") 一個(gè)通用的時(shí)空預(yù)測(cè)學(xué)習(xí)框架
一個(gè)通用的時(shí)空預(yù)測(cè)學(xué)習(xí)框架

本文介紹CVPR2023的中稿論文:Temporal Attention Unit: Towards Efficient Spatiotemporal Predictive Learning。這篇論文介紹了一種用于高效時(shí)空預(yù)測(cè)的時(shí)間注意力單元(Temporal Attention Unit,TAU)。該方法改進(jìn)了現(xiàn)有框架,對(duì)時(shí)間和空間上的依賴(lài)關(guān)系分別學(xué)習(xí),提出了時(shí)間維度上的可并行化時(shí)序注意力單元,實(shí)現(xiàn)了高效的視頻預(yù)測(cè)。
引言
時(shí)空預(yù)測(cè)學(xué)習(xí)是一種通過(guò)學(xué)習(xí)歷史幀來(lái)預(yù)測(cè)未來(lái)幀的自監(jiān)督學(xué)習(xí)范式,可以利用海量的無(wú)標(biāo)注視頻數(shù)據(jù)學(xué)習(xí)豐富的視覺(jué)信息,在氣象預(yù)測(cè)、交通流量預(yù)測(cè)、人體姿勢(shì)變化估計(jì)等領(lǐng)域有著廣泛的應(yīng)用場(chǎng)景。時(shí)空預(yù)測(cè)學(xué)習(xí)需要考慮視頻中的空間相關(guān)性和時(shí)間演變規(guī)律,這是一項(xiàng)具有挑戰(zhàn)性的任務(wù)。傳統(tǒng)的方法主要基于循環(huán)神經(jīng)網(wǎng)絡(luò)來(lái)建模時(shí)間依賴(lài)關(guān)系,但是RNN有著計(jì)算效率低、難以捕捉長(zhǎng)期依賴(lài)、容易出現(xiàn)梯度消失或爆炸等缺點(diǎn)。因此,如何設(shè)計(jì)一個(gè)高效、準(zhǔn)確、穩(wěn)定的時(shí)空預(yù)測(cè)學(xué)習(xí)模型,是一個(gè)亟待解決的問(wèn)題。為了解決這個(gè)問(wèn)題,我們首先研究現(xiàn)有的方法,并提出時(shí)空預(yù)測(cè)學(xué)習(xí)的通用框架,如下圖所示。
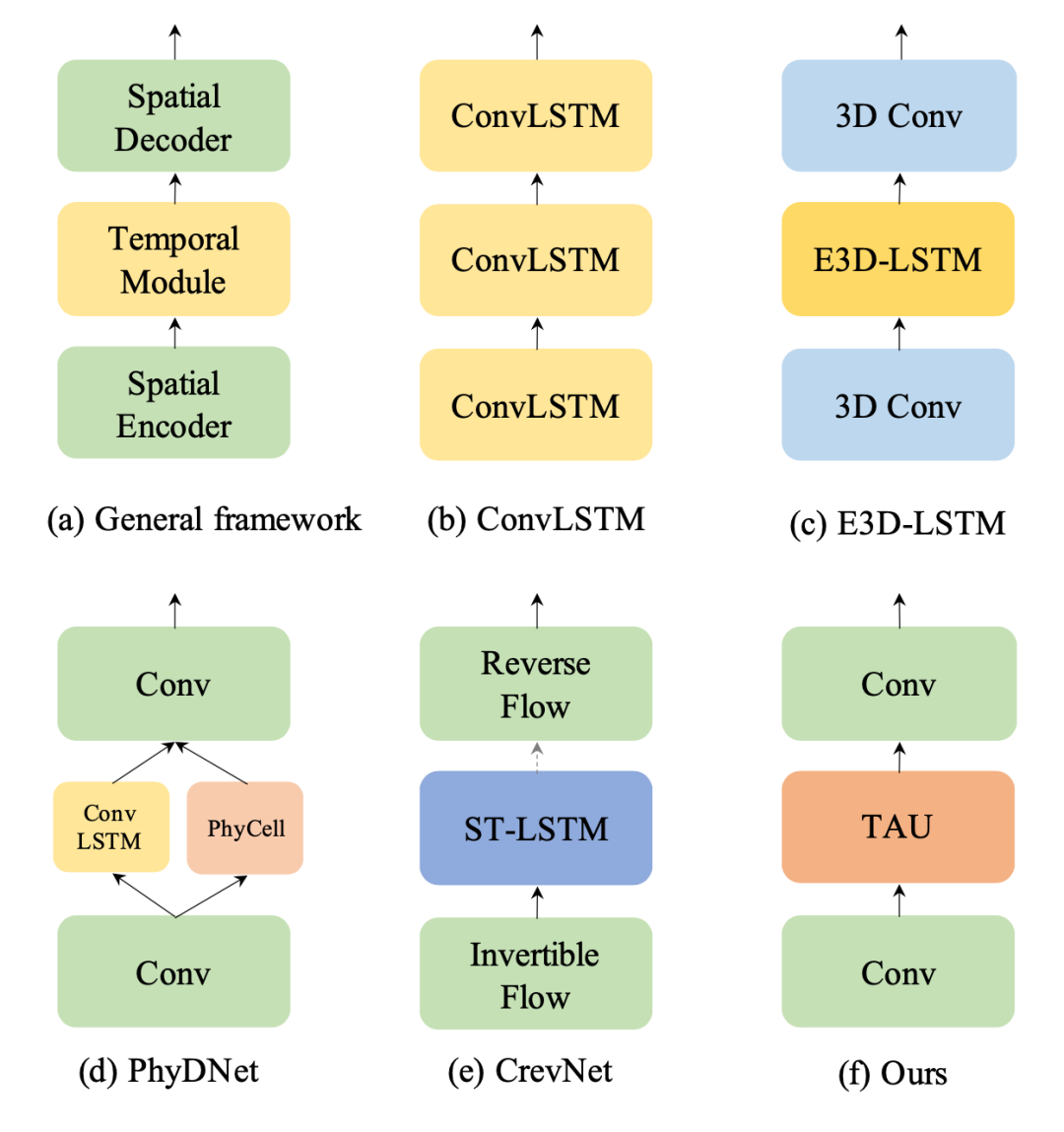
TAU
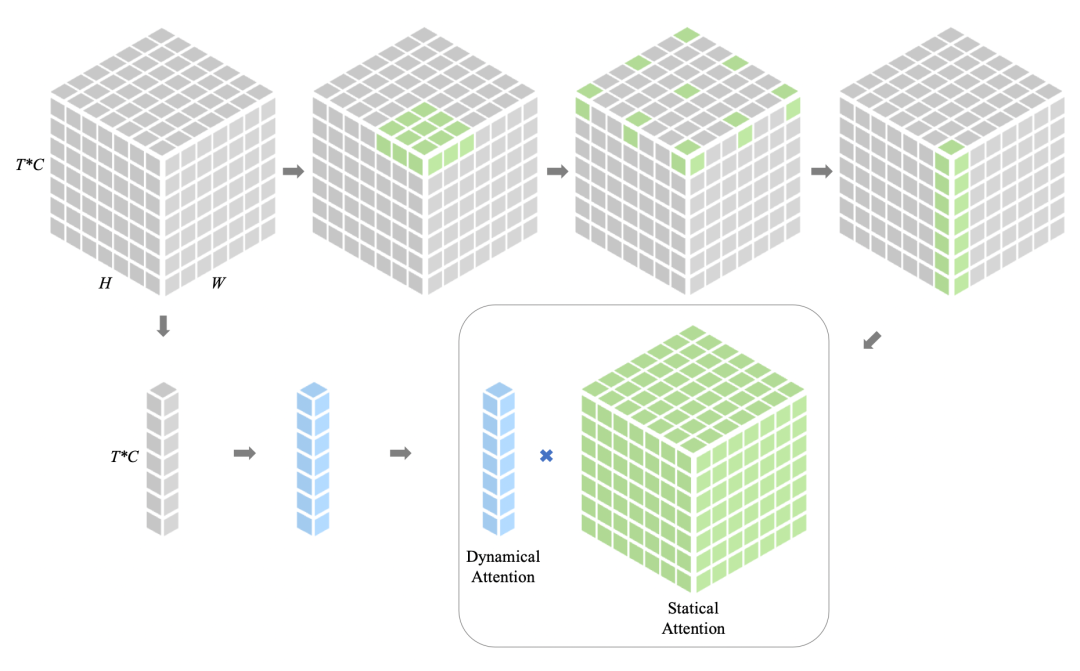
如下圖所示,TAU模型不使用循環(huán)神經(jīng)網(wǎng)絡(luò),而是使用注意力機(jī)制來(lái)并行化地處理時(shí)間演變。TAU模型將時(shí)空注意力分解為兩個(gè)部分:幀內(nèi)靜態(tài)注意力和幀間動(dòng)態(tài)注意力。幀內(nèi)靜態(tài)注意力使用小核心深度卷積和擴(kuò)張卷積來(lái)實(shí)現(xiàn)大感受野,從而捕捉幀內(nèi)的長(zhǎng)距離依賴(lài)關(guān)系。幀間動(dòng)態(tài)注意力使用通道間注意力的方式來(lái)學(xué)習(xí)不同幀之間的通道權(quán)重,從而捕捉幀間的變化趨勢(shì)。
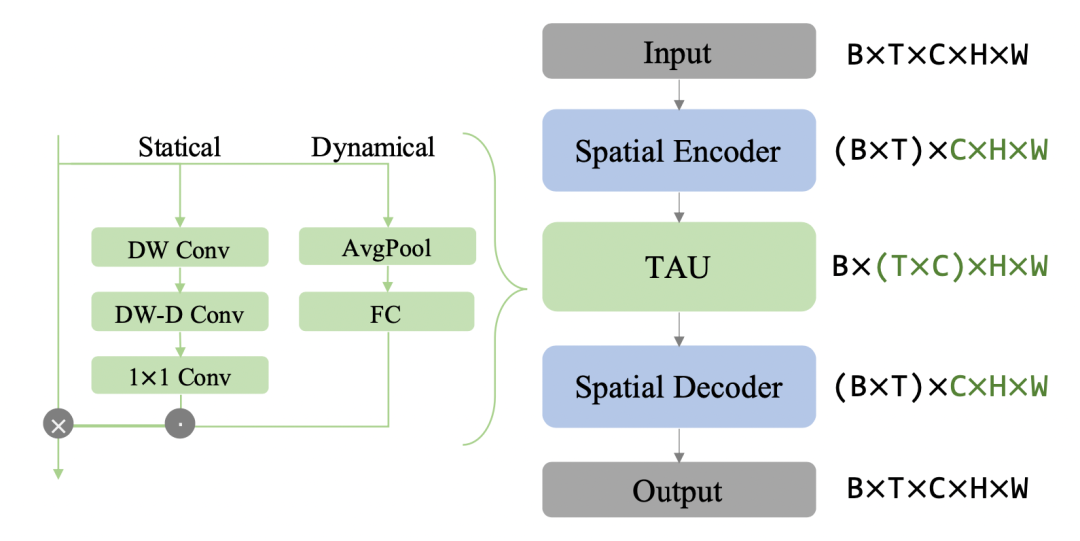
TAU模塊將時(shí)間注意力分為兩部分:幀內(nèi)靜態(tài)注意力和幀間動(dòng)態(tài)注意力。前者通過(guò)獲得的大感受野捕捉幀內(nèi)的長(zhǎng)期依賴(lài)關(guān)系;而后者以擠壓和激發(fā)的方式學(xué)習(xí)通道的注意力權(quán)重,以捕捉時(shí)間線上的時(shí)序演變。最后的注意力是動(dòng)態(tài)注意力和靜態(tài)注意力結(jié)合的產(chǎn)物。受ViTs和大核卷積的啟發(fā),研究者使用了深度卷積(DW Conv)、深度擴(kuò)張卷積(DW-D Conv)和1x1通道卷積來(lái)建模大核卷積。
 此外,我們還提出了一種新穎的差分散度正則化方法,用于優(yōu)化時(shí)空預(yù)測(cè)學(xué)習(xí)的損失函數(shù)。該方法同時(shí)考慮了幀內(nèi)誤差和幀間變化量。通過(guò)將預(yù)測(cè)幀和真實(shí)幀之間的差分轉(zhuǎn)換為概率分布,并計(jì)算它們之間的KL散度,來(lái)強(qiáng)制模型學(xué)習(xí)到視頻中固有的變化規(guī)律。差分散度正則化(differential divergence regularization)是預(yù)測(cè)幀與其對(duì)應(yīng)的真實(shí)幀之間的Kullback-Leibler(KL)散度。具體而言,它是預(yù)測(cè)幀差分和真實(shí)幀差分之間的KL散度。
此外,我們還提出了一種新穎的差分散度正則化方法,用于優(yōu)化時(shí)空預(yù)測(cè)學(xué)習(xí)的損失函數(shù)。該方法同時(shí)考慮了幀內(nèi)誤差和幀間變化量。通過(guò)將預(yù)測(cè)幀和真實(shí)幀之間的差分轉(zhuǎn)換為概率分布,并計(jì)算它們之間的KL散度,來(lái)強(qiáng)制模型學(xué)習(xí)到視頻中固有的變化規(guī)律。差分散度正則化(differential divergence regularization)是預(yù)測(cè)幀與其對(duì)應(yīng)的真實(shí)幀之間的Kullback-Leibler(KL)散度。具體而言,它是預(yù)測(cè)幀差分和真實(shí)幀差分之間的KL散度。 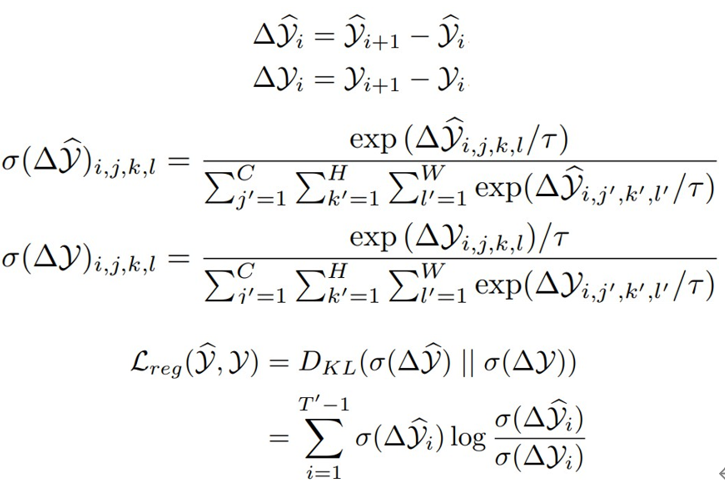
τ 代表溫度參數(shù),經(jīng)驗(yàn)性地將其設(shè)置為0.1以增強(qiáng)概率分布的差異。直觀來(lái)說(shuō),均方誤差損失(MSE)僅考慮幀內(nèi)誤差,而差分散度正則化克服了這一缺點(diǎn),迫使模型學(xué)習(xí)連續(xù)幀之間的差異并意識(shí)到固有的變化,以改善模型的預(yù)測(cè)。
因此目標(biāo)損失函數(shù):
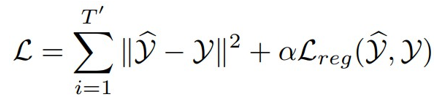
實(shí)驗(yàn)
Moving MNIST
下圖是在Moving MNIST上測(cè)試的兩個(gè)實(shí)例,對(duì)于隨機(jī)運(yùn)動(dòng)的數(shù)字,預(yù)測(cè)與目標(biāo)的絕對(duì)差異很細(xì)微,說(shuō)明TAU能很好地處理時(shí)空預(yù)測(cè):
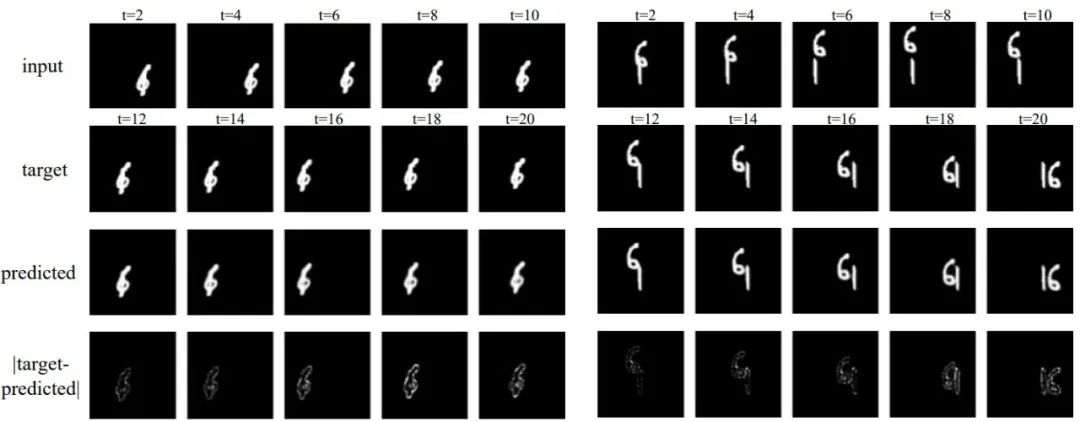
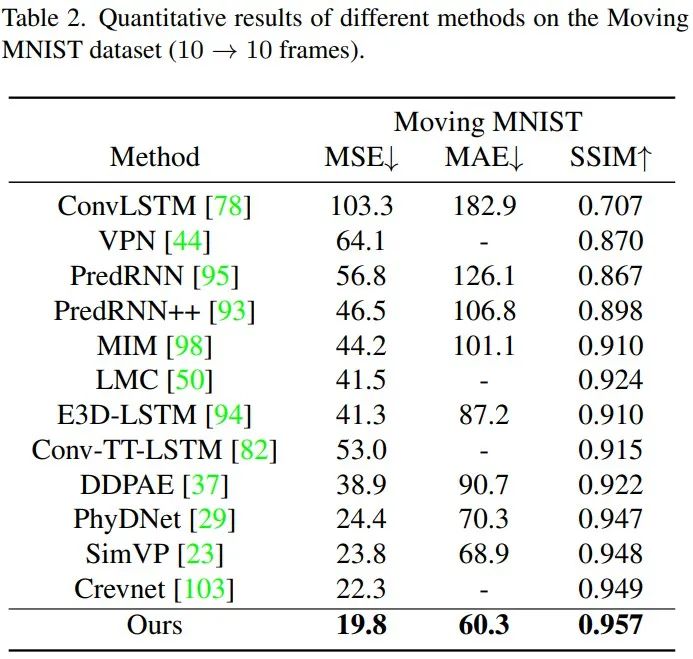
相對(duì)于SOTA的循環(huán)模型,TAU的性能增益是較大的,在三個(gè)度量指標(biāo)下,TAU的表現(xiàn)都超越了其他方法:
TaxiBJ
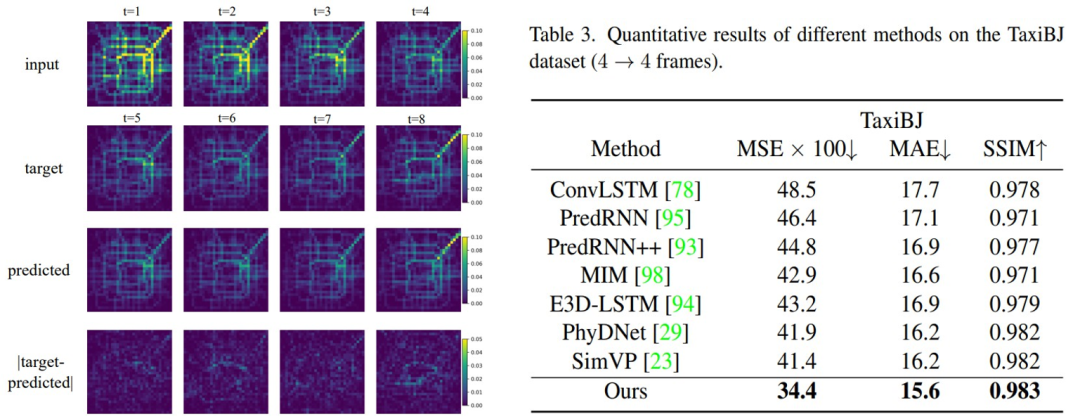
在真實(shí)復(fù)雜環(huán)境的交通流量數(shù)據(jù)集上,TAU具有良好的表現(xiàn):
不同數(shù)據(jù)的泛化
為了檢驗(yàn)?zāi)P偷姆夯芰Γ覀兿仍贙ITTI原始數(shù)據(jù)上進(jìn)行訓(xùn)練,接著使用Caltech dataset進(jìn)行評(píng)估,評(píng)估時(shí)輸入前十幀預(yù)測(cè)下一幀。

靈活長(zhǎng)度的預(yù)測(cè)
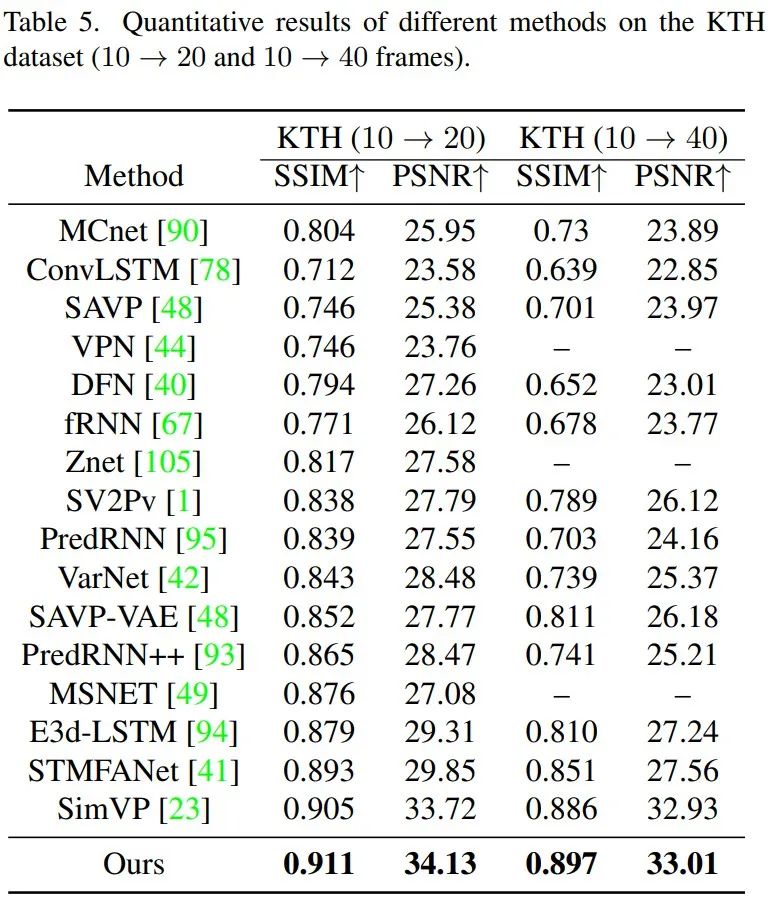
我們的模型可以通過(guò)模仿RNN,將預(yù)測(cè)的幀作為輸入并遞歸產(chǎn)生預(yù)測(cè)來(lái)處理靈活長(zhǎng)度的預(yù)測(cè)。對(duì)于KTH數(shù)據(jù)集,人體運(yùn)動(dòng)預(yù)測(cè)任務(wù)的難點(diǎn)不僅在于預(yù)測(cè)幀的靈活長(zhǎng)度,還在于涉及人類(lèi)意識(shí)隨機(jī)性的復(fù)雜動(dòng)力學(xué),這增加了任務(wù)的困難程度。TAU可以從給定的10幀中預(yù)測(cè)接下來(lái)的20或40幀,也有出色的表現(xiàn)。
運(yùn)行效率
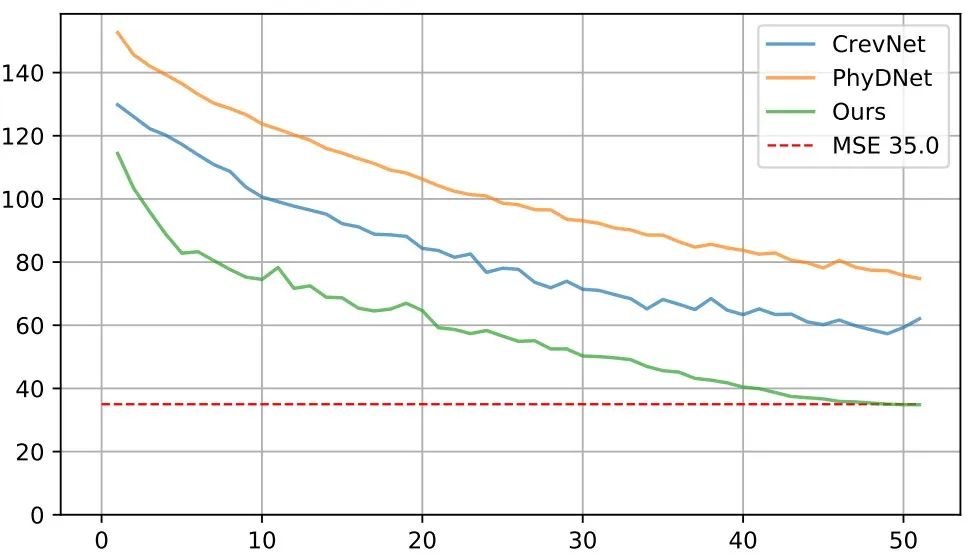
此外,我們的模型不僅可以提高視頻生成質(zhì)量,還可以提高計(jì)算效率和訓(xùn)練速度。如下圖所示,收斂速度極快,50輪訓(xùn)練即可達(dá)到MSE 35.0的水準(zhǔn)。在相同實(shí)驗(yàn)環(huán)境下,TAU模型在基準(zhǔn)數(shù)據(jù)集上每個(gè)周期只需要2.5分鐘,而此前的SOTA方法需要7到30分鐘不等。
總結(jié)
本文提出了一個(gè)通用的時(shí)空預(yù)測(cè)學(xué)習(xí)框架,使用基于靜態(tài)和動(dòng)態(tài)結(jié)合的時(shí)間注意力模塊替代循環(huán)單元,還引入了差分散度正則化方法來(lái)解決僅考慮幀內(nèi)誤差的MSE損失的問(wèn)題,為高效的時(shí)空預(yù)測(cè)學(xué)習(xí)提供了新的范式。
責(zé)任編輯:彭菁
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103616 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91868 -
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17894
發(fā)布評(píng)論請(qǐng)先 登錄
深度學(xué)習(xí)發(fā)展的5個(gè)主力框架

PLASTER:一個(gè)與深度學(xué)習(xí)性能有關(guān)的框架
谷歌發(fā)布機(jī)器學(xué)習(xí)框架:一個(gè)名叫NSL的神經(jīng)結(jié)構(gòu)學(xué)習(xí)框架
一個(gè)跳出人類(lèi)思維框架的人工智能抗生素預(yù)測(cè)平臺(tái)
一個(gè)全新的深度學(xué)習(xí)框架——計(jì)圖
一種用于交通流預(yù)測(cè)的深度學(xué)習(xí)框架

基于時(shí)空特性的ST-LSTM網(wǎng)絡(luò)位置預(yù)測(cè)模型
一個(gè)基于參數(shù)更新的遷移學(xué)習(xí)的統(tǒng)一框架
時(shí)空圖神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)學(xué)習(xí)應(yīng)用解析

通用的時(shí)空預(yù)測(cè)學(xué)習(xí)框架實(shí)現(xiàn)高效視頻預(yù)測(cè)案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論