SIGGRAPH 博士論文獎設立于 2016 年,每年頒發(fā)給在計算機圖形學和交互技術領域成功答辯并完....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 07-04 10:55
?1352次閱讀

如今,計算機視覺社區(qū)已經(jīng)廣泛展開了對物體姿態(tài)的 6D 追蹤和 3D 重建。本文中英偉達提出了同時對未....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 07-03 11:24
?836次閱讀

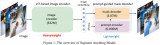
導讀 本文提出一種"解耦蒸餾"方案對SAM的ViT-H解碼器進行蒸餾,同時所得輕量級編碼器可與SAM....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-30 10:59
?1659次閱讀
動動鼠標,讓圖片變「活」,成為你想要的模樣。 在 AIGC 的神奇世界里,我們可以在圖像上通過「拖曳....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-30 10:57
?642次閱讀
對于訓練好的圖像分類器,能讓其可靠地在開放世界中工作的一個關鍵能力便是檢測未知的、分布外的(out-....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-28 15:57
?1131次閱讀

通過將分割?切任務重新劃分為全實例分割和提?指導選擇兩個?任務,?帶實例分割分?的常規(guī) CNN 檢測....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-28 14:33
?2082次閱讀
之前的模型大多利用手工制作的視覺線索特征,如顏色/亮度對比度、邊緣和形狀等,最近也有一些方法轉(zhuǎn)向基于....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-27 14:37
?606次閱讀

然而生成圖表也面臨一些挑戰(zhàn),它需要表示框、箭頭、文本等離散組件之間的復雜關系。與生成自然圖像不同,論....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-27 14:32
?782次閱讀

1. 研究動機 圖像分割旨在將具有不同語義的像素進行分類進而分組,例如類別或?qū)嵗陙砣〉蔑w速的發(fā)....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-26 10:39
?768次閱讀

本文旨在更好地理解基于 Transformer 的大型語言模型(LLM)的內(nèi)部機制,以提高它們的可靠....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-25 15:08
?1827次閱讀

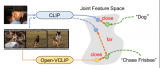
本文提出了一種新的CLIP向視頻領域的遷移方法,找到模型泛化和專用化之間的平衡,讓模型既能識別微調(diào)時....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-25 15:04
?1476次閱讀
在傳統(tǒng)的三維物體檢測任務中,前景物體通常由三維邊界框表示。然而,這種方法存在一些弊端,一方面,現(xiàn)實世....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-21 14:04
?1149次閱讀

在上周復旦大學邱錫鵬團隊提交的論文《Full Parameter Fine-tuning for L....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-21 14:00
?1174次閱讀

盡管AI發(fā)展迅猛,但目前CV領域的許多任務仍然缺乏高質(zhì)量的數(shù)據(jù),3D尤甚。一個解決辦法是用合成數(shù)據(jù)。....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-20 14:47
?553次閱讀

這篇論文的通訊作者是結構生物學家顏寧,主要從事與疾病相關的重要膜轉(zhuǎn)運蛋白、電壓門控離子通道的結構與工....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-19 16:08
?750次閱讀

面向真實 3D 物體的感知、理解、重建與生成是計算機視覺領域一直倍受關注的問題,也在近年來取得了飛速....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-19 15:30
?1787次閱讀

引言 距離上次的長篇大論,已經(jīng)過去了半年有余。這段時間,對于AI業(yè)界甚至整個世界,都是驚心動魄的。在....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-19 11:44
?887次閱讀

我可以將最近的一篇數(shù)學預印本的前幾頁PDF輸入GPT-4,讓它生成半打有關該預印本的專家可能會提出的....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-19 10:52
?660次閱讀

本文介紹CVPR2023的中稿論文:Temporal Attention Unit: Towards....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-19 10:27
?1944次閱讀

在一些非自然圖像中要比傳統(tǒng)模型表現(xiàn)更好 CoOp 增加一些 prompt 會讓模型能力進一步提升 怎....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-15 16:36
?769次閱讀

今日,Meta 推出了首個基于 LeCun 世界模型概念的 AI 模型。該模型名為圖像聯(lián)合嵌入預測架....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-15 15:47
?516次閱讀
圖2是模型的整體結構圖,它包含顏色感知背景提取網(wǎng)絡(Color-aware Background E....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-12 14:20
?1438次閱讀

先隨機采樣兩個視頻幀,并進行非對稱掩碼操作;然后SiamMAE編碼器網(wǎng)絡對兩個幀進行獨立處理,最后使....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-12 14:18
?809次閱讀

? Stable Diffusion (SD)是當前最熱門的文本到圖像(text to image)....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-12 10:14
?1054次閱讀

? 【導讀】 AI理論再進一步,破解ChatGPT指日可待? Transformer架構已經(jīng)橫掃了包....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-12 10:11
?1151次閱讀

本文將空間條件中物體的形狀、位置以及它們之間的關系等性質(zhì)總結為視覺先驗(Visual Prior),....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-11 10:34
?514次閱讀

RES在圖形編輯、視頻制作、人機交互和機器人等眾多應用領域具有巨大潛力。目前,大多數(shù)現(xiàn)有方法都遵循在....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-08 15:06
?656次閱讀

現(xiàn)有的可控圖片生成模型都是針對單一的模態(tài)進行設計,然而 Taskonomy [3] 等工作證明不同的....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-08 15:01
?947次閱讀

該研究提出了一個簡單而有效的框架 Control-GPT,它利用 LLM 的強大功能根據(jù)文本 pro....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-05 15:31
?1155次閱讀

ImageBind算是跨出了重要的一步,但我之前文章提了我的個人觀點,就是采用小規(guī)模其他模態(tài)和圖像的....
![的頭像]() CVer 發(fā)表于
CVer 發(fā)表于 06-02 17:26
?1207次閱讀






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)