") Transformer模型能夠做什么
Transformer模型能夠做什么
如果想在 AI 領(lǐng)域引領(lǐng)一輪新浪潮,就需要使用到 Transformer。
盡管名為 Transformer,但它們不是電視銀幕上的變形金剛,也不是電線桿上垃圾桶大小的變壓器。
在人工智能的快速發(fā)展中,Transformer 模型作為一種神經(jīng)網(wǎng)絡(luò),以其獨(dú)特的自注意力機(jī)制,引領(lǐng)了自然語言處理的新浪潮,以革命性的方式推動了整個行業(yè)的進(jìn)步。本文將帶您深入了解 Transformer 模型的起源,探討其如何通過自注意力機(jī)制捕捉數(shù)據(jù)元素間的微妙聯(lián)系,并理解其在 AI 領(lǐng)域中的關(guān)鍵作用。
什么是 Transformer 模型?
Transformer 模型是一種神經(jīng)網(wǎng)絡(luò),通過追蹤連續(xù)數(shù)據(jù)(例如句子中的單詞)中的關(guān)系了解上下文,進(jìn)而理解其含義。
Transformer 模型使用一套不斷發(fā)展的數(shù)學(xué)方法(這套方法被稱為注意力或自注意力),檢測一系列數(shù)據(jù)元素之間的微妙影響和依賴關(guān)系,包括距離遙遠(yuǎn)的數(shù)據(jù)元素。
谷歌在 2017 年的一篇論文中首次描述了 Transformer,定義它為一種迄今為止所發(fā)明的最新、最強(qiáng)大的模型。這種模型正在推動機(jī)器學(xué)習(xí)領(lǐng)域的進(jìn)步,一些人將其稱為 Transformer AI。
斯坦福大學(xué)的研究人員在 2021 年 8 月的一篇論文中將 Transformrer 稱為“基礎(chǔ)模型”,他們認(rèn)為其推動了 AI 的范式轉(zhuǎn)變。他們在論文中寫道:“在過去幾年中,基礎(chǔ)模型的規(guī)模之大、范圍之廣,超出了我們的想象。”
Transformer 模型能夠做什么?
Transformer 可以近乎實(shí)時地翻譯文本和語音,為不同人群包括聽障人士提供會議和課堂服務(wù)。
它們還能幫助研究人員了解 DNA 中的基因鏈和蛋白質(zhì)中的氨基酸,從而加快藥物設(shè)計(jì)的速度。
Transformer 有時也被稱為基礎(chǔ)模型,目前已經(jīng)連同許多數(shù)據(jù)源用于大量應(yīng)用中
Transformer 可通過檢測趨勢和異常現(xiàn)象,為防止欺詐、簡化制造流程、提供在線建議或改善醫(yī)療服務(wù)提供助力。
每當(dāng)人們在谷歌或微軟必應(yīng)上進(jìn)行搜索時,就會用到 Transformer。
Transformer AI 的良性循環(huán)
Transformer 模型適用于一切使用連續(xù)文本、圖像或視頻數(shù)據(jù)的應(yīng)用。
這使這些模型可以形成一個良性的 Transformer AI 良性循環(huán):使用大型數(shù)據(jù)集創(chuàng)建而成的 Transformer 能夠做出準(zhǔn)確的預(yù)測,從而被越來越廣泛地應(yīng)用,因此產(chǎn)生的數(shù)據(jù)也越來越多,這些數(shù)據(jù)又被用于創(chuàng)建更好的模型。
斯坦福大學(xué)的研究人員表示,Transformer 標(biāo)志著 AI 發(fā)展的下一個階段,有人將這個階段稱為 Transformer AI 時代
NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛在 GTC 2022 上發(fā)表的主題演講中表示:“Transformer 讓自監(jiān)督學(xué)習(xí)成為可能,AI 迎來了了飛速發(fā)展的階段。”
Transformer 取代 CNN 和 RNN
Transformer 正在許多場景中取代卷積神經(jīng)網(wǎng)絡(luò)和遞歸神經(jīng)網(wǎng)絡(luò)(CNN 和 RNN),而這兩種模型在七年前還是最流行的深度學(xué)習(xí)模型。
事實(shí)上,在過去幾年發(fā)表的關(guān)于 AI 的 arXiv 論文中,有 70% 都提到了 Transformer。這與 2017 年 IEEE 的研究報(bào)告將 RNN 和 CNN 稱為最流行的模式識別模型時相比,變化可以說是翻天覆地。
無標(biāo)記且性能更強(qiáng)大
在 Transformer 出現(xiàn)之前,用戶不得不使用大量帶標(biāo)記的數(shù)據(jù)集訓(xùn)練神經(jīng)網(wǎng)絡(luò),而制作這些數(shù)據(jù)集既費(fèi)錢又耗時。Transformer 通過數(shù)學(xué)方法發(fā)現(xiàn)元素之間的模式,因此實(shí)現(xiàn)了不需要進(jìn)行標(biāo)記,這讓網(wǎng)絡(luò)和企業(yè)數(shù)據(jù)庫中的數(shù)萬億張圖像和數(shù) PB 文本數(shù)據(jù)有了用武之地。
此外,Transformer 使用的數(shù)學(xué)方法支持并行處理,因此這些模型得以快速運(yùn)行。
Transformer 目前在流行的性能排行榜上獨(dú)占鰲頭,比如 2019 年為語言處理系統(tǒng)開發(fā)的基準(zhǔn)測試 SuperGLUE。
Transformer 的注意力機(jī)制
與大多數(shù)神經(jīng)網(wǎng)絡(luò)一樣,Transformer 模型本質(zhì)上是處理數(shù)據(jù)的大型編碼器/解碼器模塊。
其能夠獨(dú)占鰲頭的原因是在這些模塊的基礎(chǔ)上,添加了其他微小但具有戰(zhàn)略意義的模塊(如下圖所示)。
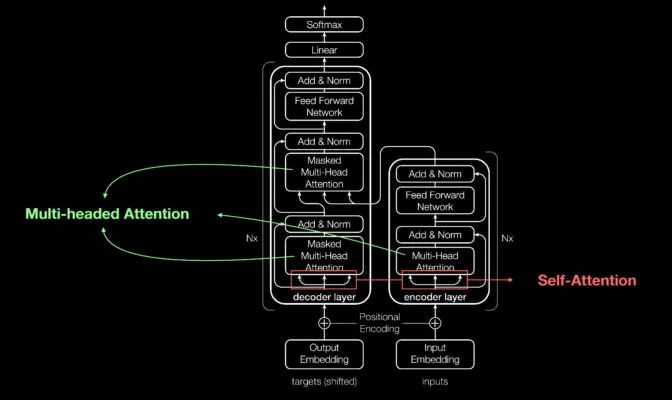
Aidan Gomez(2017 年定義 Transformer 的論文的 8 位共同作者之一)展示內(nèi)容的概覽圖
Transformer 使用位置編碼器標(biāo)記進(jìn)出網(wǎng)絡(luò)的數(shù)據(jù)元素。注意力單元跟蹤這些標(biāo)簽,計(jì)算每個元素與其他元素間關(guān)系的代數(shù)圖。
注意力查詢通常通過計(jì)算被稱為多頭注意力中的方程矩陣并行執(zhí)行。
通過這些工具,計(jì)算機(jī)也能看到人類所看到的模式。
自注意力機(jī)制能夠明確意義
例如在下面的句子中:
她把壺里的水倒到杯子里,直到它被倒?jié)M。
我們知道這里的“它”指的是杯子,而在下面的句子中:
她壺里的水倒到杯子里,直到它被倒空。
我們知道這里的“它”指的是壺。
領(lǐng)導(dǎo) 2017 年這篇開創(chuàng)性論文研究工作的前 Google Brain 高級研究科學(xué)家 Ashish Vaswani 表示:“意義是事物之間的關(guān)系所產(chǎn)生的結(jié)果,而自注意力是一種學(xué)習(xí)關(guān)系的通用方法。”
Vaswani 表示:“由于需要單詞之間的短距離和長距離關(guān)系,因此機(jī)器翻譯能夠很好地驗(yàn)證自注意力。”
“現(xiàn)在我們已經(jīng)看到,自注意力是一種強(qiáng)大、靈活的學(xué)習(xí)工具。”
Transformer 名稱的由來
注意力對于 Transformer 非常關(guān)鍵,谷歌的研究人員差點(diǎn)把這個詞作為他們 2017 年模型的名稱。
在 2011 年就開始研究神經(jīng)網(wǎng)絡(luò)的 Vaswani 表示:“注意力網(wǎng)絡(luò)這個名稱不夠響亮。”
該團(tuán)隊(duì)的高級軟件工程師 Jakob Uszkoreit 想出了“Transformer”這個名稱。
Vaswani 表示:“我當(dāng)時覺得我們是在轉(zhuǎn)換表征,但其實(shí)轉(zhuǎn)換的只是語義。”
Transformer 的誕生
在 2017 年 NeurIPS 大會上發(fā)表的論文中,谷歌團(tuán)隊(duì)介紹了他們的 Transformer 及其為機(jī)器翻譯創(chuàng)造的準(zhǔn)確率記錄。
憑借一系列技術(shù),他們僅用 3.5 天就在 8 顆 NVIDIA GPU 上訓(xùn)練出了自己的模型,所用時間和成本遠(yuǎn)低于訓(xùn)練之前的模型。這次訓(xùn)練使用的數(shù)據(jù)集包含多達(dá)十億對單詞。
2017 年參與這項(xiàng)工作并做出貢獻(xiàn)的谷歌實(shí)習(xí)生 Aidan Gomez 回憶道:“距離論文提交日期只有短短三個月的時間。提交論文的那天晚上,Ashish 和我在谷歌熬了一個通宵。我在一間小會議室里睡了幾個小時,醒來時正好趕上提交時間。一個來得早的人開門撞到了我的頭。”
這讓 Aidan 一下子清醒了。
“那天晚上,Ashish 告訴我,他相信這將是一件足以改變游戲規(guī)則的大事。但我不相信,我認(rèn)為這只是讓基準(zhǔn)測試進(jìn)步了一點(diǎn)。事實(shí)證明他說得非常對。”Gomez 現(xiàn)在是初創(chuàng)公司 Cohere 的首席執(zhí)行官,該公司提供基于 Transformer 的語言處理服務(wù)。
機(jī)器學(xué)習(xí)的重要時刻
Vaswani 回憶道,當(dāng)看到結(jié)果超過了 Facebook 團(tuán)隊(duì)使用 CNN 所得到的結(jié)果時,他感到非常興奮。
Vaswani 表示:“我覺得這可能成為機(jī)器學(xué)習(xí)的一個重要時刻。”
一年后,谷歌的另一個團(tuán)隊(duì)嘗試用 Transformer 處理正向和反向文本序列。這有助于捕捉單詞之間的更多關(guān)系,提高模型理解句子意義的能力。
他們基于 Transformer 的雙向編碼器表征(BERT)模型創(chuàng)造了 11 項(xiàng)新記錄,并被加入到谷歌搜索的后臺算法中。
“由于文本是公司最常見的數(shù)據(jù)類型之一”,在短短幾周內(nèi),全球的研究人員就將 BERT 應(yīng)用于多個語言和行業(yè)的用例中。Anders Arpteg,這位擁有 20 年機(jī)器學(xué)習(xí)研究經(jīng)驗(yàn)的專家表示,因?yàn)槲谋臼枪咀畛R姷臄?shù)據(jù)類型之一,所以這種調(diào)整變得尤為重要。
小結(jié)
Transformer 模型的誕生標(biāo)志著自然語言處理技術(shù)的一次重大飛躍。本文上篇為您揭示了這一模型的基本原理和發(fā)展歷程。隨著對 Transformer 模型的深入理解,我們可以看到其在機(jī)器翻譯、文本理解、基因序列分析等多個領(lǐng)域的廣泛應(yīng)用,預(yù)示著 AI 技術(shù)革新與發(fā)展的無限可能。
-
AI
+關(guān)注
關(guān)注
87文章
34274瀏覽量
275461 -
模型
+關(guān)注
關(guān)注
1文章
3488瀏覽量
50011 -
Transformer
+關(guān)注
關(guān)注
0文章
148瀏覽量
6398
原文標(biāo)題:什么是 Transformer 模型(一)
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何使用MATLAB構(gòu)建Transformer模型

transformer專用ASIC芯片Sohu說明

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
【「大模型啟示錄」閱讀體驗(yàn)】+開啟智能時代的新鑰匙
【「大模型啟示錄」閱讀體驗(yàn)】如何在客服領(lǐng)域應(yīng)用大模型
Transformer模型的具體應(yīng)用

自動駕駛中一直說的BEV+Transformer到底是個啥?

【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識學(xué)習(xí)
Transformer能代替圖神經(jīng)網(wǎng)絡(luò)嗎
Transformer語言模型簡介與實(shí)現(xiàn)過程
llm模型有哪些格式
llm模型和chatGPT的區(qū)別
Transformer模型在語音識別和語音生成中的應(yīng)用優(yōu)勢
使用PyTorch搭建Transformer模型
Transformer 能代替圖神經(jīng)網(wǎng)絡(luò)嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論