 UniVL-DR: 多模態稠密向量檢索模型
UniVL-DR: 多模態稠密向量檢索模型

論文標題:
Universal Vision-Language Dense Retrieval: Learning A Unified Representation Space for Multi-Modal Retrieval
背景介紹盡管當前主流搜索引擎主要面向文本數據,然而多媒體內容的增長一直是互聯網上最顯著趨勢之一,各種研究表明用戶更喜歡搜索結果中出現生動的多模態內容。因而,針對于多模態數據的信息獲取需求在用戶搜索過程中尤為重要。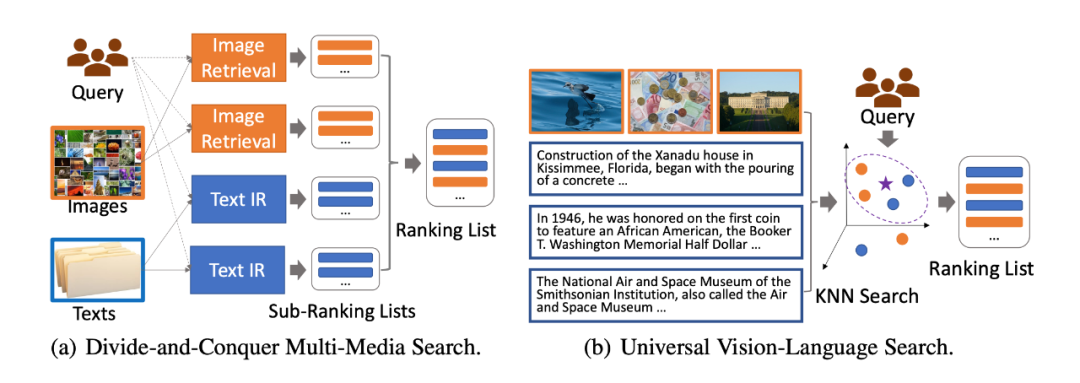 ▲圖1. 不同多模態檢索框架示意圖
▲圖1. 不同多模態檢索框架示意圖為了實現多模態檢索過程,當前的多媒體搜索系統通常采用“分而治之”的方法。如圖 1(a) 所示,這些方法首先在單個模態中進行搜索,包括文本、圖像、視頻等 ,然后將各個模態的檢索結果融合在一起,例如,在這些單/交叉模態檢索器之上構建另一個排序模塊來進行模態融合。
顯而易見,相關性建模(Relevance Modeling)和檢索結果融合(Retrieval Result Fusion)二者的建模過程通常交織在一起,以實現更準確的多模態檢索結果。然而,由于模態差距,這類模型只能以分而治之的方式進行流水線建模,這使得融合來自不同模態的檢索結果具有挑戰性。
在本文中,我們提出端到端多模態檢索模型,通過用戶查詢對多模態文檔進行統一的檢索。如圖 1(b) 所示,通用多模態檢索將查詢和多模態文檔映射到一個統一的嵌入空間,并通過最近鄰搜索檢索多模態候選結果。最終,本文將相關性建模(Relevance Modeling)、跨模態匹配(Cross-Modality Matching)和檢索結果融合(Retrieval Result Fusion)進行統一的建模。多模態檢索任務介紹
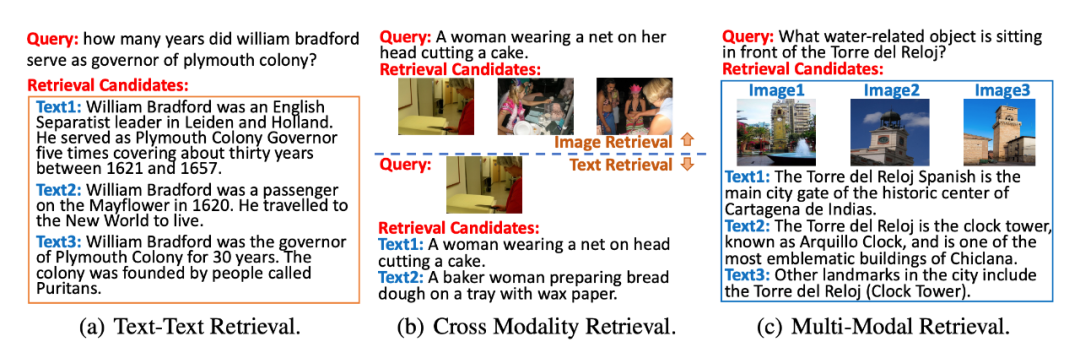
▲圖2. 不同檢索任務示意圖
單模態檢索(Single Modality Retrieval)。如圖 2(a)所示,單模態檢索側重于在一個模態空間內進行相關性檢索,包括文本-文本檢索和圖像-圖像檢索。文本-文本檢索旨在從文本集合中檢索出與查詢相關的文本文檔;而圖像-圖像檢索期望于從圖像集合中檢索出與給定查詢圖像匹配度較高的圖像。
跨模態檢索(Cross Modality Retrieval)。如圖 2(b)所示,該檢索場景包含兩個子任務:文本-圖像檢索,圖像-文本檢索。這兩種任務要求檢索模型在圖像與圖像對應的描述文字之間進行跨模態匹配,
例如,在圖像-文本檢索任務中,對于給定的圖像,檢索模型需要在給定的圖像描述文本集合中檢索出與之匹配的描述文本。這種跨模態檢索場景中的任務更加側重于文本與圖像之間的跨模態語義信息匹配,不同于信息檢索中的相似度搜索,這種跨模態匹配更加注重“淺層”的語義匹配,對于深層的文檔理解能力要求不高。
多模態檢索(Multi-Modal Retrieval)。如圖 2(c)所示,該檢索場景旨在包含多模態文檔的數據集合中檢索相關文檔。在多模態檢索場景下,檢索模型需要同時處理查詢與不同模態文檔之間的相似度計算,例如,對于給定的查詢,檢索模型需要在給定的文檔集合中檢索出相似文檔。
不同于單模態檢索和跨模態檢索,多模態檢索的目的是從多模態文檔集合中檢索、返回相關文檔。根據用戶的查詢,檢索結果可能由文本文檔、圖像文檔或文本文檔與圖像文檔的混合序列組成。多模態檢索更加關注查詢和文檔之間的關聯建模,且檢索過程中涉及查詢與文本文檔的單模態匹配、查詢與圖像文檔的跨模態匹配以及不同模態文檔與查詢的相似度之間的比較,這使得這項任務具有更大的挑戰性。UniVL-DR:基于統一表征空間的多模態稠密向量檢索框架
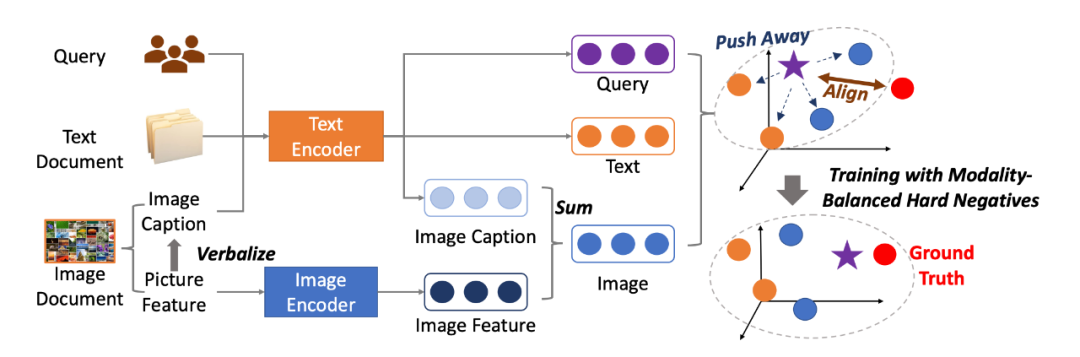
▲圖3. UniVL-DR模型結構圖
在多模態信息檢索場景下,本文提出了 Universal Vision-Language Dense Retrieval (UniVL-DR) 模型來建模多模態檢索過程。如圖 3 所示,對于給定用戶查詢和多模態文檔,UniVL-DR 將用戶查詢、文本文檔和圖像文檔編碼在一個統一的向量表征空間中,并在該表征空間中進行用戶查詢與相關文檔的相關性建模以及多模態文檔向量表征建模。
UniVL-DR 由兩個編碼器構成:文本編碼器和圖像編碼器。查詢、圖像文檔和文本文檔均通過這兩個編碼器編碼得到稠密向量表示。
查詢編碼:如公式(1)所示,本文算法直接通過文本編碼器對查詢進行編碼,得到查詢的表征向量:
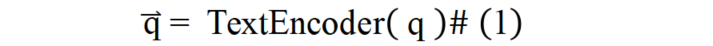
文本文檔編碼:如公式(2)所示,對于文本文檔,本文算法將其經過文本編碼器得到文本文檔的稠密表征向量:
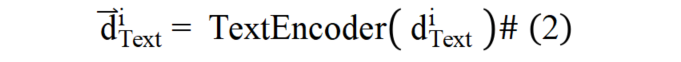
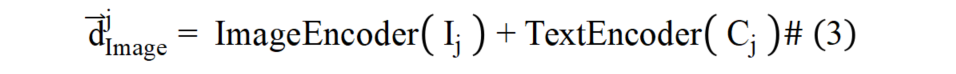
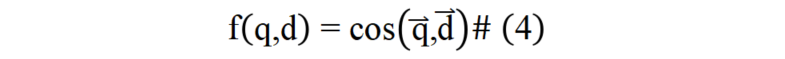
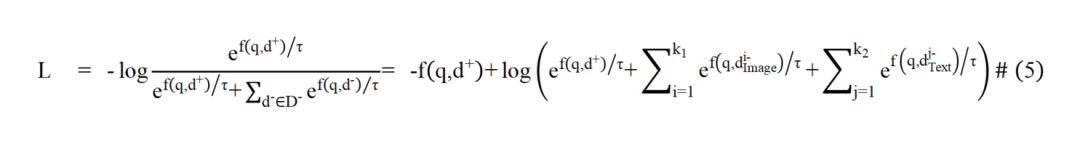
為解決圖像文檔與文本文檔在表征上的模態屏障,本文提出通過圖像的語言化拓展來彌合不同模態文檔間表征鴻溝的方法。
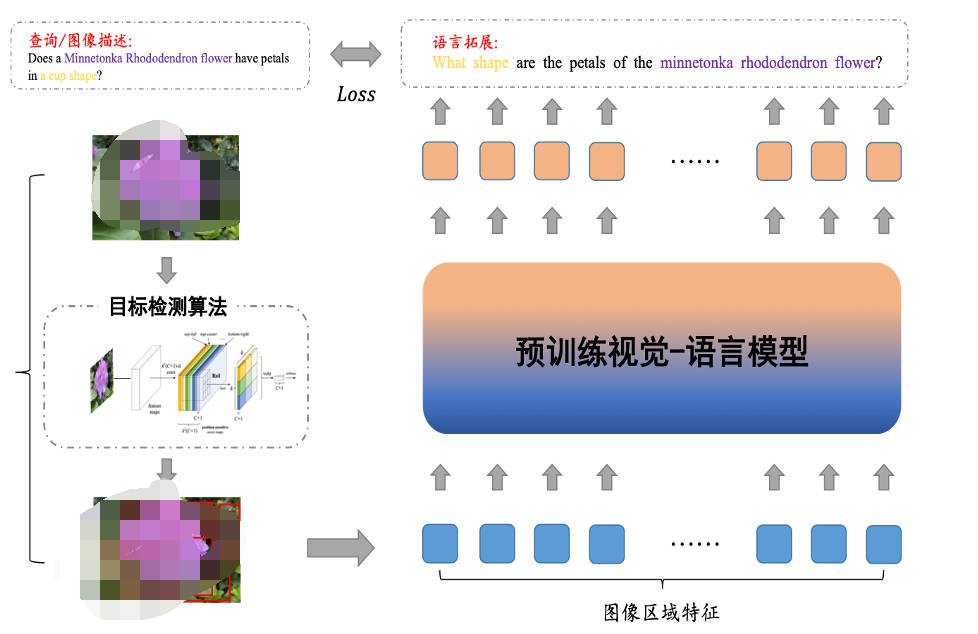
▲圖4. 圖像的語言拓展算法示意圖
本文借鑒信息檢索領域中的文檔拓展技術對圖像進行語言化拓展,增強圖像的語義表示。如圖(4)所示,首先對圖像進行目標檢測,得到圖像的區域特征和檢測出的區域文本標簽集合。本文首先將由圖像和目標檢測得到的區域標簽生成圖像描述形式的語言化拓展,輸入結構如公式(6)所示:
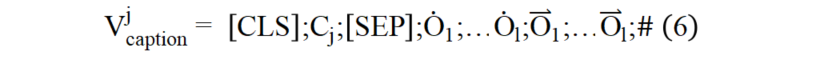
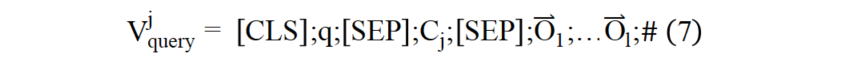
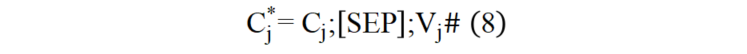
實驗結果
實驗結果如表 2 所示。UniVL-DR 在性能評估上比所有基線模型提高了 7% 以上,顯著的檢索性能提升說明了本文算法在構建面向多模態文檔的信息檢索系統方面的有效性。相比較分而治之的策略,UniVL-DR 甚至超過了 BM25&CLIP-DPR(Oracle Modality)模型,該模型利用了數據集中標注的與用戶問題相關的文檔模態信息進行模態路由。證明統一化的多模態文檔向量建模能夠很好地建模多模態檢索任務。
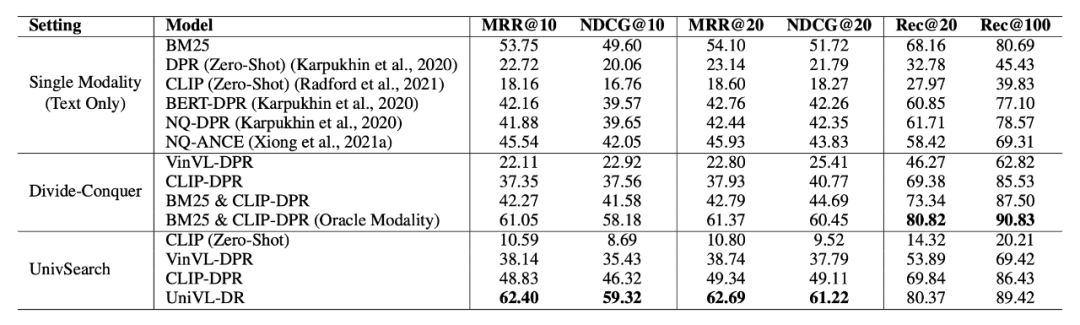
▲表2. 主實驗結果
如表 3 所示,本文展示了模型的消融試驗結果。在實驗中我們發現針對于多模態檢索任務,圖像文檔的標題信息相比較像素信息更加重要。同時,在圖像文檔標題信息的基礎上加入圖像像素信息能夠進一步提升檢索的效果。
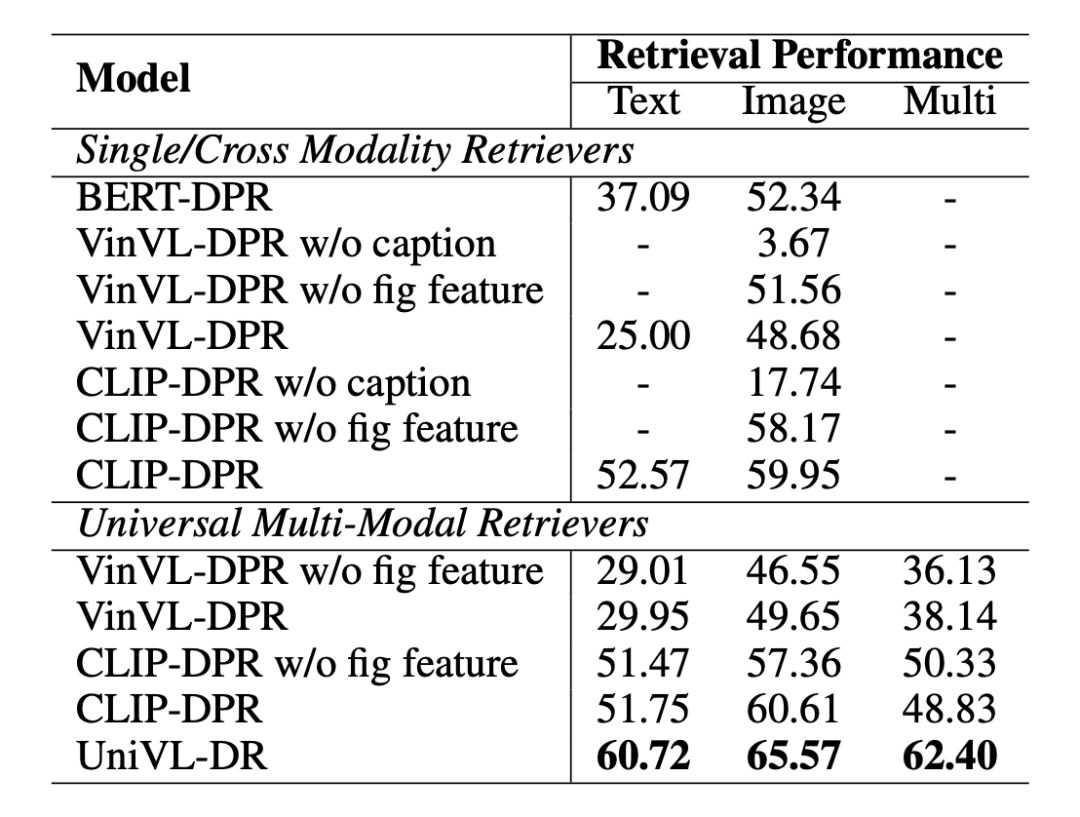
▲表3. 消融實驗結果
如圖 5 所示,在用戶問題中,往往會出現與圖片所描述內容相關的實體,例如:明尼通卡杜鵑花(Minnetonka Rhododendron flower),然而,現有的圖片編碼器(例如:CLIP)往往缺少此類的背景知識,因而導致在多模態檢索過程中圖像文本的像素編碼向量的作用不大。此原因導致了在多模態檢索過程中圖片像素的語義信息對檢索精度的提升貢獻不大的現象。
▲圖5. 圖片檢索樣例
進一步我們通過不同負例選取方式訓練得到的多模態檢索模型的向量空間可視化,如圖 6 所示。我們的實驗結果發現,通過模態平衡難負例訓練的檢索模型學習的向量空間更加的均勻。同時,通過對難負例的模態進行平衡可以很好地緩解檢索模型對于模態的偏見問題。

▲圖6. 稠密向量可視化
總結本文提出了 UniVL-DR,UniVL-DR 構建了統一的多模態向量表征空間,將單模態、跨模態匹配和檢索結果融合建模在一起,實現端到端的多模態信息檢索。具體來講,本文的主要貢獻有以下兩點:1)通過模態均衡的難負例選取策略進行統一多模態表征空間的對比優化。2)利用圖像語言化方法彌合了原始數據空間中圖像和文本之間的模態差距。實驗表明,UniVL-DR 可以通過圖像語言化技術彌合模態差距,并通過模態均衡的難負例選取策略避免過度擬合某一種模態的訓練監督信號。 ·
-
物聯網
+關注
關注
2927文章
45856瀏覽量
387856
原文標題:UniVL-DR: 多模態稠密向量檢索模型
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

海康威視發布多模態大模型AI融合巡檢超腦
移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

海康威視文搜存儲系列:跨模態檢索,安防新境界

商湯日日新多模態大模型權威評測第一
一文理解多模態大語言模型——下

一文理解多模態大語言模型——上

利用OpenVINO部署Qwen2多模態模型
云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首






 工商網監
工商網監
評論