本周四,一些媒體首次報道了英偉達特供芯片的消息。報道稱,這三款新產品是在 H100 GPU 的基礎版....
![的頭像]() CVer 發表于
CVer 發表于 11-13 16:44
?1295次閱讀

不同領域的數據集包含各種數據類型和類別,如圖像、視頻、點云、時間序列等。每種數據類型可能需要不同的異....
![的頭像]() CVer 發表于
CVer 發表于 11-13 16:25
?1144次閱讀

盡管Vision Transformer(ViTs)和自監督學習(SSL)越來越受歡迎,但在大多數任....
![的頭像]() CVer 發表于
CVer 發表于 11-13 15:41
?1439次閱讀

深度學習的大模型時代已經來臨,越來越多的大規模預訓練模型在文本、視覺和多模態領域展示出杰出的生成和推....
![的頭像]() CVer 發表于
CVer 發表于 11-08 16:20
?1562次閱讀

在top-1中,CODEFUSION的性能與自回歸模型相媲美,甚至在某些情況下表現更出色,尤其是在P....
![的頭像]() CVer 發表于
CVer 發表于 11-01 16:23
?1143次閱讀

相比于僅使用logits的蒸餾方法,同步使用模型中間層特征進行蒸餾的方法通常能取得更好的性能。然而在....
![的頭像]() CVer 發表于
CVer 發表于 11-01 16:18
?1655次閱讀

在初始階段我們嘗試了多個GAN-based從mask生成image的模型 (e.g., OASIS[....
![的頭像]() CVer 發表于
CVer 發表于 11-01 16:09
?1096次閱讀

現有方法往往是:用一個2D特征提取網絡提取圖像特征;用一個3D特征提取網絡提取點云特征;然后根據pi....
![的頭像]() CVer 發表于
CVer 發表于 10-29 17:14
?1340次閱讀

2023年10月18日(北京時間),PyTorch 基金會正式宣布華為作為Premier會員加入基金....
![的頭像]() CVer 發表于
CVer 發表于 10-22 16:33
?1401次閱讀
效果怎么樣呢?PaLI-3 在需要視覺定位文本理解和目標定位的任務上實現了新的 SOTA,包括 Re....
![的頭像]() CVer 發表于
CVer 發表于 10-20 16:21
?2648次閱讀

描述自動駕駛場景的條件是多維度的,包括:相機參數、物體框、路面地圖以及對場景屬性的語言描述(比如天氣....
![的頭像]() CVer 發表于
CVer 發表于 10-20 16:18
?718次閱讀

用一句話來總結這個工作就是——我們提出了一種即插即用的loss S3IM(隨機結構相似性),可以近乎....
![的頭像]() CVer 發表于
CVer 發表于 10-13 15:59
?968次閱讀

為了完成這兩個任務,最為直覺,也是使用最多的方式就是:使用兩個分支來完成這兩件事,一個用來保留信息,....
![的頭像]() CVer 發表于
CVer 發表于 10-10 17:18
?1244次閱讀

我們提出了一種全新的自監督代理任務 DropPos,首先在 ViT 前向過程中屏蔽掉大量的 posi....
![的頭像]() CVer 發表于
CVer 發表于 10-10 17:10
?870次閱讀

LanguageMPC首次將LLM應用于駕駛場景,并設計了將文字形式高層決策轉化為可操作駕駛行為的方....
![的頭像]() CVer 發表于
CVer 發表于 10-10 15:57
?1236次閱讀

最后,可能大家從上面一段論述中也已經能感覺出來了,許多大佬們正把embodied AI作為一個最終的....
![的頭像]() CVer 發表于
CVer 發表于 10-08 16:16
?928次閱讀

本文將空間條件中物體的形狀、位置以及它們之間的關系等性質總結為視覺先驗(Visual Prior),....
![的頭像]() CVer 發表于
CVer 發表于 09-26 16:14
?848次閱讀
目前為止,OpenAI還沒有對爆料中的傳聞做出回應,但此前發布過多模態模型測試。CEO奧特曼在回應有....
![的頭像]() CVer 發表于
CVer 發表于 09-20 17:34
?1431次閱讀

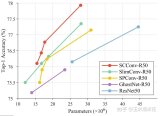
進一步使用大核卷積使得 FastViT 精度得到提升,而且不怎么影響延時。在移動設備和 ImageN....
![的頭像]() CVer 發表于
CVer 發表于 09-20 17:12
?971次閱讀

近來去噪擴散概率模型 Denoising diffusion probabilistic model....
![的頭像]() CVer 發表于
CVer 發表于 09-19 16:02
?6113次閱讀

基于MoCo[3]的框架,該文提出了用于文本識別的關系對比學習框架(RCLSTR)。如下圖所示:1、....
![的頭像]() CVer 發表于
CVer 發表于 09-14 17:21
?820次閱讀

如下圖,SCConv 由兩個單元組成,即空間重構單元 (SRU) 和信道重構單元 (CRU) ,兩個....
![的頭像]() CVer 發表于
CVer 發表于 09-14 17:05
?3657次閱讀
最近,馬毅教授團隊探索了基于Transformer架構的模型中涌現分割能力是否僅僅是復雜的自監督學習....
![的頭像]() CVer 發表于
CVer 發表于 09-14 15:58
?720次閱讀

一般性地,輸入數據可以被表征為由序列維度(sequential)和通道維度(channel)組成的二....
![的頭像]() CVer 發表于
CVer 發表于 09-12 16:40
?554次閱讀
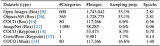
事實上,這并非唯一案例。自pubpeer不完全統計,4個月以來就有十幾篇含有「Regenerate ....
![的頭像]() CVer 發表于
CVer 發表于 09-12 16:22
?779次閱讀
本文提出了新型的可控光照增強框架,主要采用了條件擴散模型來控制任意區域的任意亮度增強。通過亮度控制模....
![的頭像]() CVer 發表于
CVer 發表于 09-11 17:20
?1320次閱讀

使用主動學習進行遙感目標檢測旨在通過從大型未標記數據集中選擇信息量豐富的樣本來降低標注成本,從而訓練....
![的頭像]() CVer 發表于
CVer 發表于 09-10 10:02
?990次閱讀

近期,火熱的擴散模型也被廣泛應用于多模態合成與編輯任務。例如效果驚人的DALLE-2和Imagen都....
![的頭像]() CVer 發表于
CVer 發表于 09-05 16:06
?1025次閱讀

現有的視頻目標分割(VOS)數據集主要關注于短時視頻,平均時長在3-5秒左右,并且視頻中的物體大部分....
![的頭像]() CVer 發表于
CVer 發表于 09-04 16:33
?1479次閱讀

另外,采訪中,Suleyman還爆出了很多自己在DeepMind和Inflection AI工作時的....
![的頭像]() CVer 發表于
CVer 發表于 09-04 16:28
?872次閱讀




 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1

