") 武大+上交提出BatGPT:創(chuàng)新性采用雙向自回歸架構(gòu),可預(yù)測(cè)前后token
武大+上交提出BatGPT:創(chuàng)新性采用雙向自回歸架構(gòu),可預(yù)測(cè)前后token
本論文介紹了一種名為BATGPT的大規(guī)模語(yǔ)言模型,由武漢大學(xué)和上海交通大學(xué)聯(lián)合開(kāi)發(fā)和訓(xùn)練。

該模型采用雙向自回歸架構(gòu),通過(guò)創(chuàng)新的參數(shù)擴(kuò)展方法和強(qiáng)化學(xué)習(xí)方法來(lái)提高模型的對(duì)齊性能,從而更有效地捕捉自然語(yǔ)言的復(fù)雜依賴關(guān)系。

BATGPT在語(yǔ)言生成、對(duì)話系統(tǒng)和問(wèn)答等任務(wù)中表現(xiàn)出色,是一種高效且多用途的語(yǔ)言模型。
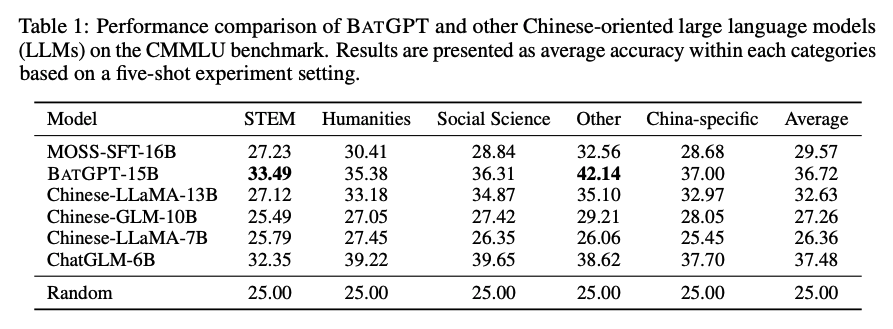
BATGPT 的雙向自回歸架構(gòu)如何幫助其捕獲自然語(yǔ)言的復(fù)雜依賴關(guān)系?
BATGPT的雙向自回歸架構(gòu)可以同時(shí)考慮輸入序列的前后文信息,從而更好地捕捉自然語(yǔ)言的復(fù)雜依賴關(guān)系。
傳統(tǒng)的自回歸模型只能考慮輸入序列的前面部分,而BATGPT的雙向自回歸架構(gòu)可以同時(shí)考慮前面和后面的信息,從而更好地理解整個(gè)輸入序列的語(yǔ)義。
這種架構(gòu)可以有效地解決傳統(tǒng)模型中存在的“有限記憶”和“幻覺(jué)”問(wèn)題,提高模型的生成質(zhì)量和對(duì)齊性能。
BATGPT在訓(xùn)練方面提出的參數(shù)擴(kuò)展方法是什么,它是如何提高模型有效性的?
BATGPT在訓(xùn)練方面提出了一種參數(shù)擴(kuò)展方法,即在較小的模型上進(jìn)行預(yù)訓(xùn)練,然后將預(yù)訓(xùn)練的參數(shù)擴(kuò)展到更大的模型中。
這種方法可以有效地利用較小模型的預(yù)訓(xùn)練參數(shù),從而加速更大模型的訓(xùn)練過(guò)程,并提高模型的有效性。
此外,BATGPT還采用了強(qiáng)化學(xué)習(xí)方法,從AI和人類反饋中學(xué)習(xí),以進(jìn)一步提高模型的對(duì)齊性能。這些方法的結(jié)合可以顯著提高BATGPT的生成質(zhì)量和對(duì)齊性能,使其成為一種高效且多用途的語(yǔ)言模型。
BATGPT 是否可以用于語(yǔ)言生成、對(duì)話系統(tǒng)和問(wèn)答之外的應(yīng)用程序?
BATGPT表現(xiàn)穩(wěn)健,能夠處理不同類型的提示,因此它具有廣泛的能力,并適用于廣泛的應(yīng)用程序。
雖然文中沒(méi)有明確提到BATGPT是否可以用于語(yǔ)言生成、對(duì)話系統(tǒng)和問(wèn)答之外的應(yīng)用程序,但是它的廣泛能力表明它可以用于其他類型的應(yīng)用程序。
-
應(yīng)用程序
+關(guān)注
關(guān)注
38文章
3322瀏覽量
58726 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10670 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11517
原文標(biāo)題:武大+上交提出 BatGPT:創(chuàng)新性采用雙向自回歸架構(gòu),可預(yù)測(cè)前后token
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
設(shè)備遠(yuǎn)程監(jiān)控與預(yù)測(cè)性維護(hù)系統(tǒng)架構(gòu)設(shè)計(jì)及應(yīng)用實(shí)踐

Token經(jīng)濟(jì),風(fēng)起隴東

基于移動(dòng)自回歸的時(shí)序擴(kuò)散預(yù)測(cè)模型
基于RK3568國(guó)產(chǎn)處理器教學(xué)實(shí)驗(yàn)箱操作案例分享:一元線性回歸實(shí)驗(yàn)
基于risc-v架構(gòu)的芯片與linux系統(tǒng)兼容性討論
什么是回歸測(cè)試_回歸測(cè)試的測(cè)試策略
一種創(chuàng)新的動(dòng)態(tài)軌跡預(yù)測(cè)方法
RISC--V架構(gòu)的目標(biāo)和特點(diǎn)
零漂移、雙向電流檢測(cè)放大器AiP8181可替代可兼容INA181






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論