 火山引擎:ClickHouse增強計劃之“多表關聯查詢”
火山引擎:ClickHouse增強計劃之“多表關聯查詢”
相信大家都對大名鼎鼎的ClickHouse有一定的了解了,它強大的數據分析性能讓人印象深刻。但在字節大量生產使用中,發現了ClickHouse依然存在了一定的限制。例如:
? 缺少完整的upsert和delete操作
? 多表關聯查詢能力弱
? 集群規模較大時可用性下降(對字節尤其如此)
? 沒有資源隔離能力
因此,我們決定將ClickHouse能力進行全方位加強,打造一款更強大的數據分析平臺。后面我們將從五個方面來和大家分享,此前為大家介紹了字節是如何為ClickHouse補全更新刪除能力的,本篇將詳細介紹我們是如何加強ClickHouse多表關聯查詢能力。
大寬表的局限
數據分析的發展歷程,可以看作是不斷追求分析效率和分析靈活的過程。分析效率是非常重要的,但是并不是需要無限提升的。1秒返回結果和1分鐘返回結果的體驗是天壤之別,但是0.1秒返回結果和1秒返回結果的差距就沒那么大了。因此,在滿足了一定時效的情況下,分析的靈活性就顯得額外重要了。
起初,數據分析都采用了固定報表的形式,格式更新頻率低,依賴定制化的開發,查詢邏輯是寫死的。對于業務和數據需求相對穩定、不會頻繁變化的場景來說固定報表確實就足夠了,但是以如今的視角來看,完全固定的查詢邏輯不能充分發揮數據的價值,只有通過靈活的數據分析,才能幫助業務人員化被動為主動,探索各數據間的相關關系,快速找到問題背后的原因,極大地提升工作效率。。
后面,基于預計算思想的cube建模方案被提出。通過將數據ETL加工后存儲在cube中,保證領導和業務人員能夠快速得到分析結果基礎上,獲得了一定的分析靈活性。不過由于維度固定,以及數據聚合后基本無法查詢明細數據,依然無法滿足Adhoc這類即席查詢的場景需求。
近些年,以ClickHouse為代表的具備強大單表性能的查詢引擎,帶來了大寬表分析的風潮。所謂的大寬表,就是在數據加工的過程中,將多張表通過一些關聯字段打平成一張寬表,通過一張表對外提供分析能力。基于ClickHouse單表性能支撐的大寬表模式,既能提升分析時效性又能提高數據查詢和分析操作的靈活性,是目前非常流行的一種模式。
然而大寬表依然有它的局限性,具體有:
? 生成每一張大寬表都需要數據開發人員不小的工作量,而且生成過程也需要一定的時間
? 生成寬表會產生大量的數據冗余
剛才有提到,數據分析的發展歷程可以看作是不斷追求分析效率和分析靈活的過程,那么大寬表的下一個階段呢?如果ClickHouse的多表關聯查詢能力足夠強,是不是連“將數據打平成寬表”這個步驟也可以省略,只需要維護好對外服務的接口,任何業務人員的需求都現場直接關聯查詢就可以了呢?
ByteHouse是如何強化多表關聯查詢能力的?
ClickHouse 的執行模式相對比較簡單,其基本查詢模式分為 2 個階段:
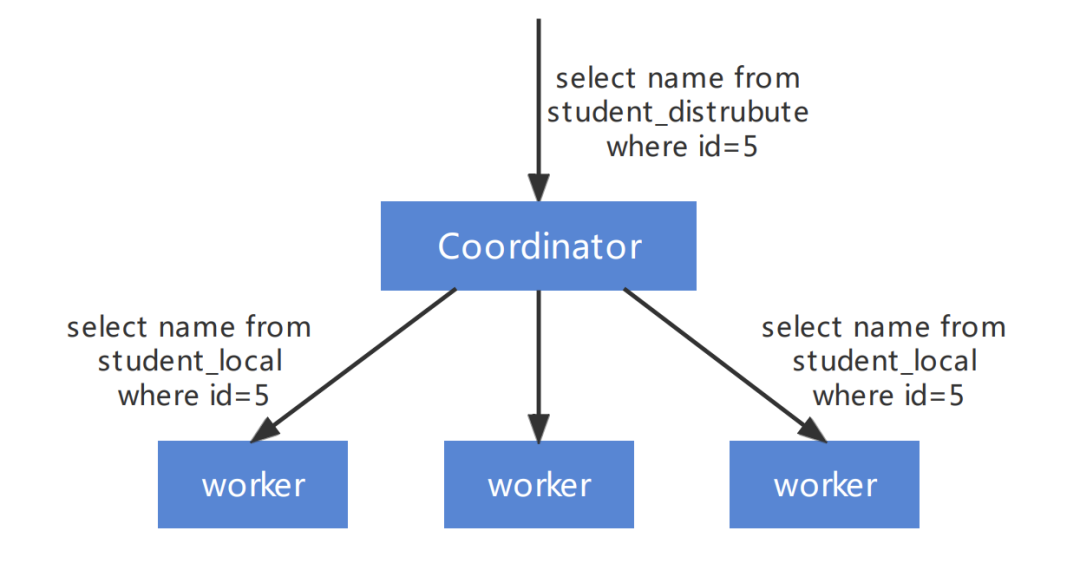
ByteHouse 進行多表關聯的復雜查詢時,采用分 Stage 的方式,替換目前 ClickHouse的2階段執行方式。將一個復雜的 Query 按照數據交換情況切分成多個 Stage,Stage 和 Stage 之間通過 exchange 完成數據的交換,單個 Stage 內不存在數據交換。Stage 間的數據交換主要有以下三種形式:
? 按照單(多)個 key 進行 Shuffle
? 由 1 個或者多個節點匯聚到一個節點 (我們稱為 gather)
? 同一份數據復制到多個節點(也稱為 broadcast 或者說廣播)
單個 Stage 執行會繼續復用 ClickHouse 的底層的執行方式。
按照不同的功能切分不同的模塊,設計目標如下:
各個模塊約定好接口,盡量減少彼此的依賴和耦合。一旦某個模塊有變動不會影響別的模塊,例如 Stage 生成邏輯的調整不影響調度的邏輯。
模塊采用插件的架構,允許模塊根據配置靈活支持不同的策略。
根據數據的規模和分布,ByteHouse支持了多種關聯查詢的實現,目前已經支持的有:
Shuffle Join,最通用的 Join
Broadcast Join,針對大表 Join 小表的場景,通過把右表廣播到左表的所有 worker 節點來減少左表的傳輸
Colocate Join,針對左右表按照 Join key 保持相通分布的場景,減少左右表數據傳輸
Join 算子通常是 OLAP 引擎中最耗時的算子。如果想優化 Join 算子,可以有兩種思路,一方面可以提升 Join 算子的性能,例如更好的 Hash Table 實現和 Hash 算法,以及更好的并行。另一方面可以盡可能減少參與 Join 計算的數據。
Runtime Filter 在一些場景特別是事實表 join 維度表的星型模型場景下會有比較大的效果。因為這種情況下通常事實表規模比較大,而大部分過濾條件都在維度表上,事實表可能要全量 join 維度表。Runtime Filter 的作用是通過在 Join 的 probe 端(就是左表)提前過濾掉那些不會命中 Join 的輸入數據來大幅減少 Join 中的數據傳輸和計算,從而減少整體的執行時間。以下圖為例,
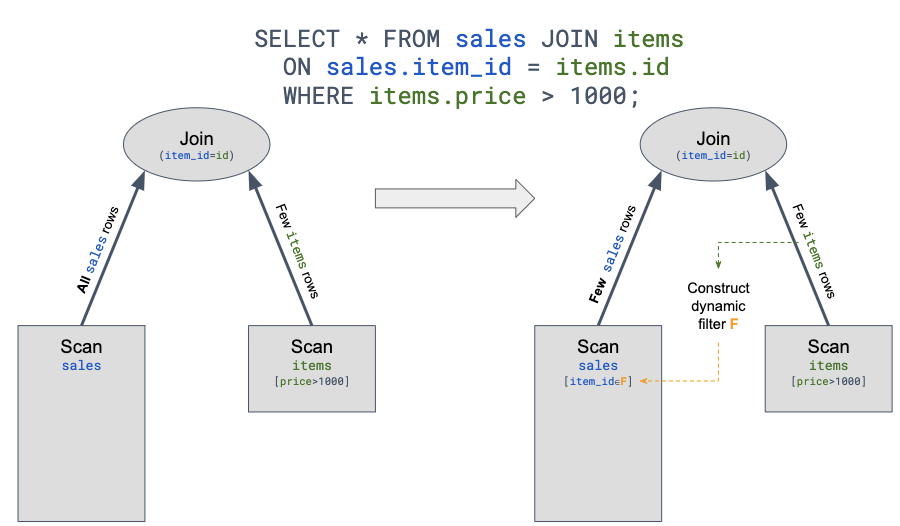
改善后的效果
以SSB 100G測試集為例,不把數據打成大寬表的情況下,分別使用 ClickHouse 22.2.3.1版本和ByteHouse 2.0.1版本,在相同硬件環境下進行測試。(無數據表示無法返回結果或超過60s)
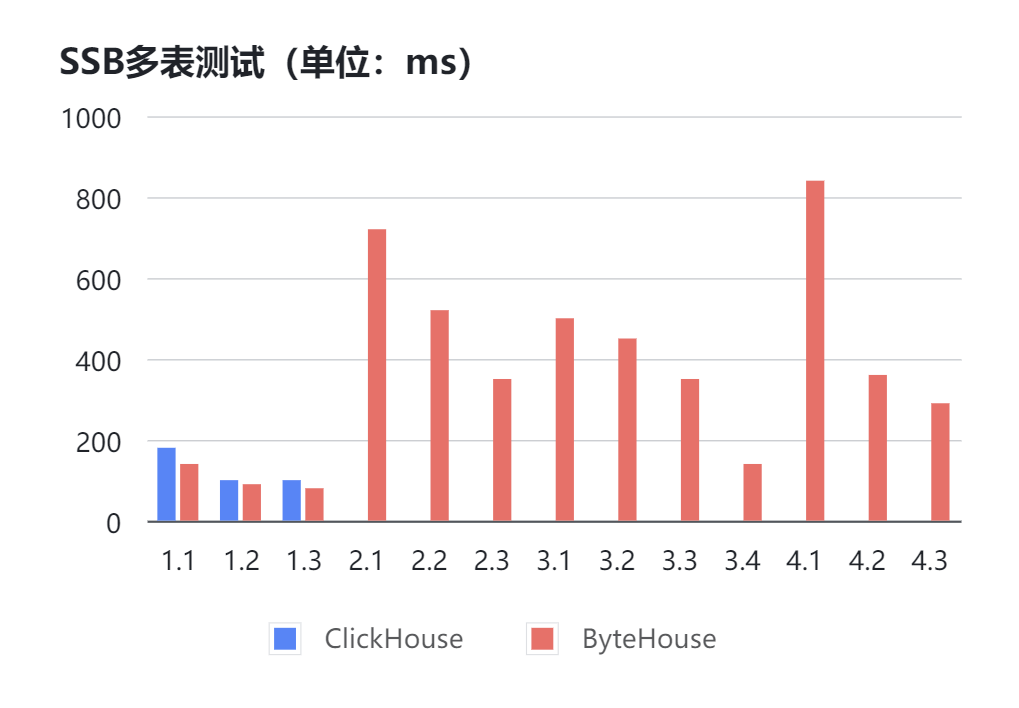
可以看到大多數測試中,ClickHouse都會發生報錯無法返回結果的情況,而ByteHouse能夠穩定的在1s內跑出結果。
只看SSB的多表測試有些抽象,下面從兩個具體的case來看一下優化后的效果:。
Case1:Hash Join 右表為大表
經過優化后,query 執行時間從17.210s降低至1.749s。
lineorder 是一張大表,通過 shuffle 可以將大表數據按照 join key shuffle 到每個 worker 節點,減少了右表構建的壓力。
SELECT sum(LO_REVENUE)-sum(LO_SUPPLYCOST)ASprofit FROM customer INNERJOIN ( SELECT LO_REVENUE, LO_SUPPLYCOST, LO_CUSTKEY from lineorder WHEREtoYear(LO_ORDERDATE)=1997andtoMonth(LO_ORDERDATE)=1 )aslineorder ONLO_CUSTKEY=C_CUSTKEY WHEREC_REGION='AMERICA'
Case 2:5張表 Join(未開啟runtime filter)
經優化后,query 執行時間從8.583s降低至4.464s。
所有的右表可同時開始數據讀取和構建。為了和現有模式做對比,ByteHouse這里并沒有開啟 runtime filter,開啟 runtime filter 后效果會更快。
SELECT D_YEAR, S_CITY, P_BRAND, sum(LO_REVENUE)-sum(LO_SUPPLYCOST)ASprofit FROMssb1000.lineorder INNERJOIN ( SELECTC_CUSTKEY FROMssb1000.customer WHEREC_REGION='AMERICA' )AScustomerONLO_CUSTKEY=C_CUSTKEY INNERJOIN ( SELECT D_DATEKEY, D_YEAR FROMdate WHERE(D_YEAR=1997)OR(D_YEAR=1998) )ASdatesONLO_ORDERDATE=toDate(D_DATEKEY) INNERJOIN ( SELECT S_SUPPKEY, S_CITY FROMssb1000.supplier WHERES_NATION='UNITEDSTATES' )ASsupplierONLO_SUPPKEY=S_SUPPKEY INNERJOIN ( SELECT P_PARTKEY, P_BRAND FROMssb1000.part WHEREP_CATEGORY='MFGR#14' )ASpartONLO_PARTKEY=P_PARTKEY GROUPBY D_YEAR, S_CITY, P_BRAND ORDERBY D_YEARASC, S_CITYASC, P_BRANDASC SETTINGSenable_distributed_stages=1,exchange_source_pipeline_threads=32
經過多表關聯查詢能力的增強,ByteHouse能夠更加全面的支撐各類業務,用戶可以根據場景選擇是否將數據打成大寬表,均能獲得非常良好的分析體驗。
之所以ByteHouse在多表關聯場景表現如此出色,其中一大原因就是因為字節自研了查詢優化器,彌補了社區ClickHouse的一大不足。查詢優化器都能帶來哪些體驗上的優化?字節是如何實現查詢優化器的?我們會在下一期為大家詳細介紹。
ByteHouse已經全面對外服務,并且提供各種版本以滿足不同類型用戶的需求。在ByteHouse官網上提交試用信息即可免費試用!
-
編程
+關注
關注
88文章
3679瀏覽量
94865 -
引擎
+關注
關注
1文章
366瀏覽量
22888 -
代碼
+關注
關注
30文章
4886瀏覽量
70253 -
數據分析
+關注
關注
2文章
1470瀏覽量
34797 -
Join
+關注
關注
0文章
9瀏覽量
3395
原文標題:火山引擎:ClickHouse增強計劃之“多表關聯查詢”
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Centos7下如何搭建ClickHouse列式存儲數據庫
基于多表的動態查詢模塊設計與實現

火山引擎:ClickHouse增強計劃之“Upsert”
ClickHouse增強計劃之“資源隔離”
如何使用原生ClickHouse函數和表引擎在兩個數據庫之間遷移數據
英特爾助力火山引擎 推動數據飛輪加速運轉

sql關聯查詢中的主表和從表
ClickHouse內幕(3)基于索引的查詢優化
中科創達與火山引擎達成深度合作
中科創達攜手火山引擎開啟AI智能座艙新體驗
賽思×字節跳動 高精度同步時鐘助力火山引擎打造“云上新宇宙”






 工商網監
工商網監
評論