在這些情況下, 傳感器自帶的噪聲、無紋理的黑暗區域和反光等不利因素都違反了基于監督和自監督學習方法的....
![的頭像]() CVer 發表于
CVer 發表于 09-04 16:14
?950次閱讀

為了讓大家更好的理解 Karpathy 的內容。我們先介紹一下「Speculative decodi....
![的頭像]() CVer 發表于
CVer 發表于 09-04 15:43
?987次閱讀
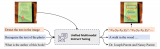
如上圖所示,UniDoc基于預訓練的視覺大模型及大語言模型,將文字的檢測、識別、spotting(圖....
![的頭像]() CVer 發表于
CVer 發表于 08-31 15:29
?1851次閱讀
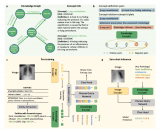
為了解決這一問題,我們系統地分析了前景和背景在圖像級跨域對齊中的重要性,并認識到在圖像級跨域對齊中,....
![的頭像]() CVer 發表于
CVer 發表于 08-30 15:30
?1084次閱讀

BEV自動駕駛感知好比一個從高處統觀全局的“上帝視角”,將三維環境信息投影到二維平面,以俯視視角展示....
![的頭像]() CVer 發表于
CVer 發表于 08-23 14:51
?1266次閱讀

根據這種方法,我們可以根據其他網絡的權重來訓練一個網絡,這也許是一個用來做持續學習的好方法。同樣有趣....
![的頭像]() CVer 發表于
CVer 發表于 08-21 14:55
?659次閱讀

隨著基于激光雷達(LiDAR)的三維物體檢測在機器人系統和自動駕駛汽車等各種應用中不斷發展,解決在實....
![的頭像]() CVer 發表于
CVer 發表于 08-18 15:19
?1296次閱讀

圖像分解致力于通過完備的監督信號還原出包括噪聲天氣在內的所有圖層,指向各圖層的 multi-head....
![的頭像]() CVer 發表于
CVer 發表于 08-15 15:16
?893次閱讀

人體神經輻射場的目標是從 2D 人體圖片中恢復高質量的 3D 數字人并加以驅動,從而避免耗費大量人力....
![的頭像]() CVer 發表于
CVer 發表于 08-15 11:46
?1010次閱讀

想要注意的是,模型和數據集的詳細信息并不是這里的主要關注點(它們只是為了盡可能簡單,以便讀者可以在自....
![的頭像]() CVer 發表于
CVer 發表于 08-14 13:07
?891次閱讀
SID[1] 首先提出一套完整的 benchmark 以及 dataset 進行RAW圖像低光增強或....
![的頭像]() CVer 發表于
CVer 發表于 08-11 15:47
?1939次閱讀

為實現模型性能和計算資源消耗、顯存消耗、推理時延之間的平衡,Focus-DETR 利用精細設計的前景....
![的頭像]() CVer 發表于
CVer 發表于 08-02 15:43
?787次閱讀

即便如此,傳統的 Transformer 依然存在局限。首要的一點,它們有著對于序列長度的二次時間復....
![的頭像]() CVer 發表于
CVer 發表于 07-31 15:20
?1379次閱讀

然而,這一假設在機器人部署中通常是難以滿足的,因為算法本身的延遲在機器人硬件上不可忽視,當算法完成當....
![的頭像]() CVer 發表于
CVer 發表于 07-19 16:06
?1015次閱讀

構建這種表征的一個重要挑戰是人體運動數據資源的異質性。運動捕捉(MoCap)系統提供了基于標記和傳感....
![的頭像]() CVer 發表于
CVer 發表于 07-19 14:23
?1210次閱讀

CLIP是一個通用的模型,考慮到下游數據分布的差異,對某個下游任務來說,CLIP提取的特征并不全是有....
![的頭像]() CVer 發表于
CVer 發表于 07-19 14:19
?2147次閱讀

如圖1(a)所示,遙感圖像中的物體檢測器所使用的有限范圍的背景往往會導致錯誤的分類。例如,在上層圖像....
![的頭像]() CVer 發表于
CVer 發表于 07-18 16:57
?1935次閱讀

人體動作預測是計算機視覺和圖形學中的一個經典問題,旨在提升預測結果的多樣性、準確性,并在自動駕駛、動....
![的頭像]() CVer 發表于
CVer 發表于 07-17 16:56
?897次閱讀

隨著基于廣泛數據訓練的大模型興起,上下文學習(In-Context Learning)已成為一種新的....
![的頭像]() CVer 發表于
CVer 發表于 07-13 14:41
?1151次閱讀

這一驚人效果來自于發表在SIGGRAPH 2023會議上的 [Drag Your GAN] 論文(簡....
![的頭像]() CVer 發表于
CVer 發表于 07-13 14:36
?646次閱讀
這個定律啟發了基于運動的無監督分割。然而,Common Fate并不是物體性質的可靠指標:關節可動 ....
![的頭像]() CVer 發表于
CVer 發表于 07-12 14:21
?934次閱讀

文章稱,他們從許多來源收集了大量有關 GPT-4 的信息,包括模型架構、訓練基礎設施、推理基礎設施、....
![的頭像]() CVer 發表于
CVer 發表于 07-12 14:16
?1105次閱讀

自 50 年前舉辦第一次會議以來, Technical Papers program 一直是 SIG....
![的頭像]() CVer 發表于
CVer 發表于 07-11 14:34
?1284次閱讀

接著,LLM(大語言模型)根據這些內容編寫代碼,所生成代碼與VLM(視覺語言模型)進行交互,指導系統....
![的頭像]() CVer 發表于
CVer 發表于 07-11 14:31
?1438次閱讀

但是因為當時的技術所限,做出來的效果不好,于是他和OpenAI就改變了方向,開始做大語言模型了。最簡....
![的頭像]() CVer 發表于
CVer 發表于 07-11 11:17
?827次閱讀
在半監督視頻對象分割(VOS)和視頻實例分割(VIS)方面,目前的主流方法處理未知數據時表現一般,是....
![的頭像]() CVer 發表于
CVer 發表于 07-10 15:28
?974次閱讀

VisProg目前支持20個模塊,可實現圖像理解、圖像操作(包括生成)、知識檢索和算術和邏輯操作等能....
![的頭像]() CVer 發表于
CVer 發表于 07-10 15:26
?909次閱讀

這篇論文揭示了 PaLM 或 GPT 在通過上下文學習解決視覺任務方面的能力,并提出了新方法 SPA....
![的頭像]() CVer 發表于
CVer 發表于 07-09 15:35
?1526次閱讀

? ? ? 近年來,基于大數據預訓練的多模態基礎模型 (Foundation Model) 在自然語....
![的頭像]() CVer 發表于
CVer 發表于 07-07 11:10
?1099次閱讀
過去業界也有推出一些數據集。他們主要有三個特點。第一個是數據規模小,第二個是都是基于GAN的,第三個....
![的頭像]() CVer 發表于
CVer 發表于 07-04 15:53
?813次閱讀






 工商網監
工商網監