") 如何使用MATLAB構(gòu)建Transformer模型
如何使用MATLAB構(gòu)建Transformer模型
Transformer 模型在 2017 年由 Vaswani 等人在論文《Attentionis All You Need》中首次提出。其設(shè)計(jì)初衷是為了解決自然語言處理(Nature LanguageProcessing, NLP)中的序列到序列任務(wù),如機(jī)器翻譯。Transformer 通過引入自注意力機(jī)制使得處理長距離依賴關(guān)系時(shí)變得高效。因此 Vaswani 等人的論文強(qiáng)調(diào)“注意力是所需的一切”。
傳感器數(shù)據(jù)表現(xiàn)為時(shí)間序列,并且序列內(nèi)部往往存在時(shí)間上的依賴關(guān)系,這些時(shí)間上的依賴能夠反映出設(shè)備的當(dāng)下或未來的狀態(tài),如何發(fā)現(xiàn)和挖掘序列內(nèi)部的知識和依賴關(guān)系,是以傳感器表征設(shè)備狀態(tài)的工業(yè)領(lǐng)域中故障診斷關(guān)注的重點(diǎn)。
本文中主要關(guān)注 Transformer 在傳感器數(shù)據(jù)中的應(yīng)用,通過其編碼器功能捕獲序列內(nèi)部依賴關(guān)系,尤其是長距離的依賴關(guān)系,并生成輸出數(shù)據(jù)做進(jìn)一步處理。后續(xù)的內(nèi)容將對圖 1 中的編碼器的功能及其在 MATLAB 中的實(shí)現(xiàn)做進(jìn)一步介紹,最后通過一個(gè)案例演示在 MATLAB 如如何設(shè)計(jì)和構(gòu)建 Transformer 的編碼器網(wǎng)絡(luò),并在信號數(shù)據(jù)集中進(jìn)行訓(xùn)練,同時(shí)也展示了經(jīng)過初步訓(xùn)練后的模型在測試集上的良好測試結(jié)果。由于篇幅所限,文章中不能展示全部過程的 MATLAB 代碼,如果讀者想要測試運(yùn)行代碼,可以掃碼后通過提供的鏈接進(jìn)行下載。
1. Transformer 模型
Transformer 模型的核心是自注意力機(jī)制(Self-Attention Mechanism)及完全基于注意力的編碼器-解碼器架構(gòu)。圖1顯示了在論文《Attention is All You Need》中提出的 Transformer 架構(gòu),其主要由編碼器(Encoder,圖 1 中左側(cè)部分)和解碼器(Decoder,圖1中的右側(cè)部分)兩個(gè)部分組成,編碼器的輸出序列將編碼器和解碼器關(guān)聯(lián)起來,構(gòu)建跨序列的注意力機(jī)制。
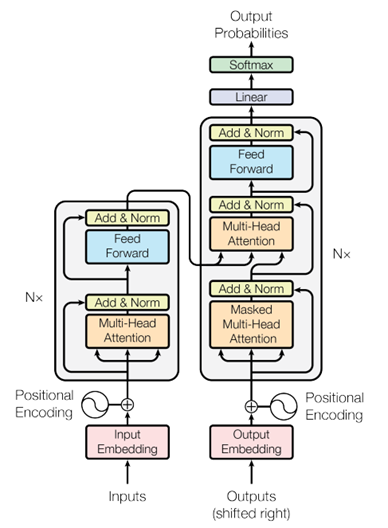
圖 1 Transformer 架構(gòu)
Transformer 編碼器(Encoder)專門用于處理輸入序列,通過引入自注意力機(jī)制,使其能夠高效地捕捉序列中的長距離依賴關(guān)系。而這種依賴關(guān)系體現(xiàn)為輸入序列不同位置之間的相關(guān)性。并且將相關(guān)性信息加入到輸出序列中,使得輸出數(shù)據(jù)包含豐富的上下文信息。
Transformer 解碼器(Decoder)主要負(fù)責(zé)逐步生成輸出結(jié)果。解碼器根據(jù)編碼器生成的上下文信息和前一步生成的輸出,逐步輸出目標(biāo)序列的每一個(gè)元素。在解碼器中,采用了帶有掩碼的自注意力機(jī)制,使得在計(jì)算輸出向量時(shí)只考慮當(dāng)前和之前的輸入數(shù)據(jù),以保持生成結(jié)果的順序性。同時(shí),解碼也采用了交叉注意力機(jī)制,將編碼器的輸出結(jié)果引入到解碼器中。通過交叉注意力機(jī)制,計(jì)算與編碼器的輸出序列的相關(guān)性。這一機(jī)制保證解碼器在生成每個(gè)輸出向量(輸出詞)時(shí),不僅要考慮之前輸出的詞,還要考慮編碼器生成的上下文信息。
本文主要關(guān)注 Transformer 在時(shí)間序列(信號)上的應(yīng)用,主要利用 Transformer 編碼器發(fā)現(xiàn)序列內(nèi)部在時(shí)間上的依賴關(guān)系。接下來將重點(diǎn)介紹 Transformer 編碼器及其在 MATLAB 中的實(shí)現(xiàn),并利用 Transformer 編碼器構(gòu)建分類模型 。
2.Transformer編碼器及其在MATLAB中的實(shí)現(xiàn)
Transformer 編碼器的主要由輸入、位置編碼(input embedding)、多頭注意力(multi-head attention)、殘差(Add)、標(biāo)準(zhǔn)化(Norm),以及前饋網(wǎng)絡(luò)(Feed Forward)組成。對于每一個(gè)組成部分,在MATLAB中都對應(yīng)的網(wǎng)絡(luò)層。
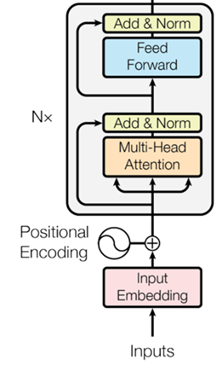
圖 2Transformer 編碼器
輸入序列
Transformer 的提出是針對序列到序列的自然語言處理任務(wù)。自然語言文本首先被轉(zhuǎn)換為固定長度的向量表示,進(jìn)而形成輸入向量序列。我們以自然語言文本“Do you speak MATLAB”為例,MATLAB 中的文本分析工具箱提供FastText預(yù)訓(xùn)練詞嵌入模型,可以將英文單詞轉(zhuǎn)換為 300 維的詞向量。例如對于“Do”,通過以下操作可以轉(zhuǎn)為300維的詞向量 vec (如下所示):

基于 FastText 生成詞向量
其中,fastTextWordEmbedding是FastText預(yù)訓(xùn)練詞嵌入模型,word2vec將詞轉(zhuǎn)換為向量表示。進(jìn)而,輸入的自然語言文本被轉(zhuǎn)換為詞向量序列,如圖 3 所示

圖 3 自然語言文本轉(zhuǎn)換為詞向量序列
位置編碼(input embedding)
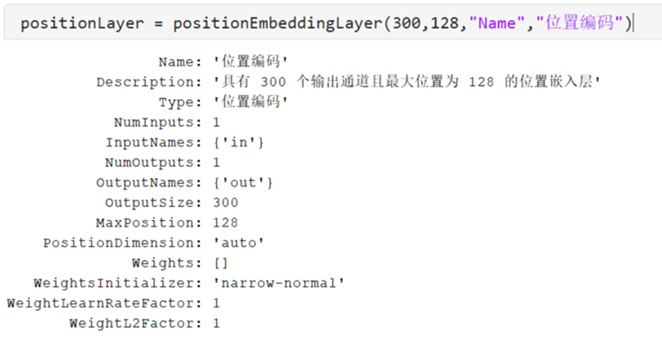
Transformer 不具備內(nèi)置的序列順序信息,需要通過位置編碼將序列位置信息注入到輸入數(shù)據(jù)中。在 MATLAB 中,通過使用positionEmbeddingLayer層,將序列順序信息注入到輸入數(shù)據(jù)中,如下所示。positionEmbeddingLayer的OutputSize的屬性設(shè)置為詞向量維度。
自注意力機(jī)制
Transformer 模型的核心是自注意力機(jī)制。對于輸入序列中每個(gè)位置對應(yīng)的向量。自注意力機(jī)制首先通過線性變換生成三個(gè)向量:查詢(Query),鍵(Key),和值(Value)。然后,通過計(jì)算查詢和鍵之間的點(diǎn)積來獲得注意力得分(即相關(guān)性),這些得分經(jīng)過 Softmax 歸一化后,用于加權(quán)求和值向量,即生成輸出向量。
以圖3中的輸入序列為例,假設(shè)自然語言文本對應(yīng)的詞向量按順序分別定義為d, y, s, m。并且定義 Query,Key,Value 的轉(zhuǎn)換矩陣為wq, wk, wv。對于詞“you”對應(yīng)的詞向量y,通過線性變換生成的 Query,Key,Value 向量為:
yq = wq × y;
yk = wk × y;
yv = wv × y;
同理,對于詞“Do”對應(yīng)的詞向量d,通過線性變換生成的 Query,Key,Value 向量為:
dq = wq × d;
dk = wk × d;
dv = wv × d;
其它兩個(gè)詞向量以此類推。
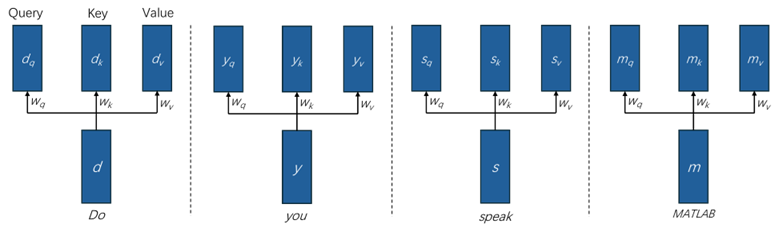
圖 4 詞向量的線性變換
對于詞“Do”,計(jì)算其與其它四個(gè)詞的相關(guān)性,分別為:·
rdd =dq· dk
rdy =dq· yk
rds = dq · sk
rdm =dq· mk
其中,rdd,rdy,rds,rdm,分別表示“Do”與自身、“you”、“speak”、“MATLAB”的相關(guān)性。利用 softmax 對相關(guān)性做歸一化處理,并生成歸一化后的相關(guān)性srdd,srdy,srds,srdm,將其它詞對當(dāng)前詞的影響納入的新生成的向量do 中,即:
do=srdd× dv+ srdy× yv + srds× sv+ srdm× mv
使用同樣的計(jì)算,可以得到輸出向量:do,yo,so,mo(如圖5所示)。
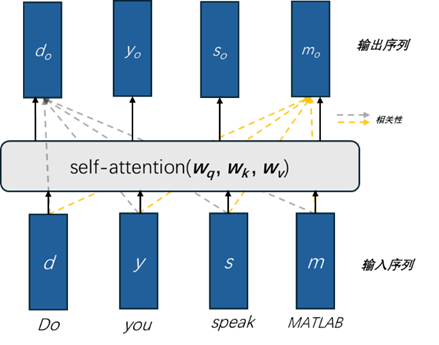
圖 5 輸入的序列經(jīng)過自注意力計(jì)算后生成新的輸出序列
通過以上介紹,self-attention 機(jī)制可以總結(jié)出:
通過三個(gè)線性變換(也是要學(xué)習(xí)的參數(shù),當(dāng)然還包含偏差)對輸入序列的每個(gè)位置的向量衍生出三個(gè)向量,經(jīng)過相關(guān)性計(jì)算以及加權(quán)平均,又轉(zhuǎn)換為一個(gè)輸出向量。但是輸出向量不僅包含自身的信息,還同時(shí)包含了與輸入序列其它位置的依賴關(guān)系(即其它位置向量的相關(guān)性),因此其信息內(nèi)容更加豐富。
每個(gè)輸入序列位置上的計(jì)算過程都是獨(dú)立進(jìn)行,并沒有前后依賴關(guān)系(類似 LSTM),因此可以通過并行計(jì)算進(jìn)行加速
通過獨(dú)立計(jì)算不同位置間的相關(guān)性來捕獲輸入序列內(nèi)部的依賴信息,因此其處理長距離的依賴關(guān)系更有效,可以避免 LSTM 的長距離依賴關(guān)系通過串行傳遞導(dǎo)致的信息不斷衰減問題。
在 MATLAB 中,selfAttentionLayer層實(shí)現(xiàn)了自注意力機(jī)制。NumKeyChannels屬性決定轉(zhuǎn)換后的 Key 向量的維度。因?yàn)?Query 要與 Key 做內(nèi)積,所以 Query 向量的維度與 Key 的維度相同。對于 Value 向量的維度,也可以通過屬性NumValueChannels進(jìn)行設(shè)置。如果NumValueChannels設(shè)置為“auto”,那么其與 key 向量的維度一致 (如下所示)。

自注意力機(jī)制中,線性變換矩陣就是要學(xué)習(xí)的參數(shù)(當(dāng)然也包含偏差)。而參數(shù)規(guī)模通過設(shè)置生成的 Query、Key 和 Value 向量的維度自動決定。例如,當(dāng)詞向量 d 的維度是 300,如果設(shè)置 Key 向量 k 的維度設(shè)置為 512,那么變換矩陣wk(Key Weights)大小為:512×300,即:

自注意力中的 Key 向量生成過程
帶有掩碼的自注意力機(jī)制(Masked Self-Attention)
Masked Self-Attention 主要用于處理序列數(shù)據(jù)中的有序性,使用掩碼來限制注意力的范圍。具體來說,掩碼會遮擋掉未來時(shí)間步的信息,確保模型在生成當(dāng)前位置的輸出向量時(shí),只能訪問當(dāng)前位置及之前位置的詞向量,以保持生成過程的順序性。在 MATLAB 中,通過設(shè)置selfAttentionLayer層的屬性AttentionMask值為“causal”實(shí)現(xiàn)帶掩碼的自注意力機(jī)制。
多頭自注意力機(jī)制
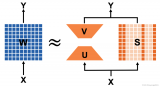
多頭自注意力通過并行地執(zhí)行多個(gè)自注意力計(jì)算(也就是單頭自注意力計(jì)算),然后將結(jié)果拼接起來。這種方法允許模型在不同的“注意力空間”中捕捉不同類型的信息。這里的“注意力空間”可以用一組 Query、key、Value 向量的線性變換表示。每個(gè)“頭”使用不同的線性變換對輸入序列生成 Query、key、Value,再計(jì)算注意力,并生成不同的輸出向量。將所有頭的輸出向量拼接(concatenate)在一起。拼接后的結(jié)果可以選擇(也可以不選擇)通過另一個(gè)線性變換整合來自所有頭的信息,生成最終的多頭自注意力輸出向量(如圖6所示)。
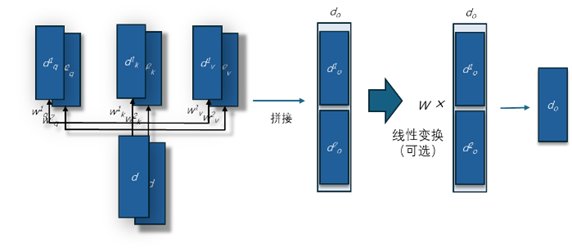
圖 6 多頭(2頭,two-head)自注意力機(jī)制
在 MATLAB 中,通過設(shè)置selfAttentionLayer層的屬性NumHeads來決定多頭自注意力機(jī)制的頭數(shù)(heads)。
在 Transformer 中,除了自注意力機(jī)制外的前饋網(wǎng)絡(luò)、殘差鏈接、以及層歸一化,都屬于常規(guī)網(wǎng)絡(luò)層,分別對應(yīng) MATLAB 中fullyConnectedLayer、additionLayer和layerNormalizationLayer,這些都是常規(guī)操作,這里就不做介紹。 ▼
3.Transformer編碼器在基于信號數(shù)據(jù)的故障診斷中的應(yīng)用
設(shè)備故障診斷是涉及通過各種傳感器數(shù)據(jù)檢測和識別設(shè)備故障。傳感器數(shù)據(jù)內(nèi)部蘊(yùn)含了時(shí)間上的依賴關(guān)系,這種依賴關(guān)系表現(xiàn)了設(shè)備的動態(tài)變化過程,因此,捕獲傳感器數(shù)據(jù)蘊(yùn)含的動態(tài)變化過程,可以很好的識別和預(yù)測設(shè)備的故障狀態(tài)。
本文的故障診斷案例是針對使用軸承的旋轉(zhuǎn)機(jī)械。這些機(jī)械系統(tǒng)常常因電流通過軸承放電而導(dǎo)致電機(jī)軸承在系統(tǒng)啟動后的幾個(gè)月內(nèi)發(fā)生故障。如果未能及時(shí)檢測這些問題,可能會導(dǎo)致系統(tǒng)運(yùn)行的重大問題。
數(shù)據(jù)集
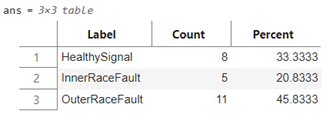
數(shù)據(jù)集包含從軸承測試臺和真實(shí)生產(chǎn)中的旋轉(zhuǎn)機(jī)械收集的振動數(shù)據(jù)。總共有 34 組數(shù)據(jù)。信號采樣頻率為 25 Hz。設(shè)備狀態(tài)包含三種:健康(healthy),內(nèi)圈故障(inner race fault),外圈故障(outer race fault)。
由于軸承電流是由變速條件引起的,故障頻率會隨著速度變化而在頻率范圍內(nèi)上下波動。因此,軸承振動信號本質(zhì)上是非平穩(wěn)的。時(shí)頻表示可以很好地捕捉這種非平穩(wěn)特性。從信號的時(shí)間、頻率和時(shí)頻表示中提取的組合特征可用于提高系統(tǒng)的故障檢測性能。圖7顯示了信號在時(shí)域和時(shí)頻域上的顯示。
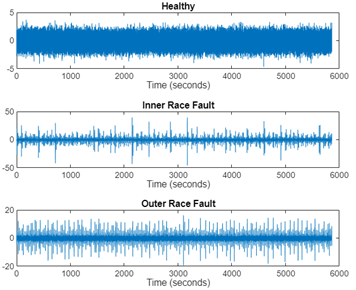
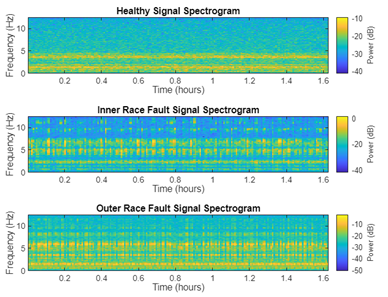
圖 7 輸入數(shù)據(jù)(信號)在時(shí)域(上)和時(shí)頻域(下)上的顯示
對于信號數(shù)據(jù),MATLAB 提供了特征提取函數(shù),可以分別從時(shí)域、頻域和時(shí)頻域上提取特征:
時(shí)域 - signalTimeFeatureExtractor
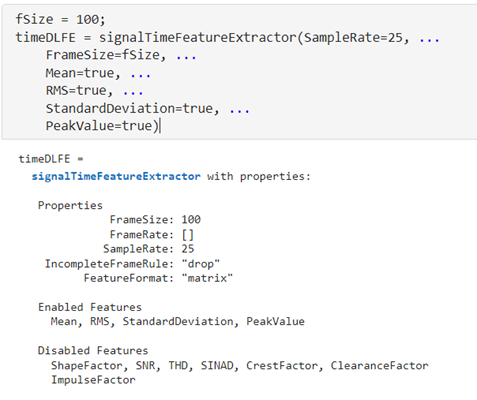
signalTimeFeatureExtractor 可以提取時(shí)域上的統(tǒng)計(jì)特征,如期望(mean)、均方根(RMS)、標(biāo)準(zhǔn)差(StandardDeviation)、及峰值(PeakValue)。而時(shí)域上的其它特征,如ShapeFactor、SNR等在本文案例中并沒有提取。signalTimeFeatureExtractor 在做信號特征提取的時(shí)候需要設(shè)置一個(gè)窗口(FrameSize),窗口大小決定了計(jì)算統(tǒng)計(jì)特征的采樣點(diǎn)數(shù)量。
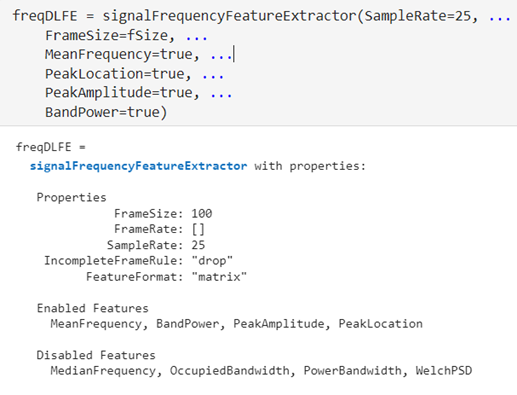
頻域 – signalFrequencyFeatureExtractor
signalFrequencyFeatureExtractor 用于在頻域上提取信號的統(tǒng)計(jì)特征,在本文中,主要提取頻率期望(MeanFrequency)、頻譜峰值位置(PeakLocation)、頻譜峰值(PeakAmplitude)、及平均頻帶功率(BandPower)。頻域上的其它特征,如OccupiedBandwidth等在本文中并沒有提取。signalFrequencyFeatureExtractor 在做信號特征提取時(shí),同樣需要設(shè)置一個(gè)窗口(FrameSize),用于指定每個(gè)幀的采樣點(diǎn)數(shù),也是頻域特征提取時(shí)分析窗口的大小。當(dāng)處理長時(shí)間信號時(shí),將信號分成較小的幀可以更有效地進(jìn)行頻域分析。
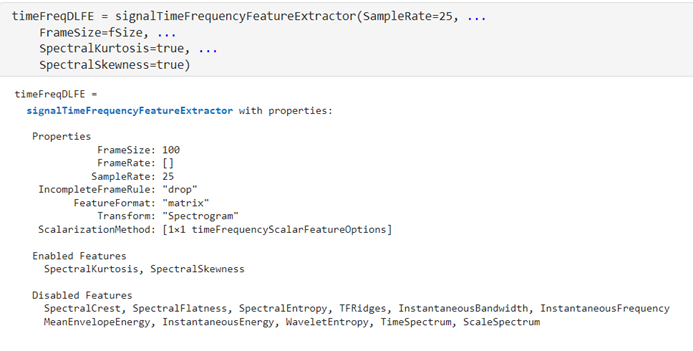
時(shí)頻域 – signalTimeFrequencyFeatureExtractor
signalTimeFrequencyFeatureExtractor 用于在時(shí)頻域上提取信號的特征,捕捉到信號在時(shí)間和頻率上的變化。在本文中,時(shí)頻上提取頻譜峭度(SpectralKurtosis)和頻譜偏度(SpectralSkewness)。在時(shí)頻域分析中,譜峭度值描述了信號在特定時(shí)間點(diǎn)上的頻譜形狀的尖銳程度或平坦程度,通過頻譜峭度分析,可以識別信號中的瞬態(tài)事件或沖擊。譜偏度值描述了信號在特定時(shí)間點(diǎn)上頻譜的對稱性或偏斜程度,通過分析頻譜偏度,可以識別信號中非對稱的頻率分布。
原始信號經(jīng)過分幀并做特征提取,從具有 146484 采樣點(diǎn)一維數(shù)據(jù),轉(zhuǎn)換為 1464×30 的二維矩陣,如圖 8 所示。矩陣的行表示時(shí)間點(diǎn),矩陣的列表示特征。
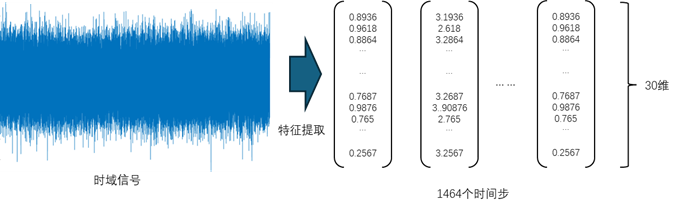
圖 8 經(jīng)過特征提取的信號數(shù)據(jù)
對于轉(zhuǎn)換后的數(shù)據(jù),每個(gè)特征可以抽象成一個(gè)傳感器,每個(gè)采樣點(diǎn)同時(shí)從 30 個(gè)傳感器采集數(shù)據(jù)而組成一個(gè)特征向量。一個(gè)樣本共進(jìn)行1464次采樣。這樣就為接下來的 Transformer 編碼器模型訓(xùn)練準(zhǔn)備好了數(shù)據(jù)基礎(chǔ)
基于Transformer編碼器構(gòu)建分類模型
本文是對照《Attentionis all you need》論文中的 Transformer 編碼器,通過Deep Network Designer App構(gòu)建編碼器網(wǎng)絡(luò),如圖9所示。Transformer 編碼器的每個(gè)組成部分,在MATLAB中都有對應(yīng)的網(wǎng)絡(luò)層,通過這些層可以快速的組建網(wǎng)絡(luò),并自定義每層的參數(shù)。例如本文中,selfAttentionLayer層的頭數(shù)是 2,并帶有掩碼。
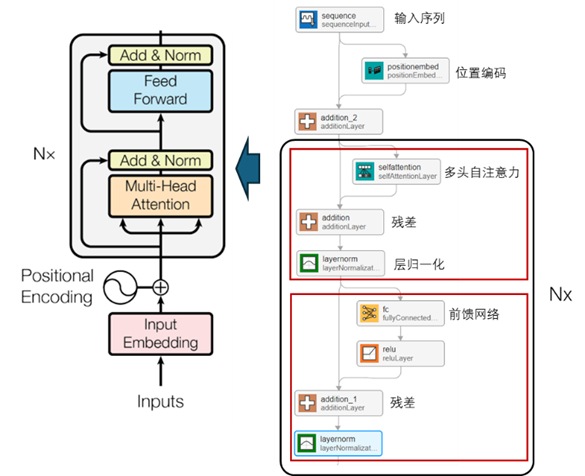
圖 9 基于Transformer的編碼器構(gòu)建故障診斷模型(分類模型)
編碼器的輸出是帶有上下文信息的向量序列,而在設(shè)備的故障診斷中,故障的類型是離散的。本文中,軸承有內(nèi)圈故障、外圈故障、以及健康狀態(tài)三種類型。因此,還需要利用編碼器的輸出向量,進(jìn)一步來構(gòu)建三分類模型。
對于 Transformer 編碼器的輸出向量序列,MATLAB 提供globalAveragePooling1dLayer和globalMaxPooling1dLayer兩種全局池化方法,在序列(或時(shí)間)方向上做向量每個(gè)維度上的數(shù)據(jù)合并。在本文中,編碼器的輸出序列向量的維度是 30,序列長度(時(shí)間步)是 1464,即 1464×30。經(jīng)過數(shù)據(jù)合并后,變?yōu)椋?×30,如圖 10 所示。
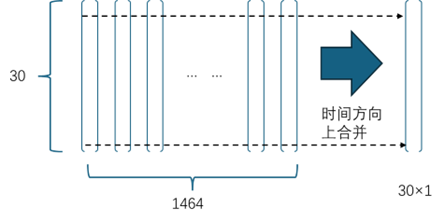
圖 10 向量序列在時(shí)間方向的合并
序列數(shù)據(jù)做全局池化后的輸出結(jié)果是一維數(shù)據(jù),通過連接全連接網(wǎng)絡(luò)層fullyConnectedLayer,進(jìn)一步縮減為三輸出,即對應(yīng)于三分類。最后再通過softmaxLayer轉(zhuǎn)換為概率分布,進(jìn)而判斷所屬類別。整體網(wǎng)絡(luò)模型如圖11所示。
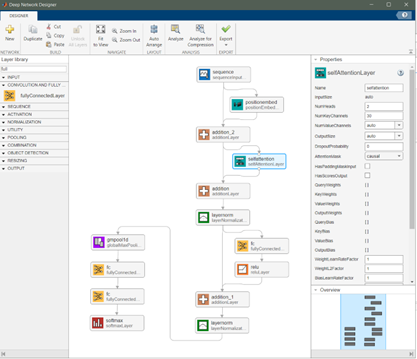
圖11 基于 Transformer 的編碼器構(gòu)建分類模型
模型訓(xùn)練與測試
本文共收集34條信號數(shù)據(jù),采用隨機(jī)的方式按照 70% 和 30% 進(jìn)一步將數(shù)據(jù)集劃分為訓(xùn)練集和測試集(由于數(shù)據(jù)量有限,訓(xùn)練過程并沒有使用驗(yàn)證集)。
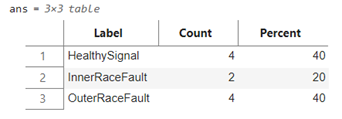
訓(xùn)練集(上)和測試集(下)
模型訓(xùn)練過程,MATLAB 提供了超參數(shù)選項(xiàng)實(shí)現(xiàn)模型的進(jìn)一步調(diào)優(yōu),而超參數(shù)選項(xiàng)是通過 trainingOptions 函數(shù)設(shè)置的,包括初始學(xué)習(xí)速率、學(xué)習(xí)速率衰減策略、minibatch 大小、訓(xùn)練執(zhí)行環(huán)境(GPU、CPU)、訓(xùn)練周期等等。經(jīng)過 100 個(gè) Epoch 訓(xùn)練的模型在測試集上的測試結(jié)果如下:
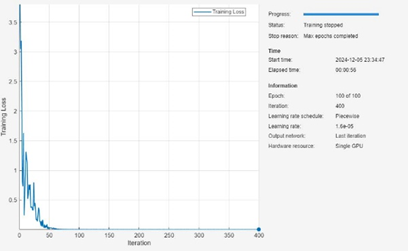
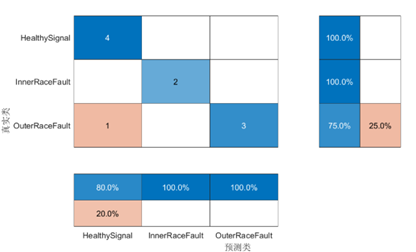
圖 12 模型訓(xùn)練過程(上)和測試集精度(heatmap)(下)
從測試的結(jié)果看,Transforme 編碼器對長距離依賴關(guān)系的捕獲效果還是比較好的。
4.總結(jié)
本文的目的主要是介紹 Transformer 模型的編碼器,以及如何使用 MATLAB 構(gòu)建 Transformer 模型,并為讀者提供一種 Transformer 編碼器的應(yīng)用思路,模型本身以及訓(xùn)練過程還有可以優(yōu)化地方,僅為讀者提供參考,也歡迎大家做進(jìn)一步模型結(jié)構(gòu)調(diào)整和精度提升。
-
matlab
+關(guān)注
關(guān)注
188文章
2995瀏覽量
233187 -
編碼器
+關(guān)注
關(guān)注
45文章
3772瀏覽量
137083 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49962 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122461 -
Transformer
+關(guān)注
關(guān)注
0文章
148瀏覽量
6385
原文標(biāo)題:傳感器數(shù)據(jù)的深度學(xué)習(xí)模型應(yīng)用(一)—— Transformer 模型
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大語言模型背后的Transformer,與CNN和RNN有何不同

【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
你了解在單GPU上就可以運(yùn)行的Transformer模型嗎
如何使用Matlab/Simulink構(gòu)建MIMXRT1170 EVK?
TensorFlow2.0中創(chuàng)建了一個(gè)Transformer模型包,可用于重新構(gòu)建GPT-2、 BERT和XLNet

Microsoft使用NVIDIA Triton加速AI Transformer模型應(yīng)用
基于Transformer的大型語言模型(LLM)的內(nèi)部機(jī)制

transformer模型詳解:Transformer 模型的壓縮方法
基于Transformer模型的壓縮方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論