 圖解B+樹的生成過程!
圖解B+樹的生成過程!
本文大概字數三千多,預計觀看時長十分鐘,練習時長兩個半小時。希望大家都能學到知識。
前提
不少網友看 B+ 樹,看不懂樹結構什么意思。希望本文可以幫你理解樹結構生成的過程。
在說 B+ 樹之前,需要知道,一頁的大小是多少。
showglobalstatuslike'innodb_page_size'
 MySQL一頁16kb
MySQL一頁16kb
這個是看出,一頁是 16384 也就是16384/1024 = 16kbinnodb 中一頁的大小默認是 16kb。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
正文
創建表結構 指定引擎為 Innodb。
CREATETABLEtree(
idintPRIMARYkeyauto_increment,
t_nameVARCHAR(20),
t_codeint
)ENGINE=INNODB
查看一下當前表的索引情況
showindexfromtree
B 樹和 B+ 樹的顯示都是 BTREE,但是實際使用的 B+ 樹。B+ 樹也是 B 樹的升級版,這里顯示為 B 樹也是沒有問題的。
 BTREE
BTREE創建數據,這里會有一個小知識點,如果看過上一篇文章的朋友可以明白是為什么。
INSERTintotreeVALUES(3,"變成派大星",3);
INSERTintotreeVALUES(1,"變成派大星",1);
INSERTintotreeVALUES(2,"變成派大星",2);
INSERTintotreeVALUES(4,"變成派大星",4);
INSERTintotreeVALUES(7,"變成派大星",7);
INSERTintotreeVALUES(5,"變成派大星",5);
INSERTintotreeVALUES(6,"變成派大星",6);
INSERTintotreeVALUES(8,"變成派大星",8);
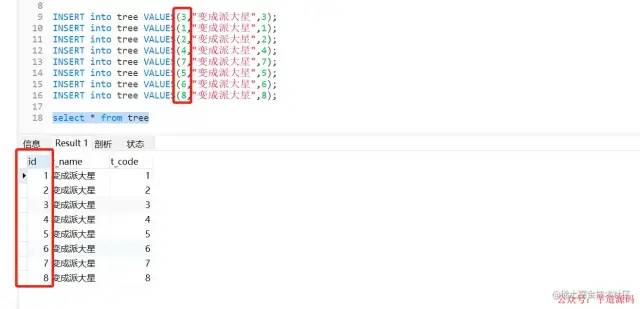 插入測試數據
插入測試數據疑問
為什么創建數據的時候數據是亂序的,但是在創建好數據,被排好順序了。
基礎知識
我們在尋找答案之前,想明白一些基礎知識。
細心的朋友可以看出來,我們插入 Id 時候數據是亂的,插入進去之后,數據就自動幫我通過 Id 進行排序了,這是為什么呢?接著往下看。
我們如果對于 B+ 樹有點了解的話就知道 B+ 樹是每頁 16KB 進行數據儲存。在進行數據查詢的時候也是一頁一頁的去查詢。
相當于下面的數據。
首先每一頁都有很多數據,就像我們平常去寫分頁的時候我們返回給前端的數據也會有很多屬性。
 MySQL數據頁
MySQL數據頁這個可能比較抽象,我是把他當成平常,分頁查詢的思想代入進去。
我們可以把一頁想成是一個對象。
@Data
publicclasspage{
Listdata;
//....省略其余屬性
}
我們先看一下,一頁數據的圖是什么樣子,僅僅是進行邏輯思考畫的圖。
這里的 Data,就相當于 一頁中的數據區域。
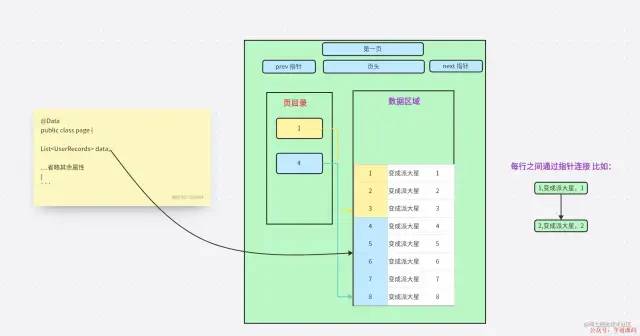 數據區域
數據區域但是這里是有限制的,上面我們說到,一頁的數據只能是 16Kb,也就是一個 Page 里面的 data 只能16Kb。當數據超過 16Kb,就會新開一個對象相當于在進行創建樹的時候增加了判斷。
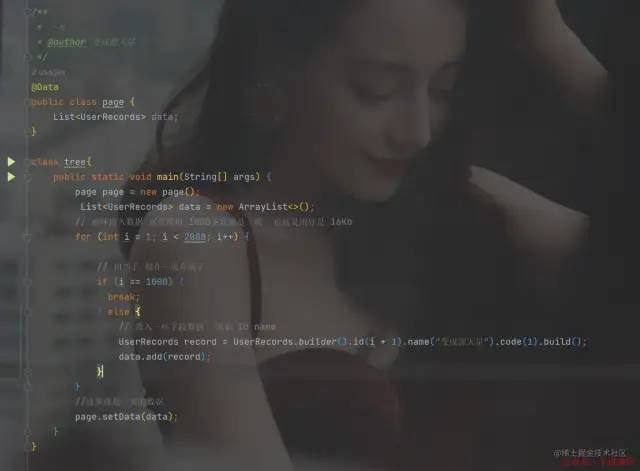 Java模擬MySQL數據頁
Java模擬MySQL數據頁當 Page 對象的大小已經達到16Kb 就算完成這一頁。把這一頁放到,磁盤中等待使用就行了,到時候進行查詢數據的時候會直接返回這一頁,里面包含這些數據。
我們回到最初的問題 為什么我們在進行插入的時候明明 Id 是亂的?等到插入到數據的時候,數據就變成有序的了?我們知道,同時這個數據是根據主鍵進行排序的,InnoDB 的數據儲存一定是要依賴主鍵的,有些人會想,我就是不創建主鍵,他還能排序嗎?
疑問二
我們在疑問一的基礎上,產生出的疑問,不設置主鍵 Mysql 怎么辦?
解答
InnoDB 對聚簇索引處理如下:
- 如果定義了主鍵,那么 InnoDB 會使用主鍵作為聚簇索引
- 如果沒有定義主鍵,那么會使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作為聚簇索引
- 如果既沒有主鍵也找不到合適的非空索引,InnoDB 會自動幫你創建一個不可見的、長度為 6 字節的 row_id,而且 InnoDB 維護了一個全局的 dictsys.row_id,所以未定義主鍵的表都共享該row_id,每次插入一條數據,都把全局 row_id 當成主鍵 id,然后全局 row_id 加 1
很明顯,缺少主鍵的表,InnoDB 會內置一列用于聚簇索引來組織數據。而沒有建立主鍵的話就沒法通過主鍵來進行索引,查詢的時候都是全表掃描,小數據量沒問題,大數據量就會出現性能問題。
但是,問題真的只是查詢影響嗎?不是的,對于生成的 ROW_ID,其自增的實現來源于一個全局的序列,而所以有 ROW_ID 的表共享該序列,這也意味著插入的時候生成需要共享一個序列,那么高并發插入的時候為了保持唯一性就避免不了鎖的競爭,進而影響性能
解答
我們看完疑問二的解答就知道,即便我們不設置主鍵。數據也會幫我們去生成一個默認的主鍵,有點像,類默認生成構造器的思想。
有了主鍵之后呢?
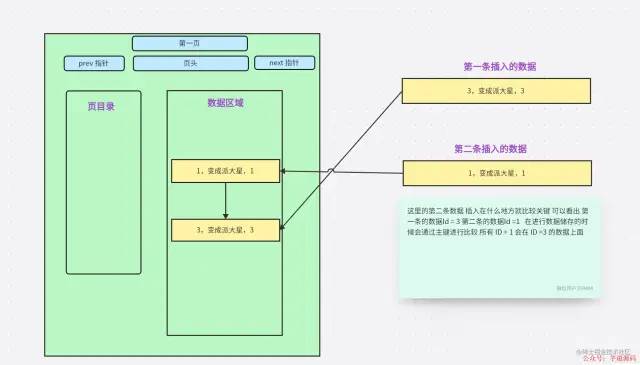 表中有主鍵
表中有主鍵為什么會自動排序,大家都知道了。其實在文章之初就會有很多人明白是為什么,大概腦子里會有答案。
疑問三
為什么要進行排序?
解答
我們都知道,在進行數據查找的時候,比如幾個基礎的查找算法的,前提都是,先進行排序。再者 List 和 Map 的一些區別肯定都很熟悉了。排序當然是為了更快,所以無須的 Id 會對插入效率造成影響,也就是為什么很多文章說使用自增 Id 比 UUID 或者雪花算效率高的原因。第一個是 UUID 他們是隨機的 每次都要重新排序,甚至可能會因為排序的原因造成頁數據的更換。還有就是 UUID 一般都比較長,一頁是 16Kb 數據越短。一頁的數據就會越多,查詢的速度也就比較快。
這里說完為什么排序 還有一個點就是上面的「頁目錄」
疑問三
頁目錄的作用是什么?
頁目錄的作用是減少范圍。
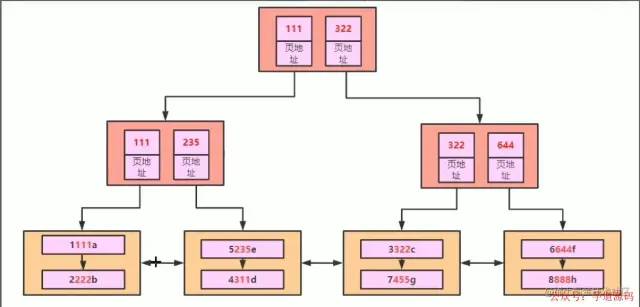 頁目錄
頁目錄這里的第三層是數據,上面都是目錄,可以增加數據的檢索效率。
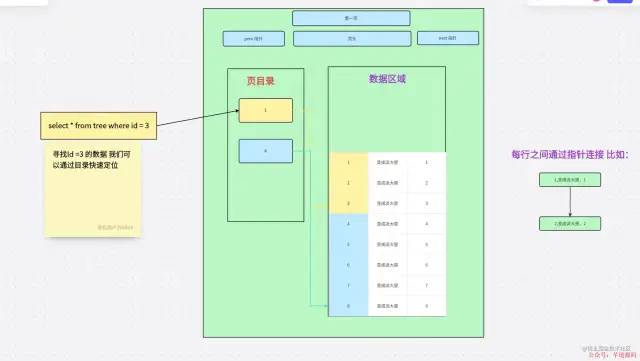 頁目錄增加數據的檢索效率
頁目錄增加數據的檢索效率如果沒有目錄我們需要去直接遍歷數據區域,會降低效率。目錄能幫我們縮小范圍,這里,我們查詢 ID = 3。我們可以通過目錄知道 1 < 3 < 4,如果在 1 中沒有找到對應數據。但是因為 3 < 4 就不會接著往下查詢了,直接返回空結果。
當第一頁沒有的時候去第二頁查詢,不會直接跳到第二頁查詢。
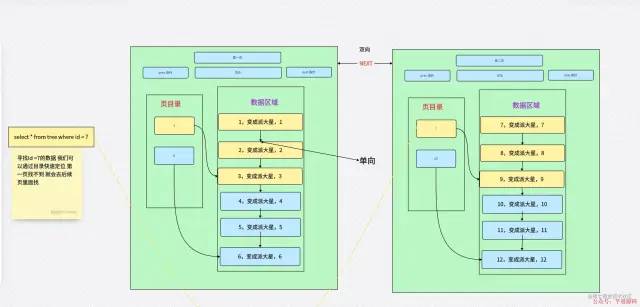 提高范圍查找效率
提高范圍查找效率為了提高效率,當目錄數據數量過多時,就會網上延伸一層樹,同時可以減少磁盤的 IO 次數。
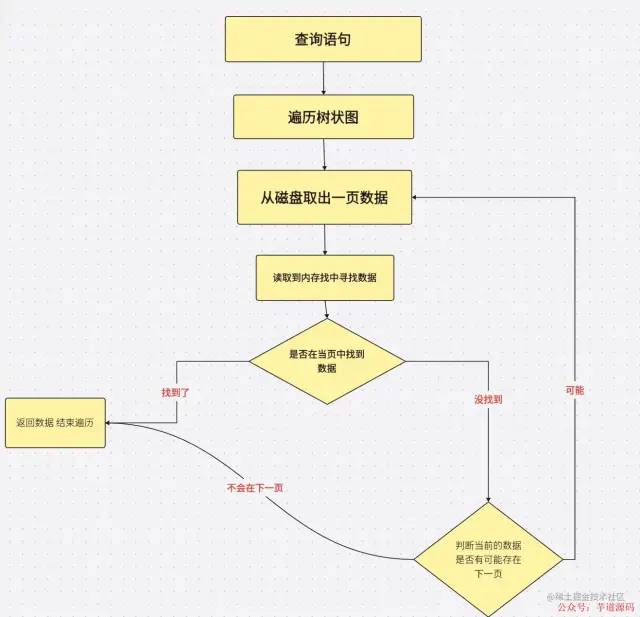 索引就是一顆樹
索引就是一顆樹關于所有葉子節點都處于同一深度是如何實現的?這與 B+ 樹具體的插入和刪除算法有關。簡單解釋一下插入時的情況,根據插入值的大小,逐步向下直到對應的葉子節點。如果葉子節點關鍵字個數小于 2t,則直接插入值或者更新衛星數據;如果插入之前葉子節點已經滿了,則分裂該葉子節點成兩半,并把中間值提上到父節點的關鍵字中,如果這導致父節點滿了的話,則把該父節點分裂,如此遞歸向上。所以樹高是一層層的增加的,葉子節點永遠都在同一深度。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
小總結
- 內部節點并不存儲真正的信息,而是保存其葉子節點的最小值作為索引。
- 每次插入刪除都進行更新(此時用到parent指針),保持最新狀態。
- B+ 樹非葉子節點上是不存儲數據的,僅存儲鍵值
- B+ 樹只在葉子節點上儲存“數據”,上層就會存儲更多的鍵值,相應的樹的階數(節點的子節點樹)就會更大,樹就會更矮更胖,如此一來我們查找數據進行磁盤的 IO 次數又會再次減少,數據查詢的效率也會更快。
- B+ 樹的階數是等于鍵值的數量的,如果我們的 B+ 樹一個節點可以存儲 1000 個鍵值,那么 3 層 B+ 樹可以存儲 1000×1000×1000=10 億個數據。
- 一般根節點是常駐內存的,所以一般我們查找 10 億數據,只需要 2 次磁盤 IO。
- 因為 B+ 樹索引的所有“數據”均存儲在葉子節點,而且數據是按照順序排列的。
- 那么 B+ 樹使得范圍查找,排序查找,分組查找以及去重查找變得異常簡單
- 有心的讀者可能還發現上圖 B+ 樹中各個頁之間是通過雙向鏈表連接的,葉子節點中的數據是通過單向鏈表連接的。
- 其實上面的 B 樹我們也可以對各個節點加上鏈表。這些不是它們之前的區別,是因為在 MySQL 的 InnoDB 存儲引擎中,索引就是這樣存儲的。
- 我們通過數據頁之間通過雙向鏈表連接以及葉子節點中數據之間通過單向鏈表連接的方式可以找到表中所有的數據。
結尾
感覺寫的有點啰嗦了 但是還是有點加深印象的 后續會接著整理一下相關的資料 補充進來
-
如果你是直接跳到這里,看看文章有多長
建議收藏 -
如果你一步步看到這里,感覺有點幫助
贊贊來一個 -
如果感覺文章有問題,建議評論區指出
會修正
審核編輯 :李倩
-
數據
+關注
關注
8文章
7240瀏覽量
90992 -
MySQL
+關注
關注
1文章
849瀏覽量
27517
原文標題:圖解B+樹的生成過程!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
北大教授領銜,無錫一傳感器公司完成B+輪數千萬元融資
PCB封裝圖解
?Diffusion生成式動作引擎技術解析
宏誠創新獲B+輪融資追加投資
使用TFTP加載內核設備樹
飛凌嵌入式ElfBoard ELF 1板卡-內核移植之編譯后生成文件說明
飛凌嵌入式ElfBoard ELF 1板卡-內核移植之編譯后生成文件說明
C語言生成可執行二進制文件的具體過程
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據






 工商網監
工商網監
評論