") 中文對話式大語言模型Firefly-2b6開源,使用210萬訓(xùn)練數(shù)據(jù)
中文對話式大語言模型Firefly-2b6開源,使用210萬訓(xùn)練數(shù)據(jù)
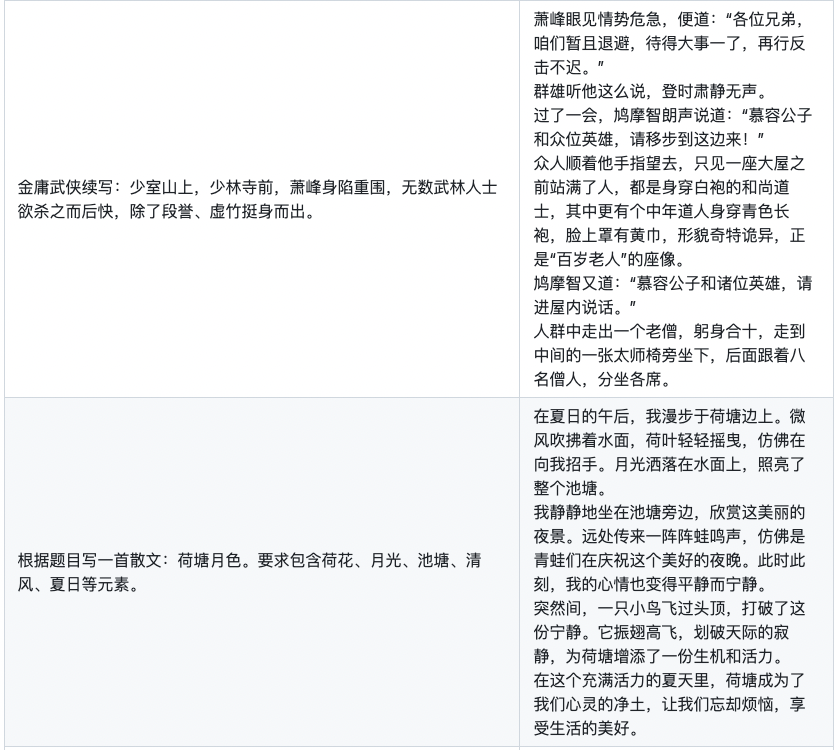
在文章Firefly(流螢): 中文對話式大語言模型中,我們介紹了關(guān)于Firefly(流螢)項目的工作,并且分享了我們訓(xùn)練的firefly-1b4模型。這是Firefly項目開源的第一個模型,雖然取得了還不錯的效果,但無論是訓(xùn)練數(shù)據(jù)還是模型參數(shù)量,都還有很大的優(yōu)化空間。
所以,在firefly-1b4實驗的基礎(chǔ)上,我們對訓(xùn)練數(shù)據(jù)進(jìn)行清洗,并且增加了數(shù)據(jù)量,得到210萬數(shù)據(jù),并用它訓(xùn)練得到了firefly-2b6模型。
在本文中,我們將對該模型進(jìn)行分享和介紹。與firefly-1b4相比,firefly-2b6的代碼生成能力取得了較大的進(jìn)步,并且在古詩詞生成、對聯(lián)、作文、開放域生成等方面也有不錯的提升。
firefly-1b4和firefly-2b6的訓(xùn)練配置如下表所示。無論是訓(xùn)練數(shù)據(jù)量,還是訓(xùn)練步數(shù),firefly-2b6都更加充分。
| 參數(shù) | firefly-1b4 | firefly-2b6 |
| batch size | 16 | 8 |
| learning rate | 3e-5 | 3e-5 |
| warmup step | 3000 | 3000 |
| lr schedule | cosine | cosine |
| max length | 512 | 512 |
| training step | 90k | 260k |
| 訓(xùn)練集規(guī)模 | 160萬 | 210萬 |
項目地址:
https://github.com/yangjianxin1/Firefly
模型權(quán)重鏈接見文末。
模型使用
使用如下代碼即可使用模型:
from transformers import BloomTokenizerFast, BloomForCausalLM
device = 'cuda'
path = 'YeungNLP/firefly-2b6'
tokenizer = BloomTokenizerFast.from_pretrained(path)
model = BloomForCausalLM.from_pretrained(path)
model.eval()
model = model.to(device)
text = input('User:')
while True:
text = '{}'.format(text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs=model.generate(input_ids,max_new_tokens=250,do_sample=True,top_p=0.7,temperature=0.35,
repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('', "")
print("Firefly:{}".format(output))
text = input('User:')
代碼生成
盡管在訓(xùn)練集中,代碼的數(shù)據(jù)量不多,但令人驚喜的是,firefly-2b6已經(jīng)具備一定的代碼生成能力。
在筆者的實測中,對于一些編程題,firefly-2b6生成的代碼可以做到無需修改,直接運行成功,并且得到正確的答案。下面將展示一些編程題的生成例子。
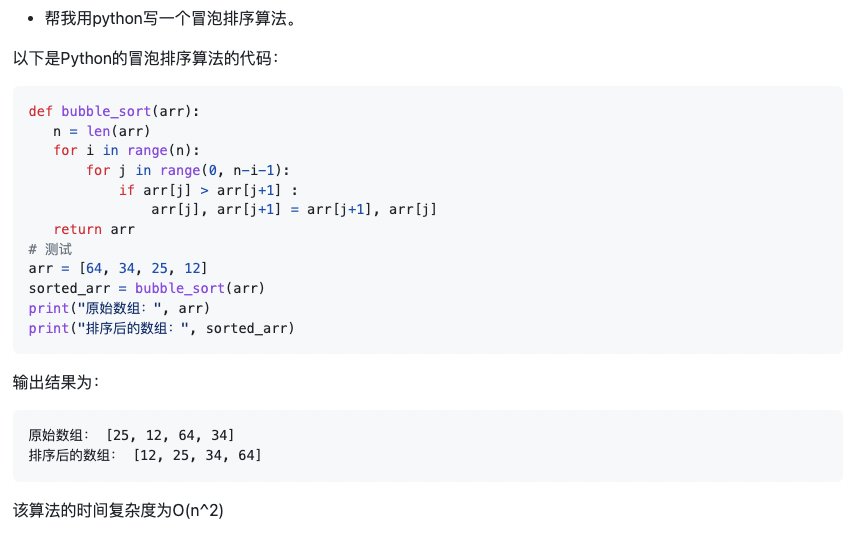
示例2:用python實現(xiàn)一個快速排序算法,輸入為一個數(shù)組,返回排序好之后的數(shù)組。

示例3:用python寫一個二分查找算法。
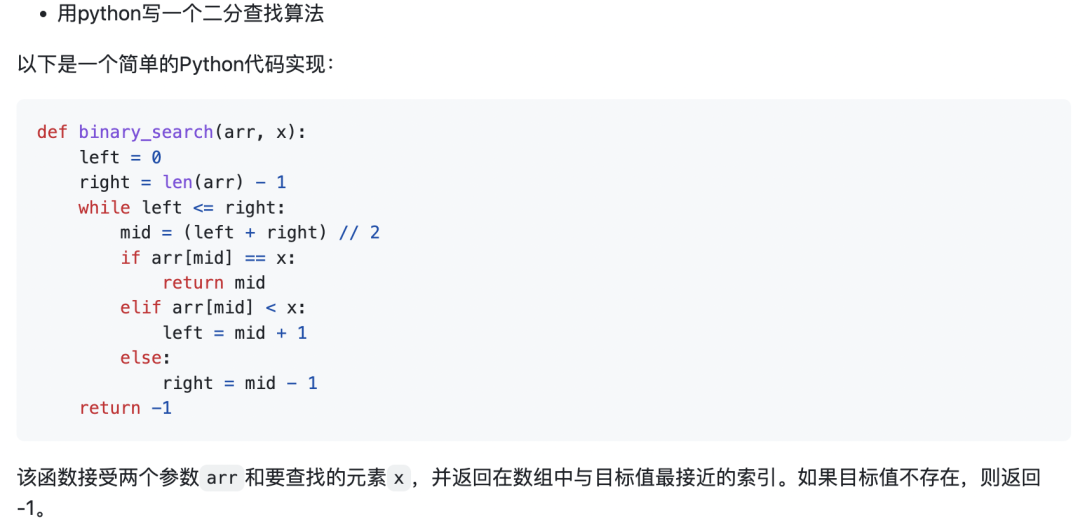
示例4:寫一個函數(shù),計算數(shù)組中偶數(shù)的個數(shù),輸入為數(shù)組,輸出為偶數(shù)的個數(shù)。
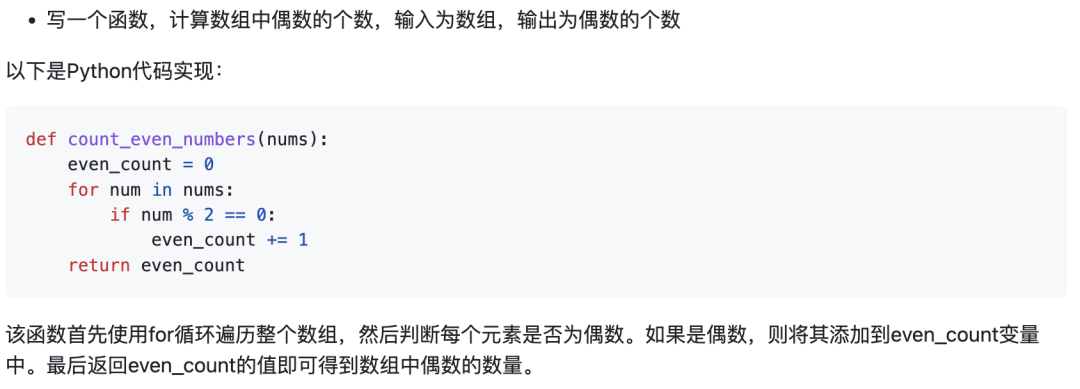
示例5:用html生成一個教務(wù)管理系統(tǒng)的登錄界面,要求包含用戶名、密碼輸入框和登錄按鈕。

該html代碼在瀏覽器中的效果如下圖:

其他樣例
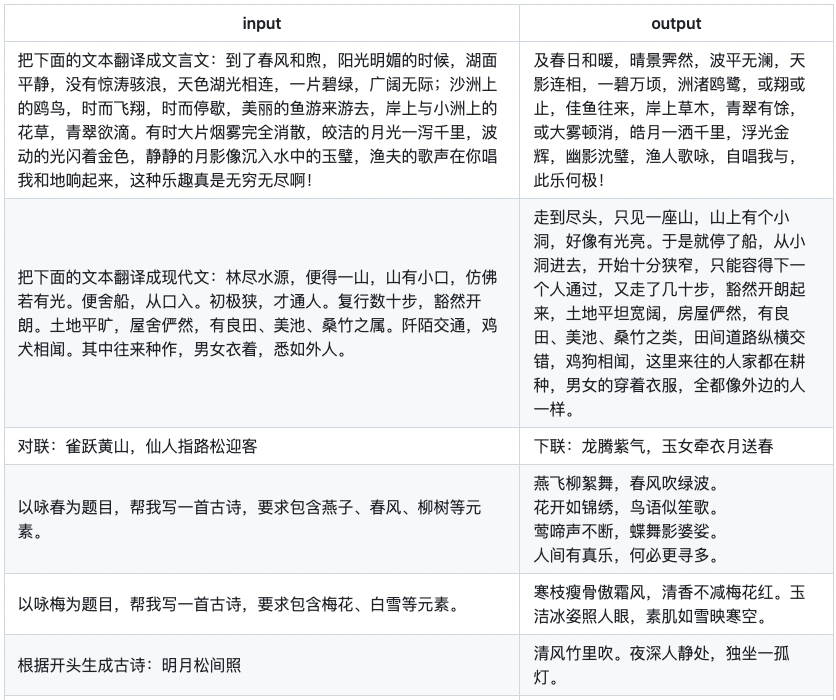
同樣,我們也對文言文、古詩詞、文章生成等數(shù)據(jù)進(jìn)行了清洗,提高數(shù)據(jù)的質(zhì)量。實測下來,我們發(fā)現(xiàn)firefly-2b6的生成效果,確實提升了不少。
數(shù)據(jù)質(zhì)量的優(yōu)化,對文言文翻譯任務(wù)的提升,尤為明顯。在訓(xùn)練firefly-1b4時,文言文數(shù)據(jù)為較短的句子對。但在訓(xùn)練firefly-2b6時,我們使用了較長篇幅的文本對。
下面為一些實測的例子。







文章小結(jié)
雖然firefly-2b6已經(jīng)初步具備代碼生成能力,但由于訓(xùn)練集中的代碼數(shù)據(jù)的數(shù)量不多,對于一些編程題,效果不如人意。我們覺得仍有非常大的優(yōu)化空間,后續(xù)我們也將收集更多代碼數(shù)據(jù),提升模型的代碼能力。
經(jīng)過firefly-1b4和firefly-2b6兩個模型的迭代,能明顯感受到增加數(shù)據(jù)量、提升數(shù)據(jù)質(zhì)量、增大模型參數(shù)量,對模型的提升非常大。
在前文中,我們提到,firefly-1b4在訓(xùn)練數(shù)據(jù)量、訓(xùn)練步數(shù)上都略有不足。為了探索"小"模型的效果上限,我們也將使用更多數(shù)量、更高質(zhì)量的數(shù)據(jù)對firefly-1b4進(jìn)行迭代。該項工作正在進(jìn)行。
后續(xù),我們也將在多輪對話、增大模型參數(shù)量、模型量化等方向上進(jìn)行迭代,我們也將陸續(xù)開源訓(xùn)練代碼以及更多的訓(xùn)練數(shù)據(jù)。期待大家的意見和建議。
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3486瀏覽量
49990 -
代碼
+關(guān)注
關(guān)注
30文章
4886瀏覽量
70255 -
語言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10670
原文標(biāo)題:中文對話式大語言模型Firefly-2b6開源,使用210萬訓(xùn)練數(shù)據(jù)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
海思SD3403邊緣計算AI數(shù)據(jù)訓(xùn)練概述
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

小白學(xué)大模型:訓(xùn)練大語言模型的深度指南

大模型訓(xùn)練:開源數(shù)據(jù)與算法的機遇與挑戰(zhàn)分析
騰訊公布大語言模型訓(xùn)練新專利
如何訓(xùn)練自己的LLM模型
AI大模型的訓(xùn)練數(shù)據(jù)來源分析
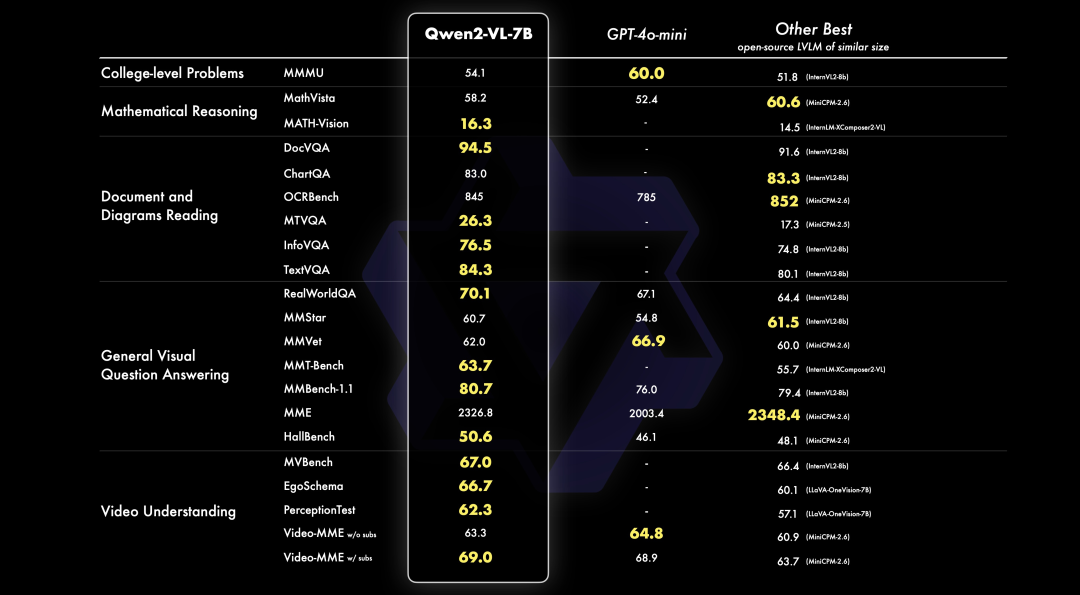
PerfXCloud重磅升級 阿里開源最強視覺語言模型Qwen2-VL-7B強勢上線!
NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)

摩爾線程與羽人科技完成大語言模型訓(xùn)練測試
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
大語言模型的預(yù)訓(xùn)練
tensorflow簡單的模型訓(xùn)練
Al大模型機器人
英偉達(dá)開源Nemotron-4 340B系列模型,助力大型語言模型訓(xùn)練
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:[email protected]
- 內(nèi)容合作
- 黃晶晶:[email protected]
- 內(nèi)容合作(海外)
- 張迎輝:[email protected]
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:[email protected]
- 投資合作
- 曾海銀:[email protected]
- 社區(qū)合作
- 劉勇:[email protected]
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論