 如何高效訓練Transformer?
如何高效訓練Transformer?
近期,微軟亞洲研究院從深度學習基礎理論出發,研發并推出了 TorchScale 開源工具包。TorchScale 工具包通過采用 DeepNet、Magneto 和 X-MoE 等最先進的建模技術,可以幫助研究和開發人員提高建模的通用性和整體性能,確保訓練模型的穩定性及效率,并允許以不同的模型大小擴展 Transformer 網絡。
如今,在包括語音、自然語言處理(NLP)、計算機視覺(CV)、多模態模型和 AI for Science 等領域的研究中,Transformer 已經成為一種通用網絡結構,加速了 AI 模型的大一統。與此同時,越來越多的實踐證明大模型不僅在廣泛的任務中能產生更好的結果、擁有更強的泛化性,還可以提升模型的訓練效率,甚至衍生出新的能力。因此,學術界和產業界都開始追求更大規模的模型。
然而隨著模型的不斷擴大,其訓練過程也變得更加困難,比如會出現訓練不收斂等問題。這就需要大量的手動調參工作來解決,而這不僅會造成資源浪費,還會產生不可預估的計算成本。
與其揚湯止沸,不如釜底抽薪。微軟亞洲研究院從深度學習基礎理論出發,創新推出了 TorchScale 工具包,并已將其開源。TorchScale 是一個 PyTorch 庫,允許科研和開發人員更高效地訓練 Transformer 大模型。同時,它有效地提升了建模的性能和通用性,提高了 Transformer 的穩定性和訓練效率。
TorchScale GitHub 頁面:
https://github.com/microsoft/torchscale
“我們希望通過 TorchScale 的系列工作從更底層出發做一些基礎性的研究創新,通過數學或者理論上的指導和啟發,在 Transformer 模型擴展的工作中取得更好的效果,而不是單純的調參或僅從工程層面部分緩解某些問題。TorchScale 能夠支持任意的網絡深度和寬度,實驗驗證它可以輕松擴大模型規模,而且只需要幾行代碼就能夠實現多模態模型的訓練。”微軟亞洲研究院自然語言計算組首席研究員韋福如表示。
據了解,TorchScale 主要從三個方面幫助科研人員克服了擴展 Transformer 大模型時的困難:
DeepNet:提升模型的穩定性。
Magneto:提升模型的通用性。
X-MoE:提升模型訓練的高效性。
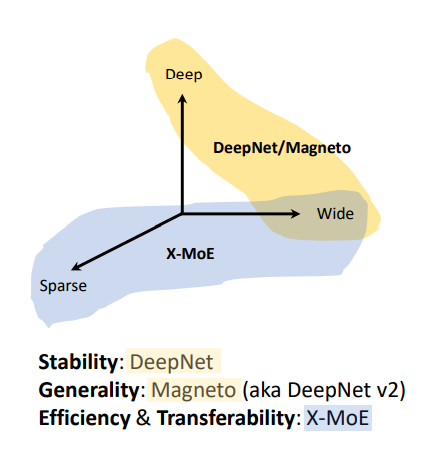
圖1:TorchScale 解決大模型在
穩定性、通用性、高效性上面臨的問題
DeepNet:讓Transformer訓練深度超過1000層
盡管近年來模型參數的數量越來越大,已經從百萬級擴展到萬億級,但參數的深度卻一直受限于 Transformer 訓練的不穩定性。為了解決這一問題,一些科研人員嘗試通過更好的初始化或架構來提升 Transformer 的穩定性,但這也只能讓 Transformer 在百層級別的深度下保持穩定。
微軟亞洲研究院的研究員們發現,模型輸出的劇烈變化是導致模型不穩定的重要原因。為此,研究員們在殘差連接處使用了一種新的歸一化函數——DeepNorm。新的函數由理論推導而來,可以把模型輸出的變化限制在常數范圍內。這種方法只需要改變幾行代碼,就可以大幅提升 Transformer 的穩定性。通過引入新的 DeepNorm 函數,研究員們訓練了超深的 Transformer 網絡 DeepNet,在保證模型穩定的同時,可以將模型深度擴展到1000層以上。
DeepNorm 同時具備 Post-LN 的性能和 Pre-LN 的訓練穩定性。這個新方法或將成為 Transformer 的首選替代方案,它不僅適用于深模型,更適用于大模型。值得一提的是,與具有120億參數的48層模型相比,微軟亞洲研究院32億參數的200層模型在100多個語言、超10000個語言對和130億個文本對的多語言機器翻譯實驗中實現了5 BLEU 的提升。在大規模多語言翻譯任務上,隨著 DeepNet 模型深度從10層擴展至100層和1000層,模型也獲得了更高的 BLEU 值。
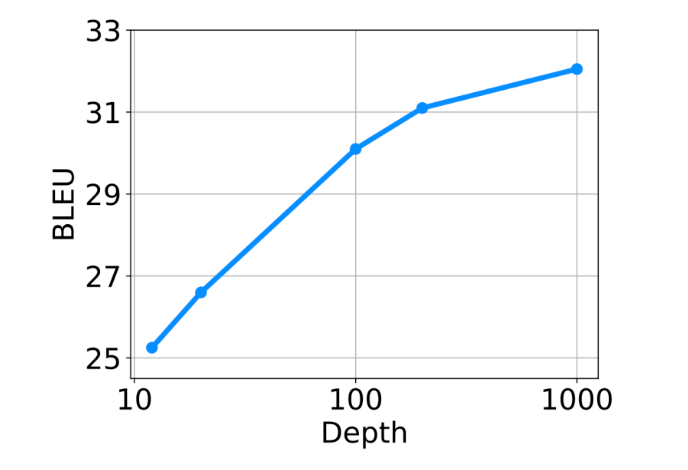
圖2:隨著模型深度從10層擴展至100層和1000層,DeepNet 有效提升了多語言翻譯結果
韋福如說,“此前,科研人員在訓練更大規模的模型時,往往需要投入大量的精力在模型調參上,無形中增加了實驗成本,有的模型在訓練中途就無法繼續下去了,即使給模型打上補丁也還是會影響模型性能。DeepNet 可以幫助科研人員大幅降低調參的負擔,在提升模型性能的同時降低實驗成本。”
Magneto:真正實現多模態模型架構統一
跨語言、視覺、語音和多模態的模型在模型結構上走向大一統的趨勢如今已經愈發明顯。具體而言,從 NLP 領域開始,Transformer 已成為 AI 各領域的主流結構。然而,盡管都使用了 Transformer,但不同模態任務的模型結構在具體實現時仍存在顯著差異。例如,GPT 和 ViT 模型采用了 Pre-LN Transformer,而 BERT 和機器翻譯模型使用的是 Post-LN 來獲得更好的性能。更重要的是,對于多模態模型,不同輸入模態的最優 Transformer 變體通常是不同的。以微軟亞洲研究院推出的多模態預訓練模型 BEiT-3為例,其使用 Post-LN 對于視覺部分是次優的,而 Pre-LN 對于語言部分是次優的。
要想讓多模態預訓練真正實現大一統就需要一個統一的架構,該架構需要在不同任務和模態上都能有良好的性能表現。另外,如之前所述,Transformer 架構訓練的穩定性也是一個痛點。微軟亞洲研究院的研究員們意識到,通用模型的開發需要更基礎的 Transformer,即 Foundation Transformer。首先它的建模能夠作為各種任務和模式的統一架構,這樣就可以使用相同的主干而無需反復魔改。其通用的設計原則也應該支持多模態基礎模型的開發,在不犧牲性能的前提下將統一的 Transformer 用于各種模態。其次,它的網絡結構應能夠保障訓練的穩定性,從而降低基礎模型大規模預訓練的難度。
為了實現這些目標,微軟亞洲研究院的研究員們提出了一個 Foundation Transformer——Magneto。在 Magneto 中,研究員們引入了 Sub-LN,為每個子層(即多頭自注意力和前饋網絡)添加了額外的 LayerNorm,并且提出了一種新的初始化方法,為從根本上提高訓練的穩定性提供了理論保證。
通過對 Magneto 在不同任務和模態上的評測,包括掩碼語言建模(即BERT)、因果語言建模(例如GPT)、機器翻譯、掩碼圖像建模(即BEiT)、語音識別和視覺語言預訓練(即BEiT-3),結果顯示在下游任務上,Magneto 顯著優于各種 Transformer 變體。此外,得益于訓練穩定性的提高,Magneto 還允許使用更高的學習率來進一步提高結果。
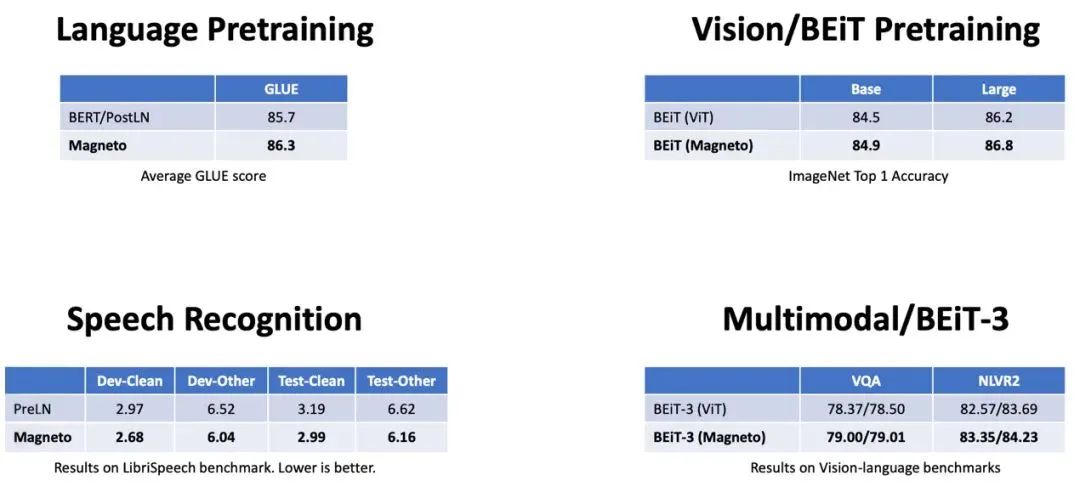
圖3:Magneto 在語言、圖像、
語音和多模態任務上的實驗結果
X-MoE:優于基線SMoE模型,助力模型高效訓練
在有關大模型訓練的研究中,除了將網絡深度做得更深和將寬度即隱藏維度擴大以外,還可以利用混合專家系統(Mixture of Experts, MoE)。盡管 MoE 可以在諸如語言模型和視覺表示學習等廣泛問題上獲得更好的性能,但也會導致更高的計算成本,這促使越來越多的科研人員開始探索稀疏混合專家模型(Sparse Mixture-of-Experts, SMoE)。SMoE 主要通過構建稀疏激活的神經網絡來增加模型容量。在不顯著增加計算開銷的情況下 SMoE 模型在各種任務(包括機器翻譯、圖像分類和語音識別)上的性能都優于稠密模型。
在 SMoE 模型中,路由機制發揮著重要的作用。給定輸入 token,路由機制會測量每個 token 與專家之間的相似度分數,然后再根據路由得分將 token 分配給最匹配的專家。因此,近年來許多研究都集中在如何設計 token 專家分配算法上。然而,微軟亞洲研究院的研究員們發現,當前的路由機制傾向于以專家為中心來推動隱藏表示聚類,這容易引起表征坍塌(Representation Collapse),損害模型性能。
為了緩解現有的路由機制引起的表征坍塌問題,微軟亞洲研究院的研究員們提出了新的方法 X-MoE,為 SMoE 模型引入了一種簡單而有效的路由算法。具體來說,區別于現有 SMoE 模型直接使用隱藏向量進行路由,X-MoE 先將隱藏向量投射到低維空間中,再對 token 表示和專家表示進行 L2 歸一化,來測量低維超球面上的路由分數。此外,研究員們還提出了軟專家門(soft expert gate),以學習控制專家的激活。
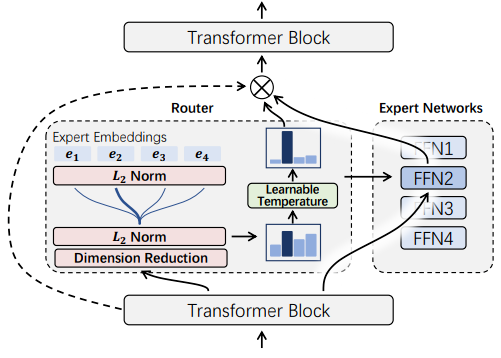
圖4:X-MoE 流程圖
微軟亞洲研究院的研究員們對這一新方法在跨語言模型預訓練任務上進行了評測。實驗結果表明,在語言建模和微調性能方面,基于 X-MoE 的模型始終優于基線 SMoE 模型。實驗分析還表明,與 SMoE 基線相比,X-MoE 方法有效緩解了表征坍塌問題。該方法在預訓練和微調期間也實現了更一致的路由行為,證實了 X-MoE 路由算法的有效性。
“隨著技術的持續演進,大模型的訓練不僅僅是工程層面的工作。我們應該從基礎研究的角度出發,探索下一代 Transformer 網絡架構。與此同時,在 AI 模型大一統趨勢的推動下,我們更應該追求同一結構來支持不同模態的輸入,并在不同語言和模態的任務上獲得良好的性能。通過理論指導讓模型變得更大、更穩定、更通用。”韋福如說。
審核編輯 :李倩
-
開源
+關注
關注
3文章
3612瀏覽量
43488 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46576 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14014
原文標題:如何高效訓練 Transformer?微軟亞研院開源TorchScale工具包
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于DINO知識蒸餾架構的分層級聯Transformer網絡
基于Transformer做大模型預訓練基本的并行范式
如何進行高效的時序圖神經網絡的訓練
探索一種降低ViT模型訓練成本的方法
教你如何使用Python搭一個Transformer
視覺新范式Transformer之ViT的成功
Transformer的復雜度和高效設計及Transformer的應用
超大Transformer語言模型的分布式訓練框架

探究超大Transformer語言模型的分布式訓練框架
用于語言和視覺處理的高效 Transformer能在多種語言和視覺任務中帶來優異效果
英偉達H100 Transformer引擎加速AI訓練 準確而且高達6倍性能
基于Transformer架構的文檔圖像自監督預訓練技術
PyTorch教程11.9之使用Transformer進行大規模預訓練

PyTorch教程-11.9. 使用 Transformer 進行大規模預訓練

Transformer在下一個token預測任務上的SGD訓練動態






 工商網監
工商網監
評論