") 利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(上)
利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(上)
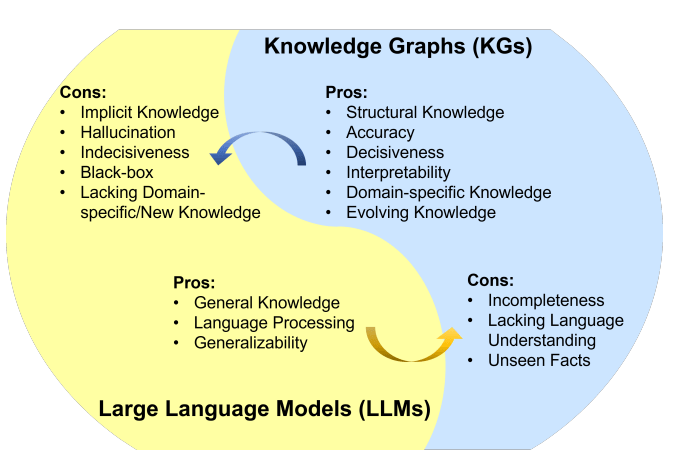
幻覺是在處理大型語言模型(LLMs)時常見的問題。LLMs生成流暢連貫的文本,但經(jīng)常產(chǎn)生不準確或不一致的信息。防止LLMs中出現(xiàn)幻覺的一種方法是使用外部知識源,如提供事實信息的數(shù)據(jù)庫或知識圖譜。
矢量數(shù)據(jù)庫和知識圖譜使用不同的方法來存儲和表示數(shù)據(jù)。矢量數(shù)據(jù)庫適合基于相似性的操作,知識圖譜旨在捕捉和分析復(fù)雜的關(guān)系和依賴關(guān)系。
對于LLM中的幻覺問題,知識圖譜是一個比向量數(shù)據(jù)庫更好的解決方案。知識圖譜為LLM提供了更準確、相關(guān)、多樣化、有趣、邏輯和一致的信息。因此,使用知識圖譜可以減少LLM中的幻覺,使其在生成準確和真實的文本時更加可靠。但關(guān)鍵是文檔需要清楚地展示關(guān)系,否則知識圖譜將無法捕捉到它。
向量數(shù)據(jù)庫
向量數(shù)據(jù)庫是一組高維向量的集合,用于表示實體或概念,例如單詞、短語或文檔。向量數(shù)據(jù)庫可以根據(jù)實體或概念的向量表示來度量它們之間的相似性或關(guān)聯(lián)性。
舉個例子,向量數(shù)據(jù)庫可以告訴你“巴黎”和“法國”比“巴黎”和“德國”更相關(guān),基于它們的向量距離。
知識圖譜
知識圖譜是一組節(jié)點和邊,用于表示實體或概念以及它們之間的關(guān)系,例如事實、屬性或類別。知識圖譜可以根據(jù)節(jié)點和邊的屬性來查詢或推斷不同實體或概念的事實信息。
舉個例子,知識圖譜可以告訴你“巴黎”是“法國”的首都,基于它們的邊標簽。
知識圖譜組件
頂點/節(jié)點:表示知識領(lǐng)域中的實體或?qū)ο蟆C總€節(jié)點對應(yīng)一個唯一的實體,并由唯一的標識符進行標識。例如,在關(guān)于Chennai Kings的知識圖譜中,節(jié)點可以具有諸如“Philadelphia Phillies”和“Major League Cricket”這樣的值。
邊:表示兩個節(jié)點之間的關(guān)系。例如,一條“compete in”的邊可以將“Chennai Kings”節(jié)點連接到“Major League Cricket”節(jié)點。
知識圖譜中的基本數(shù)據(jù)單元
三元組是圖中的基本數(shù)據(jù)單元。它由三個部分組成:
主語:三元組所關(guān)于的節(jié)點。
賓語:關(guān)系指向的節(jié)點。
謂語:主語和賓語之間的關(guān)系。
在以下三元組示例中,“Chennai Kings”是主語,“compete in”是謂語,“Major League Cricket”是賓語。
(Chennai Kings) — [compete in]->(Major League Cricket)
知識圖譜數(shù)據(jù)庫可以通過存儲三元組來高效地存儲和查詢復(fù)雜的圖數(shù)據(jù)。
查詢圖數(shù)據(jù)庫
查詢涉及遍歷圖結(jié)構(gòu)并根據(jù)特定標準檢索節(jié)點、關(guān)系或模式。下面是一個簡單的示例,展示了如何查詢圖數(shù)據(jù)庫:假設(shè)你有一個代表社交網(wǎng)絡(luò)的圖數(shù)據(jù)庫,其中用戶是節(jié)點,而它們的關(guān)系(例如友誼)由連接節(jié)點的邊表示。你想要找到給定用戶的朋友圈(共同的連接)。
從參考用戶開始:在圖數(shù)據(jù)庫中,通過查詢特定的用戶標識符或其他相關(guān)標準來識別代表參考用戶的節(jié)點。
遍歷圖:使用圖形查詢語言(如Neo4j中使用的Cypher或Gremlin)從參考用戶節(jié)點遍歷圖。編寫一個查詢,指定要探索的模式或關(guān)系。在這種情況下,您想要找到朋友的朋友。示例Cypher查詢:MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fof這個查詢從參考用戶開始,沿著FRIEND關(guān)系找到另一個節(jié)點(朋友),然后再沿著另一個FRIEND關(guān)系找到朋友的朋友(fof)。
檢索結(jié)果:在圖數(shù)據(jù)庫上執(zhí)行查詢,根據(jù)查詢模式檢索出相應(yīng)的節(jié)點(朋友的朋友)。如果需要,還可以獲取檢索到的節(jié)點的特定屬性或附加信息。
呈現(xiàn)結(jié)果:將檢索到的朋友的朋友顯示給用戶或按照需求進一步處理數(shù)據(jù)。這些信息可以用于建議、網(wǎng)絡(luò)分析或其他相關(guān)目的。
圖數(shù)據(jù)庫提供了更高級查詢功能,包括過濾、聚合和復(fù)雜模式匹配。具體的查詢語言和語法可能有所不同,但總體過程涉及遍歷圖結(jié)構(gòu)以檢索與所需條件匹配的節(jié)點和關(guān)系。
查詢向量數(shù)據(jù)庫
通常涉及搜索相似向量或根據(jù)特定條件檢索向量。以下是查詢向量數(shù)據(jù)庫的簡單示例:假設(shè)你有一個包含客戶配置文件的向量數(shù)據(jù)庫,這些配置文件表示為高維向量,你想找到與給定參考客戶相似的客戶。
定義參考客戶向量:首先,為參考客戶定義一個向量表示。這可以通過提取相關(guān)特征或?qū)傩圆⑺鼈冝D(zhuǎn)換為向量格式來完成。
執(zhí)行相似性搜索:使用合適的算法,如k-最近鄰(k-NN)或余弦相似度,在向量數(shù)據(jù)庫中執(zhí)行相似性搜索。該算法將根據(jù)相似性分數(shù)識別參考客戶向量的最近鄰居。
檢索相似客戶:檢索與上一步中識別的最近鄰居向量對應(yīng)的客戶配置文件。這些配置文件將根據(jù)定義的相似性度量表示與參考客戶相似的客戶。
呈現(xiàn)結(jié)果:最后,將檢索到的客戶配置文件或相關(guān)信息呈現(xiàn)給用戶,例如顯示他們的名字、人口統(tǒng)計信息或購買歷史。此信息可用于推薦、定向營銷活動或個性化體驗。
知識圖譜的優(yōu)勢
相比于向量數(shù)據(jù)庫,知識圖譜提供了更精確和具體信息。向量數(shù)據(jù)庫表示兩個實體或概念之間的相似性或關(guān)聯(lián)性,而知識圖譜能夠更好地理解它們之間的關(guān)系。例如,知識圖譜可以告訴你“埃菲爾鐵塔”是“巴黎”的地標,而向量數(shù)據(jù)庫只能表示這兩個概念的相似程度。這可以幫助LLM生成更準確和相關(guān)的文本。
知識圖譜支持比向量數(shù)據(jù)庫更多樣化和復(fù)雜的查詢。向量數(shù)據(jù)庫主要基于向量距離、相似度或最近鄰來回答問題,這些僅限于直接相似度測量。相比之下,知識圖譜可以處理基于邏輯運算符(如“具有屬性Z的所有實體是什么?”或“W和V的共同類別是什么?”)的查詢。這可以幫助LLM生成更多樣化和有趣的文本。
知識圖譜比向量數(shù)據(jù)庫能夠進行更多的推理和推斷。向量數(shù)據(jù)庫只能提供直接存儲在數(shù)據(jù)庫中的信息。相比之下,知識圖譜可以從實體或概念之間的關(guān)系推導出間接信息。例如,知識圖譜可以根據(jù)“巴黎是法國的首都”和“法國位于歐洲”的事實推斷出“埃菲爾鐵塔位于歐洲”。這可以幫助LLM生成更符合邏輯和一致的文本。
LlamaIndex
LlamaIndex是一個編排框架,用于簡化將私有數(shù)據(jù)與公共數(shù)據(jù)集成以構(gòu)建使用大型語言模型(LLMs)的應(yīng)用程序。它提供了數(shù)據(jù)攝取、索引和查詢的工具,使其成為生成式AI需求的一種多功能解決方案。
嵌入模型
嵌入模型需要將文本轉(zhuǎn)換為所提供文本的信息的數(shù)字表示形式。該表示形式捕獲了所嵌入內(nèi)容的語義含義,使其適用于許多行業(yè)應(yīng)用。在這里,我們使用了“thenlper/gte-large”模型。
LLM
大型語言模型需要根據(jù)提供的問題和上下文生成響應(yīng)。在這里,我們使用了Zephyr 7B beta模型。
代碼實現(xiàn)
1、安裝所有依賴庫
pipinstallllama_indexpyvisIpythonlangchainpypdf
2、設(shè)置日志
importlogging importsys # logging.basicConfig(stream=sys.stdout,level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
3、導包
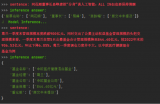
fromllama_indeximport(SimpleDirectoryReader, LLMPredictor, ServiceContext, KnowledgeGraphIndex) # fromllama_index.graph_storesimportSimpleGraphStore fromllama_index.storage.storage_contextimportStorageContext fromllama_index.llmsimportHuggingFaceInferenceAPI fromlangchain.embeddingsimportHuggingFaceInferenceAPIEmbeddings fromllama_index.embeddingsimportLangchainEmbedding frompyvis.networkimportNetwork
SimpleDirectoryReader:用于讀取非結(jié)構(gòu)化數(shù)據(jù)。
LLMPredictor:用于使用大型語言模型(LLM)生成預(yù)測。
ServiceContext:提供協(xié)調(diào)各種服務(wù)所需的上下文數(shù)據(jù)。
KnowledgeGraphIndex:用于構(gòu)建和操作知識圖譜。
SimpleGraphStore:用作存儲圖數(shù)據(jù)的簡單倉庫。
HuggingFaceInferenceAPI:用于利用開源LLM的模塊。
4、引入LLM
HF_TOKEN='YourHuggaingfaceapikey' llm=HuggingFaceInferenceAPI( model_name='HuggingFaceH4/zephyr-7b-beta',token=HF_TOKEN )
5、引入embedding
embed_model=LangchainEmbedding( HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name='thenlper/gte-large') )
6、裝載數(shù)據(jù)
documents=SimpleDirectoryReader('/content/Documents').load_data()
print(len(documents))
審核編輯:黃飛
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3900瀏覽量
65774 -
大模型
+關(guān)注
關(guān)注
2文章
3026瀏覽量
3825
原文標題:借助知識圖譜和Llama-Index實現(xiàn)基于大模型的RAG-上
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
KGB知識圖譜基于傳統(tǒng)知識工程的突破分析
KGB知識圖譜技術(shù)能夠解決哪些行業(yè)痛點?
知識圖譜的三種特性評析
KGB知識圖譜通過智能搜索提升金融行業(yè)分析能力
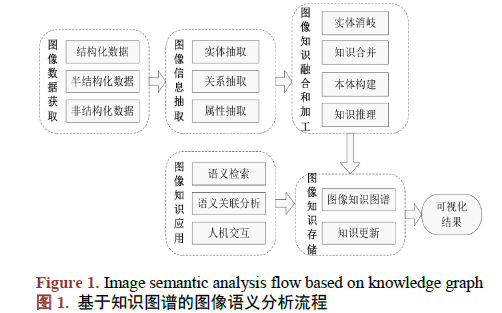
如何使用知識圖譜對圖像語義進行分析技術(shù)及應(yīng)用研究
知識圖譜在工程應(yīng)用中的關(guān)鍵技術(shù)、應(yīng)用及案例

通用知識圖譜構(gòu)建技術(shù)的應(yīng)用及發(fā)展趨勢

知識圖譜Knowledge Graph構(gòu)建與應(yīng)用
知識圖譜:知識圖譜的典型應(yīng)用
基于本體的金融知識圖譜自動化構(gòu)建技術(shù)
如何利用大模型構(gòu)建知識圖譜?如何利用大模型操作結(jié)構(gòu)化數(shù)據(jù)?
知識圖譜與大模型結(jié)合方法概述
利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(下)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論