") 超大Transformer語(yǔ)言模型的分布式訓(xùn)練框架
超大Transformer語(yǔ)言模型的分布式訓(xùn)練框架

NVIDIA Megatron 是一個(gè)基于 PyTorch 的框架,用于訓(xùn)練基于 Transformer 架構(gòu)的巨型語(yǔ)言模型。本系列文章將詳細(xì)介紹Megatron的設(shè)計(jì)和實(shí)踐,探索這一框架如何助力大模型的預(yù)訓(xùn)練計(jì)算。
大模型是大勢(shì)所趨
近年來(lái),NLP 模型的發(fā)展十分迅速,模型的大小每年以1-2個(gè)數(shù)量級(jí)的速度在提升,背后的推動(dòng)力當(dāng)然是大模型可以帶來(lái)更強(qiáng)大更精準(zhǔn)的語(yǔ)言語(yǔ)義理解和推理能力。
截止到去年,OpenAI發(fā)布的GPT-3模型達(dá)到了175B的大小,相比2018年94M的ELMo模型,三年的時(shí)間整整增大了1800倍之多。按此趨勢(shì),預(yù)計(jì)兩年后,會(huì)有100 Trillion參數(shù)的模型推出。
另外一個(gè)特點(diǎn)是,自從18年 Google 推出 Attention is All You Need論文后,這幾年的模型架構(gòu),不管是雙向的BERT,還是生成式的GPT,都是基于Transformer 架構(gòu)來(lái)構(gòu)建的,通常說(shuō)的模型有多少層,指的便是有多少個(gè)Transformer塊來(lái)堆疊起來(lái)的。
而且,這類模型的計(jì)算量也主要來(lái)自于對(duì)Transformer塊的處理,其本質(zhì)上可以轉(zhuǎn)化成大量的矩陣操作,天然地適合NVIDIA GPU的并行架構(gòu)。
分布式是大模型訓(xùn)練的必須
大模型的預(yù)訓(xùn)練對(duì)計(jì)算、通信帶來(lái)的挑戰(zhàn)是不言而喻的。我們以GPT-3 175B 模型為例,分析預(yù)訓(xùn)練對(duì)計(jì)算量、顯存、通信帶來(lái)的挑戰(zhàn)。
GPT-3 175B模型的參數(shù)如下:網(wǎng)絡(luò)層(Number of layers): 96
句子長(zhǎng)度(Sequence length): 2048
隱藏層大小(Hidden layer size): 12288
詞匯表(Vocabulary size):51200
總參數(shù)量:約175B
1. 對(duì)顯存的挑戰(zhàn)
175B的模型,一個(gè)原生沒有經(jīng)過優(yōu)化的框架執(zhí)行,各部分大概需要的顯存空間:
模型參數(shù):700 GB (175B * 4bytes)
參數(shù)對(duì)應(yīng)的梯度:700 GB
優(yōu)化器狀態(tài):1400 GB
所以,一個(gè)175B模型共需要大概2.8 TB的顯存空間,這對(duì) GPU 顯存是巨大的挑戰(zhàn):
1)模型在單卡、單機(jī)上存放不下。以 NVIDIA A100 80GB為例,存放此模型需要超過35塊。
2) 必須使用模型并行,并且需要跨機(jī)器。主流的A100 服務(wù)器是單機(jī)八卡,需要在多臺(tái)機(jī)器之間做模型切分。
2. 對(duì)計(jì)算的挑戰(zhàn)
基于Transformer 架構(gòu)的模型計(jì)算量主要來(lái)自于Transformer層和 logit 層里的矩陣乘,可以得出每個(gè)迭代步大致需要的計(jì)算量:
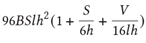
B: 批大小,S:句子長(zhǎng)度,l:Transformer 層數(shù),h:隱藏層大小,V:詞匯表大小
這是真實(shí)計(jì)算量的一個(gè)下限,但已是非常接近真實(shí)的計(jì)算量。關(guān)于此公式的詳細(xì)說(shuō)明,請(qǐng)參考 NVIDIA Paper(https://arxiv.org/abs/2104.04473)里的附錄章節(jié)。
其中S=2048, l=96, h=12288, V=51200,在我們的實(shí)踐中,B = 1536,一共需要迭代大約95000次。代入這次參數(shù)到上述公式,可以得到:
一次迭代的計(jì)算量:4.5 ExaFLOPS.
完整訓(xùn)練的計(jì)算量:430 ZettaFLOPS (~95K 次迭代)
這是一個(gè)巨大的計(jì)算量,以最新的 NVIDIA A100 的FP16計(jì)算能力 312 TFLOPS來(lái)計(jì)算,即使不考慮計(jì)算效率和擴(kuò)展性的情況,需要大概16K A100*days的計(jì)算量。直觀可以理解為16000塊A100一天的計(jì)算量,或者一塊A100 跑43.8年的計(jì)算量。
3. 對(duì)通信的挑戰(zhàn)
訓(xùn)練過程中GPU之間需要頻繁的通信,這些通信源于模型并行和數(shù)據(jù)并行的應(yīng)用,而不同的并行劃分策略產(chǎn)生的通信模式和通信量不盡相同。
對(duì)于數(shù)據(jù)并行來(lái)說(shuō),通信發(fā)生在后向傳播,用于梯度通信,通信類型為AllReduce,每次后向傳播中的通信量為每個(gè)GPU上的模型大小。
對(duì)于模型并行來(lái)說(shuō),稍微復(fù)雜些。模型并行通常有橫切和豎切兩種,比如把一個(gè)模型按網(wǎng)絡(luò)層從左到右橫著擺放,橫切即把每個(gè)網(wǎng)絡(luò)層切成多份(Intra-layer),每個(gè)GPU上計(jì)算網(wǎng)絡(luò)層的不同切塊,也稱為Tensor(張量)模型并行。豎切即把不同的網(wǎng)絡(luò)層切開(Inter-layer),每個(gè)GPU上計(jì)算不同的網(wǎng)絡(luò)層,也稱為Pipeline (流水線)模型并行。
對(duì)于Tensor模型并行,通信發(fā)生在每層的前向和后向傳播,通信類型為AllReduce,通信頻繁且通信量比較大。
對(duì)于Pipeline 模型并行,通信發(fā)生在相鄰的切分點(diǎn),通信類型主要為P2P,每次通信數(shù)據(jù)量比較少但比較頻繁,而且會(huì)引入額外的GPU 空閑等待時(shí)間。
稍后會(huì)詳細(xì)闡述在Transformer 架構(gòu)上如何應(yīng)用這兩種模型劃分方式。
更為復(fù)雜的是,對(duì)于超大的語(yǔ)言模型,通常會(huì)采用數(shù)據(jù)并行 + Tensor 模型并行 + Pipeline 模型并行混合的方式,這使得通信方式錯(cuò)綜復(fù)雜在一起,對(duì)系統(tǒng)連接拓?fù)涮岢龈蟮奶魬?zhàn):能靈活滿足不同劃分策略、不同通信模式下,不同通信組里高效的通信。
總而言之,超大語(yǔ)言模型的預(yù)訓(xùn)練,采用多節(jié)點(diǎn)的分布式訓(xùn)練是必須,而且是基于模型并行的。這就對(duì)集群架構(gòu)和訓(xùn)練框架提出了嚴(yán)苛的設(shè)計(jì)要求,集群架構(gòu)要有優(yōu)化的互聯(lián)設(shè)計(jì),訓(xùn)練框架更為重要:不僅僅是結(jié)合算法特點(diǎn)對(duì)模型做合理切割,更是需要做出結(jié)合系統(tǒng)架構(gòu)特點(diǎn)、軟硬一體的co-design。
為此,NVIDIA 分別提出了優(yōu)化的分布式框架NVIDIA Megatron 和優(yōu)化的分布式集群架構(gòu) NVIDIA DGX SuperPOD。
優(yōu)化的分布式框架:NVIDIA Megatron
Megatron設(shè)計(jì)就是為了支持超大的Transformer模型的訓(xùn)練的,因此它不僅支持傳統(tǒng)分布式訓(xùn)練的數(shù)據(jù)并行,也支持模型并行,包括Tensor并行和Pipeline并行兩種模型并行方式。
1. Tensor 模型并行
上面我們看到,對(duì)于一個(gè)Transformer塊,主要包括Masked Multi Self Attention和Feed Forward兩個(gè)部分,對(duì)于Tensor并行,需要把這兩部分都并行化。
對(duì)于Feed Forward部分,是由多個(gè)全連接層組成的MLP網(wǎng)絡(luò),每個(gè)全連接層由矩陣乘和GeLU激活或Dropout組成,在Megatron中,F(xiàn)eed Forward采用兩層全連接層。對(duì)于一個(gè)全連接層,可以表示為:
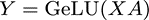
其中X輸入,A為參數(shù)矩陣,Y為輸出,則可以有兩種并行方式。
一種是按行的方向把權(quán)重矩陣A切分開并按列的方向把輸入X切分開,即: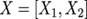
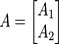 則輸出:
則輸出:
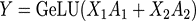
其中括號(hào)中的每一項(xiàng),可以在一個(gè)單獨(dú)的GPU上獨(dú)立的完成,再通過一次AllReduce完成求和操作。
另一種則是按列的方向把權(quán)重矩陣A切分開,而不切分輸入,即:
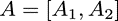
則可以得到同樣按列方向切分開的輸出:
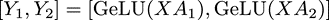
方括號(hào)中每一項(xiàng)可以在一個(gè)單獨(dú)的GPU上獨(dú)立的完成,這樣每個(gè)GPU上得到部分的最終輸出,大家拼接在一起就是完整輸出,不需要再做AllReduce。
Megatron在計(jì)算MLP時(shí)采用了這兩種并行方式,具體如下圖所示:
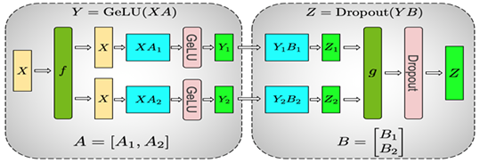
整個(gè)MLP的輸入X先通過f放到每一塊GPU上,然后先使用上面提到的按列切分權(quán)重矩陣A的方式,在每塊GPU上得到第一層全連接的部分輸出Y1和Y2,然后采用按行切分權(quán)重矩陣B,按列切分Y的方式,其中前一層的輸出Y1和Y2剛好滿足Y的切分需求,因此可以直接和B的相應(yīng)部分做相應(yīng)的計(jì)算而不需要額外操作或通信。這樣得到了最終Z的部分、Z1和Z2,通過g做AllReduce得到最終的Z,再通過相應(yīng)的激活層或Dropout。
這樣就完成了MLP層的Tensor并行,對(duì)于Masked Multi Self Attention層,如下圖所示:
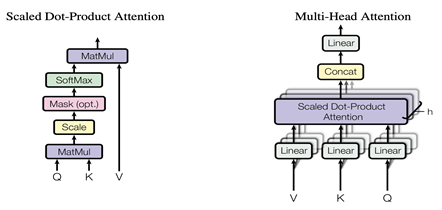
正如它的名字中提到的,它是由多個(gè)Self Attention組成的,因此很自然的并行方式就是可以把每個(gè)Self Attention分到不同的GPU上去進(jìn)行計(jì)算,這樣每塊GPU上就能夠得到輸出的一部分,最后的Linear全連接層,由于每個(gè)GPU上已經(jīng)有部分輸出,因此可以采用上面全連接層的按行的方向切權(quán)重矩陣B并按列的方向切輸入Y的方式直接進(jìn)行計(jì)算,再通過AllReduce操作g得到最終結(jié)果。
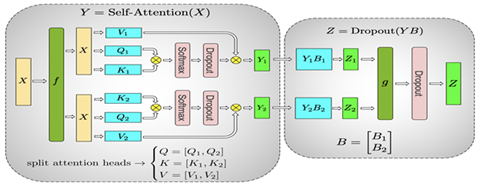
這樣我們就可以完成Transformer塊的Tensor并行。有了Tensor并行,我們可以把模型的每一層進(jìn)行切分,分散到不同的GPU上,從而訓(xùn)練比較大的模型。由于Tensor并行會(huì)對(duì)每一層進(jìn)行切分,并且需要通信,因此Tensor并行在同一臺(tái)機(jī)器上,并且有NVLink的加速情況下性能最好。如果模型進(jìn)一步增大,大到一臺(tái)機(jī)器可能都放不下整個(gè)模型,這時(shí)就需要引入另一種并行方式,Pipeline并行。
2. Pipeline 模型并行
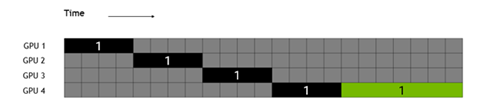
相對(duì)于Tensor并行的把模型的每一層內(nèi)部進(jìn)行切分,Pipeline并行是會(huì)在模型的層之間進(jìn)行切分,不同的層在不同的GPU或機(jī)器節(jié)點(diǎn)上進(jìn)行計(jì)算。由于不同的層間有依賴關(guān)系,所以如果直接并行會(huì)像下圖所示,黑色部分是前向,綠色部分是反向計(jì)算,灰色部分是空閑,可以看出GPU的絕大部分時(shí)間是在等待。
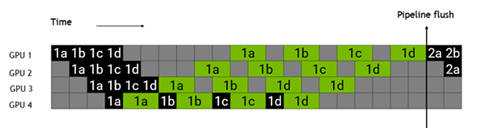
為了解決這個(gè)問題,Megatron把每一個(gè)batch分成了更小的microbatch,如下圖所示,把batch 1分成了1a,1b,1c,1d四個(gè)microbatch,由于不同的microbatch間沒有數(shù)據(jù)依賴,因此互相可以掩蓋各自的等待時(shí)間,提高GPU利用率,提升整體的性能。
這就是Megatron 核心的兩種模型并行的設(shè)計(jì),可以支撐超大的Transformer-based 語(yǔ)言模型,再結(jié)合經(jīng)典的數(shù)據(jù)并行方式,可以讓大模型的訓(xùn)練更快。
編輯:jq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91863 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5309瀏覽量
106404 -
gpu
+關(guān)注
關(guān)注
28文章
4946瀏覽量
131236 -
分布式
+關(guān)注
關(guān)注
1文章
997瀏覽量
75402 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4618
原文標(biāo)題:NVIDIA Megatron:超大Transformer語(yǔ)言模型的分布式訓(xùn)練框架 (一)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
雙電機(jī)分布式驅(qū)動(dòng)汽車高速穩(wěn)定性機(jī)電耦合控制
潤(rùn)和軟件StackRUNS異構(gòu)分布式推理框架的應(yīng)用案例

潤(rùn)和軟件發(fā)布StackRUNS異構(gòu)分布式推理框架

AI原生架構(gòu)升級(jí):RAKsmart服務(wù)器在超大規(guī)模模型訓(xùn)練中的算力突破
淺談工商企業(yè)用電管理的分布式儲(chǔ)能設(shè)計(jì)
小白學(xué)大模型:訓(xùn)練大語(yǔ)言模型的深度指南

騰訊公布大語(yǔ)言模型訓(xùn)練新專利
分布式云化數(shù)據(jù)庫(kù)有哪些類型
大模型訓(xùn)練框架(五)之Accelerate
大語(yǔ)言模型開發(fā)框架是什么
分布式通信的原理和實(shí)現(xiàn)高效分布式通信背后的技術(shù)NVLink的演進(jìn)

分布式光纖測(cè)溫是什么?應(yīng)用領(lǐng)域是?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論