 基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型
基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型
多模態理解模型是讓AI像人類一樣,通過整合多維度信息(如視覺、語言、聽覺等),理解數據背后的語義、情感、邏輯或場景,從而完成推理、決策等任務。
當前已經進入多模態理解大模型發展的快車道,2025年2月,最新一代的多模態理解模型Qwen2.5VL開源發布,其在多個基準測試中取得了SOTA效果,更是直接登頂司南(OpenCompass)排行榜,甚至超越國內外知名的GPT-4o和Gemini-2.0等閉源模型。
MindSpeed MM開發團隊快速對Qwen2.5VL模型全系列尺寸進行適配,并將其正式開源在MindSpeed MM倉庫,同時支持視圖理解全參微調訓練、Lora微調訓練、在線推理和評測。
MindSpeed MM基于MindSpeed Core的多維并行能力實現對多模態模型的極致性能優化,更親和昇騰硬件,致力成為昇騰開發者大集群、大參數場景多模態訓練的首選,為開發者提供高效易用的開發體驗。
基于MindSpeed MM的Qwen2.5VL視圖理解生成體驗
新一代的多模態理解模型Qwen2.5VL有強大的視圖理解能力,讓我們快速體驗一下。
基于MindSpeed MM的Qwen2.5VL訓練優化特性
多模態理解模型主要處理如文本、圖像、音頻、視頻、傳感器信號等模態數據,不同模態數據存在結構差異、特征表示異質性、融合策略多樣性、訓練機制復雜性等特點,Qwen2.5VL訓練的性能瓶頸主要是負載不均衡問題。MindSpeed MM在使用融合算子、分布式優化器及流水調度優化等常用特性的基礎上,支持多模態異構流水線并行、動態流水線并行、數據分桶負載均衡等優化加速特性,實現訓練性能極致優化。
01多模態異構流水線并行,支持大規模數據的復雜多模態訓練,實現負載均衡
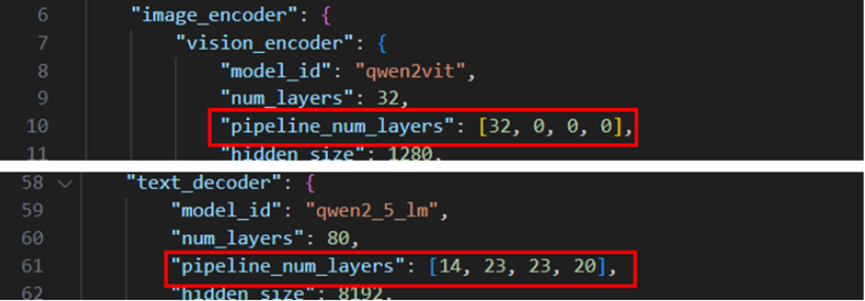
Qwen2.5VL模型包括視覺模塊、連接層以及語言模塊,其中視覺模塊的激活值比較大,當視覺模塊放開訓練或視圖數據規模較大時,會導致顯存占用過大甚至OOM,同時影響多卡之間的負載均衡。MindSpeed MM創新性地實現了異構流水線并行特性,支持各種模態模塊的快速流水線并行適配,支撐實現更復雜場景和更大數據規模的訓練微調,同時也緩解了負載不均衡的問題。
使用方式:在examples/qwen2.5vl/model_*b.json中配置vision_encoder和text_decoder中的pipeline_num_layers字段參數
02流水線并行動態shape通信支持,實現訓練效率和資源利用率雙提升
多模態場景中,batch內樣本長度要保持一致,需將所有輸入樣本都擴展到統一的序列長度,而不同樣本的序列長度差異較大,對于短序列的數據樣本會產生大量冗余計算、增加顯存占用和通信耗時。MindSpeed MM通過使用MindSpeed Core的動態shape流水線并行特性,減少過度擴展現象,有效降低冗余計算量,實現訓練效率與計算資源利用率雙提升,數據集序列長度差異越大,收益越大。
使用方式:在examples/qwen2.5vl/finetune_qwen2_5_vl_*b.sh的GPT_ARGS中加入--variable-seq-lengths參數。

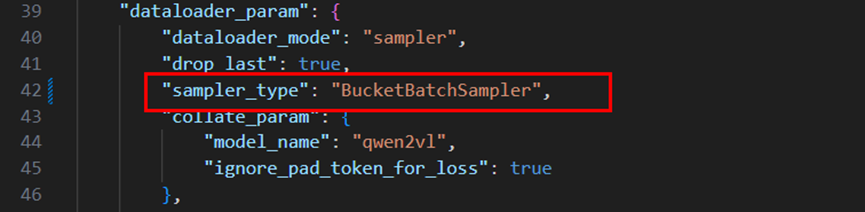
03數據分桶負載優化,實現多卡數據計算均衡,訓練效率提升10%+
多模態理解場景由于視圖數據的規模不一致,不同輸入數據長度差異很大,因此會導致大集群訓練微調過程中,不同卡之間的計算耗時差異大,出現卡間負載不均衡問題。MindSpeed MM中通過實現全局數據分桶重排,將不同序列長度的數據重新進行劃分,從而實現卡間的數據大小基本相同,保證訓練數據多樣性的同時訓練效率提升10%+。
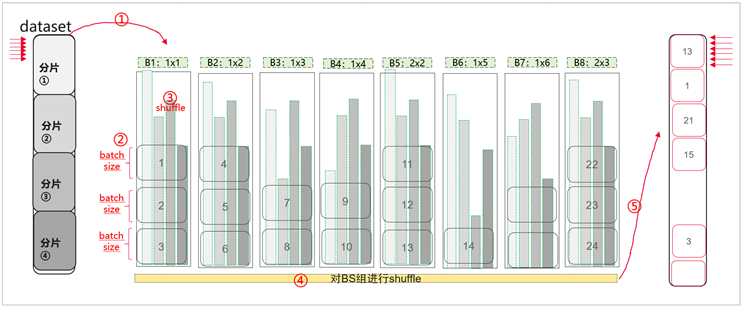
數據分桶負載:將數據按token數量
分配到不同的桶,訓練時按桶取數據
使用方式:在examples/qwen2.5vl/data_*b.json中,修改dataloader_param下的sampler_type為"BucketBatchSampler"
快速上手,基于MindSpeed MM玩轉Qwen2.5VL
環境安裝
模型開發時推薦使用配套的環境版本,詳見倉庫中的”環境安裝”
https://gitee.com/ascend/MindSpeed-MM/blob/master/examples/qwen2.5vl/README.md
倉庫拉取:
git clone https://gitee.com/ascend/MindSpeed-MM.git
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.8.0
cp -r megatron ../MindSpeed-MM/
cd ..
cd MindSpeed-MM
mkdir logs
mkdir data
mkdir ckpt
環境搭建:
torch npu 與 CANN包參考鏈接:安裝包參考鏈接
https://gitee.com/link?target=https%3A%2F%2Fsupport.huawei.com%2Fenterprise%2Fzh%2Fascend-computing%2Fcann-pid-251168373%2Fsoftware
# python3.10
conda create -ntestpython=3.10
conda activatetest
#安裝torch和torch_npu,注意要選擇對應python版本、x86或arm的torch、torch_npu及apex包
#下載路徑參考https://www.hiascend.com/document/detail/zh/Pytorch/60RC3/configandinstg/instg/insg_0001.html
pip install torch-2.1.0-cp310-cp310m-manylinux2014_aarch64.whl
pip install torch_npu-2.1.0*-cp310-cp310m-linux_aarch64.whl
# apex for Ascend參考https://gitee.com/ascend/apex
#建議從原倉編譯安裝
#安裝加速庫
gitclonehttps://gitee.com/ascend/MindSpeed.git
cdMindSpeed
# checkout commit from MindSpeed core_r0.8.0
git checkout 3f09d6736571cf1e30f8ac97de77982d0ab32cc5
pip install -r requirements.txt
pip3 install -e .
cd..
#替換MindSpeed中的文件
cp examples/qwen2vl/dot_product_attention.py MindSpeed/mindspeed/core/transformer/dot_product_attention.py
#安裝其余依賴庫
pip install -e .
#安裝transformers指定版本
gitclonehttps://github.com/huggingface/transformers.git
cdtransformers
git checkout fa56dcc2a
pip install -e .
權重下載及轉換
Qwen2.5VL權重下載:
| 模型 | Huggingface下載鏈接 |
| 3B | https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct/tree/main |
| 7B | https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct/tree/main |
| 32B | https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct/tree/main |
| 72B | https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct/tree/main |
權重轉換:
MindSpeed MM修改了部分原始網絡的結構名稱,使用mm-convert工具對原始預訓練權重進行轉換。該工具實現了huggingface權重和MindSpeed MM權重的互相轉換以及PP(Pipeline Parallel)權重的重切分。
# 3b
mm-convert Qwen2_5_VLConverter hf_to_mm
--cfg.mm_dir"ckpt/mm_path/Qwen2.5-VL-3B-Instruct"
--cfg.hf_config.hf_dir"ckpt/hf_path/Qwen2.5-VL-3B-Instruct"
--cfg.parallel_config.llm_pp_layers [36]
--cfg.parallel_config.vit_pp_layers [32]
--cfg.parallel_config.tp_size 1
# 7b
mm-convert Qwen2_5_VLConverter hf_to_mm
--cfg.mm_dir"ckpt/mm_path/Qwen2.5-VL-7B-Instruct"
--cfg.hf_config.hf_dir"ckpt/hf_path/Qwen2.5-VL-7B-Instruct"
--cfg.parallel_config.llm_pp_layers [1,10,10,7]
--cfg.parallel_config.vit_pp_layers [32,0,0,0]
--cfg.parallel_config.tp_size 1
# 32b
mm-convert Qwen2_5_VLConverter hf_to_mm
--cfg.mm_dir "ckpt/mm_path/Qwen2.5-VL-32B-Instruct"
--cfg.hf_config.hf_dir "ckpt/hf_path/Qwen2.5-VL-32B-Instruct"
--cfg.parallel_config.llm_pp_layers [4,9,9,9,9,9,9,6]
--cfg.parallel_config.vit_pp_layers [32,0,0,0,0,0,0,0]
--cfg.parallel_config.tp_size 2
# 72b
mm-convert Qwen2_5_VLConverter hf_to_mm
--cfg.mm_dir"ckpt/mm_path/Qwen2.5-VL-72B-Instruct"
--cfg.hf_config.hf_dir"ckpt/hf_path/Qwen2.5-VL-72B-Instruct"
--cfg.parallel_config.llm_pp_layers [14,23,23,20]
--cfg.parallel_config.vit_pp_layers [32,0,0,0]
--cfg.parallel_config.tp_size 8
#其中:
# mm_dir:轉換后保存目錄
# hf_dir: huggingface權重目錄
# llm_pp_layers: llm在每個卡上切分的層數,注意要和model.json中配置的pipeline_num_layers一致
# vit_pp_layers: vit在每個卡上切分的層數,注意要和model.json中配置的pipeline_num_layers一致
# tp_size: tp并行數量,注意要和微調啟動腳本中的配置一致
如果需要用轉換后模型訓練的話,同步修改
examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh中的LOAD_PATH參數,該路徑為轉換后或者切分后的權重,注意與原始權重ckpt/hf_path/Qwen2.5-VL-7B-Instruct進行區分。
LOAD_PATH="ckpt/mm_path/Qwen2.5-VL-7B-Instruct"
【數據集準備及處理】
數據集下載(以coco2017數據集為例):
(1)用戶需要自行下載COCO2017數據集,并解壓到項目目錄下的./data/COCO2017文件夾中
下載鏈接:https://gitee.com/link?target=https%3A%2F%2Fcocodataset.org%2F%23download
(2)獲取圖片數據集的描述文件(LLaVA-Instruct-150K),下載至./data/路徑下;
https://gitee.com/link?target=https%3A%2F%2Fhuggingface.co%2Fdatasets%2Fliuhaotian%2FLLaVA-Instruct-150K%2Ftree%2Fmain
(3)在./data路徑下新建文件mllm_format_llava_instruct_data.json,運行數據轉換腳本python examples/qwen2vl/llava_instruct_2_mllm_demo_format.py;
$playground
├── data
├── COCO2017
├── train2017
├── llava_instruct_150k.json
├── mllm_format_llava_instruct_data.json
...
當前支持讀取多個以,(注意不要加空格)分隔的數據集,配置方式為data.json中 dataset_param->basic_parameters->dataset 從"./data/mllm_format_llava_instruct_data.json"修改為"./data/mllm_format_llava_instruct_data.json,./data/mllm_format_llava_instruct_data2.json"
同時注意data.json中dataset_param->basic_parameters->max_samples的配置,會限制數據只讀max_samples條,這樣可以快速驗證功能。如果正式訓練時,可以把該參數去掉則讀取全部的數據。
純文本或有圖無圖混合訓練數據(以LLaVA-Instruct-150K為例):
現在本框架已經支持純文本/混合數據(有圖像和無圖像數據混合訓練)。在數據構造時,對于包含圖片的數據,需要保留image這個鍵值。
{
"id": your_id,
"image": your_image_path,
"conversations": [
{"from":"human","value": your_query},
{"from":"gpt","value": your_response},
],
}
在數據構造時,對于純文本數據,可以去除image這個鍵值。
{
"id": your_id,
"conversations": [
{"from":"human","value": your_query},
{"from":"gpt","value": your_response},
],
}
【微調】
1. 準備工作
配置腳本前需要完成前置準備工作,包括:環境安裝、權重下載及轉換、數據集準備及處理,詳情可查看對應章節。
2. 配置參數
數據目錄配置:
根據實際情況修改data.json中的數據集路徑,包括model_name_or_path、dataset_dir、dataset等字段。
以Qwen2.5VL-7B為例,data.json進行以下修改,注意model_name_or_path的權重路徑為轉換前的權重路徑。
注意cache_dir在多機上不要配置同一個掛載目錄避免寫入同一個文件導致沖突。
{
"dataset_param": {
"dataset_type": "huggingface",
"preprocess_parameters": {
"model_name_or_path": "./ckpt/hf_path/Qwen2.5-VL-7B-Instruct",
...
},
"basic_parameters": {
...
"dataset_dir": "./data",
"dataset": "./data/mllm_format_llava_instruct_data.json",
"cache_dir": "./data/cache_dir",
...
},
...
},
...
}
}
模型保存加載及日志信息配置:
根據實際情況配置examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh的參數,包括加載、保存路徑以及保存間隔--save-interval(注意:分布式優化器保存文件較大耗時較長,請謹慎設置保存間隔)
...
#加載路徑
LOAD_PATH="ckpt/mm_path/Qwen2.5-VL-7B-Instruct"
#保存路徑
SAVE_PATH="save_dir"
...
GPT_ARGS="
...
--no-load-optim #不加載優化器狀態,若需加載請移除
--no-load-rng #不加載隨機數狀態,若需加載請移除
--no-save-optim #不保存優化器狀態,若需保存請移除
--no-save-rng #不保存隨機數狀態,若需保存請移除
...
"
...
OUTPUT_ARGS="
--log-interval 1 #日志間隔
--save-interval 5000 #保存間隔
...
--log-tps #增加此參數可使能在訓練中打印每步語言模塊的平均序列長度,并在訓練結束后計算每秒吞吐tokens量。
"
若需要加載指定迭代次數的權重、優化器等狀態,需將加載路徑LOAD_PATH設置為保存文件夾路徑LOAD_PATH="save_dir",并修改latest_checkpointed_iteration.txt文件內容為指定迭代次數 (此功能coming soon)
$save_dir
├── latest_checkpointed_iteration.txt
├── ...
單機運行配置:
配置examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh參數如下
#根據實際情況修改 ascend-toolkit 路徑
source /usr/local/Ascend/ascend-toolkit/set_env.sh
NPUS_PER_NODE=8
MASTER_ADDR=locahost
MASTER_PORT=29501
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($NPUS_PER_NODE * $NNODES))
注意,當開啟PP時,model.json中配置的vision_encoder和text_decoder的pipeline_num_layer參數控制了各自的PP切分策略。對于流水線并行,要先處理vision_encoder再處理text_decoder。 比如7b默認的值[32,0,0,0]、[1,10,10,7],其含義為PP域內第一張卡先放32層vision_encoder再放1層text_decoder、第二張卡放text_decoder接著的10層、第三張卡放text_decoder接著的10層、第四張卡放text_decoder接著的7層,vision_encoder沒有放完時不能先放text_decoder(比如[30,2,0,0]、[1,10,10,7]的配置是錯的)。
同時注意,如果某張卡上的參數全部凍結時會導致沒有梯度(比如vision_encoder凍結時PP配置[30,2,0,0]、[0,11,10,7]),需要在finetune_qwen2_5_vl_7b.sh中GPT_ARGS參數中增加--enable-dummy-optimizer,
3. 啟動微調
以Qwen2.5VL-7B為例,啟動微調訓練任務。
bash examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh
【性能實測:昇騰硬件加速提升性能】
備注:Samples per Second 為 (SPS)
| 模型尺寸 | 任務類型 | 訓練規模(A2) | 混精類型 | 性能 |
| 3B | 微調 | 單機8卡 | bf16 | 23.771(SPS) |
| 7B | 微調 | 單機8卡 | bf16 | 14.204(SPS) |
| 32B | 微調 | 雙機16卡 | bf16 | 6.755(SPS) |
| 72B | 微調 | 4機32卡 | bf16 | 4.669(SPS) |
【更多參數見MindSpeed MM倉庫】
準備工作和參數說明見MindSpeed MM開源代碼倉鏈接:
https://gitee.com/ascend/MindSpeed-MM/tree/master/examples/qwen2.5vl
結語
MindSpeed MM是面向大規模分布式訓練的昇騰多模態大模型套件,同時支持多模態生成及多模態理解,旨在為華為昇騰芯片提供端到端的多模態訓練解決方案, 包含預置業界主流模型,數據工程,分布式訓練及加速,預訓練、微調、在線推理任務等特性。
MindSpeed MM即將上線更加豐富的支持Qwen2.5VL模型的特性,敬請期待。
-
AI
+關注
關注
87文章
34150瀏覽量
275323 -
開源
+關注
關注
3文章
3582瀏覽量
43467 -
模型
+關注
關注
1文章
3483瀏覽量
49980 -
Mindspeed
+關注
關注
1文章
15瀏覽量
9238
原文標題:多模態理解SOTA模型開箱即用,MindSpeed MM支持Qwen2.5-VL最佳實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一文理解多模態大語言模型——上

愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

阿里云開源視覺語言大模型Qwen-VL ,支持圖文雙模態輸入
蘋果發布300億參數MM1多模態大模型
商湯科技推出SenseFoundry-VL方舟多模態新智平臺


通義千問發布第二代視覺語言模型Qwen2-VL
號稱全球最強開源模型 ——Qwen2.5 系列震撼來襲!PerfXCloud同步上線,快來體驗!
利用OpenVINO部署Qwen2多模態模型
PerfXCloud重磅升級 阿里開源最強視覺語言模型Qwen2-VL-7B強勢上線!
阿里云開源Qwen2.5-Coder代碼模型系列

阿里云通義Qwen2.5-Max模型全新升級
利用英特爾OpenVINO在本地運行Qwen2.5-VL系列模型





 工商網監
工商網監
評論