 ACL2021的跨視覺語言模態論文之跨視覺語言模態任務與方法
ACL2021的跨視覺語言模態論文之跨視覺語言模態任務與方法

來自:復旦DISC
引言
本次分享我們將介紹三篇來自ACL2021的跨視覺語言模態的論文。這三篇文章分別介紹了如何在圖像描述任務中生成契合用戶意圖的圖像描述、端對端的視覺語言預訓練模型和如何生成包含更多細節的圖像描述。
文章概覽
Control Image Captioning Spatially and Temporally
論文地址:https://aclanthology.org/2021.acl-long.157.pdf
該篇文章基于對比學習和注意力機制引導提出了LoopCAG模型。LoopCAG可以根據輸入的鼠標軌跡,生成與鼠標軌跡相匹配的圖像描述,從而增強了圖片描述生成的可控性和可解釋性。
E2E-VLP: End-to-End Vision-Language Pretraining Enhanced by Visual Learning
論文地址:https://arxiv.org/pdf/2106.01804.pdf
這篇文章提出了一個端到端的視覺語言預訓練模型。模型不需要利用預訓練的目標檢測器抽取基于區域的視覺特征,直接以圖片作為輸入。并且設計了兩個額外的視覺預訓練任務幫助模型學習細粒度的信息,達到了和兩階段模型相似的效果,并且提高了運算效率。
Enhancing Descriptive Image Captioning with Natural Language Inference
論文地址:https://aclanthology.org/2021.acl-short.36.pdf
這篇文章通過推理圖和PageRank對圖像描述進行描述性打分。再通過參考抽樣和加權指定獎勵來生成具有更多細節的圖像描述。模型生成了比一般方法具有更多細節的圖像描述,這些圖像描述可以包含基線方法生成的圖像描述。
論文細節
1
動機
圖像描述任務主要針對圖片上比較突出的物體和物體關系展開描述,這樣的圖片描述沒有考慮到用戶意圖。為了生成具備可控性和可解釋性的圖像描述,最近的工作提出了生成可控性的圖像描述任務。為了生成符合用戶意圖的圖像描述,通常會對描述加以情感、邊界框和鼠標軌跡限制。與此同時,近期提出的 Localized-Narratives 數據集將鼠標軌跡作為圖像描述任務的另一個輸入,為圖像描述生成任務中所涉及的語義概念進行空間和時序關系上的控制提供了可能。
模型
LoopCAG 可以總結為三部分:用于生成圖片描述且以 Transformer 為主干網絡的編碼器-解碼器;用于視覺對象空間定位的注意力引導(Attention Guidance)組件;用于句子級時序對齊的對比性約束(Contrastive Constraints)組件。
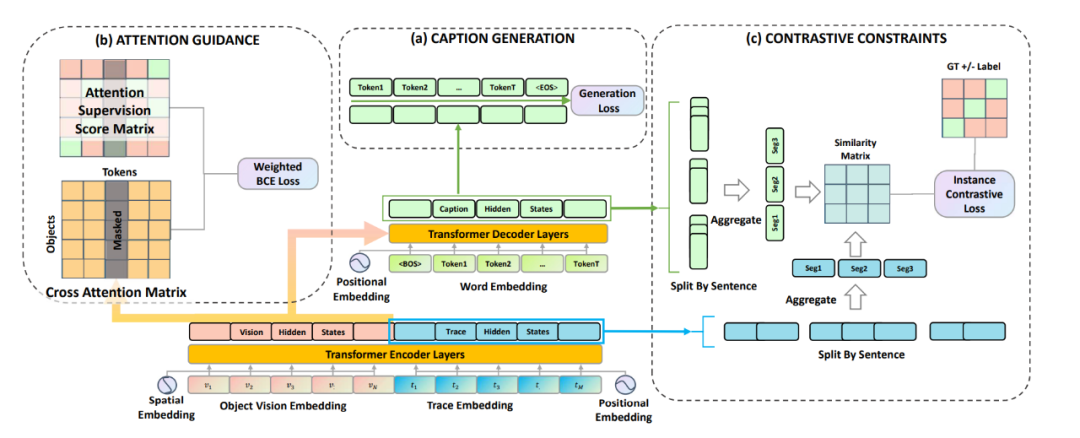
(1)Caption Generation
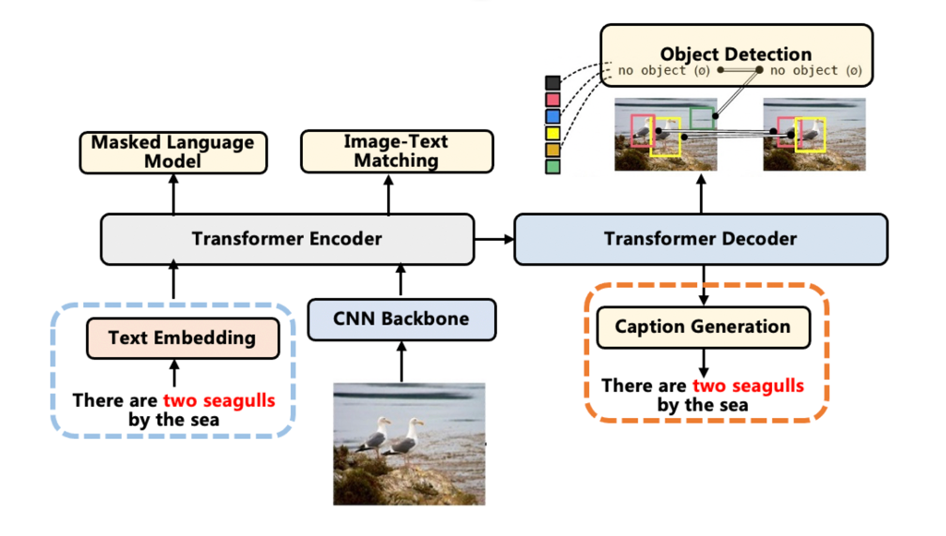
作者將視覺特征V和軌跡特征T分別編碼,并疊加位置信息后得 和 ,然后串聯在一起作為一個統一的序列輸入編碼器。解碼器通過交叉注意力模塊與編碼器最后一層的隱藏狀態相連,將視覺和軌跡信息結合起來作為生成的前置條件。解碼器的優化目標是將以下目標函數最小化:
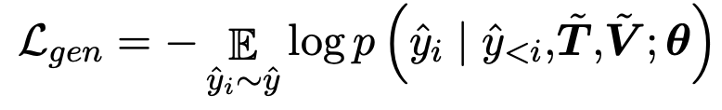
(2)Attention Guidance
為了定位物體,作者用軌跡作為中間橋梁聯系物體和語義token。作者構建了一個監督矩陣來引導詞語和視覺對象之間的注意力,即需要物體軌跡點盡可能多的落入對象邊界框中。當注意力監督矩陣和模型的交叉注意力矩陣盡可能接近時,詞語則可以準確的對應到圖片的空間視覺物體上。
(3)Contrastive Constraints
作者使用對比損失函數來約束生成過程的時間順序,對比損失的形式是 NCE 函數,用來學習區分軌跡-描述對之中的正例和負例。正例是指在順序上自然對應的描述句和軌跡段,而其余的軌跡-描述對組合均為負例。
最后作者通過將所有損失的總和最小化來聯合優化模型。
實驗
作者在Localized-Narratives COCO 這個數據集上進行了訓練和測試。在測試集上的結果如圖所示,LoopCAG 方法在所有的自動評測指標上都達到了先進水平。從表中可以看出,ROUGE-L 的得分提升了2.0。由于 ROUGE-L 主要采用了對順序敏感的最長共同子序列計分方式,這表明對比約束可以促進生成句子的順序和用戶意圖的對應。
2
動機
基于海量圖文對的多模態預訓練在下游的跨模態任務中已經取得巨大的成功。現有的多模態預訓練的方法主要基于兩階段訓練,首先利用預訓練的目標檢測器抽取基于區域的視覺特征,然后拼接視覺表示和文本向量作為Transformer的輸入進行訓練。這樣的模型存在兩點問題,一個是第一階段通常在特定數據集進行訓練模型泛化能力不好,此外提取區域的視覺特征比較耗費時間。基于此作者提出了端到端的像素級別的視覺語言預訓練模型。模型通過一個統一的Transformer框架同時學習圖像特征和多模態表示
模型
本文的模型如圖所示。E2E-VLP用一個CNN 模型提取圖片視覺特征的同時用一個Transformer進行多模態特征學習。
(1) Input Representations
模型首先用WordPiece tokenizer 分詞進行序列化。圖片則直接以三通道的像素矩陣輸入。
(2) Cross-modal Encoder Pre-training:Transformer
模型用Resnet提取圖片的特征向量。用Transformer模塊接受圖像-句子的序列輸入,進行跨模態語義學習。
為了提取跨模態語義信息,模型設計了兩個預訓練任務。一個是與Bert類似的Masked Language Modeling,只是在該任務中除去上下文信息還可以利用圖片信息避免語義混淆,第二個任務是進行圖片文本匹配。
(3) Visual-enhanced Decoder
為了提取更細粒度的視覺特征,接入了物體檢測和描述生成兩個任務。在物體檢測中,為了增強視覺語義特征的學習,除去常規的位置和物體種類預測,我們引入了屬性預測這一任務。描述生成圖片對應的描述。
實驗
根據實驗結果,E2E-VLP 和兩階段模型相比,也取得了比較好效果,可以理解和完成兩種任務。同時在參數量上,E2E-VLP 則具有更加輕量的優勢。
3
動機
現階段的圖像描述模型通常傾向于生成比較安全的較為籠統的描述,而忽略圖像細節。為了生成包含更多細節的圖像描述,作者基于更具有細節的圖像描述通常包含籠統描述的全部信息這一觀點提出了基于自然語言推斷的描述關系模型。
方法
這篇文章的具體方法如下:
(1)Constructing Inference Graphs
首先用基于Bert的自然語言推斷模型判斷圖像描述之間的關系,由于圖像描述之間不存在沖突因此挪去了沖突關系。并對一張圖的描述構建如圖所示的推斷關系圖,并利用Pagerank的方法對推斷圖計算描述性評分。
(2)Descriptiveness Regularized Learning
由于傳統圖像描述的第一階段生成描述和圖像描述最小化交叉熵損失函數等同于生成描述和均勻分布的圖像描述之間的KL Divergence,為了生成更具有描述性的圖像描述。則采用歸一化的描述性評分分布取代均勻分布,認為更具有描述性的圖像描述具有更高的生成概率。
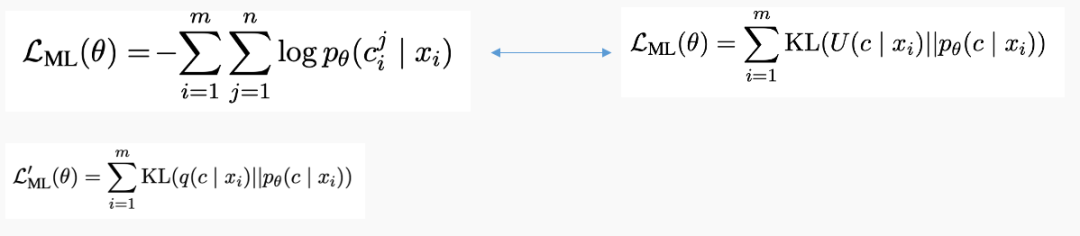
在第二階段,最大化生成圖像描述的期望收益時,也同時用描述性評分取代均勻分布來計算期望收益。

實驗
根據實驗結果,模型在多數指標特別是CIDER評分上超過了Baseline,這是因為CIDER傾向于具有更加特殊的細節描述。
此外根據自然語言推斷模型判斷文章模型生成的圖像描述對baseline的圖像描述形成更多的包含關系。
編輯:jq
-
解碼器
+關注
關注
9文章
1174瀏覽量
41957 -
編碼器
+關注
關注
45文章
3794瀏覽量
137993 -
圖像
+關注
關注
2文章
1094瀏覽量
41237 -
函數
+關注
關注
3文章
4379瀏覽量
64830 -
cnn
+關注
關注
3文章
354瀏覽量
22740
原文標題:ACL2021 | 跨視覺語言模態任務與方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
云知聲四篇論文入選自然語言處理頂會ACL 2025

基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型

移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

?VLM(視覺語言模型)?詳細解析

海康威視文搜存儲系列:跨模態檢索,安防新境界

AKI跨語言調用庫神助攻C/C++代碼遷移至HarmonyOS NEXT
NaVILA:加州大學與英偉達聯合發布新型視覺語言模型
一文理解多模態大語言模型——下

一文理解多模態大語言模型——上

基于視覺語言模型的導航框架VLMnav
思必馳發布AI辦公本Turbo,搭載專業級跨模態會議大模型
SegVG視覺定位方法的各個組件





 工商網監
工商網監
評論