

模型轉換
我們在Huggingface上提供了預編譯好的模型,建議直接使用。
如果有朋友想深入研究如何從Huggingface原生倉庫的safetytensor模型使用Pulsar2 NPU工具鏈轉換生成axmodel模型,請參考我們的開源項目:
https://github.com/AXERA-TECH/Qwen2.5-VL-3B-Instruct.axera
模型部署
預編譯文件
從Huggingface上獲取
https://huggingface.co/AXERA-TECH/Qwen2.5-VL-3B-Instruct
pipinstall -U huggingface_hub exportHF_ENDPOINT=https://hf-mirror.com huggingface-cli download --resume-download AXERA-TECH/Qwen2.5-VL-3B-Instruct --local-dir Qwen2.5-VL-3B-Instruct
文件說明
root@ax650:/mnt/qtang/llm-test/Qwen2.5-VL-3B-Instruct# tree -L 1 . |-- image |-- main |-- python |-- qwen2_5-vl-3b-image-ax650 |-- qwen2_5-vl-3b-video-ax650 |-- qwen2_5-vl-tokenizer |-- qwen2_tokenizer_image_448.py |-- qwen2_tokenizer_video_308.py |-- run_qwen2_5_vl_image.sh |-- run_qwen2_5_vl_video.sh `-- video
qwen2_5-vl-3b-image-ax650:存放圖片理解的axmodel文件
qwen2_5-vl-3b-video-ax650:存放視頻理解的axmodel文件
qwen2_tokenizer_image_448.py:適用于圖片理解的tokenizer解析服務
run_qwen2_5_vl_image.sh:圖片理解示例的執行腳本
準備環境
使用transformer庫實現tokenizer解析服務。
pipinstall transformers==4.41.1
圖片理解示例
先啟動適用于圖片理解任務的tokenizer解析服務。
python3qwen2_tokenizer_image_448.py --port12345
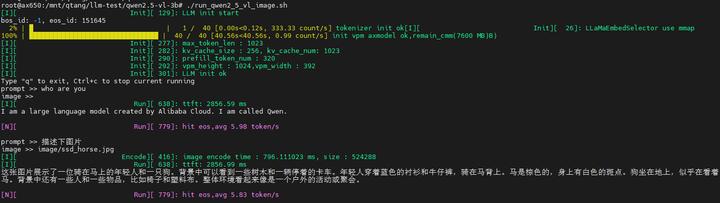
運行圖片理解示例
./run_qwen2_5_vl_image.sh
輸入圖片
輸入文本(prompt):描述下圖片
輸出結果
輸入文本(prompt):目標檢測,穿著藍色衣服的人,輸出概率最高的一個結果
輸出結果

將原始圖片resize到448x448分辨率后,使用返回的坐標信息[188, 18, 311, 278],手動畫框結果還是挺準的。
視頻理解示例
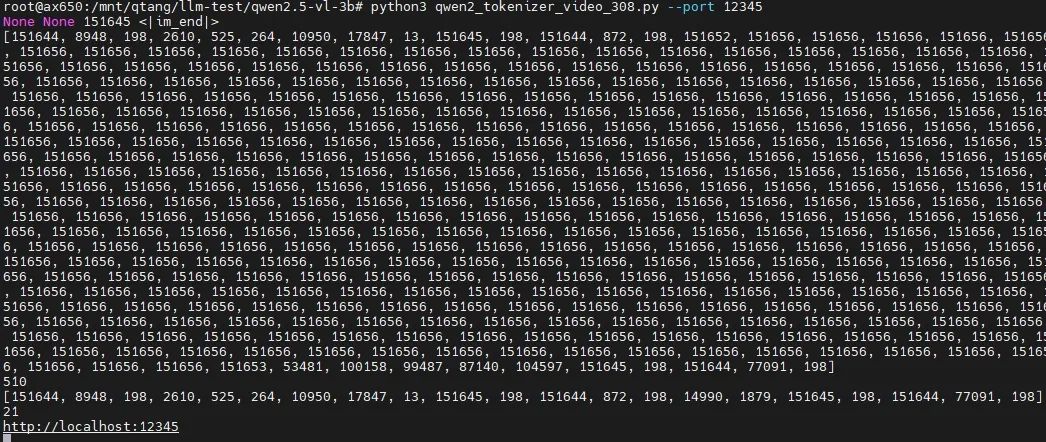
提前將從某一段視頻抽取適當時間戳的8幀。先啟動適用于視頻理解任務的tokenizer解析服務。
pythonqwen2_tokenizer_video_308.py --port12345
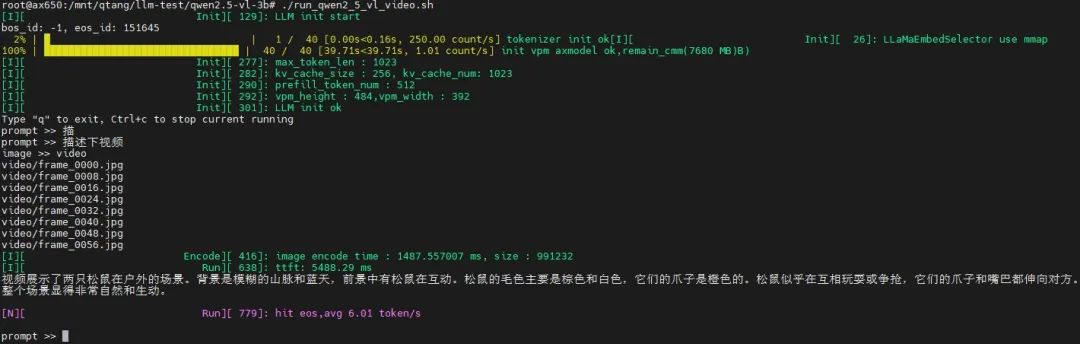
運行視頻理解示例
./run_qwen2_5_vl_video.sh
輸入視頻
輸入文本(prompt):描述下視頻
輸出結果
應用場景探討
視頻理解能結合視頻中時間序列上的信息。能夠更佳準確的理解真實世界的行為語義。
家庭場景:老人摔倒,煙火檢測
工業場景:缺陷檢測,危險行為檢測
車載場景:駕艙內外環境感知
其他場景:穿戴式視覺輔助設備
總結
隨著年初DeepSeek破圈,普通大眾已經接受大模型與日常生活中的萬事萬物進行融合,單純的語言類大模型已經無法滿足大眾的需求,多模態大模型、全模態大模型已經成為今年的主流。
愛芯通元NPU結合原生支持Transformer、高能效比、易用性等技術優勢,將積極適配業界優秀的多模態大模型,提供端&邊大模型高效部署的軟硬件整體解決方案。推動“普惠AI造就美好生活”。
-
處理器
+關注
關注
68文章
19808瀏覽量
233565 -
AI
+關注
關注
87文章
34256瀏覽量
275399 -
開源
+關注
關注
3文章
3611瀏覽量
43485 -
NPU
+關注
關注
2文章
321瀏覽量
19516 -
大模型
+關注
關注
2文章
3029瀏覽量
3830
原文標題:愛芯分享 | 愛芯通元NPU適配Qwen2.5-VL-3B
文章出處:【微信號:愛芯元智AXERA,微信公眾號:愛芯元智AXERA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Intel OpenVINO? Day0 實現阿里通義 Qwen3 快速部署
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 第9期:2025.04.21--2025.04.25
阿里云開源視覺語言大模型Qwen-VL ,支持圖文雙模態輸入
2024 WAIC智能芯片及多模態大模型論壇丨愛芯通元AI處理器助力打造普惠智能

通義千問發布第二代視覺語言模型Qwen2-VL
利用OpenVINO部署Qwen2多模態模型
PerfXCloud重磅升級 阿里開源最強視覺語言模型Qwen2-VL-7B強勢上線!
阿里云開源Qwen2.5-Coder代碼模型系列
阿里云發布開源多模態推理模型QVQ-72B-Preview
利用英特爾OpenVINO在本地運行Qwen2.5-VL系列模型
基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型







 工商網監
工商網監
評論