驚!大腦視覺(jué)信號(hào)被Stable Diffusion復(fù)現(xiàn)成視頻!
從大腦活動(dòng)中重建人類(lèi)視覺(jué)任務(wù),尤其是功能磁共振成像技術(shù)(fMRI)這種非侵入式方法,一直是受到學(xué)界較....

LinK:用線(xiàn)性核實(shí)現(xiàn)3D激光雷達(dá)感知任務(wù)中的large kernel
前文中討論了大卷積核下稀疏卷積的兩大缺陷:開(kāi)銷(xiāo)大以及優(yōu)化困難。我們首先采用神經(jīng)網(wǎng)絡(luò)模塊 來(lái)在線(xiàn)生成權(quán)....

清華朱軍團(tuán)隊(duì)提出ProlificDreamer:直接文本生成高質(zhì)量3D內(nèi)容
將 Imagen 生成的照片(下圖靜態(tài)圖)和 ProlificDreamer(基于 Stable-D....
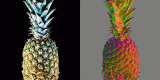
華為諾亞提出VanillaNet:一種新視覺(jué)Backbone,極簡(jiǎn)且強(qiáng)大!
后來(lái),Princeton大學(xué)的鄧嘉團(tuán)隊(duì)提出了深度為12的網(wǎng)絡(luò)并在ImageNet數(shù)據(jù)集上達(dá)到了80.....

在一個(gè)簡(jiǎn)單的Mean Teacher架構(gòu)中雙向復(fù)制粘貼標(biāo)記和未標(biāo)記的數(shù)據(jù)
為了緩解標(biāo)注數(shù)據(jù)和未標(biāo)注數(shù)據(jù)之間經(jīng)驗(yàn)不匹配問(wèn)題,一個(gè)成功的設(shè)計(jì)是鼓勵(lì)未標(biāo)注數(shù)據(jù)從標(biāo)注數(shù)據(jù)中學(xué)習(xí)全面的....

GPT-4推理提升1750%!清華姚班校友提出全新ToT框架
那么,這樣一個(gè)簡(jiǎn)單的機(jī)制能否足以建立一個(gè)通向「解決通用問(wèn)題的語(yǔ)言模型」?如果不是,哪些問(wèn)題會(huì)挑戰(zhàn)當(dāng)前....

第一篇綜述!分割一切模型(SAM)的全面調(diào)研
SAM 是一個(gè)提示型模型,其在 1100 萬(wàn)張圖像上訓(xùn)練了超過(guò) 10 億個(gè)掩碼,實(shí)現(xiàn)了強(qiáng)大的零樣本泛....

邱錫鵬團(tuán)隊(duì)提出SpeechGPT:具有內(nèi)生跨模態(tài)能力的大語(yǔ)言模型
雖然現(xiàn)有的級(jí)聯(lián)方法或口語(yǔ)語(yǔ)言模型能夠感知和生成語(yǔ)音,但仍存在一些限制。首先,在級(jí)聯(lián)模型中,LLM 僅....

特斯拉人形機(jī)器人集體出街!已與FSD算法打通
其核心是神經(jīng)網(wǎng)絡(luò)模型:通過(guò)對(duì)實(shí)時(shí)傳感器(如相機(jī)、激光雷達(dá)等)獲取的數(shù)據(jù)進(jìn)行處理和分析,并從中提取有關(guān)....

幾乎涵蓋了圖神經(jīng)網(wǎng)絡(luò)所有操作
在計(jì)算機(jī)視覺(jué)的應(yīng)用有根據(jù)提供的語(yǔ)義生成圖像,如下圖所示(引用)。輸入是一張語(yǔ)義圖,GNN通過(guò)對(duì)“ma....
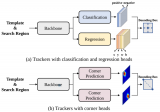
目標(biāo)跟蹤新的建模方式
現(xiàn)在比較先進(jìn)的目標(biāo)跟蹤方法采用了“分而治之”的策略,即將跟蹤問(wèn)題解耦成多個(gè)子任務(wù),例如中心點(diǎn)預(yù)測(cè)、前....
GPT-4拿下最難數(shù)學(xué)推理數(shù)據(jù)集新SOTA!新型Prompting讓大模型推理能力狂升!
結(jié)果表明,GP-T-4+PHP 在多個(gè)數(shù)據(jù)集上取得了 SOTA 結(jié)果,包括 SVAMP (91.9%....

超越Y(jié)OLOv8!YOLO-NAS:下一代目標(biāo)檢測(cè)基礎(chǔ)模型
總而言之,YOLO-NAS達(dá)成目標(biāo)檢測(cè)任務(wù)新高度,取得了最佳的精度-延遲均衡。值得一提,YOLO-N....

ImageBind:跨模態(tài)之王,將6種模態(tài)全部綁定!
最近,很多方法學(xué)習(xí)與文本、音頻等對(duì)齊的圖像特征。這些方法使用單對(duì)模態(tài)或者最多幾種視覺(jué)模態(tài)。最終嵌入僅....

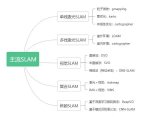
一文看盡SLAM創(chuàng)新點(diǎn)的前世今生
很多同學(xué)都覺(jué)得Slam方向難以入門(mén),也難以學(xué)深。但其實(shí)相對(duì)來(lái)講,不像其他很多方向,很多的東西大家都已....
SAM-Adapter:首次讓SAM在下游任務(wù)適應(yīng)調(diào)優(yōu)!
在這些基礎(chǔ)模型中,Segment Anything Model(SAM)作為一個(gè)在大型視覺(jué)語(yǔ)料庫(kù)上訓(xùn)....
從BLIP-2到SAM視覺(jué)語(yǔ)義金字塔+ChatGPT
怎么把圖片表示成高質(zhì)量文本一直是個(gè)熱門(mén)的問(wèn)題。傳統(tǒng)的思路Show,and Tell 等 Image ....
馬斯克離開(kāi)OpenAI內(nèi)幕:大權(quán)獨(dú)攬想法被拒
OpenAI 于 2015 年成立,起初是一家非營(yíng)利組織,得到了馬斯克和里德?霍夫曼(Reid Ho....
港中大IDEA開(kāi)源首個(gè)大規(guī)模全場(chǎng)景人體數(shù)據(jù)集Human-Art
然而,現(xiàn)有的計(jì)算機(jī)視覺(jué)任務(wù)、訓(xùn)練的數(shù)據(jù)集等大多只關(guān)注到了真實(shí)世界的照片,這導(dǎo)致相關(guān)模型在更豐富的場(chǎng)景....
StrucTexTv2:端到端文檔圖像理解預(yù)訓(xùn)練框架
視覺(jué)富文檔理解技術(shù)例如文檔分類(lèi)、版式分析、表單理解、OCR以及信息提取,逐漸成為文檔智能領(lǐng)域一個(gè)熱門(mén)....
清華&美團(tuán)提出稀疏Pairwise損失函數(shù)!ReID任務(wù)超已有損失函數(shù)!
ReID任務(wù)中的由于光照變化、視角改變和遮擋等原因會(huì)造成同一類(lèi)中不同實(shí)例的視覺(jué)相似度很低(如圖2所示....
這款編譯器能讓Python和C++一樣快!
麻省理工學(xué)院計(jì)算機(jī)科學(xué)與人工智能實(shí)驗(yàn)室(CSAIL)的研究人員希望通過(guò) Codon 來(lái)改變這一現(xiàn)狀,....
大型語(yǔ)言模型綜述全新出爐!從T5到GPT-4最全盤(pán)點(diǎn)
LLM 的涌現(xiàn)能力被正式定義為「在小型模型中不存在但在大型模型中出現(xiàn)的能力」,這是 LLM 與以前的....
GPT-4的研究路徑?jīng)]有前途?
這場(chǎng)辯論的主題為「Do large language models need sensory gro....
DepGraph:任意架構(gòu)的結(jié)構(gòu)化剪枝,CNN、Transformer、GNN等都適用!
結(jié)構(gòu)化剪枝是一種重要的模型壓縮算法,它通過(guò)移除神經(jīng)網(wǎng)絡(luò)中冗余的結(jié)構(gòu)來(lái)減少參數(shù)量,從而降低模型推理的時(shí)....
Meta提出Make-A-Video3D:一行文本,生成3D動(dòng)態(tài)場(chǎng)景!
具體而言,該方法運(yùn)用 4D 動(dòng)態(tài)神經(jīng)輻射場(chǎng)(NeRF),通過(guò)查詢(xún)基于文本到視頻(T2V)擴(kuò)散的模型,....
LERF:當(dāng)CLIP遇見(jiàn)NeRF!讓自然語(yǔ)言與3D場(chǎng)景交互更直觀(guān)
但自然語(yǔ)言不同,自然語(yǔ)言與 3D 場(chǎng)景交互非常直觀(guān)。我們可以用圖 1 中的廚房場(chǎng)景來(lái)解釋?zhuān)ㄟ^(guò)詢(xún)問(wèn)餐....
基于擴(kuò)散模型的視頻合成新模型,加特效杠杠的!
近日,曾參與創(chuàng)建 Stable Diffusion 的 Runway 公司推出了一個(gè)新的人工智能模型....
大腦視覺(jué)信號(hào)被Stable Diffusion復(fù)現(xiàn)成圖像!
這項(xiàng)研究聲稱(chēng),只需用fMRI(功能磁共振成像技術(shù),相比sMRI更關(guān)注功能性信息,如腦皮層激活情況等)....
ChatGPT正式上線(xiàn)對(duì)搜索引擎有什么影響
國(guó)內(nèi)外兩家搜索巨頭急速?zèng)_刺,現(xiàn)在卻還是投資了OpenAI的微軟更快一步。倒也不奇怪,畢竟這種“搜索大....





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)