 一文理解多模態大語言模型——下
一文理解多模態大語言模型——下
?
作者:Sebastian Raschka 博士,
翻譯:張晶,Linux Fundation APAC Open Source Evangelist
編者按:本文并不是逐字逐句翻譯,而是以更有利于中文讀者理解的目標,做了刪減、重構和意譯,并替換了多張不適合中文讀者的示意圖。
原文地址:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
《一文理解多模態大語言模型 - 上》介紹了什么是多模態大語言模型,以及構建多模態 LLM 有兩種主要方式之一:統一嵌入解碼器架構(Unified Embedding Decoder Architecture)。本文將接著介紹第二種構建多模態 LLM 的方式:跨模態注意架構(Cross-modality Attention Architecture approach)。
一,跨模態注意架構
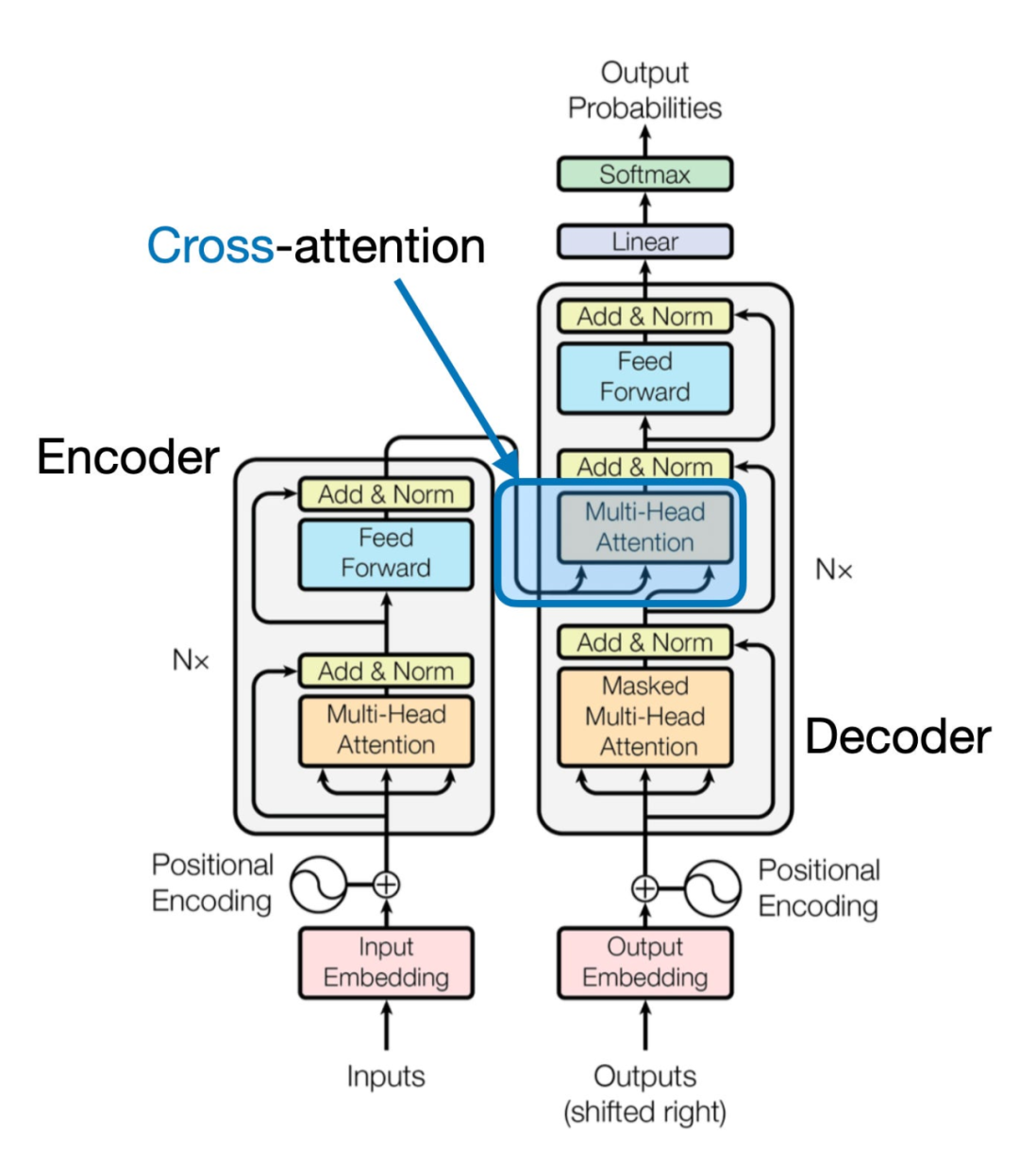
《一文理解多模態大語言模型 - 上》討論了通過統一嵌入解碼器架構來構建多模態大語言模型(LLM)的方法,并且理解了圖像編碼背后的基本概念,下面介紹另一種通過交叉注意力機制實現多模態LLM的方式,如下圖所示:

在上圖所示的跨模態注意力架構方法中,我們仍然使用之前介紹的圖像向量化方式。然而,與直接將圖像向量作為LLM的輸入不同,我們通過交叉注意力機制在多頭注意力層中連接輸入的圖像向量。
這個想法與2017年《Attention Is All You Need》論文中提出的原始Transformer架構相似,在原始《Attention Is All You Need》論文中的Transformer最初是為語言翻譯開發的。因此,它由一個文本編碼器(下圖的左部分)組成,該編碼器接收要翻譯的句子,并通過一個文本解碼器(圖的右部分)生成翻譯結果。在多模態大語言模型的背景下,圖的右部分的編碼器由之前的文本編碼器,更換為圖像編碼器(圖像編碼后的向量)。
文本和圖像在進入大語言模型前都編碼為嵌入維度和尺寸(embedding dimensions and size)一致的向量。
“我們可以把多模態大語言模型看成“翻譯”文本和圖像,或文本和其它模態數據 --- 譯者。”
二,統一解碼器和交叉注意力模型訓練
與傳統僅文本的大語言模型(LLM)的開發類似,多模態大語言模型的訓練也包含兩個階段:預訓練和指令微調。然而,與從零開始不同,多模態大語言模型的訓練通常以一個預訓練過且已經過指令微調的大語言模型作為基礎模型。
對于圖像編碼器,通常使用CLIP,并且在整個訓練過程中往往保持不變,盡管也存在例外,我們稍后會探討這一點。在預訓練階段,保持大語言模型部分凍結也是常見的做法,只專注于訓練投影器(Projector)——一個線性層或小型多層感知器。鑒于投影器的學習能力有限,通常只包含一兩層,因此在多模態指令微調(第二階段)期間,大語言模型通常會被解凍,以允許進行更全面的更新。然而,需要注意的是,在基于交叉注意力機制的模型(方法B)中,交叉注意力層在整個訓練過程中都是解凍的。
在介紹了兩種主要方法(方法A:統一嵌入解碼器架構和方法B:跨模態注意力架構)之后,你可能會好奇哪種方法更有效。答案取決于具體的權衡:
統一嵌入解碼器架構(方法A)通常更容易實現,因為它不需要對LLM架構本身進行任何修改。
跨模態注意力架構(方法B)通常被認為在計算上更高效,因為它不會通過額外的圖像分詞(Token)來過載輸入上下文,而是在后續的交叉注意力層中引入這些標記。此外,如果在訓練過程中保持大語言模型參數凍結,這種方法還能保持原始大語言模型的僅文本性能。
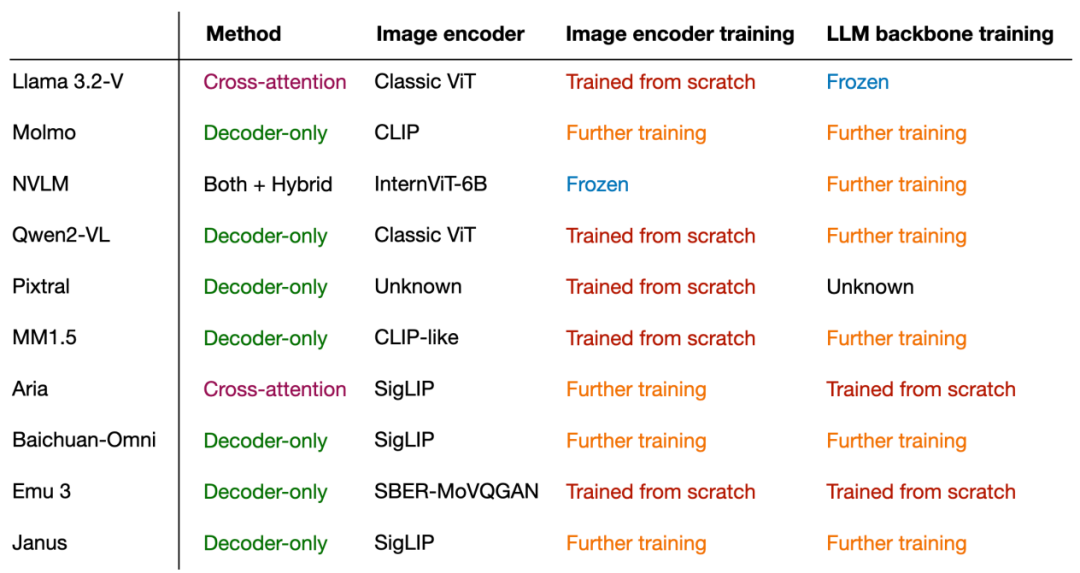
下圖總結了常見多模態大語言模型使用的組件和技術:
三,總結
“多模態LLM可以通過多種不同的方式成功構建,核心思路在于把多模態數據編碼為嵌入維度和尺寸一致的向量,使得原始大語言模型可以對多模態數據“理解并翻譯”。--- 譯者”。
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:[email protected]
更多精彩內容請關注“算力魔方?”!
?審核編輯 黃宇
-
語言模型
+關注
關注
0文章
558瀏覽量
10668 -
LLM
+關注
關注
1文章
319瀏覽量
679
發布評論請先 登錄
一文理解多模態大語言模型——上


更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
DreamLLM:多功能多模態大型語言模型,你的DreamLLM~

機器人基于開源的多模態語言視覺大模型

韓國Kakao宣布開發多模態大語言模型“蜜蜂”
李未可科技正式推出WAKE-AI多模態AI大模型








 工商網監
工商網監
評論