 云知聲四篇論文入選自然語言處理頂會ACL 2025
云知聲四篇論文入選自然語言處理頂會ACL 2025
近日,第63屆國際計算語言學年會ACL 2025(Annual Meeting of the Association for Computational Linguistics,簡稱ACL)論文接收結果正式公布。云知聲在此次國際學術盛會中表現卓越,共有4篇論文被接收,其中包括2篇主會論文(Main Paper)和2篇Findings。入選的4篇論文聚焦大語言模型知識溯源、圖文音多模態大模型、大語言模型可解釋性等關鍵領域,提出的創新理論和方法,為行業研究提供了新的思路。
ACL是自然語言處理領域最具影響力的國際會議之一,也是中國計算機學會(CCF)推薦的A類國際學術會議。該會議每年舉辦一次,由國際計算語言學學會協會主辦。本屆會議將于2025年7月27日至8月1日在奧地利維也納舉行。據統計,今年ACL總投稿數高達8000多篇,創歷史之最,被稱為ACL論文收錄競爭最為激烈的一年。
云知聲自2012年成立以來,在自然語言處理領域持續深耕,成果斐然。2017年Transformer及2018年BERT等深度學習模型的發布,推動了AI自然語言處理的重大突破。憑借自身在交互式AI方面的強大研發實力,云知聲迅速推出首個基于BERT的大語言模型UniCore,作為云知大腦的初始核心算法模型,為后續一系列AI解決方案在廣泛垂直行業的落地應用奠定了堅實基礎。2023年,在自建的Atlas智算平臺和多年積累的海量數據支持下,云知聲推出了擁有千億參數的大語言模型——山海大模型,并持續對其進行迭代升級。山海大模型不僅具備語言生成、知識問答、邏輯推理等十大核心能力,還在多模態技術方面不斷實現突破,持續拓展文生圖、音圖問答等前沿功能,極大地豐富了用戶交互體驗。
在技術攻堅過程中,云知聲收獲了多項與自然語言處理相關的專利。例如,多語言摘要的生成方法、知識增強的非自回歸神經機器翻譯方法等,為多場景應用提供了有力支撐。在學術研究與行業認可方面,云知聲持續輸出優質成果,曾在CVPR 2024、INTERSPEECH 2023、ACM MM 2023等頂會發表多篇學術著作,并斬獲CVPR2024開放環境情感行為分析競賽三項季軍。此次再度登上國際學術舞臺,充分印證了云知聲在AI領域的技術創新實力,也將進一步夯實其AGI技術底座。
以下為入選論文概覽:
1 研究方向:大語言模型知識溯源標題:TROVE: A Challenge for Fine-Grained Text Provenance via Source Sentence Tracing and Relationship Classification作者:Junnan Zhu, Min Xiao, Yining Wang, Feifei Zhai, Yu Zhou,Chengqing Zong
論文簡介:大語言模型在文本生成中的流利性和連貫性方面已取得了顯著的進展,然而其廣泛應用引發了對內容可靠性和責任心的擔憂。在醫療、法律和新聞等領域,幻覺容忍度極低,了解內容的來源及其創作方式至關重要。為解決這一問題,我們推出了文本溯源任務(TROVE),旨在將目標文本的每一句話追溯到可能冗長或多文檔輸入中的特定源句子。除了識別來源,TROVE還標注細粒度的關系(引用、壓縮、推斷等),提供了每個大模型生成結果的細粒度分析。為TROVE任務建立基準,我們通過利用三個公開數據集構建了我們的數據集,涵蓋了11種不同場景(例如問答和總結),包括英文和中文,且來源文本長度各異(0–5k,5–10k,10k+),并強化了對于溯源任務至關重要的多文檔和長文檔設置。為保證數據的高質量,我們設計了三階段的注釋過程:句子檢索、GPT溯源及人工溯源。我們在提示工程和檢索增強模式下評估了11個大語言模型,結果顯示檢索對于魯棒性至關重要,較大的模型和閉源在各類任務中表現更佳,但在檢索增強的場景下,開源模型顯示出顯著優勢。
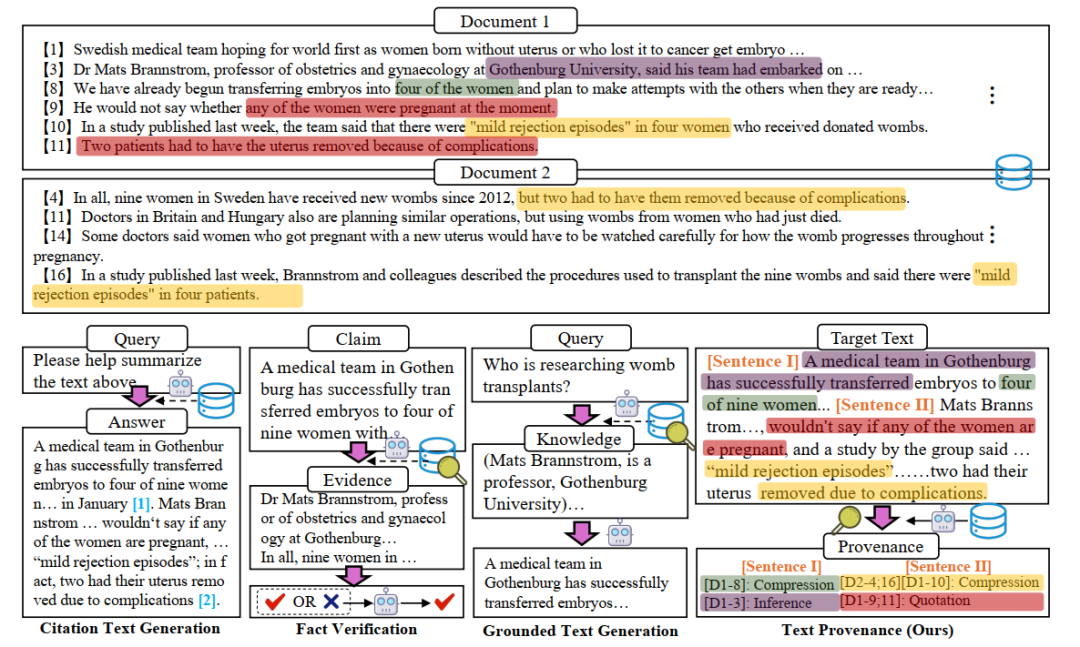
2 研究方向:大語言模型的可解釋性標題:Cracking Factual Knowledge: A Comprehensive Analysis of Degenerate Knowledge Neurons in Large Language Models作者:Yuheng Chen, Pengfei Cao, Yubo Chen, Yining Wang, Shengping Liu, Kang Liu, Jun Zhao
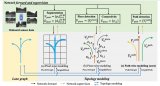
論文簡介:知識神經元理論提供了一種理解大型語言模型(LLMs)中事實性知識機制的重要方法,該理論表明,事實性知識存儲在多層感知器神經元中。本文進一步探索了簡并知識神經元(DKNs),即不同的神經元集合可以存儲相同的事實,但與簡單的冗余機制不同,它們還參與存儲其他不同的事實性知識。盡管這一概念具有新穎性和獨特性,但尚未得到嚴謹定義和系統研究。我們的貢獻包括:(1) 我們通過分析權重連接模式,開創了對知識神經元結構的研究,從功能和結構兩個方面提供了DKNs的全面定義。(2) 基于此定義,我們設計了神經拓撲聚類方法,從而更準確地識別DKNs。(3) 我們展示了DKNs在兩個方面的實際應用:引導大語言模型學習新知識以及增強大語言模型在輸入錯誤時的魯棒性。
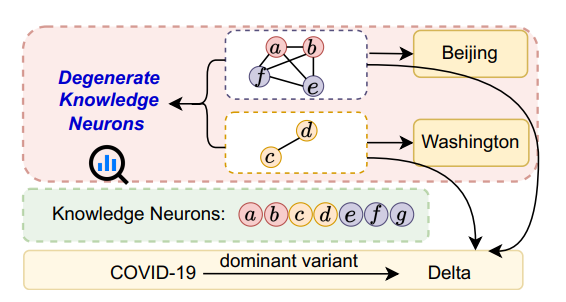
3 研究方向:圖文音多模態大模型標題:Investigating and Enhancing Vision-Audio Capability in Omni Modal Large Language Models作者:Rui Hu, Delai Qiu, Shuyu Wei, Jiaming Zhang,Yining Wang, Shengpeng Liu, Jitao Sang
論文簡介:全模態大語言模型(OLLMs)在整合視覺和文本方面取得了顯著進展,但在整合視覺和音頻方面仍然存在困難。具體來說,與處理文本查詢相比,模型在處理音頻查詢時通常表現不佳。這種差異主要是由于在訓練過程中視覺和音頻模態之間的對齊不足,導致在使用音頻查詢時對視覺信息的關注不夠。為了解決這一問題,我們提出了一種自知識蒸餾(Self-KD)的訓練方法,其中以OLLM的視覺-文本組件作為教師模型,視覺-音頻組件作為學生模型。這使得模型能夠學習以類似于處理文本查詢的方式處理音頻查詢。實驗結果表明,Self-KD可以有效提升全模態語言模型視覺-音頻能力,其通過從視覺-文本組件中學習,進而改善音頻與圖像之間的交互,并最終提升多模態任務的性能。
4
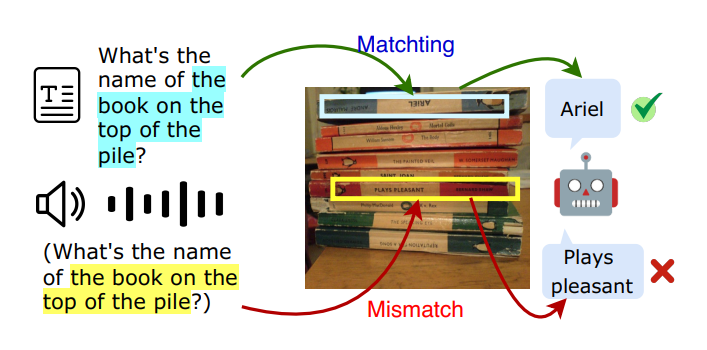
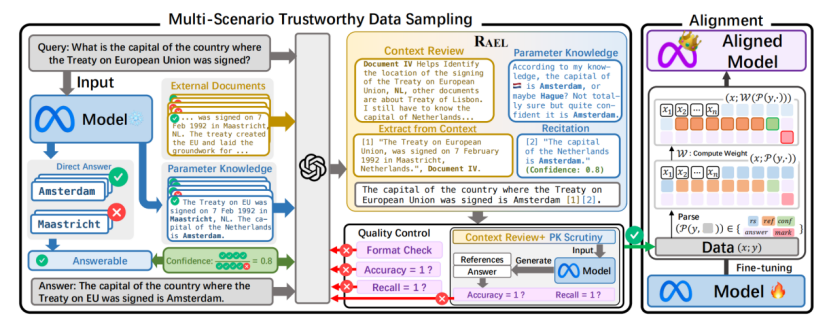
研究方向:大語言模型檢索增強標題:Transparentize the Internal and External Knowledge Utilization in LLMs with Trustworthy Citation作者:Jiajun Shen, Tong Zhou, Yubo Chen, Delai Qiu, Shengping Liu, Kang Liu, Jun Zhao
論文簡介:檢索增強生成和引文生成技術可以緩解大語言模型的幻覺問題,但模型調用內部知識的機制仍不透明,其生成答案的可信度依然難以保證。為此,我們提出“基于上下文-先驗的引用生成”任務,要求模型在綜合外部知識和內部知識的基礎上生成可信的引用。 我們的主要貢獻包括: 1. 提出了“上下文-先驗的引用生成”任務,要求模型能夠根據先驗知識合理引用參考文獻,并制定了5項評價指標,包括 (1) 答案有效性準確率,(2) 真實引用召回率,(3) 論證說服力,(4) 表述簡潔度,(5) 衡量參考文獻可信度的預期校準誤差;從答案有效性、引用準確性和結果可信度三個維度全面評估模型表現。 2. 開發了RAEL框架,要求模型審閱自我生成的相關概念或先驗知識,實現對上下文的準確引述;INTRALIGN方法,通過多場景可信數據生成和可解釋性對齊,使模型能夠有效利用先驗知識輸出更可靠的回答。
3. 在4種不同場景下測試了3類大語言模型和6種基線方法。結果表明,現有方法難以全面提升任務效果,而我們的方案不僅能準確引用參數化的內部知識,還能顯著提高引用質量和回答的可信度。
以上四篇論文的入選,是對云知聲堅持技術創新、推動產學研深度融合的有力肯定。未來,云知聲將繼續秉持開拓精神,深耕人工智能技術,不斷探索和拓展大模型的應用邊界,為全球科技進步貢獻更多中國智慧和創新力量。
-
計算機
+關注
關注
19文章
7626瀏覽量
90105 -
云知聲
+關注
關注
0文章
219瀏覽量
8651 -
自然語言處理
+關注
關注
1文章
627瀏覽量
13998
原文標題:云知聲4篇論文成果入選自然語言處理頂會ACL 2025,大模型研究再獲突破
文章出處:【微信號:云知聲,微信公眾號:云知聲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論