") 小白學(xué)大模型:訓(xùn)練大語言模型的深度指南
小白學(xué)大模型:訓(xùn)練大語言模型的深度指南
在當(dāng)今人工智能飛速發(fā)展的時代,大型語言模型(LLMs)正以其強(qiáng)大的語言理解和生成能力,改變著我們的生活和工作方式。在最近的一項研究中,科學(xué)家們?yōu)榱松钊肓私馊绾胃咝У赜?xùn)練大型語言模型,進(jìn)行了超過4000次的實驗。這些實驗動用了多達(dá)512個GPU(圖形處理單元),它們協(xié)同工作,為模型訓(xùn)練提供了強(qiáng)大的計算支持。在這項研究中,研究人員特別關(guān)注了兩個關(guān)鍵指標(biāo):吞吐量(通過標(biāo)記的大小來表示)和GPU利用率(通過標(biāo)記的顏色來表示)。這兩個指標(biāo)都根據(jù)模型的大小進(jìn)行了標(biāo)準(zhǔn)化處理,以便更直觀地比較不同模型在不同硬件配置下的表現(xiàn)。
AI模型訓(xùn)練的三大挑戰(zhàn)
內(nèi)存使用:有限的“容器”
想象一下,你有一個裝滿水的杯子,但你還需要往里面加更多的水。如果杯子滿了,就再也裝不下任何東西了。這就像訓(xùn)練AI模型時的內(nèi)存問題。如果一個訓(xùn)練步驟所需的內(nèi)存超出了GPU的容量,那么訓(xùn)練就無法繼續(xù)。內(nèi)存是一個硬性限制,我們必須在有限的空間內(nèi)完成復(fù)雜的計算任務(wù)。
計算效率:讓硬件“火力全開”
我們花了大價錢購買高性能的GPU,當(dāng)然希望它們能時刻保持高效運轉(zhuǎn)。但現(xiàn)實往往是,GPU在等待數(shù)據(jù)傳輸或者等待其他GPU完成工作時,會浪費大量時間。這就像是一個生產(chǎn)線上的工人,因為原材料沒送到或者上一個環(huán)節(jié)還沒完成,只能干等著。為了提高效率,我們需要減少這些等待時間,讓硬件盡可能多地用于計算。
通信開銷:減少“內(nèi)耗”
在多GPU協(xié)同工作的場景中,不同GPU之間需要頻繁地交換信息。但這種通信會占用大量的時間和資源,甚至?xí)孏PU處于閑置狀態(tài)。這就像是一個團(tuán)隊開會,如果溝通成本過高,那么真正干活的時間就會減少。因此,我們需要巧妙地利用節(jié)點內(nèi)部(速度快)和節(jié)點之間(速度慢)的帶寬,并盡可能讓通信和計算同時進(jìn)行,從而減少通信開銷。
從單個GPU開始:AI模型訓(xùn)練的第一步在探索如何用數(shù)千個GPU訓(xùn)練大型AI模型之前,我們先從最基礎(chǔ)的部分開始——在單個GPU上訓(xùn)練模型。這就好比在學(xué)會駕駛飛機(jī)之前,先要學(xué)會駕駛一輛汽車。別小看這一步,它是我們理解整個訓(xùn)練過程的關(guān)鍵。
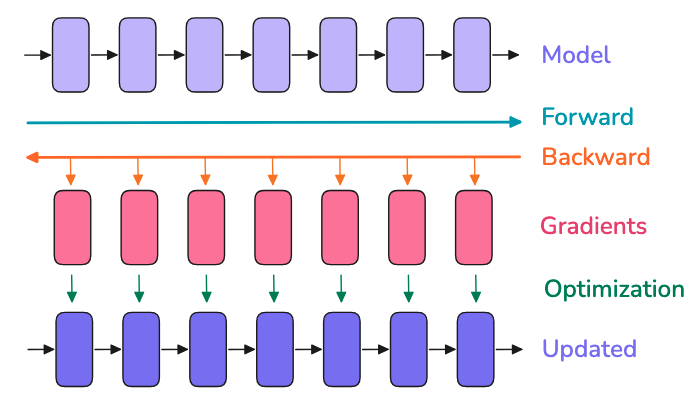
單GPU訓(xùn)練的三個基本步驟
當(dāng)你在單個GPU上訓(xùn)練一個模型時,整個過程通常可以分為三個步驟:
前向傳播(Forward Pass):將輸入數(shù)據(jù)通過模型,得到模型的輸出結(jié)果。這就好比把食材放進(jìn)烤箱,等待美味的蛋糕出爐。
反向傳播(Backward Pass):計算梯度,也就是找出模型需要改進(jìn)的方向。這一步就像是檢查蛋糕的口感,看看哪里需要調(diào)整。
優(yōu)化步驟(Optimization):用計算出的梯度來更新模型的參數(shù),讓模型變得更好。這就好比根據(jù)反饋調(diào)整烤箱的溫度和時間。
關(guān)鍵參數(shù):批次大小(Batch Size)
批次大小(Batch Size)是訓(xùn)練過程中一個非常重要的參數(shù)。它決定了每次訓(xùn)練時輸入模型的數(shù)據(jù)量。批次大小的選擇對模型的訓(xùn)練效果和效率有很大影響。
小批次大小:在訓(xùn)練初期,小批次大小可以幫助模型快速找到一個好的學(xué)習(xí)方向,就像在迷宮中快速試探出一條路。但如果一直使用小批次,模型的梯度會比較“嘈雜”,最終可能無法達(dá)到最優(yōu)性能。
- 大批量大小:大批量大小可以提供更準(zhǔn)確的梯度估計,但同時也會讓模型對每個訓(xùn)練樣本的利用效率降低,導(dǎo)致訓(xùn)練速度變慢,甚至浪費計算資源。
批次大小與訓(xùn)練時間
批次大小還會影響訓(xùn)練一個給定數(shù)據(jù)集所需的時間。小批次大小需要更多的優(yōu)化步驟來處理相同數(shù)量的數(shù)據(jù),而每個優(yōu)化步驟都需要計算時間,因此總訓(xùn)練時間會更長。不過,只要批次大小在最優(yōu)值附近,模型的最終性能通常不會受到太大影響。
在大型語言模型(LLM)的預(yù)訓(xùn)練領(lǐng)域,批次大小通常用“token”(標(biāo)記)數(shù)量而不是樣本數(shù)量來表示。這樣可以讓訓(xùn)練數(shù)據(jù)與輸入序列長度無關(guān),更加通用。
挑戰(zhàn):內(nèi)存不足怎么辦?
當(dāng)我們嘗試將訓(xùn)練擴(kuò)展到更大的批次大小時,第一個挑戰(zhàn)就來了——GPU內(nèi)存不足。當(dāng)我們的GPU無法容納目標(biāo)批次大小時,該怎么辦呢?
首先,我們需要理解為什么會出現(xiàn)內(nèi)存不足的問題。在訓(xùn)練神經(jīng)網(wǎng)絡(luò)時,我們需要在內(nèi)存中存儲以下內(nèi)容:
模型權(quán)重(Weights)
模型梯度(Gradients)
優(yōu)化器狀態(tài)(Optimizer States)
用于計算梯度的激活值(Activations)
訓(xùn)練過程中的內(nèi)存動態(tài)變化
使用PyTorch的分析工具,我們可以清楚地看到,內(nèi)存的使用并不是一成不變的,而是在訓(xùn)練過程中不斷變化。例如,在一個訓(xùn)練步驟中,內(nèi)存的使用會隨著前向傳播、反向傳播和優(yōu)化步驟而起伏。
前向傳播:當(dāng)我們開始訓(xùn)練時,模型的激活值會迅速增加,因為模型需要計算輸入數(shù)據(jù)的輸出結(jié)果。
反向傳播:隨著梯度的計算,內(nèi)存中的梯度值會逐漸積累,而用于計算梯度的激活值則會被逐步清理。
- 優(yōu)化步驟:最后,在更新模型參數(shù)時,我們需要使用所有梯度,并更新優(yōu)化器的狀態(tài)。
有趣的是,第一次訓(xùn)練步驟與其他步驟看起來很不一樣。這是因為PyTorch的內(nèi)存分配器在第一步中做了很多準(zhǔn)備工作,為后續(xù)步驟預(yù)留內(nèi)存,從而避免在后續(xù)步驟中頻繁搜索空閑內(nèi)存塊。這種機(jī)制雖然優(yōu)化了訓(xùn)練效率,但也可能導(dǎo)致一個常見問題:第一次訓(xùn)練步驟成功了,但后續(xù)步驟卻因為內(nèi)存不足而失敗。這正是因為優(yōu)化器狀態(tài)在第一次步驟后開始占用更多內(nèi)存。
如何估算模型的內(nèi)存需求?
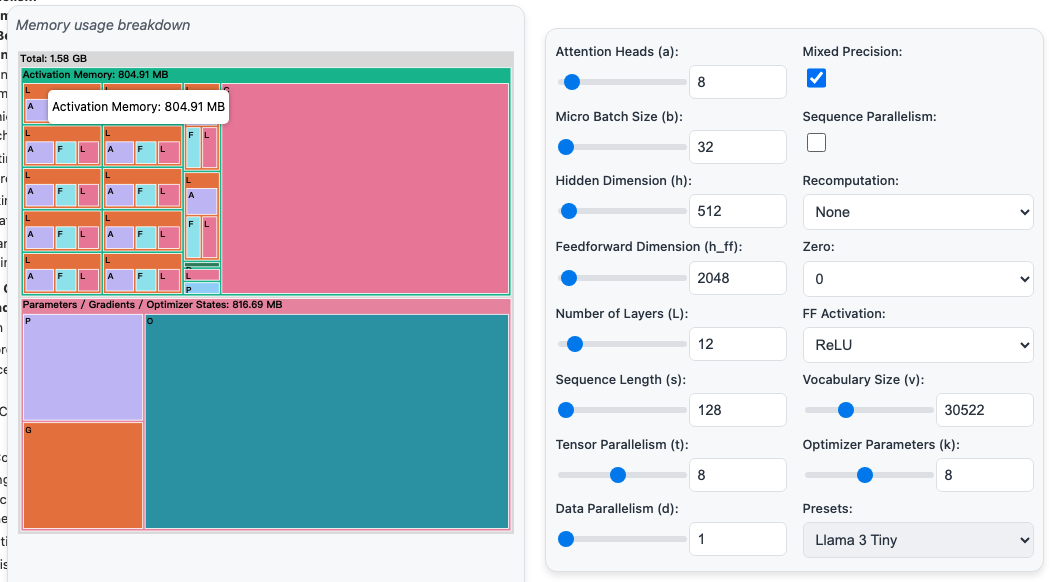
為了更好地管理內(nèi)存,我們需要了解模型的各個部分分別需要多少內(nèi)存。首先,我們來看看模型的權(quán)重、梯度和優(yōu)化器狀態(tài)。對于一個簡單的Transformer模型,其參數(shù)數(shù)量可以通過以下公式估算: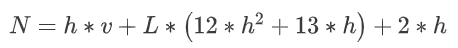 其中,h是隱藏層維度,v是詞匯表大小,L是模型層數(shù)。從這個公式可以看出,當(dāng)隱藏層維度增大時,h2項會迅速增長,成為內(nèi)存占用的主要部分。
其中,h是隱藏層維度,v是詞匯表大小,L是模型層數(shù)。從這個公式可以看出,當(dāng)隱藏層維度增大時,h2項會迅速增長,成為內(nèi)存占用的主要部分。
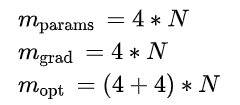
接下來,我們來計算這些參數(shù)的內(nèi)存需求。在傳統(tǒng)的全精度(FP32)訓(xùn)練中,每個參數(shù)和梯度需要4字節(jié),而優(yōu)化器(如Adam)還需要額外存儲動量和方差,每個參數(shù)再占用8字節(jié)。
如果使用混合精度訓(xùn)練(如BF16),雖然計算速度更快,但內(nèi)存需求會略有變化。在混合精度訓(xùn)練中,我們通常使用BF16(2字節(jié))進(jìn)行計算,同時保留一份FP32(4字節(jié))的模型權(quán)重副本,以確保數(shù)值穩(wěn)定性。因此,總內(nèi)存需求如下:
- 模型權(quán)重(BF16):
- 梯度(BF16):
- 模型權(quán)重副本(FP32):
- 優(yōu)化器狀態(tài)(FP32):
| 模型參數(shù)規(guī)模 | 全精度訓(xùn)練(FP32) | 混合精度訓(xùn)練(BF16 + FP32副本) |
|---|---|---|
| 10億參數(shù) | 16 GB | 20 GB |
| 70億參數(shù) | 112 GB | 140 GB |
| 700億參數(shù) | 1120 GB | 1400 GB |
| 4050億參數(shù) | 6480 GB | 8100 GB |
激活值內(nèi)存:訓(xùn)練中的“內(nèi)存大戶”
在訓(xùn)練大型語言模型時,激活值內(nèi)存(Activation Memory)是一個非常關(guān)鍵且復(fù)雜的部分。它不僅取決于模型的結(jié)構(gòu),還與輸入數(shù)據(jù)的長度和批次大小密切相關(guān)。激活值內(nèi)存的管理,往往決定了我們能否在有限的硬件資源上訓(xùn)練更大規(guī)模的模型。
激活值內(nèi)存的大小并不固定,它會隨著輸入序列的長度和批次大小的變化而變化。經(jīng)過仔細(xì)分析Transformer模型的反向傳播過程,我們可以估算出激活值內(nèi)存的大小。具體公式如下:
其中:L 是模型的層數(shù);seq 是輸入序列的長度;bs 是批次大小;h 是模型的隱藏層維度;n_heads 是多頭注意力機(jī)制中的頭數(shù)。
激活值重計算:用計算換內(nèi)存的“魔法”
在傳統(tǒng)的訓(xùn)練過程中,我們會存儲每一步的隱藏狀態(tài)(即激活值),以便在反向傳播時用來計算梯度。但有了激活值重計算,我們只需要在模型的關(guān)鍵節(jié)點存儲少量激活值,丟棄其余的激活值,并在反向傳播時從最近的保存點重新計算它們。這就好比在旅行中,你只在關(guān)鍵地點留下標(biāo)記,而不是記錄整個路線的每一個細(xì)節(jié)。激活值重計算有幾種不同的策略,每種策略在內(nèi)存節(jié)省和計算成本之間都有不同的權(quán)衡:1. 完整重計算(Full Recomputation)這種策略會在Transformer模型的每一層之間存儲激活值。因為它需要在反向傳播時重新執(zhí)行每一層的前向傳播,所以計算成本最高,但節(jié)省的內(nèi)存也最多。通常,這種策略會使計算成本和時間增加30-40%,效果非常明顯。2. 選擇性重計算(Selective Recomputation)
選擇性重計算是一種更高效的策略。研究人員發(fā)現(xiàn),注意力機(jī)制的計算通常占用大量內(nèi)存,但重新計算的成本較低。因此,我們可以丟棄這些激活值,而只存儲前饋網(wǎng)絡(luò)(Feedforward)的激活值。例如,在一個1750億參數(shù)的GPT-3模型中,這種策略可以減少70%的激活值內(nèi)存占用,而計算成本僅增加2.7%。
梯度累積:用“微批次”突破內(nèi)存限制
梯度累積的核心思想非常簡單:將一個大批次拆分成多個小批次(微批次),然后依次對每個微批次執(zhí)行前向傳播和反向傳播,計算梯度,并將這些梯度累加起來。最后,我們用累加后的梯度平均值來更新模型參數(shù)。這樣,我們就可以在不增加內(nèi)存占用的情況下,有效地模擬大批次訓(xùn)練的效果。

具體來說,我們把每個前向傳播的批次大小稱為“微批次大小”(Micro Batch Size, mbs),而把兩次優(yōu)化步驟之間的總批次大小稱為“全局批次大小”(Global Batch Size, gbs)。如果我們每執(zhí)行8次前向/反向傳播后進(jìn)行一次優(yōu)化步驟,那么全局批次大小就是微批次大小的8倍。雖然梯度累積解決了內(nèi)存問題,但它也有一個明顯的缺點:每次優(yōu)化步驟需要多次連續(xù)的前向/反向傳播,這會增加計算開銷,從而減慢訓(xùn)練速度。不過,如果你仔細(xì)思考,你會發(fā)現(xiàn)這些前向/反向傳播是可以并行化的——每個微批次的計算是獨立的,唯一的區(qū)別是輸入樣本不同。這意味著,我們可以通過多GPU并行計算來加速這一過程。數(shù)據(jù)并行:用多GPU加速模型訓(xùn)練在數(shù)據(jù)并行中,每個GPU處理一個獨立的微批次數(shù)據(jù),因此每個GPU上計算出的梯度是不同的。為了保持所有模型實例的一致性,我們需要在反向傳播過程中,通過一個稱為“全歸約”(all-reduce)的操作來平均這些梯度。全歸約是數(shù)據(jù)并行中的第一個“分布式通信原語”,它負(fù)責(zé)在GPU實例和節(jié)點之間同步和通信。
優(yōu)化數(shù)據(jù)并行的三種策略
1. 優(yōu)化一:計算與通信重疊在簡單的數(shù)據(jù)并行實現(xiàn)中,我們通常需要等待反向傳播完成后,才開始同步梯度。但其實,我們可以將通信與計算重疊起來,讓它們同時進(jìn)行。具體來說,當(dāng)反向傳播到達(dá)最后一層時,我們可以立即開始同步這些層的梯度,而不需要等待前面層的梯度計算完成。這樣,大部分全歸約操作可以在反向傳播過程中完成,從而提高效率。在PyTorch中,我們可以通過為每個參數(shù)添加一個全歸約鉤子函數(shù)來實現(xiàn)這一點。當(dāng)某個參數(shù)的梯度計算完成后,立即觸發(fā)全歸約操作,而其他參數(shù)的梯度計算仍在繼續(xù)。這樣可以顯著減少等待梯度同步的時間。2. 優(yōu)化二:梯度分桶(Bucketing)GPU在處理大型張量時通常比處理多個小型張量更高效,通信操作也是如此。因此,我們可以將梯度分組到“桶”中,然后對每個桶中的梯度執(zhí)行一次全歸約操作,而不是對每個梯度單獨執(zhí)行全歸約。這就像打包物品時,發(fā)送幾個大箱子比發(fā)送許多小箱子更高效。通過這種方式,我們可以顯著減少通信開銷,加快通信速度。3. 優(yōu)化三:與梯度累積結(jié)合
我們之前提到,梯度累積通過多次前向和反向傳播來累積梯度,然后在最后一步更新參數(shù)。當(dāng)我們將梯度累積與數(shù)據(jù)并行結(jié)合時,需要注意梯度同步的時機(jī)。在簡單的實現(xiàn)中,每次反向傳播后都會觸發(fā)全歸約操作,但這其實是不必要的。我們可以在最后一步統(tǒng)一觸發(fā)全歸約操作,從而減少通信開銷。
數(shù)據(jù)并行與梯度累積的結(jié)合
在訓(xùn)練大型語言模型時,全局批次大小(GBS)是一個關(guān)鍵參數(shù),它直接影響模型的收斂速度和訓(xùn)練效率。通過引入數(shù)據(jù)并行(Data Parallelism, DP)和梯度累積(Gradient Accumulation, GA),我們可以更靈活地調(diào)整全局批次大小,同時優(yōu)化訓(xùn)練速度和硬件利用率。全局批次大小 (GBS) = 微批次大小 (MBS) × 梯度累積步數(shù) (GA) × 數(shù)據(jù)并行實例數(shù) (DP)在實際應(yīng)用中,人們通常會優(yōu)先選擇最大化數(shù)據(jù)并行的節(jié)點數(shù)量(DP),因為數(shù)據(jù)并行是并行化的,而梯度累積是順序的。只有在數(shù)據(jù)并行無法滿足目標(biāo)全局批次大小時,才會增加梯度累積的步數(shù)。例如,當(dāng)我們有足夠的GPU時,可以通過增加數(shù)據(jù)并行的節(jié)點數(shù)量來加速訓(xùn)練,而不是單純依賴梯度累積。
確定目標(biāo)全局批次大小(GBS):通過查閱文獻(xiàn)或?qū)嶒灉y量模型的收斂情況,確定最佳的全局批次大小(以token為單位)。
選擇序列長度:根據(jù)文獻(xiàn)或?qū)嶒炦x擇合適的訓(xùn)練序列長度。通常,2-8k tokens是一個可靠的選擇。
確定單個GPU的最大微批次大小(MBS):逐步增加微批次大小,直到單個GPU的內(nèi)存不足。
- 確定可用的GPU數(shù)量:根據(jù)目標(biāo)數(shù)據(jù)并行實例數(shù)(DP),計算所需的梯度累積步數(shù)。全局批次大小除以數(shù)據(jù)并行實例數(shù),即為剩余的梯度累積步數(shù)。
ZeRO:零冗余優(yōu)化器,讓內(nèi)存管理更高效
DeepSpeed的ZeRO(Zero Redundancy Optimizer)通過將這些組件分散到不同的數(shù)據(jù)并行節(jié)點上,顯著減少了內(nèi)存冗余,同時仍然允許使用完整的參數(shù)集進(jìn)行計算。接下來,我們將深入了解ZeRO的三個階段:ZeRO-1、ZeRO-2和ZeRO-3。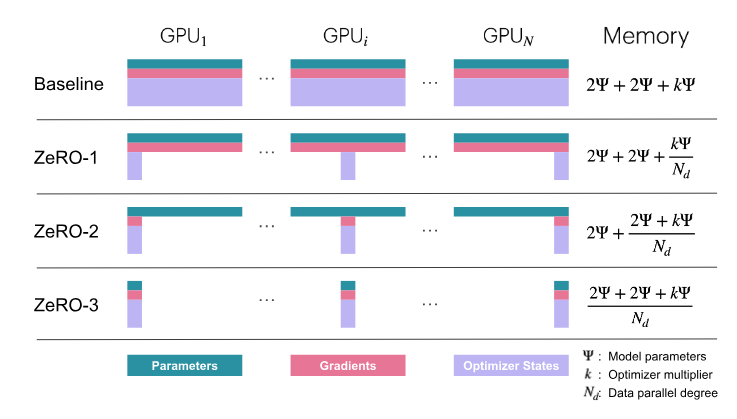
ZeRO-1:優(yōu)化器狀態(tài)分區(qū)
在傳統(tǒng)的數(shù)據(jù)并行中,所有節(jié)點在反向傳播后收集相同的梯度,并同時執(zhí)行相同的優(yōu)化器步驟。這不僅效率低下,還浪費了大量內(nèi)存。ZeRO-1通過將優(yōu)化器狀態(tài)分成N_d(數(shù)據(jù)并行度)等份來解決這個問題。每個模型副本只保留1/N_d的優(yōu)化器狀態(tài),并在優(yōu)化步驟中只更新1/N_d的浮點參數(shù)。
ZeRO-2:添加梯度分區(qū)
在ZeRO-1的基礎(chǔ)上,ZeRO-2進(jìn)一步將梯度也進(jìn)行分區(qū)。由于每個副本只需要與優(yōu)化器狀態(tài)對應(yīng)的梯度片段,因此在反向傳播時,我們只需要執(zhí)行“歸約分散”(reduce-scatter)操作,而不是“全歸約”(all-reduce)。這樣,每個副本只需要保留1/N_d的梯度,從而節(jié)省更多內(nèi)存。
ZeRO-3:添加參數(shù)分區(qū)
ZeRO-3(也稱為FSDP,即“完全分片數(shù)據(jù)并行”)是ZeRO的最終階段,它將模型參數(shù)也進(jìn)行了分區(qū)。這意味著每個副本在需要時才會動態(tài)收集所需的參數(shù)片段,并在使用后立即釋放它們。這種“按需收集”的方式進(jìn)一步減少了內(nèi)存占用。
張量并行:打破內(nèi)存限制的“魔法”在訓(xùn)練大型語言模型時,激活值內(nèi)存往往會成為瓶頸,尤其是在單個GPU無法容納模型的單層時。這時,張量并行(Tensor Parallelism, TP)就派上了用場。張量并行不僅分區(qū)了模型的參數(shù)、梯度和優(yōu)化器狀態(tài),還分區(qū)了激活值,且無需在計算前收集所有片段。
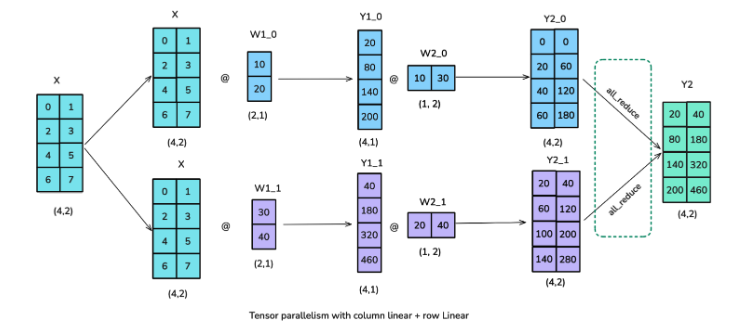
張量并行的基本原理
張量并行的核心在于矩陣乘法的數(shù)學(xué)性質(zhì)。在神經(jīng)網(wǎng)絡(luò)中,矩陣乘法通常表示為 X × W,其中:
- X是輸入或激活值;
- W是神經(jīng)網(wǎng)絡(luò)層的權(quán)重。
張量并行利用了矩陣乘法的兩個基本性質(zhì):
按列分區(qū):可以將矩陣 B 的每一列分別與矩陣 A 相乘,然后組合結(jié)果。
按行分區(qū):可以將矩陣 A 的每一行分別與矩陣 B 相乘,然后將結(jié)果相加。
按行分區(qū)(Row-wise Sharding)
按行分區(qū)是另一種實現(xiàn)方式。具體步驟如下:
- 按行分割權(quán)重矩陣:將權(quán)重矩陣 W 按行分割成多個片段,并將這些片段分配到不同的GPU上。
- 分割輸入矩陣:將輸入矩陣 X 分割成多個片段(需要一個“分散”操作,scatter)。
- 計算局部結(jié)果:每個GPU計算局部輸入矩陣與局部權(quán)重矩陣的乘積。
匯總結(jié)果:通過一個“全歸約”(all-reduce)操作,將所有GPU上的局部結(jié)果相加,得到最終結(jié)果。
多頭注意力機(jī)制(MHA)中的張量并行
多頭注意力機(jī)制是Transformer模型的核心部分,它涉及多個矩陣乘法操作(Q、K、V)。張量并行在MHA中的應(yīng)用也非常直觀:
按列分區(qū)(Column Parallel):將Q、K、V矩陣按列分割,并分配到不同的GPU上。每個GPU計算一個或多個注意力頭的輸出。這種方法非常適合多頭注意力機(jī)制,因為每個GPU可以獨立計算一個或多個頭的注意力結(jié)果。
- 按行分區(qū)(Row Parallel):對于輸出投影(Output Projection),可以按行分割權(quán)重矩陣,從而減少每個GPU上的內(nèi)存需求。
序列并行的基本原理
序列并行的核心思想是:在張量并行的基礎(chǔ)上,進(jìn)一步將激活值和計算分割到不同的GPU上,但這次是沿著輸入序列的維度,而不是隱藏維度。這種方法特別適用于那些需要完整隱藏維度的操作,如LayerNorm和Dropout。
以LayerNorm為例,它需要完整的隱藏維度來計算均值和方差:
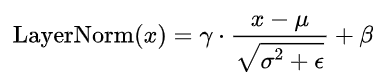
其中,均值和方差是在隱藏維度上計算的。盡管LayerNorm的計算成本較低,但它仍然需要大量的激活值內(nèi)存,因為需要完整的隱藏維度。序列井行通過在序列維度上分割激活值,將內(nèi)存負(fù)擔(dān)分散到多個GPU上,從而顯著減少了每個GPU的內(nèi)存需求。
Diving in the GPUs – fusing, threading, mixing
Fused Kernels
Flash Attention 1-3
Mixed Precision Training
-
AI
+關(guān)注
關(guān)注
87文章
34256瀏覽量
275412 -
人工智能
+關(guān)注
關(guān)注
1804文章
48717瀏覽量
246543 -
語言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10674
發(fā)布評論請先 登錄
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
大語言模型:原理與工程時間+小白初識大語言模型
【《大語言模型應(yīng)用指南》閱讀體驗】+ 俯瞰全書
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
深度融合模型的特點
深度學(xué)習(xí)模型是如何創(chuàng)建的?
一種基于亂序語言模型的預(yù)訓(xùn)練模型-PERT
訓(xùn)練大語言模型帶來的硬件挑戰(zhàn)

深度學(xué)習(xí)如何訓(xùn)練出好的模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論