") SAM-PT:點(diǎn)幾下鼠標(biāo),視頻目標(biāo)就分割出來了!
SAM-PT:點(diǎn)幾下鼠標(biāo),視頻目標(biāo)就分割出來了!
只要在視頻中點(diǎn)幾下鼠標(biāo),SAM-PT 就能分割并且追蹤物體的輪廓。

視頻分割在許多場(chǎng)景下被廣泛應(yīng)用。電影視覺效果的增強(qiáng)、自動(dòng)駕駛的理解場(chǎng)景,以及視頻會(huì)議中創(chuàng)建虛擬背景等等都需要應(yīng)用到視頻分割。近期,基于深度學(xué)習(xí)的視頻分割已經(jīng)有著不錯(cuò)的表現(xiàn)了,但這依舊是計(jì)算機(jī)視覺中一個(gè)具有挑戰(zhàn)性的話題。
在半監(jiān)督視頻對(duì)象分割(VOS)和視頻實(shí)例分割(VIS)方面,目前的主流方法處理未知數(shù)據(jù)時(shí)表現(xiàn)一般,是在零樣本情況下更是「一言難盡」。零樣本情況就是指,這些模型被遷移應(yīng)用到未經(jīng)過訓(xùn)練的視頻領(lǐng)域,并且這些視頻中包含訓(xùn)練之外的物體。而表現(xiàn)一般的原因就是沒有特定的視頻分割數(shù)據(jù)進(jìn)行微調(diào),這些模型就很難在各種場(chǎng)景中保持一致的性能。
克服這個(gè)難題,就需要將在圖像分割領(lǐng)域取得成功的模型應(yīng)用到視頻分割任務(wù)中。這就不得不提到 Segment Anything Model(SAM,分割一切模型)了。
SAM 是一個(gè)強(qiáng)大的圖像分割基礎(chǔ)模型,它在規(guī)模龐大的 SA-1B 數(shù)據(jù)集上進(jìn)行訓(xùn)練,這其中包含 1100 萬(wàn)張圖像和 10 億多個(gè)掩碼。大量的訓(xùn)練讓 SAM 了具備驚人的零樣本泛化能力。SAM 可以在不需要任何標(biāo)注的情況下,對(duì)任何圖像中的任何物體進(jìn)行分割,引起了業(yè)界的廣泛反響,甚至被稱為計(jì)算機(jī)視覺領(lǐng)域的 GPT。
盡管 SAM 在零樣本圖像分割上展現(xiàn)了巨大的能力,但它并非「天生」就適用于視頻分割任務(wù)。
最近研究人員已經(jīng)開始致力于將 SAM 應(yīng)用于視頻分割。雖然這些方法恢復(fù)了大部分分布內(nèi)數(shù)據(jù)的性能,但在零樣本情況下,它們還是無法保持 SAM 的原始性能。其他不使用 SAM 的方法,如 SegGPT,可以通過視覺 prompt 成功解決一些分割問題,但仍需要對(duì)第一幀視頻進(jìn)行掩碼注釋。這個(gè)問題在零樣本視頻分割中的關(guān)鍵難題。當(dāng)研究者試圖開發(fā)能夠容易地推廣到未見過的場(chǎng)景,并在不同的視頻領(lǐng)域持續(xù)提供高質(zhì)量分割的方法時(shí),這個(gè)難題就顯得更加「絆腳」。
現(xiàn)在,有研究者提出了 SAM-PT(Segment Anything Meets Point Tracking),這或許能夠?qū)Α附O腳石」的消除提供新的思路。

論文地址:https://arxiv.org/pdf/2307.01197
GitHub 地址:https://github.com/SysCV/sam-pt
如圖 1 所示,SAM-PT 第一種將稀疏點(diǎn)追蹤與 SAM 相結(jié)合用于視頻分割的方法。與使用以目標(biāo)為中心的密集特征匹配或掩碼傳播不同,這是一種點(diǎn)驅(qū)動(dòng)的方法。它利用嵌入在視頻中的豐富局部結(jié)構(gòu)信息來跟蹤點(diǎn)。因此,它只需要在第一幀中用稀疏點(diǎn)注釋目標(biāo)對(duì)象,并在未知對(duì)象上有更好的泛化能力,這一優(yōu)勢(shì)在 UVO 基準(zhǔn)測(cè)試中得到了證明。該方法還有助于保持 SAM 的固有靈活性,同時(shí)有效地?cái)U(kuò)展了它在視頻分割方面的能力。
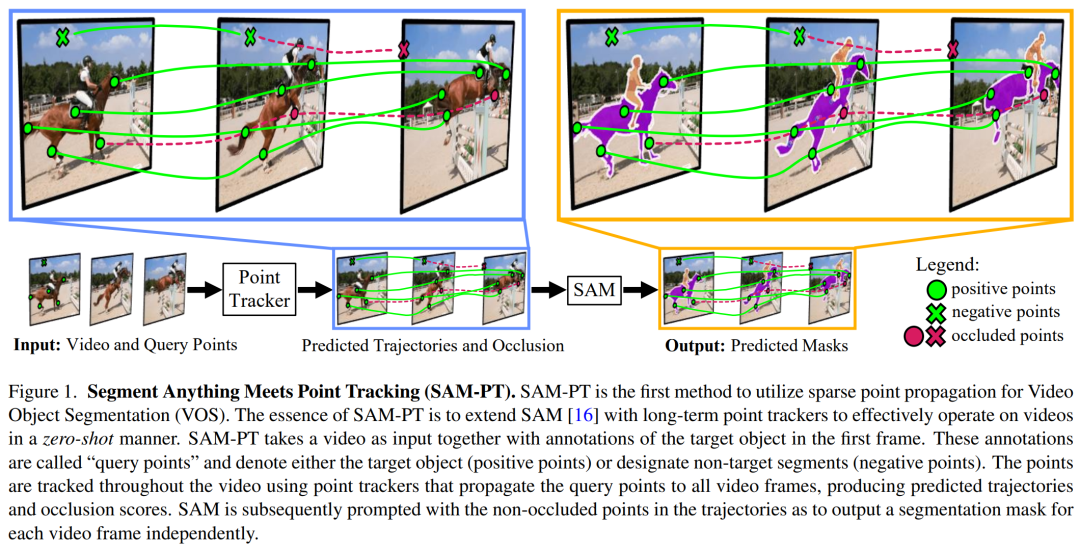
SAM-PT 使用最先進(jìn)的點(diǎn)追蹤器(如 PIPS)預(yù)測(cè)稀疏點(diǎn)軌跡,以此提示 SAM,利用其多功能性進(jìn)行視頻分割。研究人員發(fā)現(xiàn),使用來自掩碼標(biāo)簽的 K-Medoids 聚類中心來初始化跟蹤點(diǎn),是與提示 SAM 最兼容的策略。追蹤正反兩方面的點(diǎn)可以將目標(biāo)物體從其背景中清晰地劃分出來。
為了進(jìn)一步優(yōu)化輸出的掩碼,研究人員提出了多個(gè)掩碼解碼通道,將兩種類型的點(diǎn)進(jìn)行整合。此外,他們還設(shè)計(jì)了一種點(diǎn)重新初始化策略,隨著時(shí)間的推移提高了跟蹤的準(zhǔn)確性。這種方法包括丟棄變得不可靠或被遮擋的點(diǎn),并添加在后續(xù)幀 (例如當(dāng)物體旋轉(zhuǎn)時(shí)) 中變得可見的物體部分或部分的點(diǎn)。
值得注意的是,本文的實(shí)驗(yàn)結(jié)果表明,SAM-PT 在幾個(gè)視頻分割基準(zhǔn)上與現(xiàn)有的零樣本方法不相上下,甚至超過了它們。在訓(xùn)練過程中,SAM-PT 不需要任何視頻分割數(shù)據(jù),這證明了方法的穩(wěn)健性和適應(yīng)性。SAM-PT 具有增強(qiáng)視頻分割任務(wù)進(jìn)展的潛力,特別是在零樣本場(chǎng)景下。
SAM-PT 方法概覽
盡管 SAM 在圖像分割方面展示出令人印象深刻的能力,但其在處理視頻分割任務(wù)方面存在固有的局限性。我們提出的 "Segment Anything Meets Point Tracking"(SAM-PT)方法有效地將 SAM 擴(kuò)展到視頻領(lǐng)域,為視頻分割提供了強(qiáng)大的支持,而無需對(duì)任何視頻分割數(shù)據(jù)進(jìn)行訓(xùn)練。
如圖 2 所示,SAM-PT 主要由四個(gè)步驟組成:
1) 為第一幀選擇查詢點(diǎn);
2) 使用點(diǎn)跟蹤器,將這些點(diǎn)傳播到所有視頻幀;
3) 利用 SAM 生成基于傳播點(diǎn)的逐幀分割掩碼;
4) 通過從預(yù)測(cè)的掩碼中抽取查詢點(diǎn)來重新初始化這個(gè)過程。
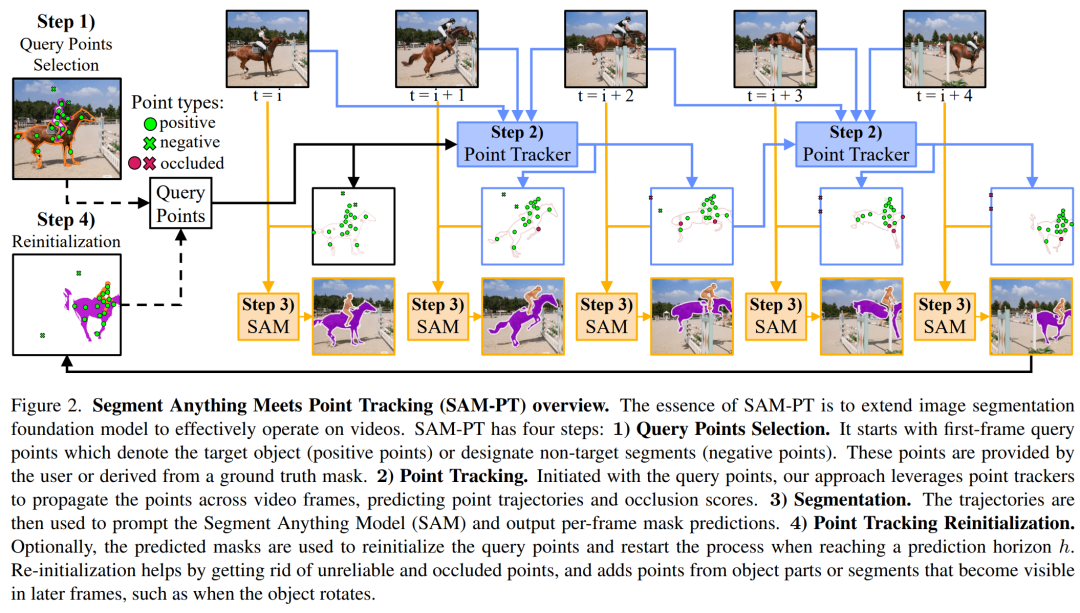
選擇查詢點(diǎn)。該過程的第一步是定義第一個(gè)視頻幀中的查詢點(diǎn)。這些查詢點(diǎn)要么表示目標(biāo)對(duì)象 (正點(diǎn)),要么指定背景和非目標(biāo)對(duì)象 (負(fù)點(diǎn))。用戶可以手動(dòng)、交互式地提供查詢點(diǎn),也可以從真實(shí)掩碼派生出查詢點(diǎn)。
考慮到它們的幾何位置或特征差異性,用戶可以使用不同的點(diǎn)采樣技術(shù)從真實(shí)掩碼中獲得查詢點(diǎn),如圖 3 所示。這些采樣技術(shù)包括:隨機(jī)采樣、K-Medoids 采樣、Shi-Tomasi 采樣和混合采樣。

點(diǎn)跟蹤。從查詢點(diǎn)開始,采用穩(wěn)健的點(diǎn)跟蹤器在視頻中的所有幀中傳播點(diǎn),從而得到點(diǎn)的軌跡和遮擋分?jǐn)?shù)。
采用最先進(jìn)的點(diǎn)跟蹤器 PIPS 來傳播點(diǎn),因?yàn)?PIPS 對(duì)長(zhǎng)期跟蹤挑戰(zhàn) (如目標(biāo)遮擋和再現(xiàn)) 顯示出適當(dāng)?shù)姆€(wěn)健性。實(shí)驗(yàn)也表明,這比鏈?zhǔn)焦饬鱾鞑セ虻谝粠瑢?duì)應(yīng)等方法更有效。
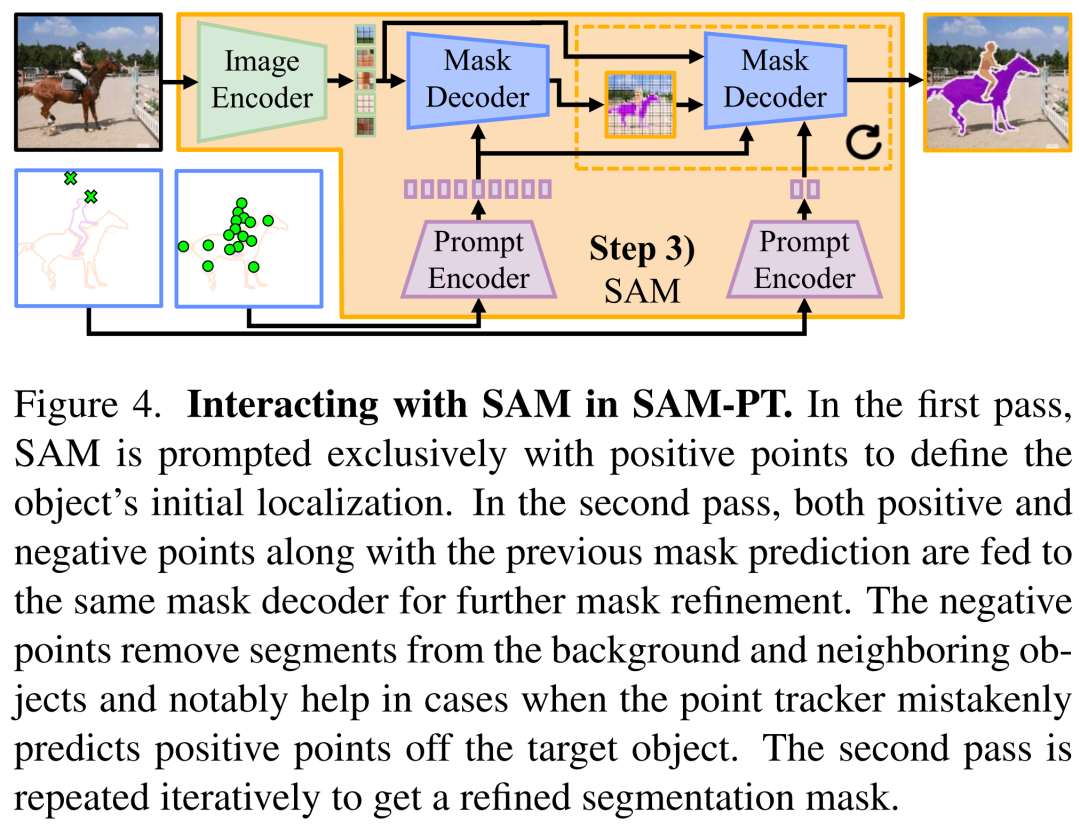
分割。在預(yù)測(cè)的軌跡中,未遮擋的點(diǎn)作為目標(biāo)對(duì)象在整個(gè)視頻中的位置的指示器。這時(shí)就可以使用非遮擋點(diǎn)來提示 SAM,并利用其固有的泛化能力來輸出每幀分割掩碼預(yù)測(cè)(如圖 4 所示) 。
點(diǎn)跟蹤重新初始化。一旦達(dá)到 h = 8 幀的預(yù)測(cè)期,用戶就可以選擇使用預(yù)測(cè)掩碼對(duì)查詢點(diǎn)進(jìn)行重新初始化,并將變體表示為 SAM-PT-reinit。在到達(dá)這個(gè)水平線時(shí),會(huì)有 h 個(gè)預(yù)測(cè)的掩碼,并將使用最后一個(gè)預(yù)測(cè)的掩模來采樣新的點(diǎn)。在這一階段,之前所有的點(diǎn)都被丟棄,用新采樣點(diǎn)來代替。
根據(jù)上面的方法,就可以將這個(gè)視頻進(jìn)行流暢的分割了,如下圖:

看看更多的展示效果:


SAM-PT 與以目標(biāo)為中心的掩碼傳播的比較
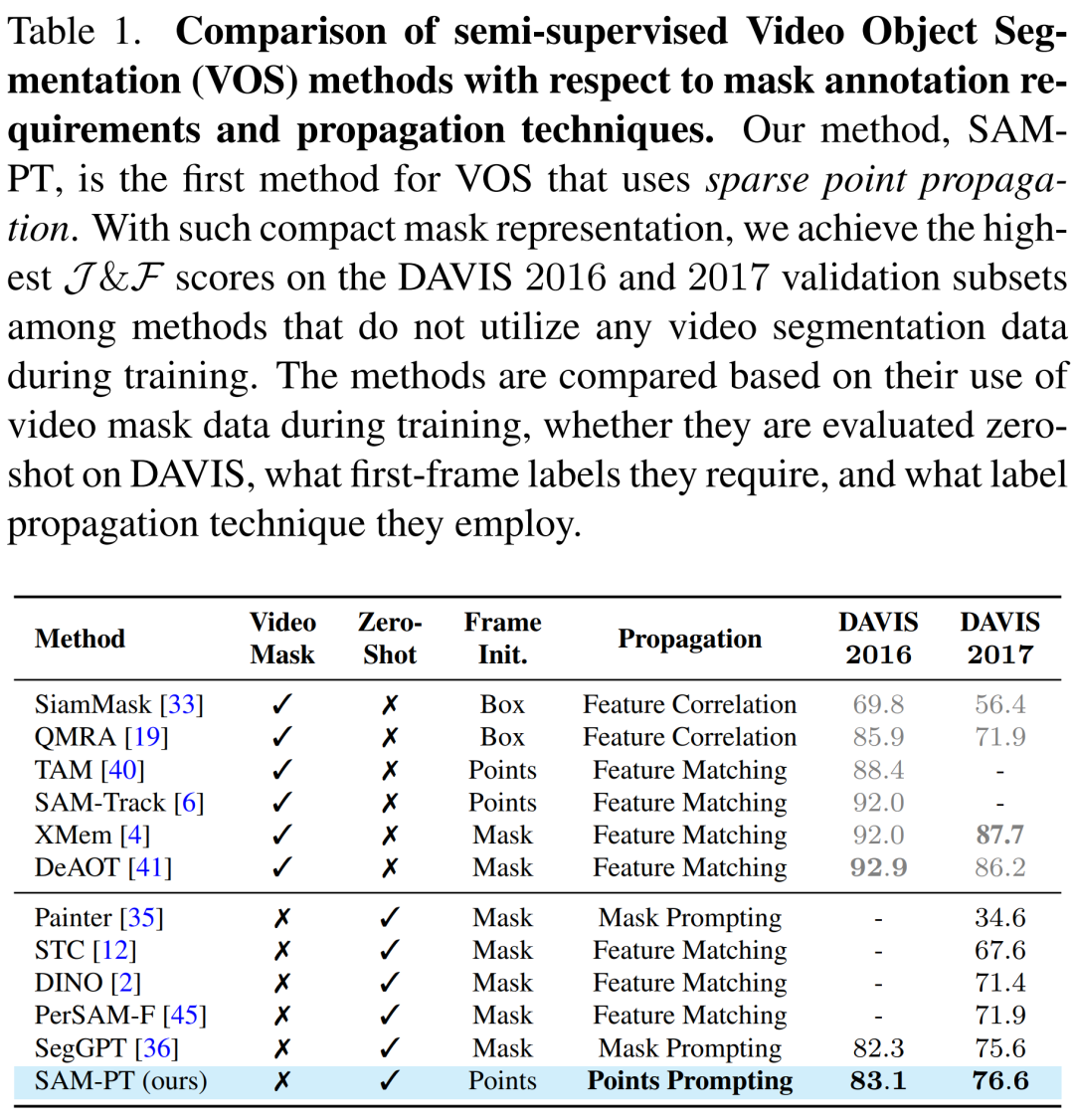
SAM- PT 將稀疏點(diǎn)跟蹤與提示 SAM 相結(jié)合,并區(qū)別于傳統(tǒng)依賴于密集目標(biāo)掩碼傳播的視頻分割方法,如表 1 所示。
與在訓(xùn)練期間不利用視頻分割數(shù)據(jù)的方法相比,SAM-PT 有著與之相當(dāng)甚至更好的表現(xiàn)。然而,這些方法與那些利用同一域中的視頻分割訓(xùn)練數(shù)據(jù)的方法, 如 XMem 或 DeAOT 之間還是存在著性能差距。
綜上所述,SAM-PT 是第一個(gè)引入稀疏點(diǎn)傳播并結(jié)合提示圖像分割基礎(chǔ)模型,進(jìn)行零樣本視頻對(duì)象分割的方法。它為關(guān)于視頻對(duì)象分割的研究提供了一個(gè)新的視角,并增加了一個(gè)新的維度。
實(shí)驗(yàn)結(jié)果
對(duì)于視頻物體分割,研究團(tuán)隊(duì)在四個(gè) VOS 數(shù)據(jù)集上評(píng)估了他們的方法,分別是 DAVIS 2016, DAVIS 2017, YouTube-VOS 2018, 和 MOSE 2023。
對(duì)于視頻實(shí)例分割,他們?cè)?UVO v1.0 數(shù)據(jù)集的 densevideo 任務(wù)上評(píng)估了該方法。
他們還用圖像實(shí)例分割中的標(biāo)準(zhǔn)評(píng)估指標(biāo)來評(píng)估所提出方法,這也適用于視頻實(shí)例分割。這些指標(biāo)包括平均準(zhǔn)確率(AP)和基于 IoU 的平均召回率(AR)。
視頻物體分割的結(jié)果
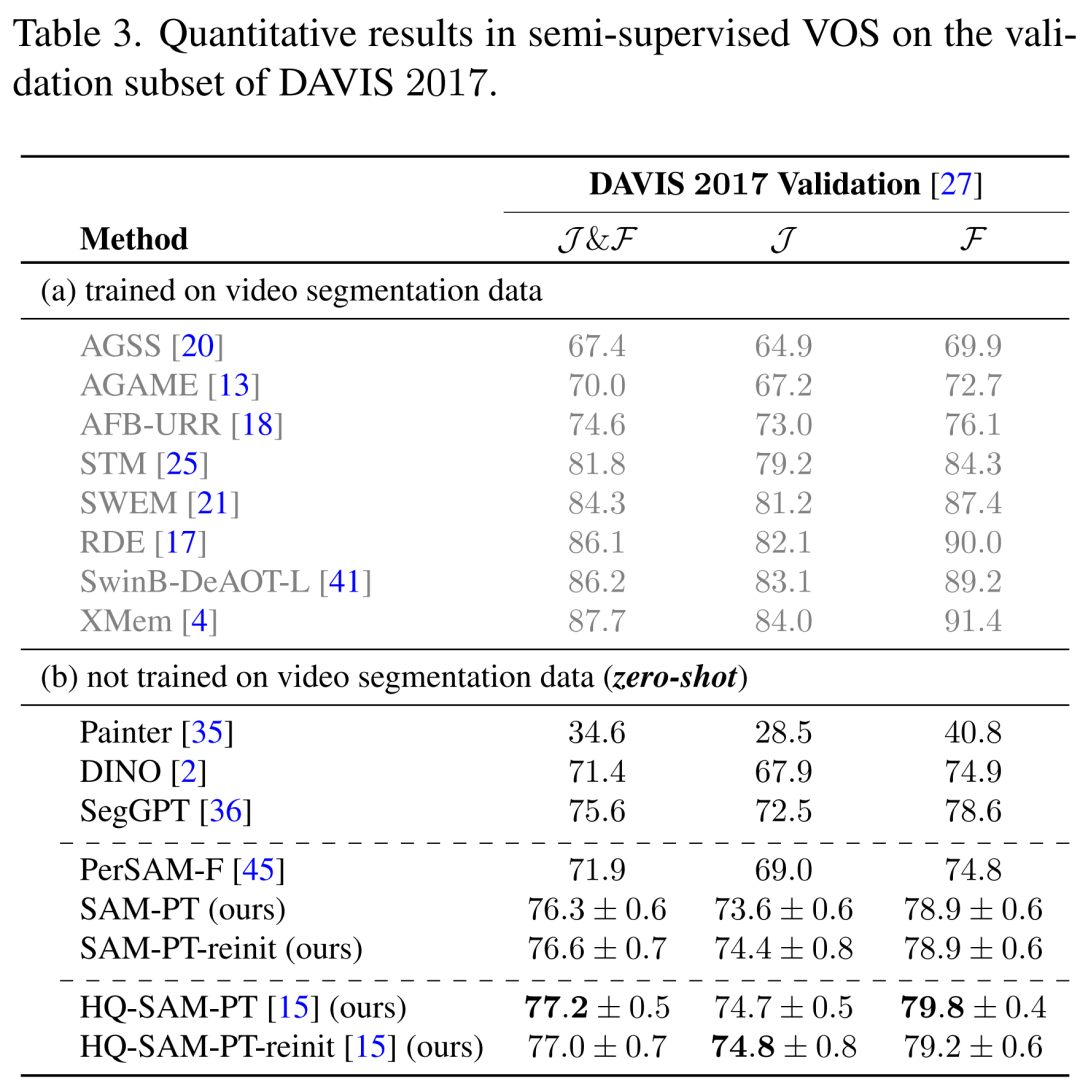
在 DAVIS 2017 數(shù)據(jù)集上,本文提出的方法優(yōu)于其他沒有經(jīng)過任何視頻物體分割數(shù)據(jù)訓(xùn)練的方法,如表 3 所示。
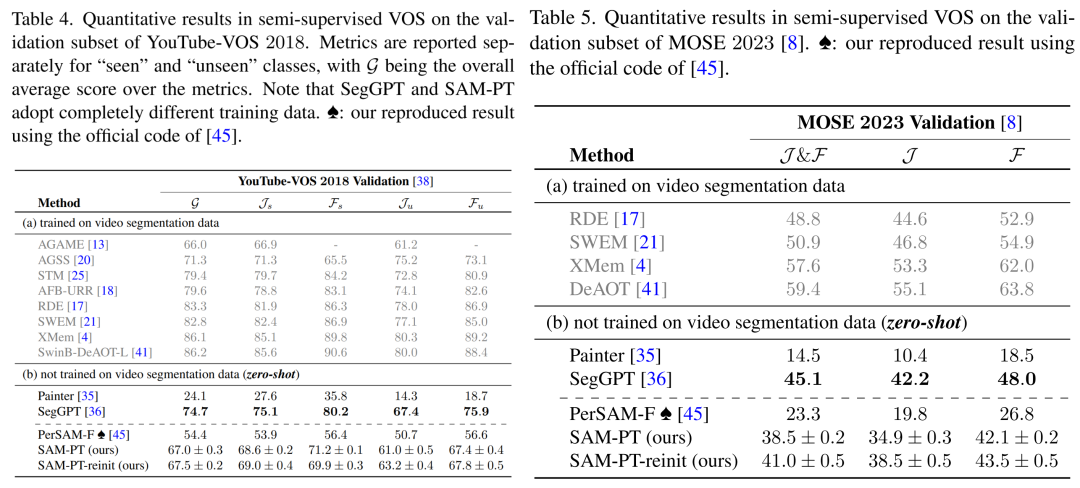
SAM-PT 在 YouTube-VOS 2018 和 MOSE 2023 數(shù)據(jù)集上的表現(xiàn)也超過了 PerSAM-F,取得了 67.0 和 41.0 的平均分,如表 4、表 5 所示。然而,在不同的掩碼訓(xùn)練數(shù)據(jù)下,與 SegGPT 相比,SAM-PT 在這兩個(gè)數(shù)據(jù)集上的表現(xiàn)有所欠缺。
定性分析。在 DAVIS 2017 上對(duì) SAM-PT 和 SAM-PTreinit 成功的視頻分割的可視化結(jié)果分別見圖 7a 和圖 7b。值得注意的是,圖 8 展示了對(duì)未知網(wǎng)絡(luò)視頻的成功視頻分割 —— 來自受動(dòng)畫影響的動(dòng)畫電視系列《降世神通:最后的氣宗》的片段,這表明了所提出方法的零樣本能力。

局限和挑戰(zhàn)。SAM-TP 的零樣本性能很有競(jìng)爭(zhēng)力,但仍然存在著一些局限。這些局限主要集中在點(diǎn)跟蹤器在處理遮擋、小物體、運(yùn)動(dòng)模糊和重新識(shí)別方面。在這些方面,點(diǎn)跟蹤器的錯(cuò)誤會(huì)傳播到未來的視頻幀中。
圖 7c 展示了 DAVIS 2017 中的這些問題實(shí)例,圖 9 展示了《降世神通:最后的氣宗》片段中的其他實(shí)例。

視頻實(shí)例分割的結(jié)果
在相同的遮罩建議下,SAM-PT 明顯優(yōu)于 TAM,盡管 SAM-PT 沒有在任何視頻分割數(shù)據(jù)上訓(xùn)練。TAM 是一個(gè)結(jié)合了 SAM 和 XMem 的并行方法,其中 XMem 在 BL30K 上進(jìn)行了預(yù)訓(xùn)練,并在 DAVIS 和 YouTube-VOS 上進(jìn)行了訓(xùn)練,但沒有在 UVO 上訓(xùn)練。
另一方面,SAM-PT 結(jié)合了 SAM 和 PIPS 點(diǎn)跟蹤方法,這兩種方法都沒有經(jīng)過視頻分割任務(wù)的訓(xùn)練。
-
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18247 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49987 -
SAM
+關(guān)注
關(guān)注
0文章
114瀏覽量
33814
原文標(biāo)題:分割一切視頻版來了!SAM-PT:點(diǎn)幾下鼠標(biāo),視頻目標(biāo)就分割出來了!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
用matlab編程實(shí)現(xiàn)圖像的字符分割
除了視頻分割,這款軟件還能進(jìn)行視頻合并、壓縮、去水印
基于筆畫提取和顏色模型的視頻文字分割算法
基于多層采樣多閾值的目標(biāo)分割算法
視覺顯著性目標(biāo)分割提取
使用OpenCv進(jìn)行運(yùn)動(dòng)目標(biāo)的檢測(cè)的課程論文免費(fèi)下載

動(dòng)態(tài)外觀模型和高階能量的雙邊視頻目標(biāo)分割方法

點(diǎn)云分割相較圖像分割的優(yōu)勢(shì)是啥?
SAM分割模型是什么?
YOLOv8最新版本支持SAM分割一切

基于SAM設(shè)計(jì)的自動(dòng)化遙感圖像實(shí)例分割方法

復(fù)旦開源LVOS:面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論