") 漲點!FreeMask:用密集標(biāo)注的合成圖像提升分割模型性能
漲點!FreeMask:用密集標(biāo)注的合成圖像提升分割模型性能
在這里分享一下我們NeurIPS 2023的工作"FreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models"。在本工作中,我們從語義分割的mask產(chǎn)生大量的合成圖像,并利用這些合成的訓(xùn)練圖像以及他們對應(yīng)的mask提升在全量真實數(shù)據(jù)上訓(xùn)練的語義分割模型的性能, e.g., 在ADE20K上,可以將Mask2Former-Swin-T從48.7提升至52.0(+3.3 mIoU)。

代碼:github.com/LiheYoung/FreeMask 論文:https://arxiv.org/abs/2310.15160
在上面的repo中我們也提供了處理過后的ADE20K-Synthetic數(shù)據(jù)集(包含ADE20K的20倍的訓(xùn)練圖像)和COCO-Synthetic數(shù)據(jù)集(包含COCO-Stuff-164K的6倍的訓(xùn)練圖像),以及結(jié)合合成數(shù)據(jù)訓(xùn)練后更好的Mask2Former、SegFormer、Segmenter模型的checkpoints。
TL;DR
不同于以往的一些工作利用合成數(shù)據(jù)提升few-shot performance(只用少量的真實數(shù)據(jù)),我們希望利用合成數(shù)據(jù)直接提升fully-supervised performance(用全量的真實數(shù)據(jù)),這更有挑戰(zhàn)性。
我們利用semantic image synthesis模型來從semantic mask產(chǎn)生diverse的合成圖像。然而,直接將這些合成圖像加入訓(xùn)練,其實并不能提升real-image baseline,反而會損害性能。
因此,我們設(shè)計了一個noise filtering策略以及一個image re-sampling策略來更有效地學(xué)習(xí)合成數(shù)據(jù),最終在ADE20K(20,210張真實圖像)和COCO-Stuff(164K張真實圖像)的各種模型上都能取得提升。此外,我們發(fā)現(xiàn)結(jié)合我們的策略后,只利用合成數(shù)據(jù)也可以取得和真實數(shù)據(jù)comparable的效果。
Take-home Messages
在全量真實數(shù)據(jù)的基礎(chǔ)上,有效地利用合成數(shù)據(jù)并不容易,需要生成模型足夠好以及設(shè)計合適的學(xué)習(xí)合成數(shù)據(jù)策略。
在初始階段我們嘗試了多個GAN-based從mask生成image的模型 (e.g., OASIS[1]),盡管他們的FID指標(biāo)還不錯,但遷移到真實數(shù)據(jù)集上的表現(xiàn)很差(這里的遷移性能,指在合成數(shù)據(jù)集上訓(xùn)練但在真實驗證集上測試,ADE20K上的mIoU只有~30%)。
基于Stable Diffusion的mask-to-image synthesis model是更好的選擇,如FreestyleNet[2]。
在生成質(zhì)量比較高以及篩選策略比較合理的情況下,joint train合成數(shù)據(jù)和真實數(shù)據(jù)會優(yōu)于先用合成數(shù)據(jù)pre-train再用真實數(shù)據(jù)fine-tune的效果。
Introduction

FreestyleNet基于semantic mask產(chǎn)生的合成圖像,非常diverse以及逼真
Stable Diffusion (SD)等模型已經(jīng)取得了非常好的text-to-image生成效果,過去一年里,semantic image synthesis領(lǐng)域的工作也開始結(jié)合SD的預(yù)訓(xùn)練來從semantic mask生成對應(yīng)的image。其中,我們發(fā)現(xiàn)FreestyleNet[2]的生成效果非常好,如上圖所示。因此,我們希望用這些合成圖像以及他們condition on的semantic mask組成新的合成訓(xùn)練樣本對,加入到原有的真實訓(xùn)練集中,進(jìn)一步提升模型的性能。
簡單的失敗嘗試
我們首先檢查了這些合成圖像到真實圖像的遷移性能,即用合成圖像訓(xùn)練但在真實圖像的驗證集上測試。我們用SegFormer-B4在真實圖像上訓(xùn)練可以取得48.5的測試mIoU,然而用比真實訓(xùn)練集大20倍的合成數(shù)據(jù)訓(xùn)練后,只得到了43.3 mIoU。此外,我們也嘗試混合真實數(shù)據(jù)和合成數(shù)據(jù)(會對真實數(shù)據(jù)上采樣到和合成數(shù)據(jù)一樣多,因為其質(zhì)量更高),然而也只取得了48.2 mIoU,依然落后于僅用真實圖像訓(xùn)練的結(jié)果。
因此,我們希望能更有效地從這些合成數(shù)據(jù)中進(jìn)行學(xué)習(xí)。
Motivation
由于上述合成數(shù)據(jù)的結(jié)果并不好,我們更仔細(xì)地觀察了一下合成數(shù)據(jù)集,發(fā)現(xiàn)其中存在著很多合成錯誤的區(qū)域,如下圖所示的紅色框區(qū)域。這些合成錯誤的區(qū)域加入到訓(xùn)練集中后會嚴(yán)重?fù)p害模型的性能。

紅色框內(nèi)的合成結(jié)果是錯誤的
此外,不同的semantic mask對應(yīng)著不同的場景,不同的場景的學(xué)習(xí)難度其實是不一樣的,因此它們所需的合成訓(xùn)練圖像的數(shù)量也是不一樣的。如下圖所示,大體上來看,從左至右semantic mask對應(yīng)的場景的難度是逐漸增加的,如果對每張mask產(chǎn)生同樣數(shù)量的合成圖像去學(xué)習(xí)的話,那么這些簡單的mask對應(yīng)的圖像就可能會主導(dǎo)模型的學(xué)習(xí),模型的學(xué)習(xí)效率就會很低。

不同的semantic mask對應(yīng)的場景的難度是不一樣的,大體上來看,從左至右難度逐漸增加
Method
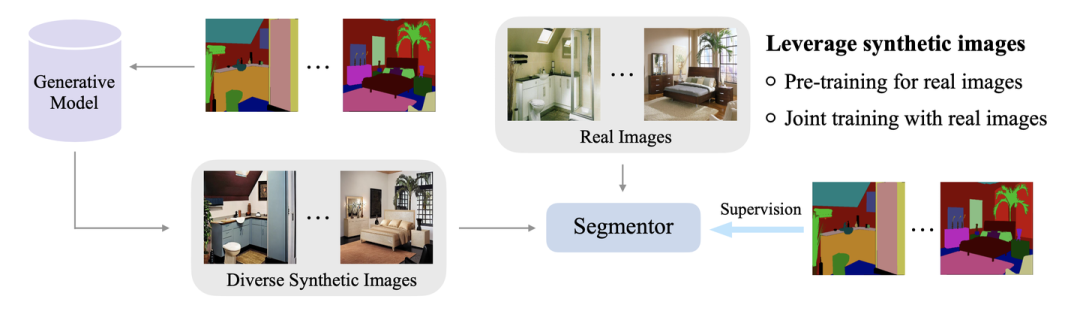
有了上述的兩個motivation,具體的做法是非常簡單的。
Filtering Noisy Synthetic Regions
針對第一點motivation,我們設(shè)計了一個noise filtering的策略,來忽略掉合成錯誤的區(qū)域。具體來說,我們利用一個在真實圖像上訓(xùn)練好的模型去計算每張合成圖像和它對應(yīng)的semantic mask之間的pixel-wise loss,直觀來看,合成錯誤的區(qū)域 (pixels)會呈現(xiàn)比較大的loss。此外,loss的大小也跟不同類別本身的難度有關(guān)。

Hardness-aware Re-sampling
針對第二點motivation,我們設(shè)計了一個hardness-aware re-sampling策略,來讓我們的數(shù)據(jù)合成以及訓(xùn)練更加偏向比較難的場景 (semantic mask),如下圖所示。

為harder的semantic mask產(chǎn)生更多的合成圖像,而減少簡單的mask的合成圖像

Learning Paradigms
我們探討了兩種從合成圖像中進(jìn)行學(xué)習(xí)的范式,分別是:
Pre-training: 用合成圖像pre-training,然后用真實圖像進(jìn)一步fine-tuning
Joint training: 混合真實圖像和合成圖像(會對真實圖像上采樣到與合成圖像同樣的數(shù)量)一起訓(xùn)練
簡單來說,我們發(fā)現(xiàn)在生成質(zhì)量比較高以及篩選策略比較合理的情況下,joint training的表現(xiàn)會更好一些。
Experiment
對比合成圖像和真實圖像遷移到真實測試集的性能
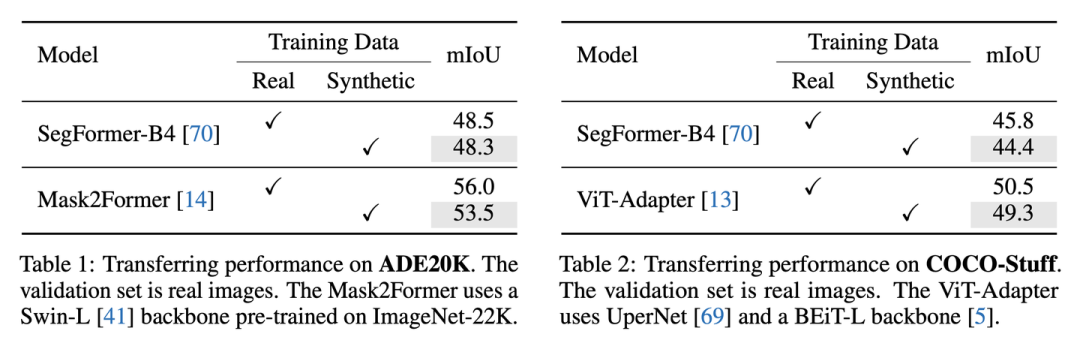
用真實圖像或合成圖像進(jìn)行訓(xùn)練,并在真實驗證集上測試
可以看到,在多種模型上,用合成圖像遷移到真實驗證集都可以取得和真實訓(xùn)練集comparable的效果。
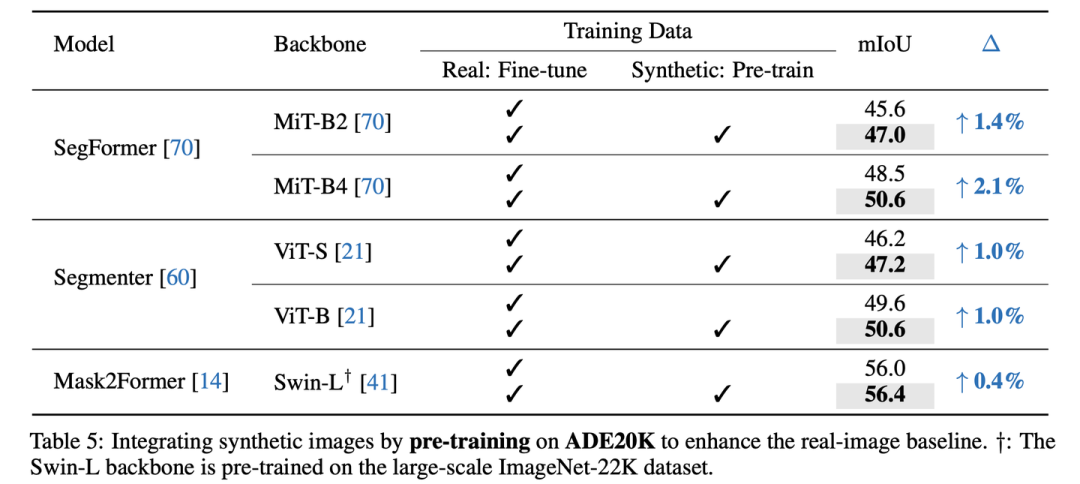
用合成圖像進(jìn)一步提升全監(jiān)督的分割模型性能
Joint training on ADE20K
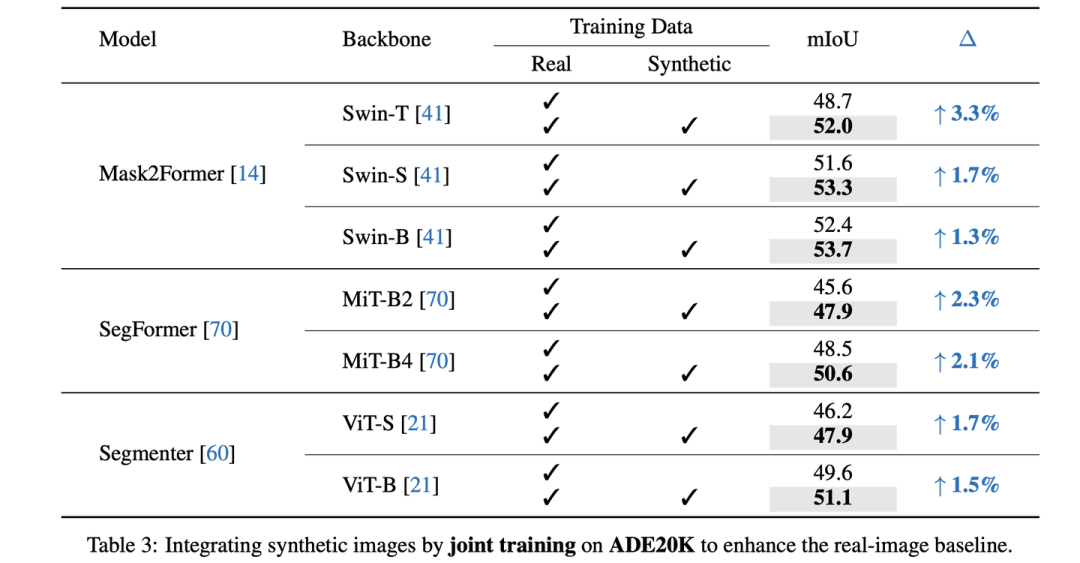
當(dāng)加入了合成數(shù)據(jù)后,真實圖像的全監(jiān)督性能獲得了顯著的提升,特別是對于Mask2Former-Swin-T,我們將mIoU從48.7提升至了52.0(+3.3);對于SegFormer-B4,從48.5提升至了50.6 (+2.1)。
Joint training on COCO-Stuff-164K
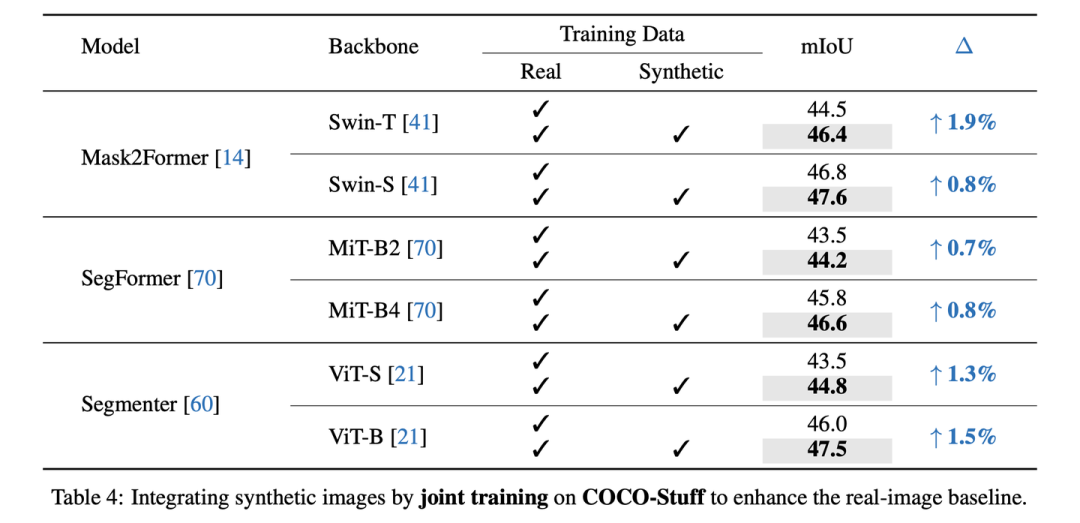
COCO-Stuff-164K由于原本的真實數(shù)據(jù)量很大,所以更難提升,但我們在Mask2Former-Swi-T上仍然取得了+1.9 mIoU的提升。
Pre-training with synthetic images on ADE20K
Ablation Studies
我們的noise filtering和hardness-aware re-sampling的必要性
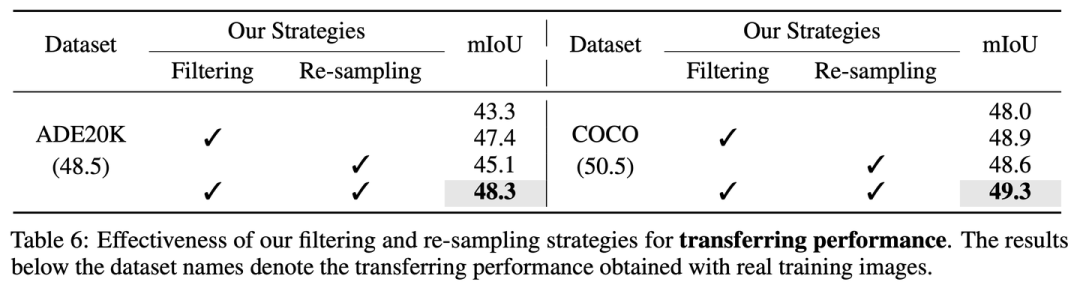
在沒有filtering和re-sampling的情況下,F(xiàn)reestyleNet產(chǎn)生的合成圖像在ADE20K和COCO的真實集上只能得到43.3和48.0的遷移性能,遠(yuǎn)遠(yuǎn)劣于真實訓(xùn)練圖像的遷移性能(ADE20K: 48.5和COCO: 50.5),而應(yīng)用我們的策略后,純合成圖像的遷移性能可以提升至48.3 (ADE20K)和49.3 (COCO),十分接近真實訓(xùn)練圖像的表現(xiàn)。

在joint training下,我們的兩項策略也是十分有效的,如果沒有這兩個策略,混合合成圖像和真實圖像只能取得48.2的mIoU (真實圖像:48.5),而加入我們的策略后,可以將真實圖像48.5的baseline提升至50.6。
合成圖像的數(shù)量

Nmax 控制單張mask最多產(chǎn)生多少張合成圖像,在沒有filtering和re-sampling的情況下,增加合成圖像的數(shù)量反而帶來了更差的遷移性能;而在經(jīng)過filtering和re-sampling后,Nmax從6增加到20可以帶來穩(wěn)定的遷移性能的提升。
更多的ablation studies請參考我們的文章。
Conclusion
在本工作中,我們通過從semantic mask產(chǎn)生合成圖像,組成大量的合成訓(xùn)練數(shù)據(jù)對,在ADE20K和COCO-Stuff-164K上顯著提升了多種語義分割模型在全監(jiān)督設(shè)定下的性能。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7239瀏覽量
90990 -
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41016 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25275
原文標(biāo)題:NeurIPS 2023 | 漲點!FreeMask:用密集標(biāo)注的合成圖像提升分割模型性能
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI時代 圖像標(biāo)注不要沒苦硬吃

基于RV1126開發(fā)板實現(xiàn)自學(xué)習(xí)圖像分類方案

大模型預(yù)標(biāo)注和自動化標(biāo)注在OCR標(biāo)注場景的應(yīng)用
數(shù)據(jù)標(biāo)注服務(wù)—奠定大模型訓(xùn)練的數(shù)據(jù)基石
標(biāo)貝數(shù)據(jù)標(biāo)注服務(wù):奠定大模型訓(xùn)練的數(shù)據(jù)基石

自動化標(biāo)注技術(shù)推動AI數(shù)據(jù)訓(xùn)練革新
標(biāo)貝自動化數(shù)據(jù)標(biāo)注平臺推動AI數(shù)據(jù)訓(xùn)練革新
AI自動圖像標(biāo)注工具SpeedDP將是數(shù)據(jù)標(biāo)注行業(yè)發(fā)展的重要引擎





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論