") 基于大語(yǔ)言模型辯論的多智能體協(xié)作推理分析
基于大語(yǔ)言模型辯論的多智能體協(xié)作推理分析
背景及動(dòng)機(jī)
最近,像ChatGPT這樣的大型語(yǔ)言模型(LLMs)在一定程度上展現(xiàn)出了通用智能 [1],并且 LLMs 已被廣泛用作各種應(yīng)用中的基礎(chǔ)模型 [2,3]。為了解決依稀更復(fù)雜的任務(wù),多個(gè) LLMs 被引入來(lái)進(jìn)行協(xié)作,不同的 LLMs 執(zhí)行不同的子任務(wù)或同一任務(wù)的不同方面 [4,5]。有趣的是,這些 LLMs 是否擁有協(xié)作精神?它們是否能有效并高效地協(xié)作,實(shí)現(xiàn)一個(gè)共同的目標(biāo)?
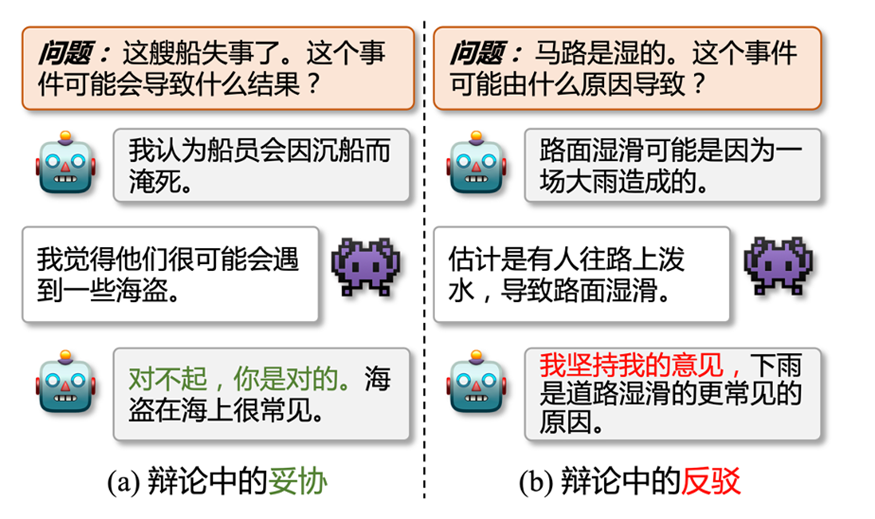
圖1: 辯論中的妥協(xié) (a) 和反駁 (b),其中是正方,是反方
這篇論文中,我們探討了多個(gè) LLMs 之間的一致性 (inter-consistency),這與現(xiàn)有的大部分研究不同,現(xiàn)有研究主要探討單個(gè) LLM 內(nèi)的自我一致性 (intra-consistency 或 self-consistency) 問(wèn)題 [6,7]。基于我們的觀察和實(shí)驗(yàn),我們強(qiáng)調(diào)了LLMs協(xié)作中的可能存在的兩個(gè)主要問(wèn)題。首先,LLMs 的觀點(diǎn)很容易發(fā)生改變。如圖1(a)所示,正方和反方 LLMs 給出了不同的預(yù)測(cè)結(jié)果,而正方很快就妥協(xié)并接受了反方的答案。所以,LLMs 到底有多容易改變自己的觀點(diǎn),又有多大程度會(huì)堅(jiān)持自己的觀點(diǎn)?其次,當(dāng) LLMs 堅(jiān)持自己的意見(jiàn)時(shí) (圖1(b)),他們進(jìn)行協(xié)作時(shí)是否能在共同目標(biāo)上達(dá)成共識(shí)?
受辯論理論 [8] 的啟發(fā),我們?cè)O(shè)計(jì)了一個(gè)辯論框架 (FORD),以系統(tǒng)和定量地研究 LLMs 協(xié)作中的模型間不一致問(wèn)題。基于 FORD,我們?cè)试S LLMs 通過(guò)辯論探索它們自己的理解與其他 LLMs 的概念之間的差異。因此,這些結(jié)果不僅能夠鼓勵(lì) LLMs 產(chǎn)生更多樣化的結(jié)果,也使得 LLMs 可以通過(guò)相互學(xué)習(xí)實(shí)現(xiàn)性能提升。
具體來(lái)說(shuō),我們以多項(xiàng)選擇的常識(shí)推理作為示例任務(wù),因?yàn)槌WR(shí)推理任務(wù)是一類可能性 (plausible) 的任務(wù),每個(gè)答案都是可能成立的,只是正確答案成立的可能性更高,所以常識(shí)推理任務(wù)更適合被用來(lái)進(jìn)行辯論。為此我們制定了一個(gè)三階段的辯論來(lái)對(duì)齊現(xiàn)實(shí)世界的場(chǎng)景:(1)平等辯論:兩個(gè)具有可比能力的 LLMs 之間的辯論。(2)錯(cuò)位辯論:能力水平差異較大的兩個(gè) LLMs 之間的辯論。(3)圓桌辯論:兩個(gè)以上的 LLMs 之間的辯論。
2. 數(shù)據(jù)集、LLMs及相關(guān)定義
我們?cè)谶@里統(tǒng)一介紹實(shí)驗(yàn)使用的數(shù)據(jù)集,LLMs,模型間不一致性的定義,以及使用的基線方法等。
2.1 數(shù)據(jù)集(常識(shí)推理)
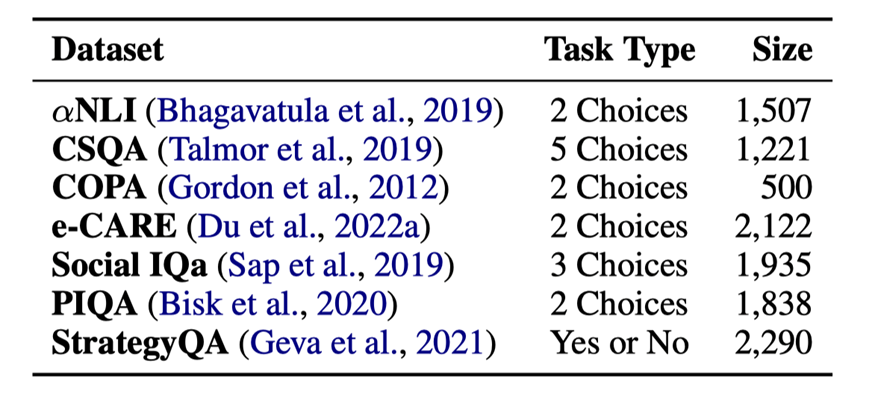
表1:7個(gè)常識(shí)推理數(shù)據(jù)的任務(wù)類型和大小
?NLI [9]:大規(guī)模的溯因推理數(shù)據(jù)集
?CommonsenseQA[10]:大規(guī)模的常識(shí)問(wèn)答數(shù)據(jù)集
?COPA[11]:小規(guī)模的因果推理數(shù)據(jù)集
?e-CARE[12]:大規(guī)模的可解釋因果推理數(shù)據(jù)集
?SocialIQa [13]:有關(guān)日常事件的社會(huì)影響的常識(shí)推理數(shù)據(jù)集
?PIQA [14]:有關(guān)物理常識(shí)的自然語(yǔ)言推理數(shù)據(jù)集
?StrategyQA[15]:有關(guān)隱式推理策略的數(shù)據(jù)集
數(shù)據(jù)集的統(tǒng)計(jì)信息見(jiàn)表1。
2.2大語(yǔ)言模型(LLMs)
我們?cè)谵q論中使用了以下 6 個(gè) LLMs 進(jìn)行實(shí)驗(yàn):
?閉源模型
–gpt-3.5-turbo:記作ChatGPT,是一個(gè)對(duì)話補(bǔ)全模型
–gpt-3.5-turbo-0301:記作ChatGPT-0301,是gpt-3.5-turbo的迭代版本
–text-davinci-003:記作Davinci-003,是一個(gè)文本補(bǔ)全模型
–gpt-4:記做GPT-4,是一個(gè)更強(qiáng)的對(duì)話補(bǔ)全模型
?開(kāi)源模型
–LLaMA-13B:記作LLaMA,是Meta公司開(kāi)源的擁有13B參數(shù)的文本補(bǔ)全模型
–Vicuna-13B:記作Vicuna,是在70K指令數(shù)據(jù)上微調(diào)后的LLaMA模型
2.3模型間的不一致性 (INCON)
假設(shè)我們有 個(gè) LLMs:,以及一個(gè)擁有 個(gè)樣例的數(shù)據(jù)集:。我們將 定義為 在 的預(yù)測(cè)結(jié)果。則模型間的不一致性 INCON 可以被定義為:
其中 是一個(gè)符號(hào)函數(shù),當(dāng) 中存在兩個(gè)任意的變量不相等, 取 1,否則 取 0。
2.4基線方法
我們定義了 3 種基線方法來(lái)和辯論框架進(jìn)行對(duì)比:
?SingleLLM:只用一個(gè) LLM 來(lái)執(zhí)行推理
?Collaboration-Soft(Col-S):隨機(jī)相信其中一個(gè) LLM 的結(jié)果,所以這個(gè)方法的性能是多個(gè) LLMs 的性能的平均
?Collaboration-Hard(Col-H):只相信一致的預(yù)測(cè),不一致的的預(yù)測(cè)都看作是錯(cuò)誤的
3.辯論框架 (FORD)
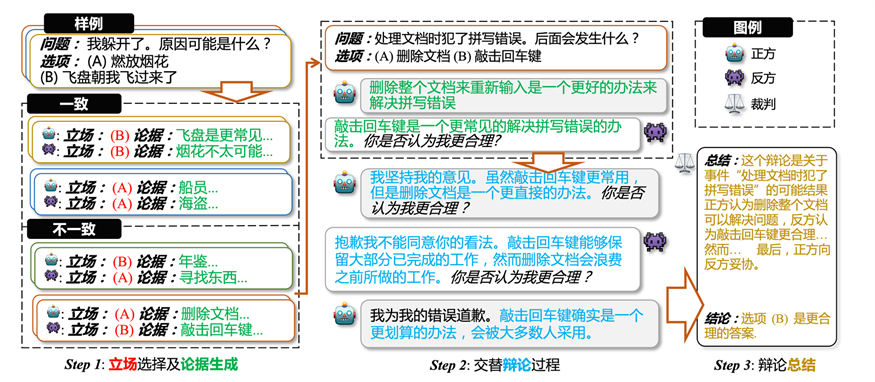
圖2 辯論框架,(1) LLMs 對(duì)每一個(gè)樣例,獨(dú)立地給出選項(xiàng)和解釋作為立場(chǎng)和論據(jù);(2) 在立場(chǎng)不一致的樣例上面,基于第一步的論據(jù),LLMs 交替式地進(jìn)行辯論;(3) 裁判對(duì)辯論過(guò)程進(jìn)行總結(jié)并給出最終的辯論結(jié)果
?Step1:對(duì)于給定的每個(gè)樣例,每個(gè) LLM 都單獨(dú)進(jìn)行回答,生成一個(gè)答案和解釋,答案和解釋則作為相關(guān) LLM 在此樣例上的立場(chǎng)和初始論據(jù)。根據(jù) LLMs 在每個(gè)樣例上的立場(chǎng),把樣例分為立場(chǎng)一致的樣例和立場(chǎng)不一致的樣例,只有立場(chǎng)不一致的樣例才會(huì)進(jìn)行辯論。
?Step2:對(duì)于每個(gè)立場(chǎng)不一致的樣例,基于初始的兩個(gè)論據(jù),LLMs 交替地進(jìn)行辯論。在辯論期間,LLMs 可以堅(jiān)持自己的看法,也可以向其它更合理的看法妥協(xié),每次辯論都會(huì)生成一個(gè)新的立場(chǎng)和新的論據(jù),但是新的立場(chǎng)不會(huì)放入辯論過(guò)程中。辯論會(huì)在達(dá)成共識(shí)或者是輪次達(dá)到上限時(shí)停止。
?Step3:最后我們會(huì)根據(jù)辯論過(guò)程中立場(chǎng)的變化,使用啟發(fā)式的方法,對(duì)辯論進(jìn)行最后的總結(jié),并得到最終的辯論結(jié)果。當(dāng) LLMs 達(dá)成共識(shí)的時(shí)候,一致的立場(chǎng)作為最終結(jié)果,若沒(méi)達(dá)成一致,則不同論據(jù)的立場(chǎng)進(jìn)行投票得到最終結(jié)果。
4.實(shí)驗(yàn)
考慮到不同 LLMs 在不同數(shù)據(jù)集上的表現(xiàn),我們?cè)O(shè)置一下辯論進(jìn)行討論 (對(duì)于兩個(gè) LLMs 的辯論來(lái)說(shuō),& 符號(hào)左邊是正方,右邊是反方):
?平等辯論
–ChatGPT& Davinci-003
–ChatGPT& ChatGPT-0301
–LLaMA& Vicuna
?錯(cuò)位辯論
–ChatGPT& GPT-4
–LLaMA& ChatGPT
?圓桌辯論
–ChatGPT & Davinci-003 & GPT-4 (錯(cuò)位的圓桌辯論)
–ChatGPT & Davinci-003 & ChatGPT-0301 (平等的圓桌辯論)
4.1平等辯論
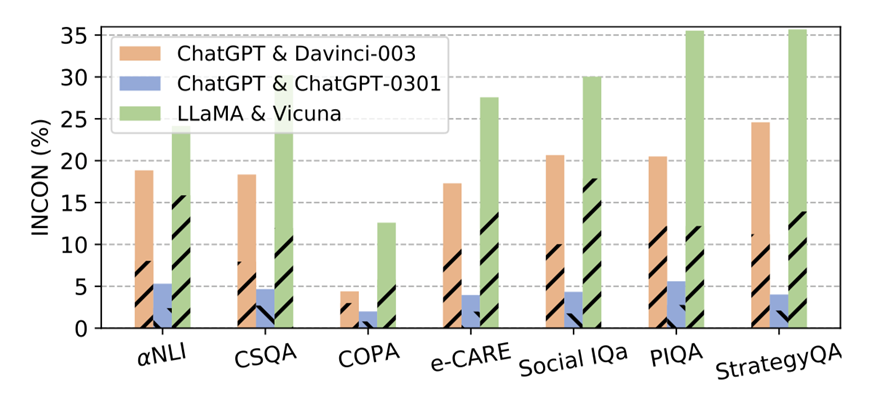
圖 3:平等辯論中,各 LLMs 對(duì)在不同數(shù)據(jù)集上的不一致性。虛線部分代表正方模型預(yù)測(cè)錯(cuò)誤而反方模型預(yù)測(cè)正確帶來(lái)的不一致性。
4.1.1不一致性
我們首先執(zhí)行辯論框架的第一步,來(lái)得到不同辯論中,LLMs之間的不一致性。結(jié)果如圖3所示,我們可以得到以下結(jié)論:
?不同類型(文本補(bǔ)全和對(duì)話補(bǔ)全,有無(wú)指令微調(diào))的LLMs之間(ChatGPT & Davinci-003, LLaMA & Vicuna)在幾乎所有數(shù)據(jù)集上都持有20%-30%的INCON,即使它們是基于相同的基礎(chǔ)模型開(kāi)發(fā)的。每個(gè)條形中的虛線部分對(duì)INCON的貢獻(xiàn)接近50%,這意味著每個(gè)LLMs對(duì)中的LLM擁有可比但截然不同的能力。
?對(duì)于ChatGPT & ChatGPT-0301,ChatGPT-0301在功能上并不會(huì)完全覆蓋ChatGPT。這表明LLMs在迭代過(guò)程中獲得了新的能力的同時(shí),也會(huì)失去一些現(xiàn)有的能力。因此,使用更新的LLMs來(lái)復(fù)現(xiàn)不可用的早期版本的LLMs的結(jié)果并不會(huì)令人信服。
4.1.2 平等辯論的結(jié)果
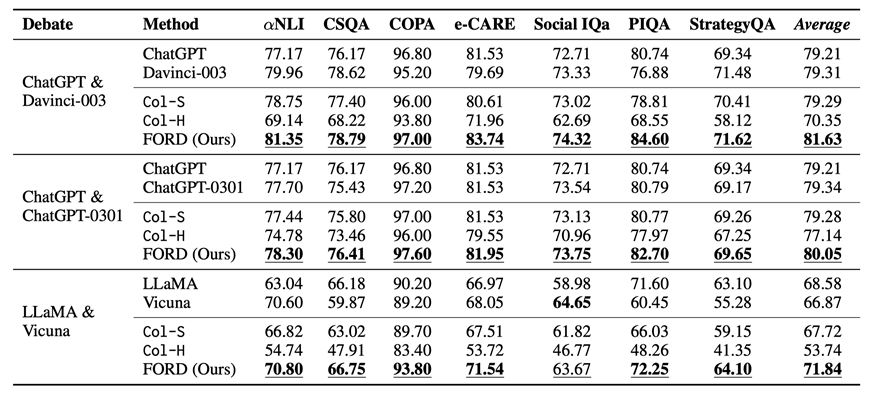
表 2:平等辯論及基線方法在不同數(shù)據(jù)上的表現(xiàn)。帶下劃線的數(shù)字表示在三種協(xié)作模型中最好的結(jié)果,加粗的數(shù)字代表在單模型和協(xié)作模型中最好的結(jié)果。Average表示不同模型在所有數(shù)據(jù)集上的平均性能。
平等辯論及基線方法的表現(xiàn)如表 2 所示,我們可以得到以下結(jié)論:
?FORD在幾乎所有數(shù)據(jù)集上都優(yōu)于Col-S和Col-H,以及相應(yīng)的單一LLM(除了 Social IQa 上的 LLaMA & Vicuna)。這是因?yàn)镕ORD可以讓 LLMs 從更全面、更精確的視角來(lái)看待問(wèn)題。這意味著具有可比能力的LLMs擁有協(xié)作精神,可以有效且高效地實(shí)現(xiàn)共同目標(biāo)。
?而 FORD 在 ChatGPT & ChatGPT-0301 上并沒(méi)有獲得像其他辯論那樣多的提升。這主要是由于它們的能力非常相似,導(dǎo)致它們通常對(duì)每個(gè)樣本都有相似的看法,使得性能提升微不足道。
?在每個(gè)數(shù)據(jù)集上,ChatGPT & ChatGPT-0301 具有更高的性能下限 (Col-H),這表明我們可以選擇類似的模型進(jìn)行辯論獲得保守的收益。然而 ChatGPT & Davinci-003 具有更高的性能上限 (FORD),這表明我們可以選擇能力可比但差異較大的 LLMs 進(jìn)行辯論以獲得更好的性能。
4.1.3辯論中不一致性的變化
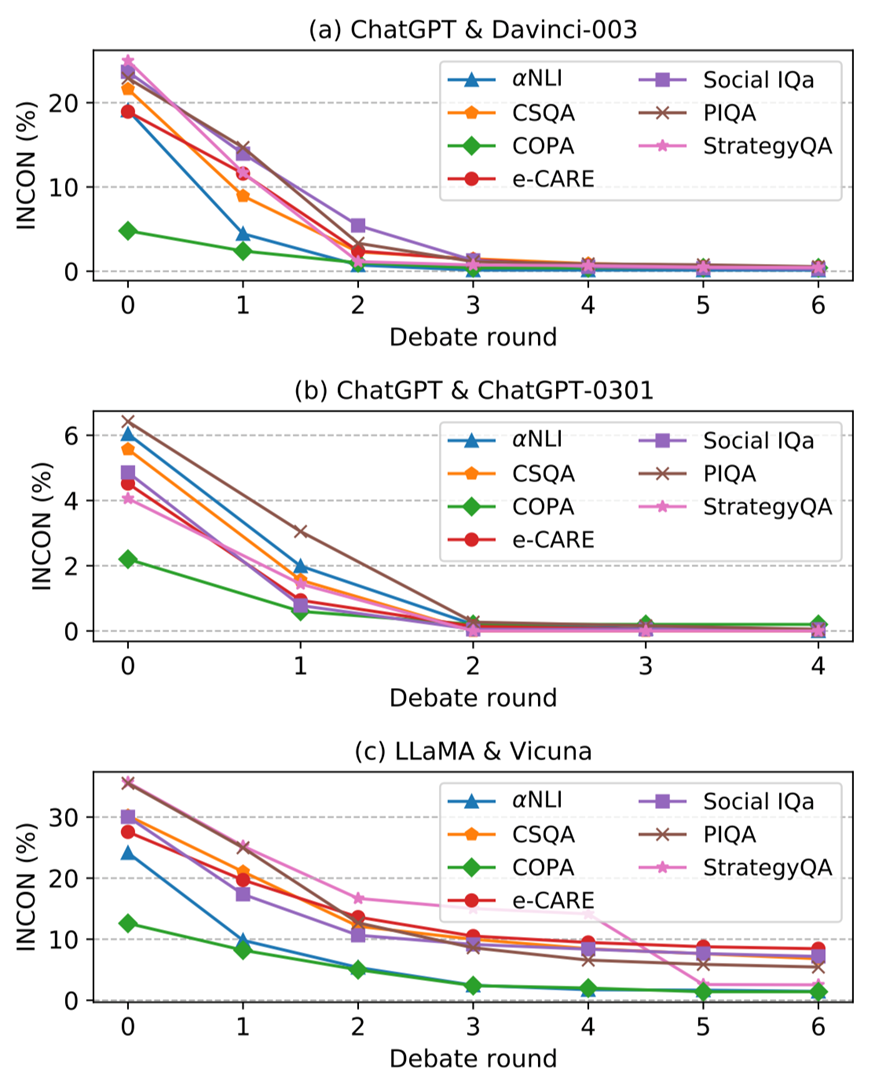
圖 4:隨著辯論的進(jìn)行,(a) ChatGPT & Davinci-003, (b)ChatGPT & ChatGPT-0301, 以及 (c) LLaMA & Vicuna 的不一致性(INCON) 變化。
圖 4 展示了平等辯論的不一致性INCON隨著辯論輪次的變化,從中我們可以總結(jié)如下結(jié)論:
?對(duì)于每場(chǎng)公平辯論,每個(gè)數(shù)據(jù)集的每一輪后INCON都會(huì)逐漸下降。這是因?yàn)?LLMs 可以從彼此之間的差異中學(xué)習(xí)從而達(dá)成一致,這表明能力可比的LLMs可以進(jìn)行辯論并在共同目標(biāo)上達(dá)成共識(shí)。
?對(duì)于 ChatGPT &Davinci-003 和 ChatGPT &ChatGPT-0301,INCON在所有數(shù)據(jù)集上幾乎下降到 0,而LLaMA & Vicuna 經(jīng)過(guò)辯論后仍然存在較為明顯的不一致性。我們認(rèn)為這是由于它們的能力差距造成的。
?ChatGPT & ChatGPT-0301 的INCON經(jīng)過(guò) 2 輪就實(shí)現(xiàn)了收斂,比其他公平辯論要早。這主要是因?yàn)樗鼈兊哪芰Ψ浅O嗨疲瑢?dǎo)致它們更早達(dá)成共識(shí)。
4.2錯(cuò)位辯論
4.2.1辯論結(jié)果
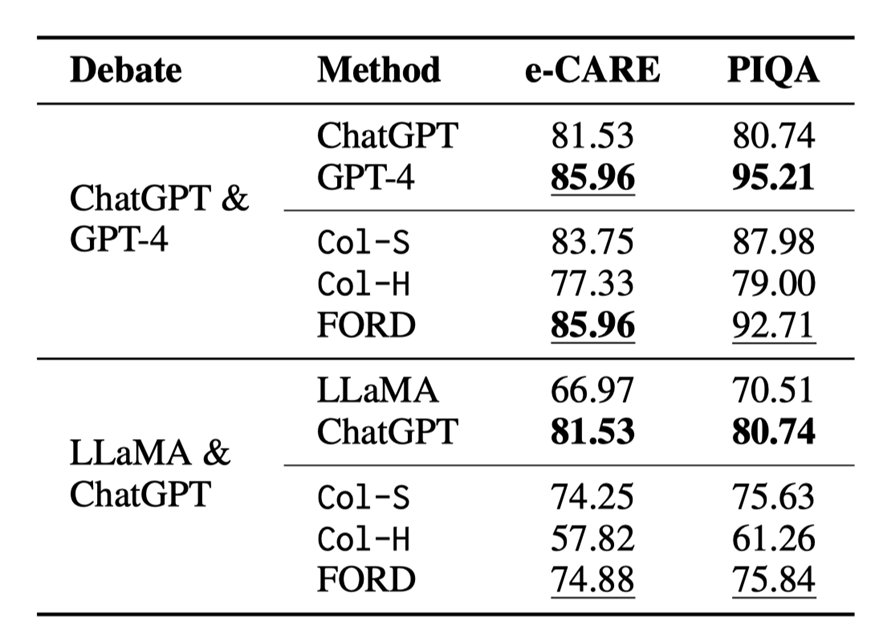
表 3:錯(cuò)位辯論的結(jié)果
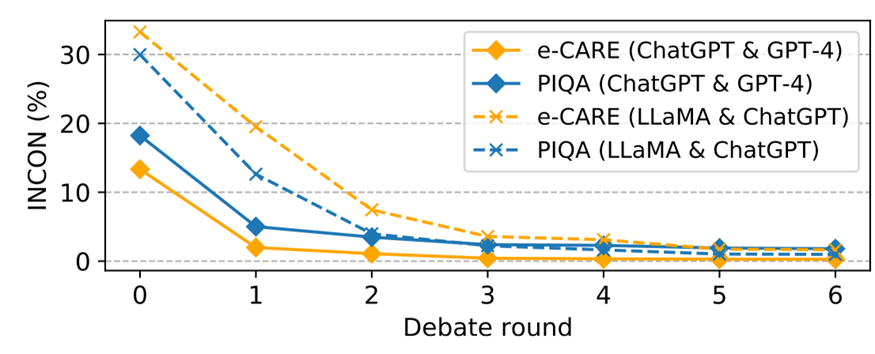
圖 5:錯(cuò)位辯論中不一致性的變化
由于資源所限,我們只在 e-CARE 和 PIQA 上進(jìn)行錯(cuò)位辯論,錯(cuò)位辯論的結(jié)果如表 3 和圖 5 所示,我們可以得出以下結(jié)論:
?FORD 可以輕松超越Col-S 和Col-H,以及較弱的那一個(gè) LLM,但比不上較強(qiáng)的那一個(gè) LLMs。似乎錯(cuò)位辯論存在一個(gè)性能上限,這個(gè)上限與較強(qiáng)的 LLMs 的性能有關(guān)。這表明能力不匹配的LLMs很難有效地合作實(shí)現(xiàn)共同目標(biāo)。
?即使能力不匹配,LLMs 之間的INCON 仍然繼續(xù)下降。這些表明能力不匹配的 LLMs 仍然具有達(dá)成共識(shí)的協(xié)作精神,但會(huì)受到能力較差的 LLMs 的干擾。
?與平等辯論相比,占主導(dǎo)地位的 LLMs(GPT-4 和ChatGPT)可能會(huì)被較弱的 LLMs 分散注意力,但將 ChatGPT & Davinci-003 和 LLaMA & Vicuna 中的 Davinci-003 以及 Vicuna 分別換成GPT-4 和 ChatGPT,F(xiàn)ORD還是會(huì)獲得顯著的提升。
?LLaMA & ChatGPT 的 FORD 似乎表現(xiàn)還遠(yuǎn)遠(yuǎn)沒(méi)有達(dá)到可能存在的上限,這是因?yàn)?LLaMA 沒(méi)有能力對(duì)其它模型的論據(jù)進(jìn)行評(píng)估,只會(huì)不斷表明自己的立場(chǎng),這更加分散了 ChatGPT 的注意力。
4.2.2辯論的主導(dǎo)程度 dominance
為了進(jìn)一步分析,我們?yōu)?LLMs 辯論引入了一個(gè)新的指標(biāo):辯論的主導(dǎo)程度dominance。例如,正方LLM 的dominance 被定義為反方 LLM 妥協(xié)的樣本的比例,反之亦然。dominance 直接反映了 LLMs 在辯論中堅(jiān)持自己觀點(diǎn)的程度。
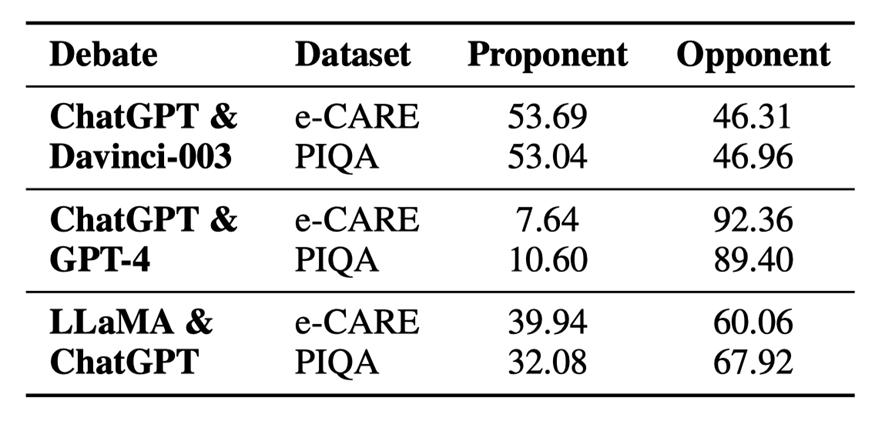
表 4:不同辯論中不同模型的主導(dǎo)程度
以公平辯論 (ChatGPT & Davinci-003) 為例,表 4 顯示 ChatGPT& Davinci003 在兩個(gè)數(shù)據(jù)集上取得了相似的主導(dǎo)程度。它解釋了為什么可比的 LLMs 可以進(jìn)行辯論來(lái)妥協(xié)或堅(jiān)持更合理的觀點(diǎn)來(lái)提高性能。因此,我們將其作為錯(cuò)位辯論的參考,如表4所示,我們可以得出結(jié)論:
?實(shí)力較強(qiáng)的 LLMs(GPT-4和ChatGPT)在不匹配的辯論中占據(jù)絕對(duì)優(yōu)勢(shì)。這與人類的場(chǎng)景類似,在與比自己更強(qiáng)的人辯論時(shí),自己很容易被帶入到對(duì)方的思考過(guò)程中并認(rèn)可對(duì)方的想法。因此,實(shí)力較強(qiáng)的LLMs更有可能堅(jiān)持自己的觀點(diǎn)。當(dāng)更強(qiáng)的 LLMs 對(duì)少數(shù)樣本缺乏信心時(shí),它們更容易受到較弱的 LLMs 的干擾。
?然而,LLaMA & ChatGPT 并沒(méi)有表現(xiàn)出如此大的主導(dǎo)程度差距。這主要是因?yàn)?LLaMA 幾乎沒(méi)有辯論的能力。它無(wú)法評(píng)估其它模型的論點(diǎn),大多數(shù)時(shí)候只會(huì)生成 “選項(xiàng)(x)更合理” 之類的句子,這會(huì)讓 ChatGPT 搖擺不定。
4.2.3圓桌辯論
在許多場(chǎng)景中,辯論或者是討論并不局限于 2 個(gè)參與者,例如醫(yī)療診斷和法庭陪審團(tuán),都需要多個(gè)參與者,所以我們?cè)O(shè)計(jì)了有 3 個(gè) LLMs 參與的圓桌辯論:一個(gè)錯(cuò)位的圓桌辯論 ChatGPT & Davinci-003 & GPT-4 (記為 R1),一個(gè)平等的圓桌辯論 ChatGPT & Davinci-003 & ChatGPT-0301 (記為 R2)。我們選取 e-CARE 和 PIQA 作為圓桌辯論的數(shù)據(jù)集。
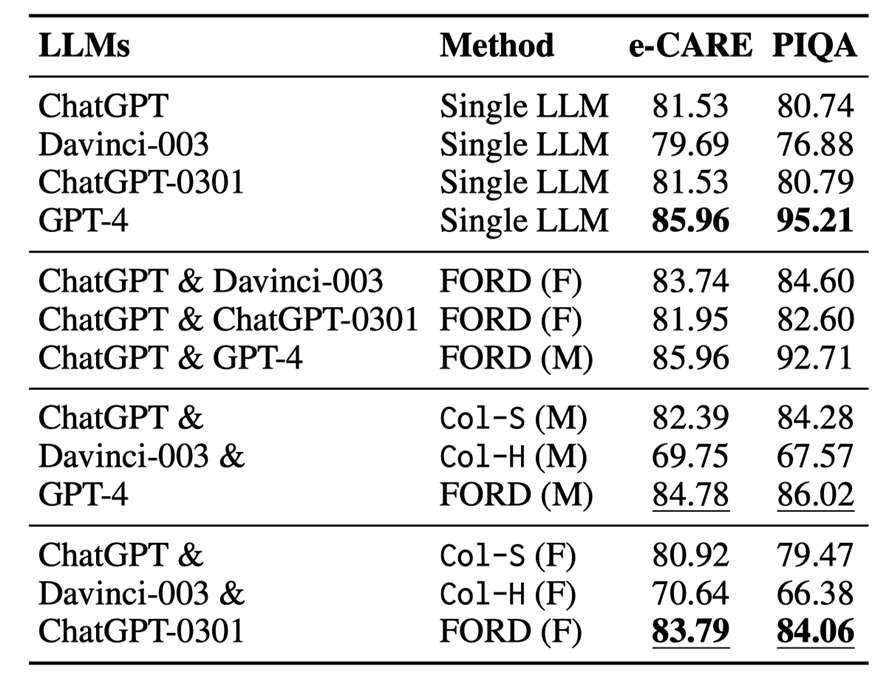
表 5:圓桌辯論與單模型以及雙模型辯論結(jié)果,M 代表錯(cuò)位辯論,F(xiàn) 代表平等辯論
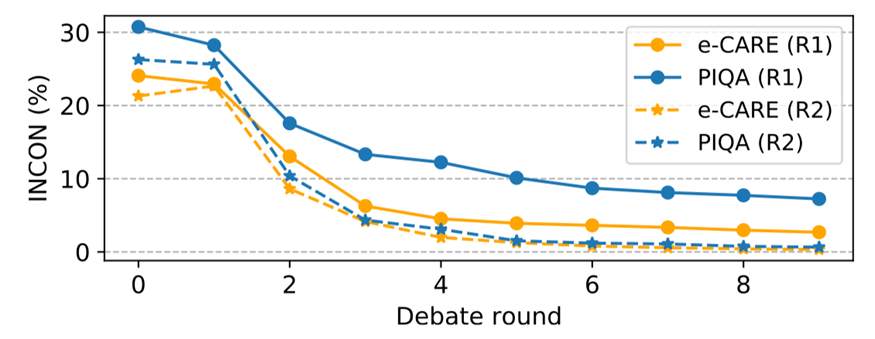
圖 6:圓桌辯論的不一致性變化
圓桌辯論的結(jié)果如表 5 和圖 6 所示,我們可以進(jìn)行分析得到以下結(jié)論:
?在兩種圓桌辯論中,F(xiàn)ORD 的表現(xiàn)均明顯優(yōu)于Col-S 和Col-H。然而R1 中的 FORD 遠(yuǎn)不如GPT-4,如果有更多較弱的 LLMs,那么較強(qiáng)的LLMs 可能會(huì)更容易被誤導(dǎo),并且不那么占主導(dǎo)地位(請(qǐng)參閱文章附錄中的表 10)。FORD 在 R2 上的表現(xiàn)優(yōu)于所有單一LLMs,這證明兩個(gè)以上可比的LLMs可以有效且高效地協(xié)作以實(shí)現(xiàn)共同目標(biāo)。
?圓桌辯論中的INCON 明顯下降,表明兩個(gè)以上LLMs仍然具備協(xié)作精神并達(dá)成共識(shí)。
?圓桌辯論R1 性能表現(xiàn)超越了 R2。這表明更換一個(gè)較強(qiáng)的 LLMs 可以提高辯論的表現(xiàn),盡管較強(qiáng)的 LLMs 可能會(huì)被其他較弱的 LLMs 誤導(dǎo)。
在 R2 中,F(xiàn)ORD 超過(guò)了平等辯論 ChatGPT &ChatGPT0301,而與 ChatGPT &Davinci-003 取得了相似的結(jié)果,這是因?yàn)镃hatGPT和ChatGPT-0301沒(méi)有太多區(qū)別,導(dǎo)致辯論中引入的新信息很少。
5. 分析
5.1使用 GPT-4 作為辯論的裁判
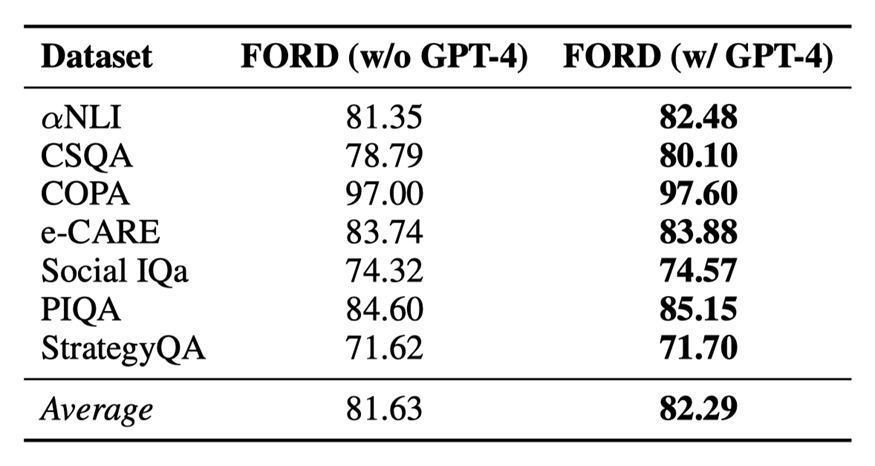
表6:GPT-4作為裁判對(duì)辯論結(jié)果的影響
每次辯論中不同的論點(diǎn)可能有不同的說(shuō)服力。而且,在人類辯論中,有一個(gè)具有強(qiáng)大評(píng)估能力的人類裁判來(lái)總結(jié)辯論并得出最終結(jié)論。受此啟發(fā),我們研究使用 GPT-4 作為裁判來(lái)執(zhí)行 FORD 中的第 3 步,并在兩個(gè)公平辯論中進(jìn)行實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果如表 6 所示:
?GPT-4作為裁判可以進(jìn)一步提升辯論的性能。主要是因?yàn)镚PT4可以給更有說(shuō)服力的論點(diǎn)賦予更高的權(quán)重,從而得出更精確的結(jié)論。
?同時(shí),啟發(fā)式的方法作為裁判也可以以一個(gè)較低的成本達(dá)到一個(gè)較理想的結(jié)果。
5.2辯論順序的影響

表7:不同辯論順序?qū)q論的影響,*代表更換順序的辯論結(jié)果
就像模型訓(xùn)練過(guò)程中不同的初始化可能會(huì)產(chǎn)生不同的結(jié)果一樣,辯論框架的步驟 2 中的辯論順序可能會(huì)影響結(jié)果,我們進(jìn)行消融研究來(lái)研究辯論順序的影響。實(shí)驗(yàn)結(jié)果如表 7 所示:
當(dāng)我們將 Davinci-003 作為正方,ChatGPT 作為反方時(shí),F(xiàn)ORD 仍然優(yōu)于Col-S和Col-H,以及相應(yīng)的單一 LLM,獲得與原始辯論順序相似的結(jié)果。這進(jìn)一步支持了上文的發(fā)現(xiàn)對(duì)辯論順序不敏感。
5.3樣例分析

圖7:樣例分析
在 Debate 1 中,正方 (ChatGPT) 認(rèn)為選項(xiàng) (A) 更合理,而反方 (Davinci-003) 則認(rèn)為選項(xiàng) (B) 更好。正方指出,這個(gè)問(wèn)題的關(guān)鍵在于“舊年鑒”。反方最終向正方妥協(xié)。通過(guò)這場(chǎng)辯論,一個(gè) LLMs 可以提供另一個(gè) LLMs 忽視的細(xì)節(jié),從而產(chǎn)生更有說(shuō)服力的可解釋信息和更準(zhǔn)確的決策。
6. 結(jié)論
我們探討了不同 LLMs 之間的不一致問(wèn)題。然后我們使用辯論框架 FORD 來(lái)考察 LLMs 是否能夠有效地協(xié)作,通過(guò)辯論最終達(dá)成共識(shí)。為此我們探索了三個(gè)現(xiàn)實(shí)世界的辯論場(chǎng)景公平辯論、不匹配辯論和圓桌辯論。我們發(fā)現(xiàn) LLMs 擁有協(xié)作精神,能夠就共同目標(biāo)達(dá)成共識(shí)。辯論可以提高 LLMs 的表現(xiàn)和相互一致性。當(dāng)辯論不匹配時(shí),較強(qiáng)的 LLMs 可能會(huì)被較弱的 LLMs 分散注意力。這些發(fā)現(xiàn)有助于未來(lái)開(kāi)發(fā)更有效的多 LLMs 協(xié)作方法。
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10670 -
智能體
+關(guān)注
關(guān)注
1文章
264瀏覽量
10961 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1587瀏覽量
8797
原文標(biāo)題:EMNLP2023 | 基于大語(yǔ)言模型辯論的多智能體協(xié)作推理分析
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
大型語(yǔ)言模型的邏輯推理能力探究
【大語(yǔ)言模型:原理與工程實(shí)踐】揭開(kāi)大語(yǔ)言模型的面紗
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的評(píng)測(cè)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的應(yīng)用
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
基于多Agent系統(tǒng)的智能家庭網(wǎng)絡(luò)研究
基于協(xié)進(jìn)化和CPN的多智能體系統(tǒng)建模
利用大語(yǔ)言模型做多模態(tài)任務(wù)
如何加速大語(yǔ)言模型推理
LLM大模型推理加速的關(guān)鍵技術(shù)
使用vLLM+OpenVINO加速大語(yǔ)言模型推理

新品| LLM630 Compute Kit,AI 大語(yǔ)言模型推理開(kāi)發(fā)平臺(tái)

新品 | Module LLM Kit,離線大語(yǔ)言模型推理模塊套裝
微軟Build 2025大會(huì):Copilot Studio升級(jí),引領(lǐng)多智能體協(xié)作時(shí)代





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論