") 如何打造BEV + Transformer的技術(shù)架構(gòu)?
如何打造BEV + Transformer的技術(shù)架構(gòu)?
Nullmax感知部總監(jiān)兼計(jì)算機(jī)視覺首席科學(xué)家成二康博士,前段時(shí)間做客汽車之心·行家說欄目,就行泊一體的感知能力話題進(jìn)行了分享。
當(dāng)中,成二康博士就自動(dòng)駕駛的數(shù)據(jù)閉環(huán)以及虛擬樣本生成等數(shù)據(jù)話題進(jìn)行了概括性的介紹,并對(duì)當(dāng)前備受關(guān)注的BEV感知,尤其是BEV + Transformer技術(shù)架構(gòu),從總結(jié)和實(shí)踐兩方面進(jìn)行了簡(jiǎn)明易懂的闡述。
我們將成二康博士分享的主體內(nèi)容進(jìn)行了整理,本篇是關(guān)于BEV + Transformer的精簡(jiǎn)介紹。目前,Nullmax已經(jīng)完成了BEV感知的一系列工作,并在量產(chǎn)項(xiàng)目開始了相關(guān)技術(shù)的運(yùn)用。
行泊一體是一個(gè)很熱的話題,簡(jiǎn)單來講就是用一個(gè)域控或者嵌入式平臺(tái)同時(shí)實(shí)現(xiàn)行車、泊車兩大功能。因此,行泊一體的方案對(duì)于整個(gè)系統(tǒng)的感知架構(gòu)也有著極高的要求。
比如,需要處理包括相機(jī)、毫米波雷達(dá)等多個(gè)傳感器的輸入,需要支持行泊一體中的融合、定位、規(guī)劃和感知等多個(gè)任務(wù)。尤其是視覺感知方面,需要支持360度覆蓋的相機(jī)配置,為下游的規(guī)劃、控制任務(wù)輸出目標(biāo)檢測(cè)、車道線檢測(cè)等感知結(jié)果。
為此,Nullmax開發(fā)了一套強(qiáng)大的感知架構(gòu),它最大的優(yōu)勢(shì)就在于可以同時(shí)融合時(shí)間、空間信息,很好地支持多傳感器、多任務(wù)的協(xié)同工作。
在整個(gè)感知架構(gòu)的設(shè)計(jì)中,Nullmax對(duì)BEV + Transformer的技術(shù)架構(gòu)進(jìn)行了充分的考慮,在技術(shù)研發(fā)和項(xiàng)目落地兩方面同步進(jìn)行了大量工作,取得了不錯(cuò)進(jìn)展。
在自動(dòng)駕駛中,BEV(鳥瞰圖)視角下的感知輸出,能夠更好地為規(guī)劃、控制等下游任務(wù)服務(wù),因此設(shè)計(jì)一個(gè)BEV-AI的技術(shù)架構(gòu),對(duì)于行泊一體方案來說很有意義。
這個(gè)架構(gòu)的輸入,是多個(gè)相機(jī)拍攝的圖像,輸出則是自動(dòng)駕駛的一系列任務(wù),當(dāng)中包含了動(dòng)態(tài)障礙物的檢測(cè)和預(yù)測(cè),靜態(tài)場(chǎng)景的理解,以及這兩個(gè)基礎(chǔ)之上的一系列下游規(guī)控任務(wù)。
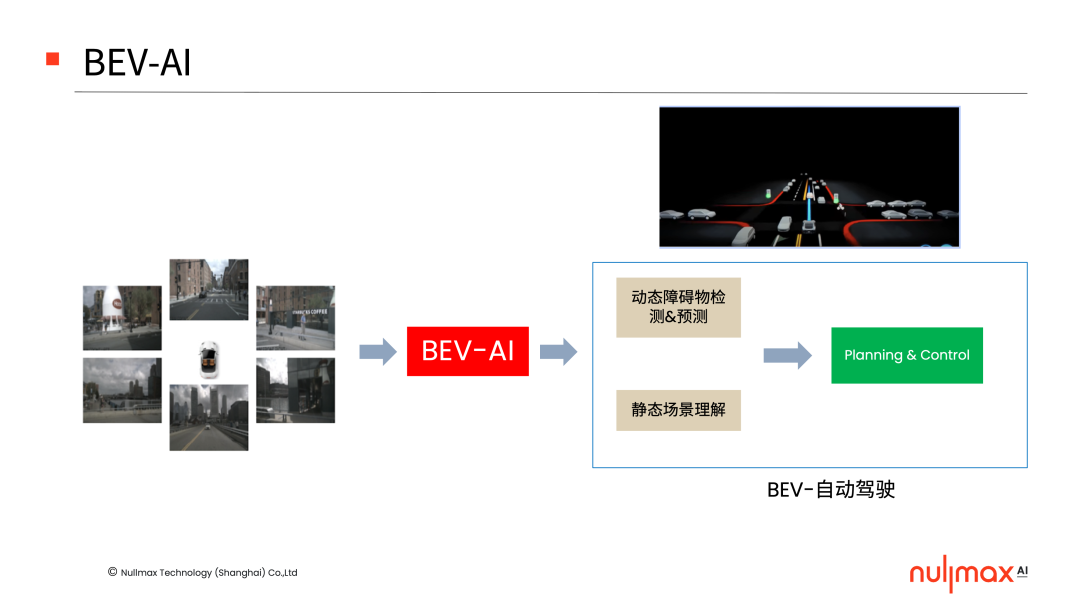
當(dāng)中的挑戰(zhàn)就在于:圖像是二維的平面空間,但是BEV空間以及自動(dòng)駕駛的車體坐標(biāo)系是三維的立體空間,如何才能去實(shí)現(xiàn)圖像空間和三維空間的影射?

1、BEV-CNN架構(gòu)
在傳統(tǒng)的CNN(卷積神經(jīng)網(wǎng)絡(luò))層面,天然的想法就是去做純粹的端到端方法。輸入一張圖片,直接輸出三維結(jié)果,不利用相機(jī)參數(shù)。
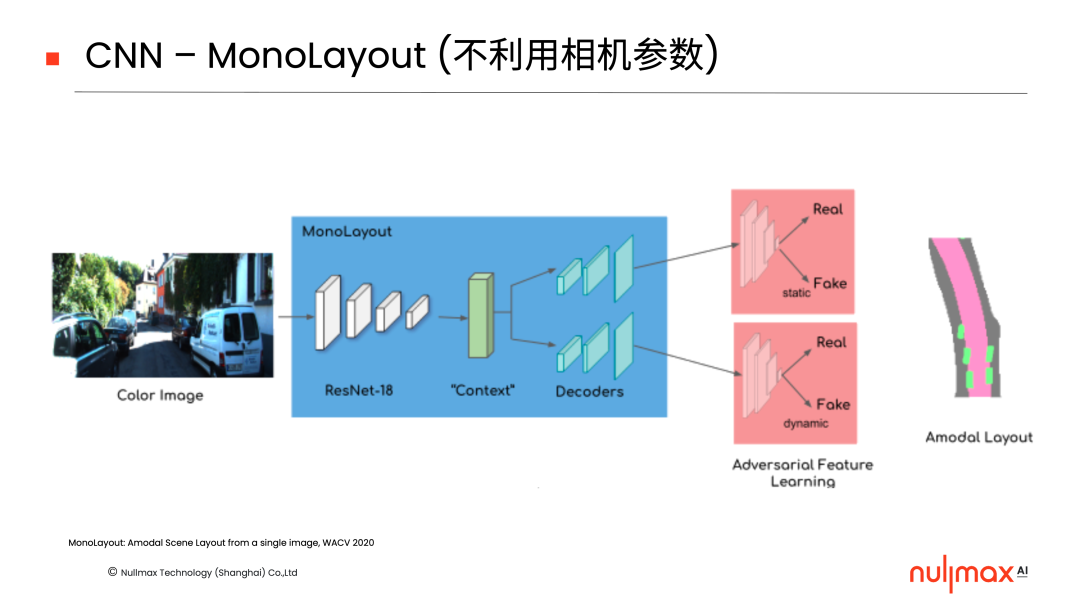
但是,相機(jī)對(duì)三維世界的成像遵循著一些原理,相機(jī)參數(shù)其實(shí)也能派上用場(chǎng)。比如,三維世界中的一個(gè)點(diǎn),它可以通過相機(jī)的外參投到相機(jī)的三維坐標(biāo)系中,然后再通過透視變換投到圖像平面,完成3D到2D的轉(zhuǎn)換。
在CNN當(dāng)中,利用相機(jī)參數(shù)和成像原理,實(shí)現(xiàn)3D和2D信息關(guān)聯(lián)的方法可以總結(jié)為兩種。一種是在后端,利用3D到2D的投影,即一個(gè)光心射線上面所有的3D點(diǎn)都會(huì)投影到一個(gè)2D像素上,完成3D和2D信息的關(guān)聯(lián)。知名的OFT算法,就是這一類方法的代表性工作。
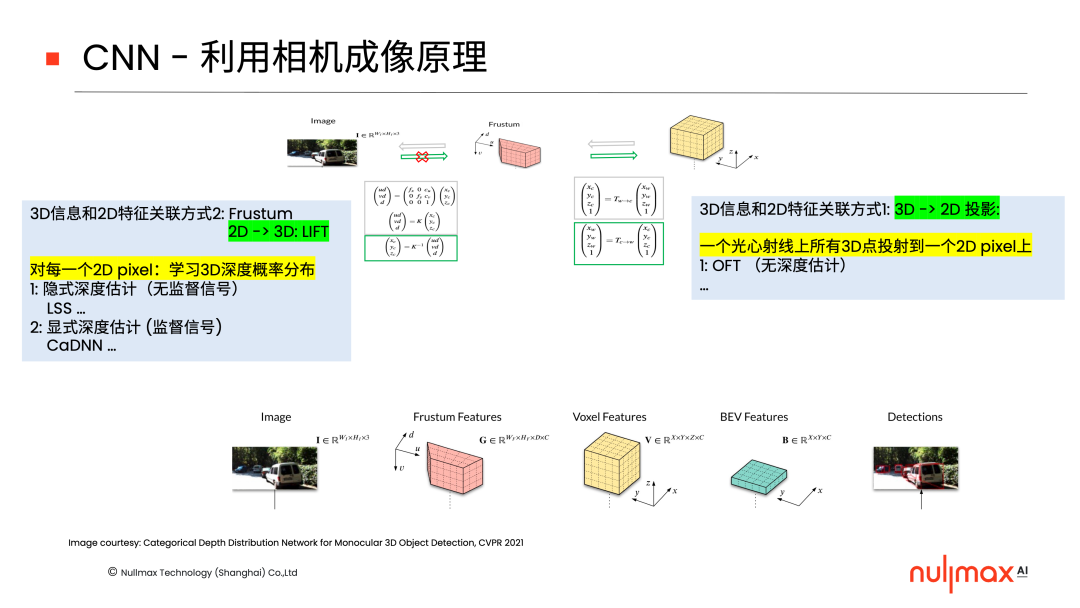
另外一種是在前端,讓每一個(gè)像素學(xué)習(xí)三維深度的分布,把2D空間lift成3D空間。這當(dāng)中又可以細(xì)分為兩種方式,一種是隱式的學(xué)習(xí),典型的算法有LSS,對(duì)每個(gè)點(diǎn)都要學(xué)一個(gè)特征,同時(shí)隱式地學(xué)習(xí)該點(diǎn)深度的概率分布;另一種則是顯式估計(jì)每個(gè)像素的深度,比如CaDNN。
2、BEV-Transformer架構(gòu)
在有了Transformer之后,它天然提供了一種機(jī)制,可以利用decoder中的cross-attention(交叉注意力)機(jī)制,架接3D空間和2D圖像空間的關(guān)系。
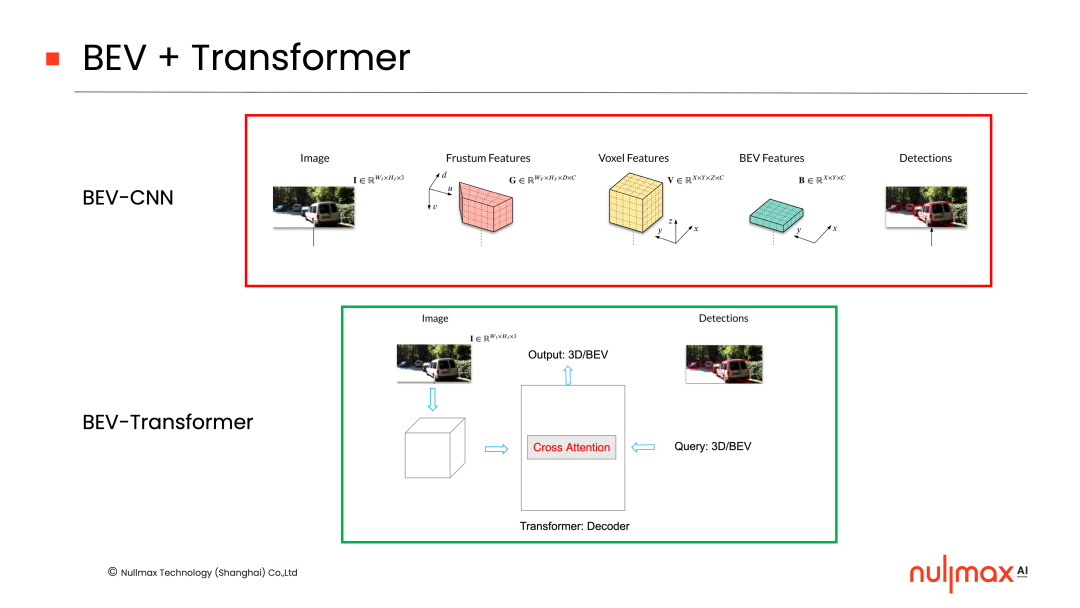
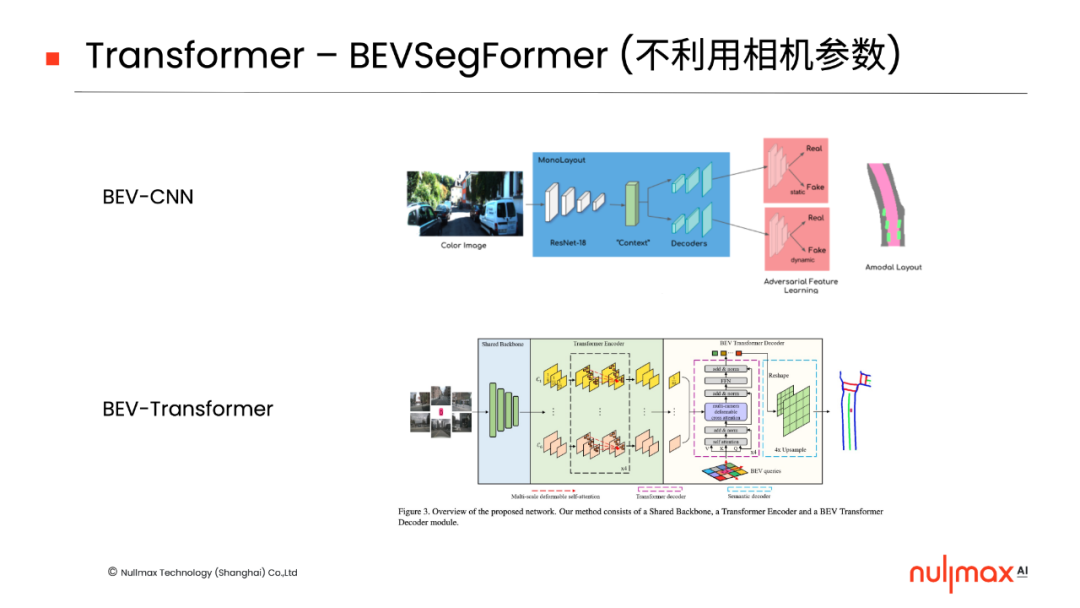
BEV-Transformer的實(shí)現(xiàn)方式也可分為兩類,一類是通過cross-attention機(jī)制,在后端加入3D信息和2D特征的關(guān)聯(lián),它可以進(jìn)一步細(xì)分為利用相機(jī)參數(shù)、不利用相機(jī)參數(shù)兩種方式,比如Nullmax提出的BEVSegFormer,就是不利用相機(jī)參數(shù)的形式。
另一類是在前端,通過Frustum(視錐)的方式,2D特征上面直接加入3D信息,PETR的一系列工作就是這方面的研究。
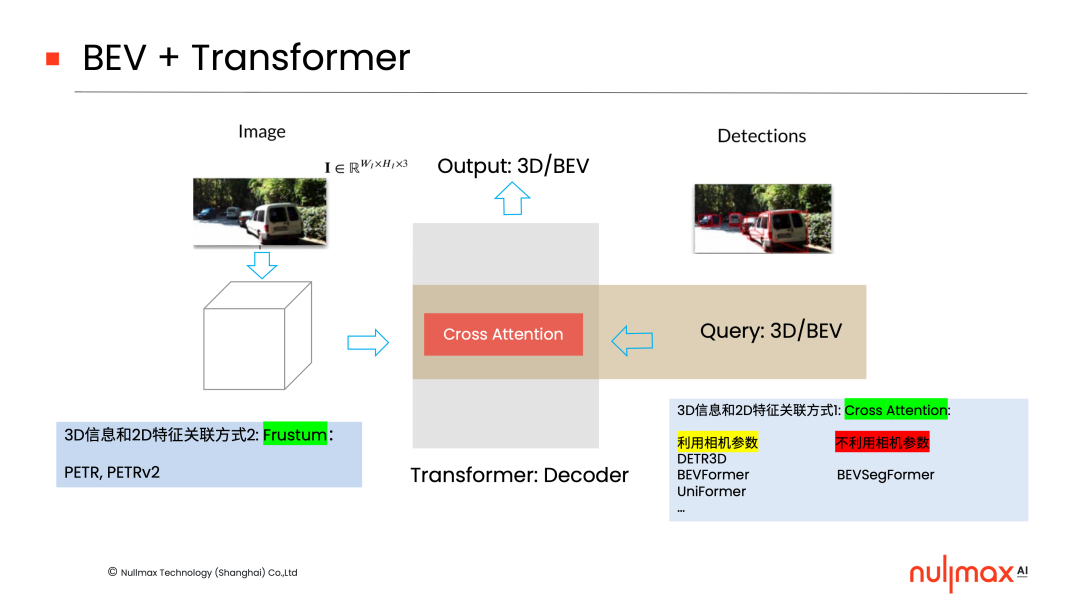
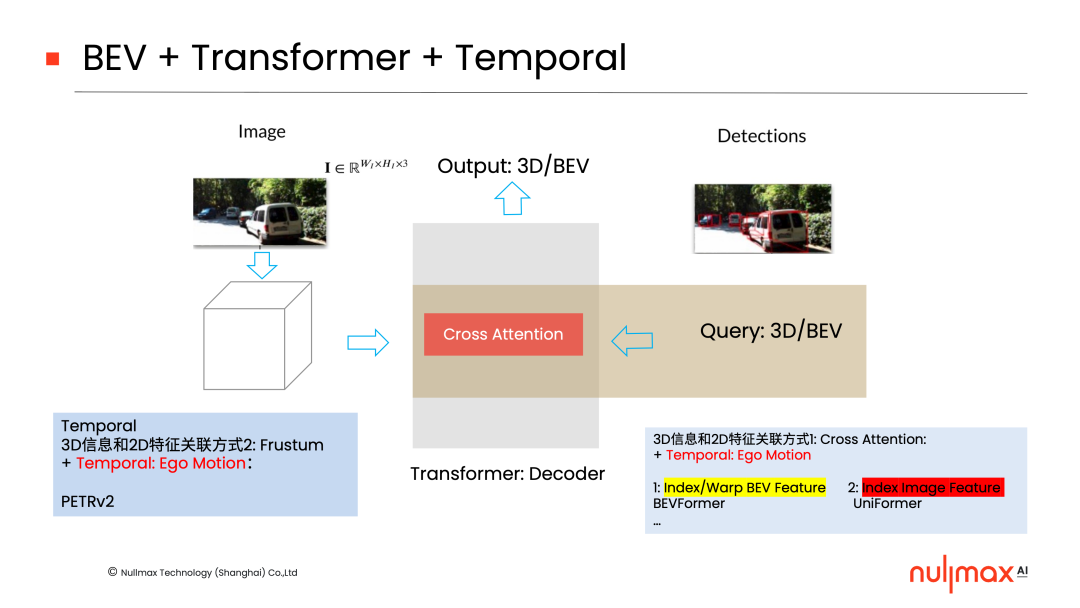
此外,在BEV + Transformer的基礎(chǔ)上,也可以加入temporal(時(shí)間)的信息。
具體來說,就是利用temporal當(dāng)中的ego motion(自運(yùn)動(dòng))信息。比如,三維世界通過ego motion在后端去關(guān)聯(lián);或者在前端,通過兩個(gè)相機(jī)坐標(biāo)系之間的ego motion將3D信息疊加進(jìn)去,然后在2D特征上面去做任務(wù)。
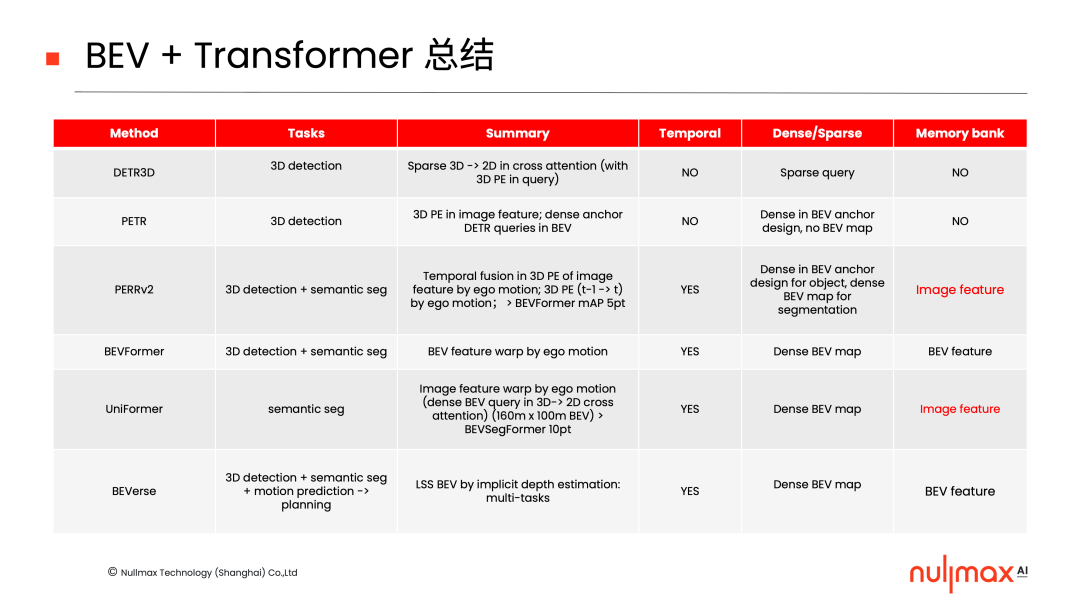
目前BEV + Transformer的方法比較多,我們對(duì)比較主流的幾種方式做了一個(gè)簡(jiǎn)單的總結(jié)。
3、Nullmax的多相機(jī)BEV方案
Nullmax正在開發(fā)多相機(jī)BEV方案,這些工作與前述的工作有所不同,面臨一些獨(dú)特的挑戰(zhàn)。

當(dāng)中有兩個(gè)非常關(guān)鍵的問題:一是支持任意多個(gè)相機(jī),二是不依賴相機(jī)參數(shù)。
此前,Nullmax提出的BEVSegFormer就是當(dāng)中的一項(xiàng)工作(現(xiàn)已被WACV 2023錄用),面向任意數(shù)量相機(jī)的BEV語(yǔ)義分割,為自動(dòng)駕駛在線實(shí)時(shí)構(gòu)建局部地圖。它在不利用相機(jī)參數(shù)的情況下,可以完成二維圖像和三維感知的關(guān)聯(lián)。「點(diǎn)擊查看詳盡解讀」
在nuScenes數(shù)據(jù)集上,BEVSegFormer相比于HDMapNet,效果提升了10個(gè)百分點(diǎn)。
除此之外,顯式構(gòu)建BEV是一個(gè)難點(diǎn),對(duì)于空間中只有少數(shù)幾個(gè)目標(biāo)的任務(wù),例如車道線,Nullmax提出了不顯式構(gòu)建BEV的方法,直接計(jì)算三維車道線的新范式。
這是Nullmax近期在3D車道線檢測(cè)方面的工作之一,通過設(shè)計(jì)sparse的curve query來完成車道線檢測(cè)。在Apollo數(shù)據(jù)集上,Nullmax的3D車道線檢測(cè)方法對(duì)比PersFormer,效果進(jìn)一步提升。「點(diǎn)擊查看詳盡解讀」
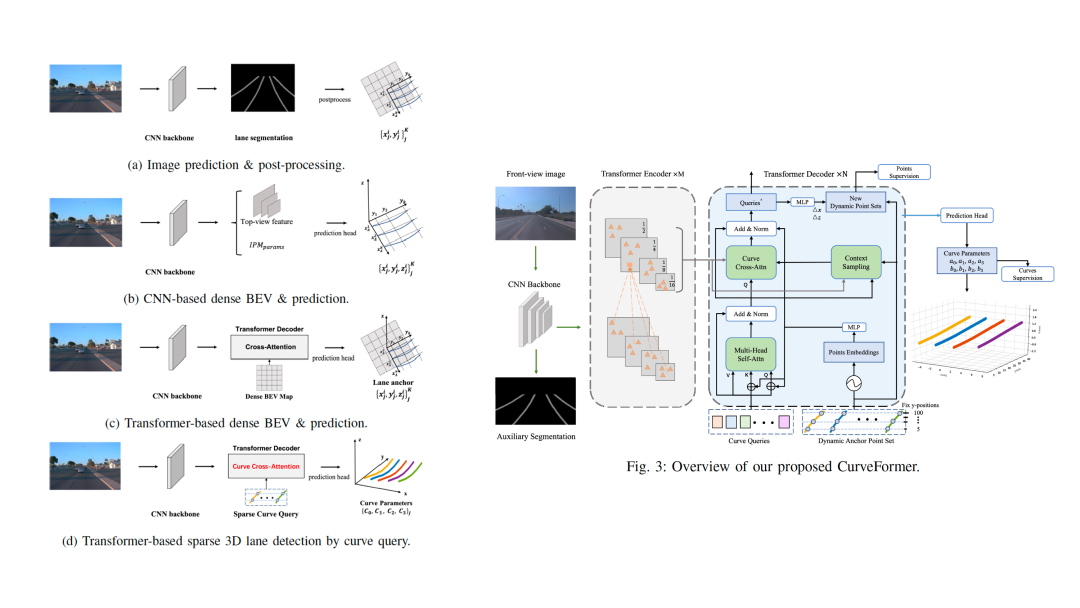
同樣的,Nullmax也將3D目標(biāo)檢測(cè)的一些工作擴(kuò)展到了量產(chǎn)應(yīng)用中,特別是在低算力平臺(tái)上進(jìn)行BEV視角的檢測(cè)。比如近期交付的一個(gè)量產(chǎn)方案,就是用8 TOPS算力實(shí)現(xiàn)4個(gè)周視相機(jī)的3D障礙物檢測(cè),當(dāng)中的優(yōu)化工作,非常具有挑戰(zhàn)。

在3D障礙物檢測(cè)方面,BEV + Transformer架構(gòu)融合多個(gè)相機(jī)信息,可以帶來一些明顯的優(yōu)勢(shì)。
在多相機(jī)的感知系統(tǒng)中,如果進(jìn)行障礙物檢測(cè),比較傳統(tǒng)的方案是每個(gè)相機(jī)單獨(dú)工作。這會(huì)導(dǎo)致系統(tǒng)的工作量比較大,每個(gè)相機(jī)都要完成目標(biāo)檢測(cè)、跟蹤、測(cè)距,還要完成不同相機(jī)的ReID(重識(shí)別)。同時(shí),這也給跨相機(jī)的融合帶來很大挑戰(zhàn),比如截?cái)嘬囕v的檢測(cè)或者融合。

如果技術(shù)架構(gòu)的輸出是BEV視角,或者車體坐標(biāo)下的三維感知結(jié)果的話,那么這個(gè)工作就可以簡(jiǎn)化,準(zhǔn)確率也能提升。
總體而言,Nullmax目前已經(jīng)在基于BEV的多相機(jī)感知方面完成了系列工作,包括BEV + Transformer的局部地圖、3D車道線檢測(cè)、3D目標(biāo)檢測(cè),以及在高、中、低算力嵌入式平臺(tái)的上線。
Nullmax希望做出的BEV + Transformer架構(gòu)能夠適配多個(gè)相機(jī)、不同相機(jī),以及不同相機(jī)的選型、內(nèi)參、外參等等因素,提供一個(gè)真正平臺(tái)化的產(chǎn)品。

同時(shí),我們還在進(jìn)行一些這里沒有介紹的工作,包括BEV視角下的規(guī)劃控制,以及支撐BEV + Transformer技術(shù)架構(gòu)的關(guān)鍵任務(wù),比如離線的4D Auto-GT(自動(dòng)化4D標(biāo)注真值)。
最終,我們希望完成一套可在車端實(shí)時(shí)運(yùn)行BEV + Transformer基礎(chǔ)架構(gòu)的整體方案,同時(shí)支持感知、預(yù)測(cè)、規(guī)劃任務(wù),并在高、中、低算力平臺(tái)上完成落地。
審核編輯 :李倩
-
嵌入式
+關(guān)注
關(guān)注
5141文章
19526瀏覽量
314878 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14194瀏覽量
169504 -
Transformer
+關(guān)注
關(guān)注
0文章
148瀏覽量
6389 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
679
原文標(biāo)題:Nullmax研習(xí)社 | 面向行泊一體,如何打造BEV + Transformer的技術(shù)架構(gòu)?
文章出處:【微信號(hào):Nullmax,微信公眾號(hào):Nullmax紐勱】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
正力新能助力零跑汽車打造全球平價(jià)智能電動(dòng)車標(biāo)桿
康謀方案 | BEV感知技術(shù):多相機(jī)數(shù)據(jù)采集與高精度時(shí)間同步方案

如何使用MATLAB構(gòu)建Transformer模型

transformer專用ASIC芯片Sohu說明

淺析基于自動(dòng)駕駛的4D-bev標(biāo)注技術(shù)

電裝新技術(shù)助力BEV電池循環(huán)再利用
Transformer是機(jī)器人技術(shù)的基礎(chǔ)嗎
Transformer模型的具體應(yīng)用

自動(dòng)駕駛中一直說的BEV+Transformer到底是個(gè)啥?

英偉達(dá)推出歸一化Transformer,革命性提升LLM訓(xùn)練速度
Transformer語(yǔ)言模型簡(jiǎn)介與實(shí)現(xiàn)過程
Transformer架構(gòu)在自然語(yǔ)言處理中的應(yīng)用
使用PyTorch搭建Transformer模型
Transformer 能代替圖神經(jīng)網(wǎng)絡(luò)嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論