 科大訊飛深度解析DeepSeek-V3/R1推理系統成本
科大訊飛深度解析DeepSeek-V3/R1推理系統成本
本篇分析來自科大訊飛技術團隊,深度解析了DeepSeek-V3 / R1 推理系統成本,旨在助力開發者實現高性價比的MoE集群部署方案。感謝訊飛研究院副院長&AI工程院常務副院長龍明康、AI工程院AI云平臺研發部總監李珍松、訊飛星辰MaaS團隊的研究對本文的貢獻。
一、分析團隊背景簡介
分析團隊來自科大訊飛星辰MaaS團隊,從語音小模型時代到認知大模型時代,積累了豐富的大規模AI推理服務集群優化及運營經驗,也支撐了國內首個全國產萬卡算力訓推集群的上線。
二、分析目的
在MaaS賽道中,大家受益于DeepSeek-V3/R1開源的壯舉,但也面臨著成本方面的壓力
由于DeepSeek未開源推理服務器的整體集群方案以及公開運營的更多細節,大部分MaaS產商的性能/成本優化可能遠不及DeepSeek當前優化的水平,我們希望通過更細節的過程分析,使得性能/成本綜合優化方向更加清晰,結合DeepSeek開源的高性能庫,更快實現高性價比的MoE集群部署方案
本文力求從應用視角計算估算相關數據,方便大家參考,由于存在大量估算,難免存在錯誤,請大家指正
DeepSeek原文鏈接,本文中的“原文”特指該鏈接內容
三、影響成本的關鍵因素
快速理解DeepSeek MoE推理邏輯架構
我們將DeepSeek MoE系統工程架構類比成醫院就醫問診流程架構,方便大家理解。
MoE
依靠“專家”機制激活參數更小,更便宜
Prefill與Decode分離,計算更高效
KVCache緩存降低重復上下文計算
從單機到幾十機,負載均衡調度復雜性上升,既要降低用戶響應時間,又要提升系統吞吐率,實現低成本,還要保障系統的可靠性(大專家EP并行工程關鍵難點)
醫院
不用花錢看更貴的“全科醫生”,看個別“專科醫生”
問診和醫技流程分離,流程更高效
歷史電子病歷、檢查報告,減少重復檢查
從全科室到多專科室,預約導診分流復雜度上升,既要縮短病人看病時間,也要提升各科室的問診效率,實現醫院的效益,還要保障關鍵流程有效運轉
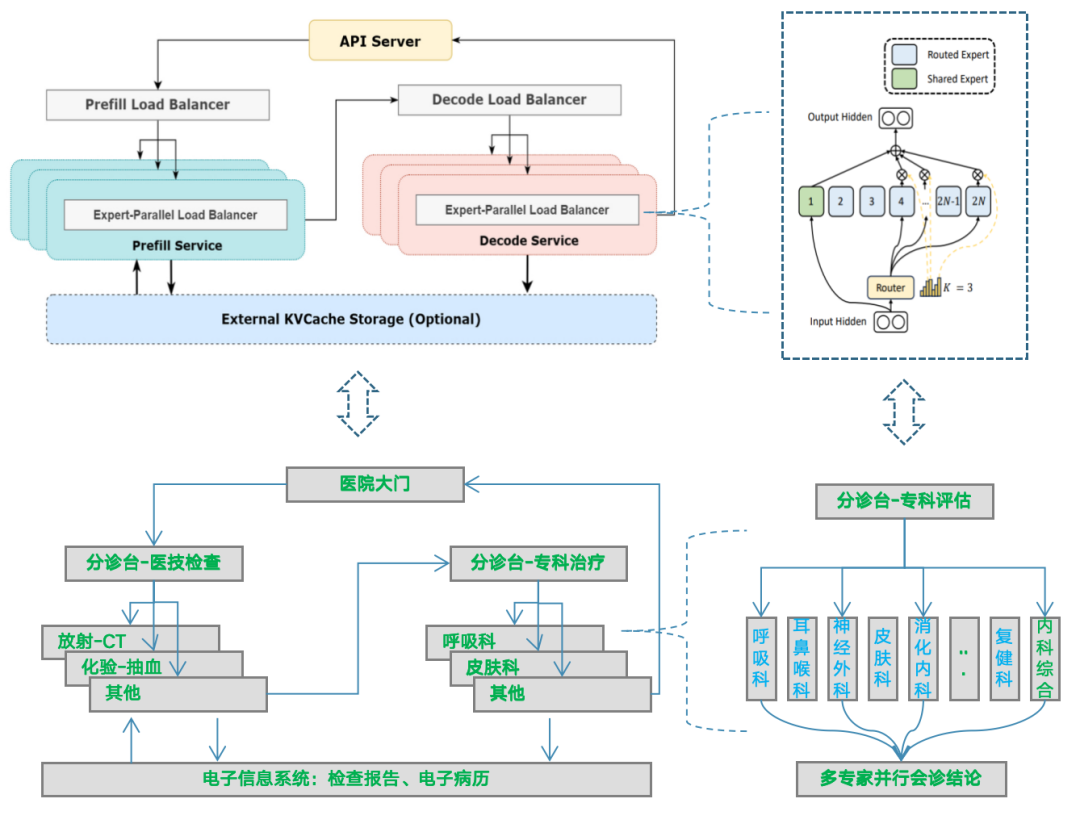
MoE推理集群部署架構概覽
備注:圖片來自知乎
關鍵概念描述
應用側
APP:DeepSeek Web/APP端的C端用戶請求
API:DeepSeek API側的B端用戶請求
DAU:日均活躍用戶
total_usage:日均總使用次數
max_con:日峰值并發用戶請求數
TTFT:首token響應時間
TPOT:平均每token輸出的時延,從原文中得知約為50ms(平均輸出速率為 20~22 tps)
系統側
API:指為API開放所搭建的平臺服務器集群,由于具有較好的邊際成本遞減效應,故不納入成本關鍵因素分析
Prefill 與 Decode:分別對應原文中PD分離架構中的兩個集群
N:M:由于我們并不清楚P與D的單元化集群配比是不是1:1,所以先假設是N:M,基于原文得知4*N+18*M=278
total_in/kvcache_rate/total_out/throughput_p/throughput_d:分別映射到原文中的總token與單機吞吐數據
運營側
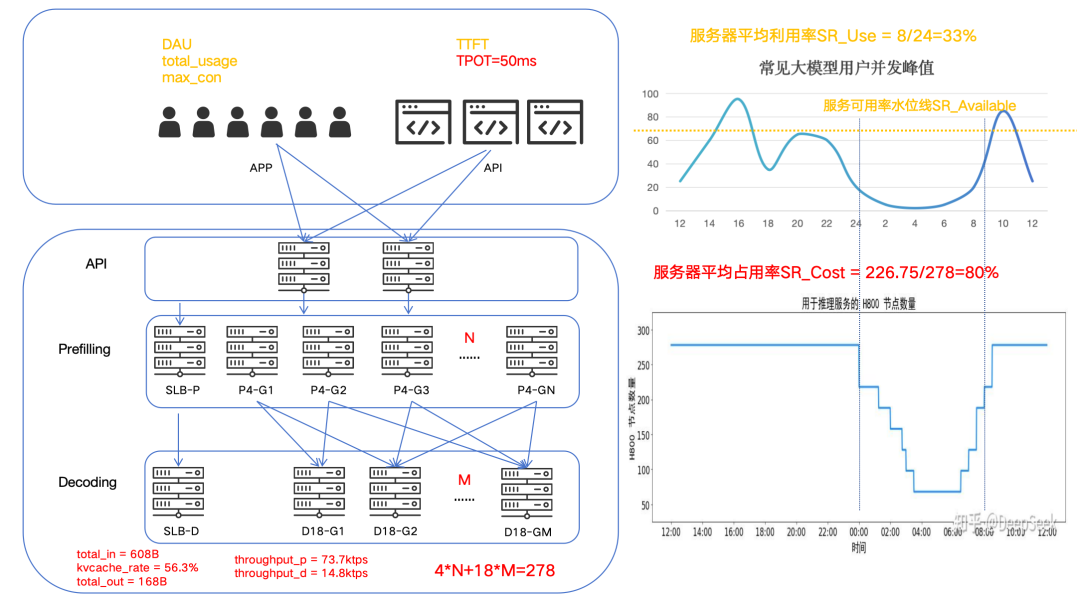
SR_Cost:原文中提到的服務器平均占用率,由原文可知SR_Cost=226.75/278≈82%
SR_Use:指服務器集群利用率,通常可以基于服務水位采樣監控值曲線求面積,反算后得到利用率
SR_Available:指服務高峰期容量超限時,可用容量水位占實際用戶請求水位的比例
四、關鍵數據項分析過程
服務器集群利用率估算
原文中提到的服務器占用率,我們首先要將這個概念轉化為服務峰值容量、服務集群利用率這兩個概念。
DeepSeek-V3 和 R1 推理服務占用節點總和,峰值占用為 278 個節點,平均占用 226.75 個節點(每個節點為 8 個 H800 GPU)
傳統互聯網應用中通常會用并發用戶請求數或者QPS每秒請求任務數來量化系統的容量水位,由于AI類計算任務(如語音識別、語音合成、大模型交互)單次請求的計算時長并不固定,因此通常使用并發用戶請求數來衡量系統容量水位。使用這種方式統計并實現相應的負載調度能更好的保障SLA中的關鍵SLO(如成功率、TTFT、TPOT等)。
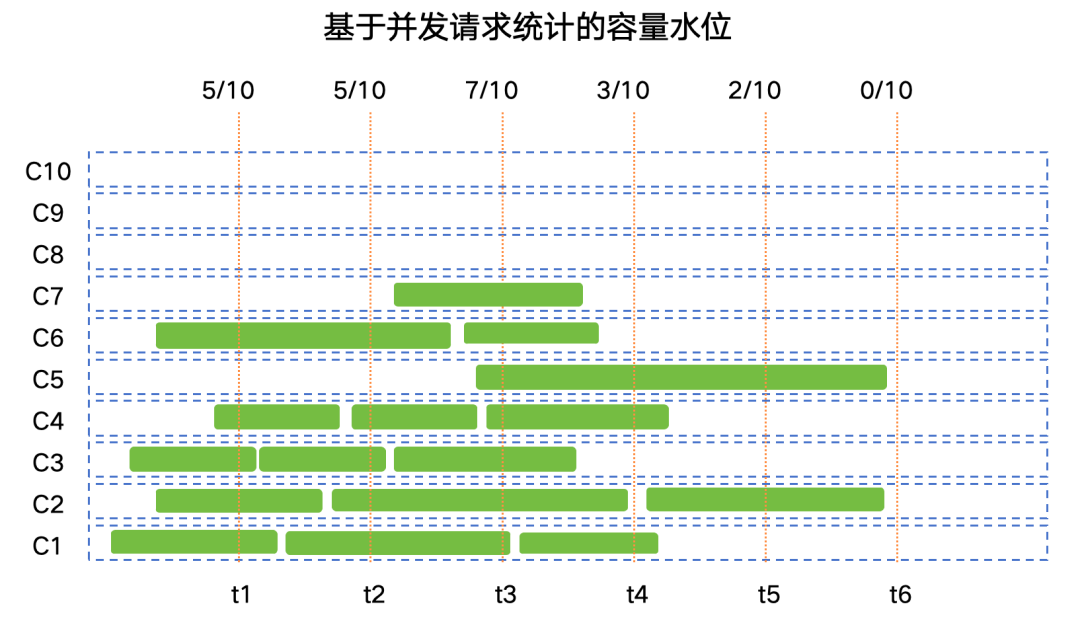
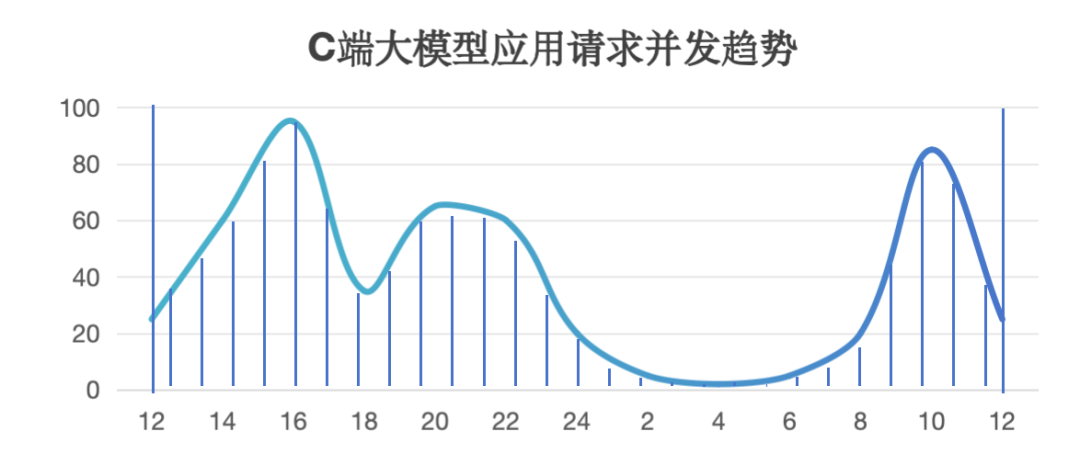
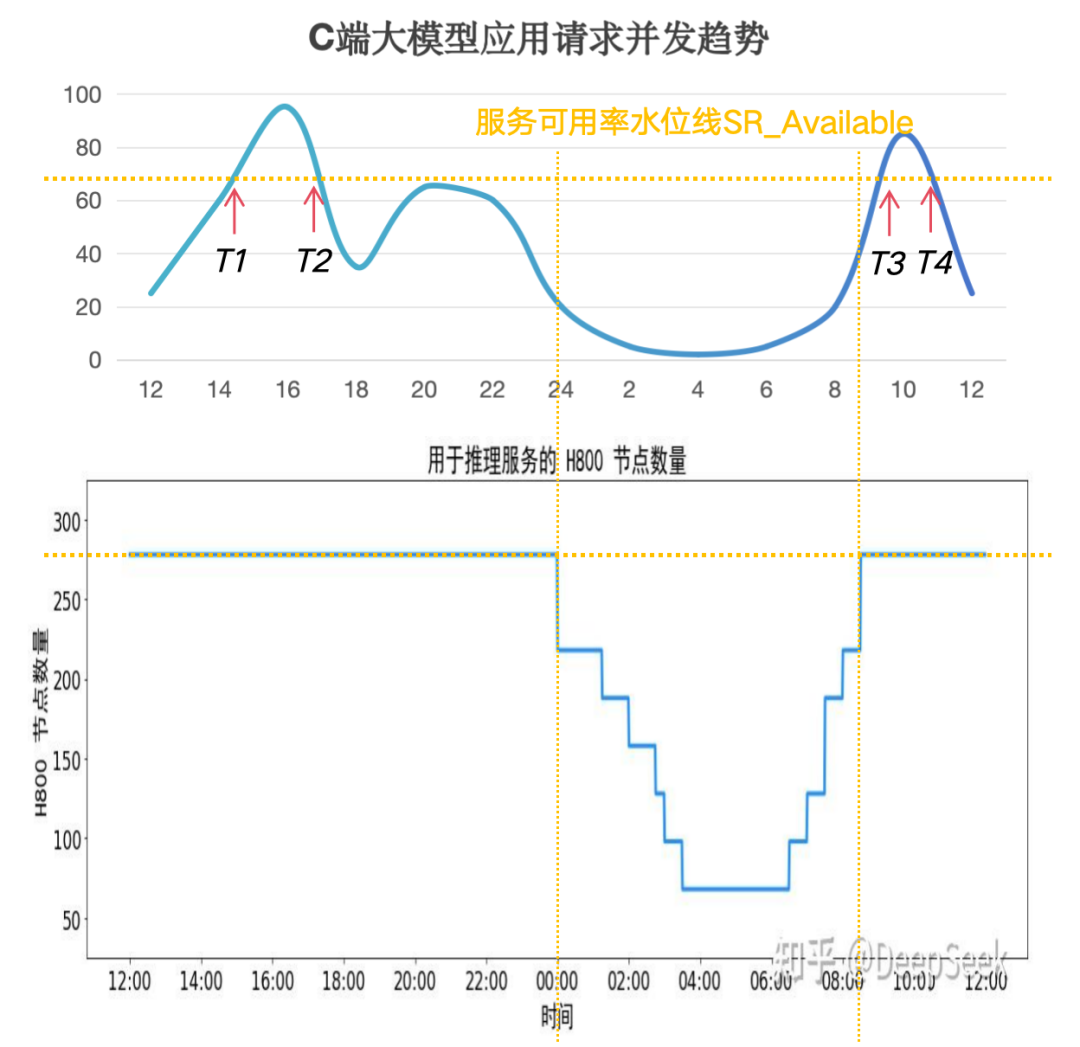
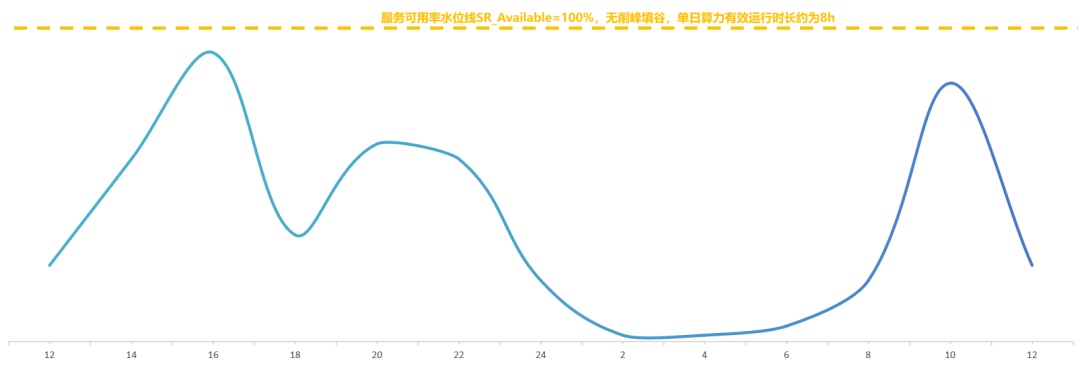
通常AI計算是一個分布式集群,所以需要采樣集群中所有節點的實時容量水位情況,max_con就是系統的并發峰值,也就是服務峰值容量(不考慮少量的容量冗余)。有了這個容量圖,就可以計算服務集群利用率。我們以訊飛星辰MaaS平臺上工作日24小時區間內常見的C端大模型應用請求并發趨勢為例(縱軸為并發容量%比例),通過計算采樣陰影部分的面積求和后與整體面積的比例估算后,得到服務集群利用率SR_Use ≈ 33%,即整個集群如果按照并發峰值水位一直計算,有效計算時間SR_Use_Time = 8小時。
我們將這個趨勢圖與原文中的服務器占用圖進行對比,在波谷階段基本是一致的。根據原文信息可以測算出服務器平均占用率SR_Cost≈82%,這個值并不是我們提到的集群利用率,結合集群利用率估算后,可能會使得單機吞吐峰值大幅上漲。我們希望結合高峰期系統拒絕請求及恢復的時間點,估算出服務可用率的水位線SR_Available的值。
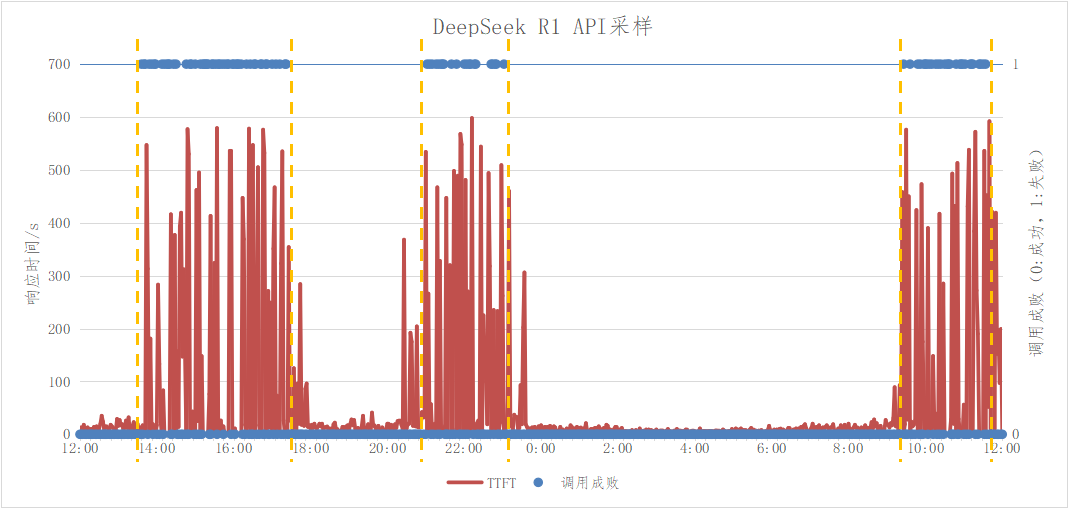
備注:圖片來自知乎 我們分別對DeepSeek API和網頁進行了V3/R1采樣測試,時間在工作日3月13日~14日,得到如下數據:
對V3 API/網頁進行全天24h采樣測試,全天測試成功率100%,表明V3請求峰值未超過集群容量
對R1 API/網頁進行全天24h采樣測試,全天測試存在3個時間段成功率下滑、且對應時間段的請求TTFT顯著增長,分別為13:36~17:22,21:02~23:02,09:26~11:34,表明在該時間段內請求峰值超過集群容量
由此可見,V3/R1存在集群隔離情況,且V3容量正常,推測V3使用量相比而言不高
在測試過程中,順便統計了低峰期首token的響應時間均值TTFT≈9秒
以上測試時間是在原文發出之后,選擇的工作日時間測試,流量特征相對吻合
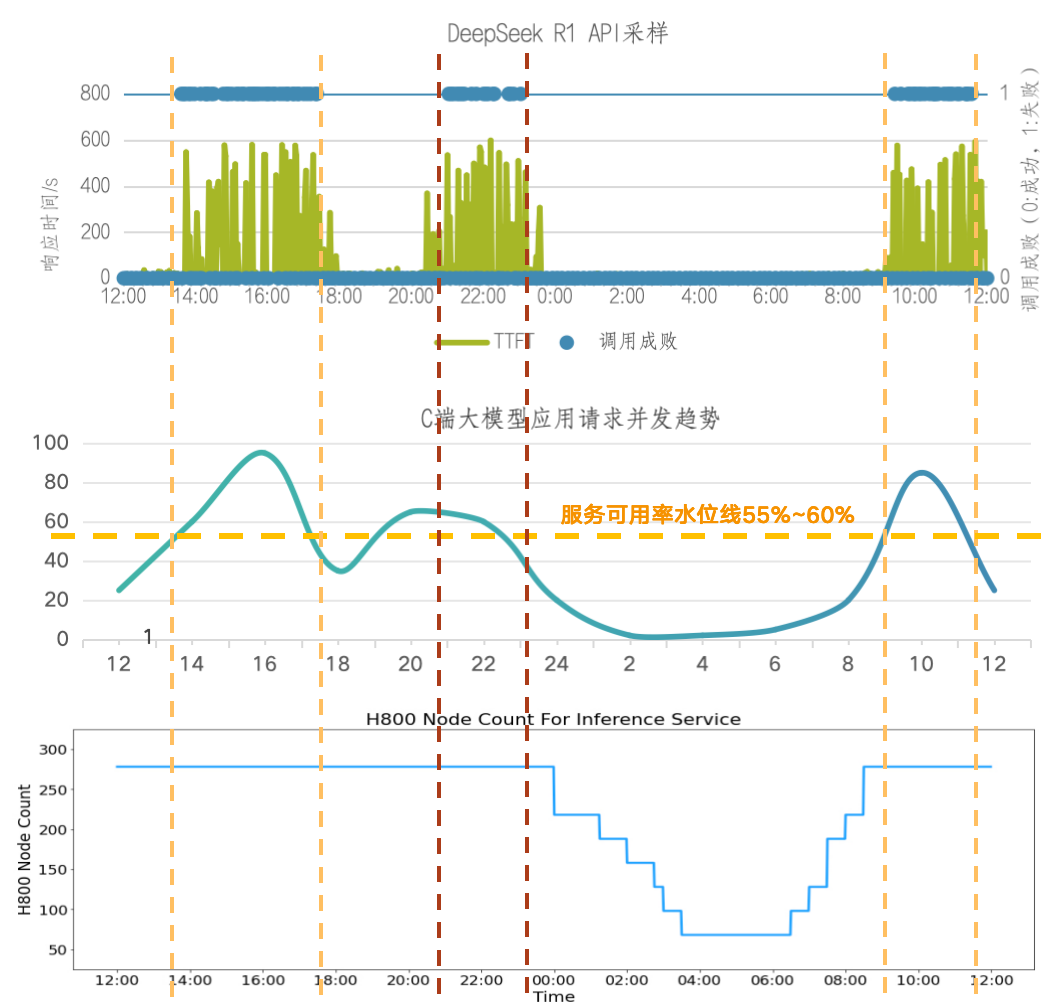
將R1成功率下滑時間段與C端并發趨勢圖進行對比,可以看到除了晚上的峰值時間不完全一樣,其他兩個峰值基本吻合,由此可以大概估算出R1集群服務可用率水位線SR_Available≈60%。
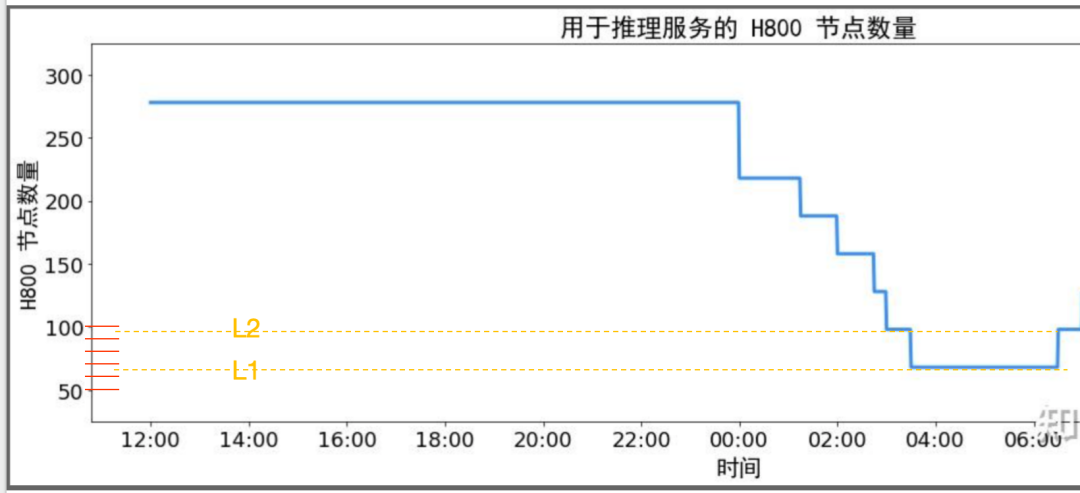
從夜間H800節點圖可以看出最小集群時預留了60~70個節點,約2~3個部署單元。假設該集群中存在大量API24小時跑特定數據處理任務,那API對高利用率的貢獻應該局限在這70個節點內。小結一下,DeepSeek公開的利用率相關的幾個數據整體合理,從集群整體層面提高利用率的可能性方法如下:
削峰,犧牲一定的SLA成功率,節省了峰值時需要額外增加但低谷時利用率偏低的服務器,預計削峰的可用率水位在60%以上。MaaS產商可以根據SLA做分級API產品
填谷,將實時任務與離線任務形成一體化集群,使用潮汐調度技術實現集群的利用率提升,降低實時任務服務器低谷期的占用攤銷18%,需要足夠的離線業務體量。MaaS產商可以發力離線產品的業務體量
服務器集群部署單元PD配比估算驗證
原文中提到每個Prefill部署單元4個節點,Decode部署單元18個節點,總集群278個節點,我們需要計算出Prefill和Decode部署單元的配比,以便后續進一步分析吞吐數據。估算步驟如下:
首先4*N+18*M=278,(N,M)=(65,1),=(56,3),=(47,5),=(38,7),=(29,9),=(20,11),=(11,13),=(2,15)
通過低谷期的節點數可以看出,L1水位約4*X1+18*Y1 在 60~70 (只能是偶數),L2擴容小于2個Decode單元36臺,即4*X2+18*(Y1+1)在 90~100(只能是偶數)
我們估計N=29,M=9,N:M ≈ 3.2。在L1水位時,X1=7,Y1=2,X1:Y1 ≈ 3.5,節點數為64。在L2水位時,X2= 10,Y1+1=3, X2:(Y1+1)≈ 3.3,節點數為40+54=94。整體與低谷水位圖吻合
Y1=2,意味著最低谷期時保留了一個V3部署單元,一個R1部署單元
備注:圖片來自知乎文章《DeepSeek-V3 / R1 推理系統概覽》 我們從原文中的吞吐的視角來計算一下這兩個值,基本吻合:
輸入608B*(1-56.3%)≈ 266B = 32.2k *24*3600*4*N,N≈23.9,考慮到機器占用率SR_Cost 82%,N≈23.9/82%≈29.15
輸出168B=14.8k*24*3600*18*M,M≈7.3,M≈23.9/82%≈8.9
基于這樣的配比,我們需要驗證Prefill/Decode集群的處理能力是否一致。我們依舊以簡化后的并發請求模式來計算相關值。在并發量一定的請求下,如果想保持Prefill/Decode兩個階段不積壓,需要在平均單位時間內,兩階段完成的計算請求數一樣,如果再簡化一下,就是每秒處理請求數QPS一樣。通過計算,兩階段的QPS十分接近,符合預期。
假設平均每個請求的輸入長度為Avg_In = 608X tokens,非緩存計算的輸入長度為Avg_In_P = 266X tokens,平均輸出長度為Avg_Out = 168X tokens
Prefill階段的QPS_P = 73.7k *(1 - 56.3%)*4*29 tps /Avg_In_P ≈ 14045/X
Decode階段的QPS_D = 14.8k*18*9 tps/Avg_Out ≈ 14271/X
小結一下,考慮到V3和R1的輸入/輸出平均長度不一樣,PD的配比也會不一樣,但總的來說,公布的數據峰谷圖、吞吐、集群配比上能高度吻合,公開數據合理。其中Prefill部署單元29個共116個節點,Decode部署單元9個共162個節點。
單機吞吐峰值與理論值估算驗證
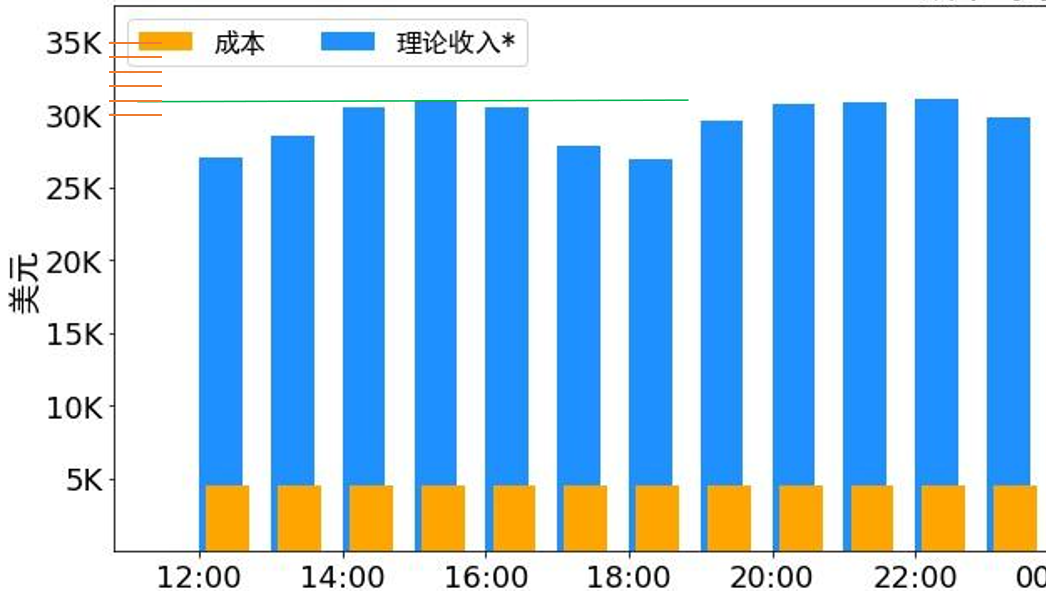
前面估算集群利用率,是為了將單機吞吐的平均值按照利用率換算為單機吞吐的峰值,這樣能更好的對比與理論值的差異,為工程優化提供參考。考慮到原文中集群存在削峰的情況,我們直接選取峰值階段1小時的吞吐數據來估算單機吞吐峰值。我們以峰值區間15:00~16:00為例:
該時間段服務器節點278,其中Prefill節點116個,Decode節點 162個,從下圖可以估算出該小時內理論收入為$31k
DeepSeek R1 的定價:$0.14 / 百萬輸入 tokens (緩存命中),$0.55 / 百萬輸入 tokens (緩存未命中),$2.19 / 百萬輸出 tokens 輸入 token 總數為 608B,其中 342B tokens(56.3%)命中 KVCache 硬盤緩存。輸出 token 總數為 168B 平均每臺 H800 的吞吐量為:對于 Prefill 任務,輸入吞吐約 73.7k tokens/s(含緩存命中);對于 Decode 任務,輸出吞吐約 14.8k tokens/s
假設該峰值區間的總輸出token為X 百萬,按輸入/輸出平均比例估計,則實際計算的總輸入token數為1.583X,命中Cache 的總輸入token數為2.036X, 結合該時段理論收入$31k與各部分單價,可得X=9.265B,累計總輸入token為33.531B(其中14.67B 未命中Cache)
該區間時間為3600秒,與Prefill的總節點數116計算,得到單節點平均輸入吞吐約為35.13k tokens/s(未含緩存命中),與Decode的總節點數162計算,得到單節點平均輸出吞吐約為15.89k token/s,與公布的數據增長了8%,整體在合理的增長范圍
考慮R1/V3集群為隔離部署,且V3請求峰值未超過集群容量,故高峰期間實際單機吞吐峰值還會略高于上述吞吐值
社區關于原文中公開的單機吞吐的理論值的分析,已經做的比較深入和全面了,其中zarbot與Han Shen的分析比較有代表性,此處引用了Han Shen其中一篇分析 https://zhuanlan.zhihu.com/p/29540042383。
H800 (BF16 kvcache)最佳離線吞吐為單卡2844 tokens/s,由two-mircobatch overlapping的 DP288-EP288 - bmla64 方案得到
H800 (FP8 kvcache)最佳離線吞吐為單卡3121 tokens/s,由two-mircobatch overlapping的 DP288-EP288- bmla128 方案,或者DP48-EP48- bmla128 方案得到
H800 (FP8 kvcache)最佳線上吞吐(滿足20 tokens/s 左右用戶延遲)為2909 tokens/s, 由single-batch compute-communication overlapping的DP24-EP24- bmla128 方案得到。
H800 (BF16 kvcache)最佳線上吞吐(滿足20 tokens/s 左右用戶延遲)為2844 tokens/s,由two-mircobatch overlapping的DP288-EP288- bmla64 方案得到
在8卡H800上,單機吞吐的理論值在22.75k tokens/s以上。本節中計算值15.89k token/s在理論值的70%,故數據在合理區間。小結一下,在服務容量高峰時段,經過估算,單節點平均輸入吞吐約為35.13k token/s,單節點平均輸出吞吐約為15.89k token/s,較官方公布平均吞吐約增長8%,公開數據合理,大家關注的輸出吞吐部分,在理論值22.75k tokens/s范圍內。
用戶請求行為粗略估算
本節我們將用一些相對粗略的公開數據,大致估算一下用戶的平均輸入/輸出。由于缺乏的數據輸入項過多,預估與實際值會存在很大的誤差,請側重參考輸入/輸出等用戶行為因素如何影響集群的配比。用戶規模,在原文發出來的一周,我們咨詢了相關C端運營,通過擬合各類數據,預估對應時間段在2400W左右。通過DeepSeek網頁端提問,大概也得到了2000~3000W日活的范圍,所以我們以DAU=24M為準。假設該用戶數也包含了API側toB toC的日活用戶,整體而言DeepSeek自有流量的日活占絕大頭。
平均輸出,相比輸入的長度受用戶使用次數和連續會話輪次影響,模型的輸出平均值一般比較穩定。我們參考星辰MaaS上 V3和R1的輸出均值,分別為300和1000 tokens。分布比例,結合上文中提到V3在容量上比R1空閑大,我們認為用戶使用V3的總次數低于R1,假設V3占比為r:
V3的每日總使用次數為168B*r/300=560M*r
R1的每日總使用次數為168B*(1-r)/1000=168M*(1-r)
平均次數,V3的平均用戶使用次數為560M*r/24M=23.33*r,R1為168M*(1-r)/24M=7*(1-r)。平均輪次,輪次越大,平均輸入因疊加歷史輸出會越長,假設V3的平均輪次為n,R1的平均輪次為m,平均輪次一定是小于等于平均次數,即n ≤ 23.33*r;m ≤ 7*(1-r)。平均輸入,平均輸入通常與用戶平均使用上下文輪次有關,除此之外,由幾個部分組成。
用戶的直接輸入,一般20 tokens左右,在平均輸出中的成分為20*(n+1)/2=10n+10
上輪輸出,R1的思維鏈約占輸出的50%,不會作為下一輪的輸入,V3不存在該截斷,故V3為300*(n-1)/2=150n-150,R1為1000*50%*(m-1)/2=250m-250
聯網搜索,聯網搜索按照星辰MaaS統計,通常請求觸發聯網比例在15~25%之間,此處取20%。每次搜索網頁全文按照5K tokens保守估計,均攤到每次的平均輸入取整為1000 tokens,這部分tokens不會作為上下文歷史累加

在粗估數據下,V3 token占比在35%時,用戶行為相對符合直覺,V3的平均輸入在2000 tokens左右,R1的平均輸入在1800左右,日均總請求次數total_usage=560M*r+168M*(1-r)=3.05億次。
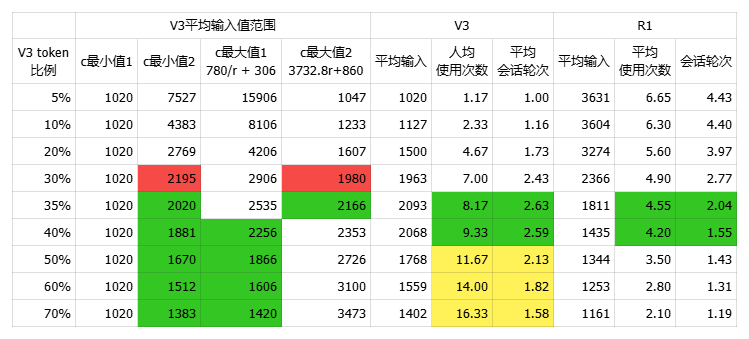
結合上一節中高峰期時段的數據,來粗略估算計算節點的分布情況,可得知下表V3的PD配比為20:3,共135個節點,R1的為9:6,共143個節點。整體來說Decode階段的計算單元R1比V3多符合預期,Prefill階段V3占用過多計算單元略顯意外,按照利用率估算過程中的值來看,V3的峰值是未觸發容量上限的,這可能與我們的平均輸出預估以及DAU的誤差有關,但也可能是為了在高峰期將預期使用R1的用戶請求引導到性價比更高的V3。
可得X=9.265B,累計總輸入token為33.531B(其中14.67B 未命中Cache)
該區間時間為3600秒,與Prefill的總節點數116計算,得到單節點平均輸入吞吐約為35.13k tokens/s(未含緩存命中),與Decode的總節點數162計算,得到單節點平均輸出吞吐約為15.89k token/s

小結一下,經過粗略的估算,當V3的輸出流量占比在35%時,V3平均輸入為2000 tokens,輸出300tokens,R1平均輸入為1800 tokens,輸出為1000 tokens,V3計算單元的PD配比為20:3,R1為9:6。
集群高并發高吞吐策略分析
大專家EP并行計算的特點是需要高并發的請求量,來激活集群各個維度的性能上限,獲得高吞吐率。首先分析原文中集群的并發情況。Decode階段并發:
結合H800的單機token吞吐、平均輸出速率可以知悉Decode節點單機并發≈14.8k/21* ≈ 705
按官方公開信息1個Decode部署單元為18個節點,故Decode最小部署單元并發≈705*18 = 12.69k
根據上文分析Decode節點總數為162,則集群整體并發數max_con≈705*162=114.21k
Prefill階段并發:
根據上節中的粗略估算的數據,R1平均輸入長度為1800 tokens,R1的TTFT=9s
R1單機并發=73.7k/1.8k * 9=368.5
R1Prefill最小部署單元并發=368.5*4 =1474
通常在推理計算過程中,在高并發、高并行計算獲得高吞吐的同時,也需要權衡延遲因素TTFT、TPOT,其關系如下:
并發提升初期,單機吞吐值、TTFT隨著并行度提升呈現非線性增長趨勢;
當并發超過一定閾值后,并行度提升帶來的計算量達到服務器計算瓶頸,吞吐不再隨之提升,但TTFT因并行排隊、通信延遲等因素而持續增加;
上述趨勢可以從zarbot的分析中得到論證:單機Prefill吞吐在DP8并行策略下達到33741,在DP4并行策略下僅為28693,提高并行度一定程度可以提升單機吞吐。MaaS廠商如果期望得到更低的TTFT,可能需要以更低的單機吞吐為代價,來獲得用戶體驗的平衡。
文章鏈接 在TP=4,DP=8的部署方式下,H800單機Prefill TPS=33741.0;TPS(overlap)=52240.1 在TP=8,DP=4的部署方式下,H800單機Prefill TPS=28693.1;TPS(overlap)=41057.0
小結一下,原文中最小部署單元可支撐12.69k路并發,整個集群支撐114.21k路并發,要達到超低成本,需要有規模化的用戶請求才能支撐,MaaS廠商需要權衡好冷啟動階段的成本問題。若要達成更小的TTFT達到更優的用戶體驗,MaaS廠商需要考慮吞吐和首響平衡帶來的Prefill階段額外成本開銷。
低成本組合方案估算
最后,我們結合上述性能分析的各類影響因素,梳理了幾種典型場景下的成本方案,供參考。方案1,假設MaaS產商在白日不削峰、夜間無填谷的情況下,集群單日成本利潤率約為112%。

方案2,通過訓推一體、彈性調度等技術實現夜間波谷期資源回收填谷后,可有效降低服務成本,集群單日成本利潤率約為183.37%。
以夜間縮容區間00:00~08:00為例,55%水位線以下填谷收益約為(278-226.75)/278= 18.4%;55%水位線以上填谷收益為1/3;全天降本收益55%*18.4%+45%*1/3=25%

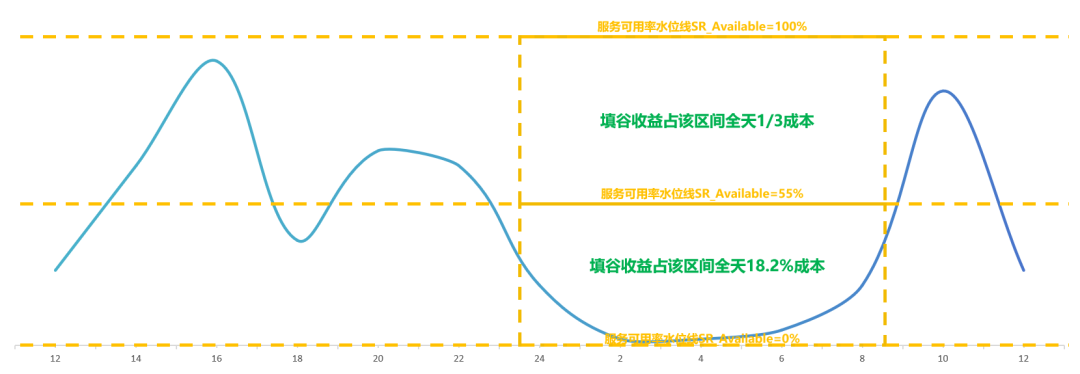
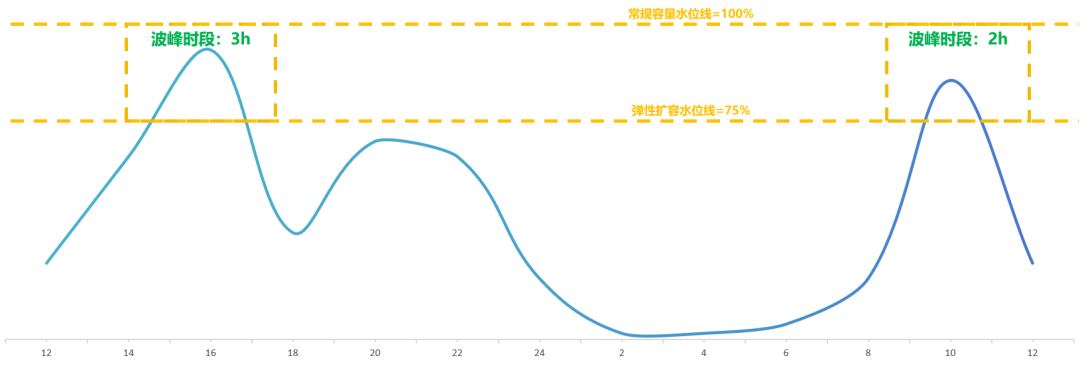
方案3,在方案2的基礎上再進一步,可以在日間波峰期間將訓練資源彈性擴容以應對流量峰值,進一步降低服務成本,單日成本利潤率約為234.16%。

五、MoE大模型成本優化方向總結
綜合上述分析,我們可以看到除了極致的推理性能及吞吐優化外,大模型成本與算力資源有效利用率、首響用戶體驗等體系化的綜合策略也息息相關。基于以上成本數據分析,MaaS產商的成本優化方向主要集中在以下幾點:
大專家EP并行方案優化,優化指標在H800上需要達到,Prefill單機達35.13k tokens/s(未含緩存命中),Decode單機吞吐達15.89k token/s,其他卡型可以參考性價比換算
集群潮汐調度,基于夜間波谷期算力潮汐調度,對MaaS業務低峰期資源回收填谷,有效降低推理算力成本25%。基于日間波峰期算力的彈性調度擴容,將75%水位線以上容量的增量資源成本由全天24h降低至5h,在夜間基礎上再降本11.4%
離線計算產品設計,通過離線產品補充峰谷期的計算空閑,提升集群利用率
差異化SLA產品,面向不同SLO及用戶體驗需求提供差異化MaaS服務,通過適當增加首token響應TTFT、降低平均每token輸出的時延TPOT、適當放棄峰值期間成功率,確保集群高利用率
規模化推廣,MoE超低成本依賴規模化用戶請求支持,冷啟動成本較高,選擇合適的部署方案應對用戶需求
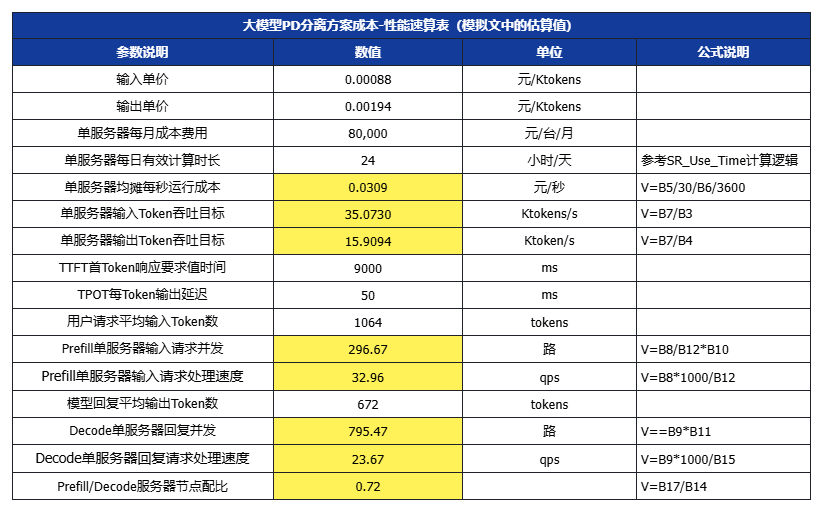
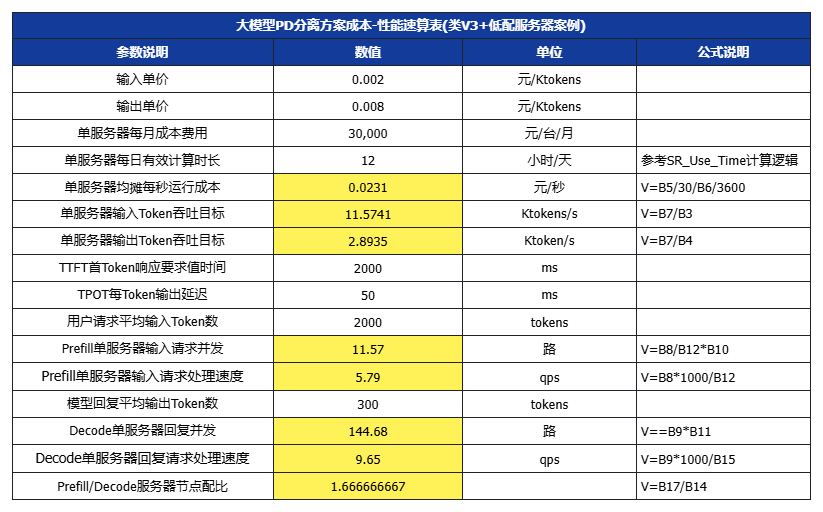
六、大模型成本-性能對照速算表
為了方便技術團隊設置技術優化目標及運營團隊設計產品價格,我們進一步提供了一個速算表,可以根據目標價格,結合不同的SLA/SLO、用戶場景輸入/輸出長度,以及服務器選型成本、集群利用率運營水平,來設置優化目標。(白色數值項可代入,黃色為公式計算)
假設平均每個請求的輸入長度為Avg_In = 608X tokens,非緩存計算的輸入長度為Avg_In_P = 266X tokens,平均輸出長度為Avg_Out = 168X tokens
設X=3
七、結語及展望
DeepSeek-V3/R1自開源后迅速轟動全球,以其領先的算法架構創新以及極致的系統性工程優化,贏得了全球從業者及用戶的尊重,這也讓無數研究員、工程師熱血澎湃!我們也看到在NVIDIA GTC 2025上,黃教主發布了性能超強的新一代Blackwell芯片。在條件受限以及硬件存在差距的情況下,我們唯有繼續從系統性角度進行極致的工程創新,方能補齊硬件上的短板,以極致的性價比迎接AI大模型應用的指數級增長!
-
開源
+關注
關注
3文章
3587瀏覽量
43475 -
科大訊飛
+關注
關注
19文章
837瀏覽量
62181 -
大模型
+關注
關注
2文章
3026瀏覽量
3825 -
DeepSeek
+關注
關注
1文章
773瀏覽量
1337
原文標題:萬字長文深度解析DeepSeek-V3 / R1 推理系統成本
文章出處:【微信號:訊飛開放平臺,微信公眾號:訊飛開放平臺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
科大訊飛發布星火深度推理模型X1,技術升級引領行業創新
AMD將DeepSeek-V3模型集成至Instinct MI300X GPU
云天勵飛上線DeepSeek R1系列模型

昆侖芯率先完成Deepseek訓練推理全版本適配

扣子平臺支持DeepSeek R1與V3模型
訊飛開放平臺支持DeepSeek
Deepseek R1大模型離線部署教程






 工商網監
工商網監
評論