 電子發燒友App
電子發燒友App


電子發燒友網報道(文 / 吳子鵬)2025 年中國政府工作報告提出,“持續推進‘人工智能 +’行動”,并將 “支持大模型廣泛應用” 首次寫入報告。經過近幾年的高速發展,大模型技術帶動算力、算法、數據等基礎要素全面升級,推動芯片、信息基礎設施等硬科技與軟件服務的協同進化,已形成技術生態閉環。同時,AI 大模型正重構生產力要素,成為新質生產力發展的核心驅動引擎之一。
政策與市場需求雙輪驅動下,中國 AI 大模型市場高速增長。根據 IDC數據,2024年,中國大模型應用市場規模達到了47.9億元人民幣,預計2028 年整體市場規模將達 211 億元人民幣。高速發展的 AI 大模型不僅拉動云端算力需求增長,還將在端側廣泛落地 —— 在具身智能、人形機器人等領域,將形成 “大模型 + 傳感器 + 場景” 的生態協同效應。
然而,在巨大的市場機遇背后,挑戰亦不容忽視。典型挑戰之一是:隨著 AI 大模型部署在向更廣泛、更深度、更高效方向演進,推理任務也正從集中化的云端向端側延伸,這使得產業對高性能、低延遲、強本地處理能力的需求愈發迫切。
從云到端:AI 大模型驅動計算需求升級
生成式 AI 的爆發式發展,推動大模型從云端集中式推理向 “云 - 邊 - 端” 全棧部署演進。這一趨勢對計算資源提出多維度嚴苛要求:云端需突破算力密度天花板,端側則需追求極致能效比。
云端層面,大模型訓練與推理的算力需求呈指數級增長,參數量從千億級向萬億級躍進,訓練階段依賴萬卡甚至十萬卡 GPU 集群的分布式計算能力。云端推理成本隨用戶訪問量也同步上升,實時響應需求加劇服務器負載。傳統 x86 架構的數據中心面臨嚴峻挑戰,單服務器功耗、機架密度和推理成本均接近極限。
端側層面,端側 AI 通過模型剪枝、知識蒸餾等技術壓縮大模型體積,以減少對云端算力的依賴,但這也使邊緣端部署面臨更嚴苛的約束,算力與能效的平衡成為核心挑戰。端側設備需適配高性能 CPU、大顯存顯卡及高速存儲模組以支持低延遲推理。當前,智能手機、車載終端等消費電子領域對計算資源的爭奪已趨白熱化,工業、醫療、教育等領域亦迸發出大量需求。
未來,AI 大模型在端側的增長潛力更強,其核心驅動力來自技術突破、場景需求及政策支持的三重疊加效應。與此同時,端云協同正逐漸成為行業發展的主流趨勢 —— 云端負責復雜訓練與全局推理,端側聚焦實時響應與隱私保護。企業需相應構建 “云 - 邊 - 端” 一體化架構,通過模型壓縮、硬件加速等技術突破,在智能制造、智能駕駛、智慧醫療等關鍵領域實現規模化應用。在這個過程中,Arm 領先的計算平臺憑借其高能效、高性能及靈活性優勢正脫穎而出,為釋放 AI 大模型的潛能提供強大支撐,助力大模型從云到端的高效部署與運行。
Arm技術全棧賦能 AI 大模型發展
面對 AI 大模型在云端、端側及端云協同場景下的計算需求,Arm 提供了從架構到平臺、從硬件到軟件的全棧解決方案。
在云端領域,早在 AI 時代全面到來之前,Arm Neoverse 平臺就憑借其卓越的高能效特性,在基礎設施領域獲得了廣泛認可,特別是在 AI 推理這一對算力與能效有著嚴苛要求的場景中,展現出了不可比擬的獨特優勢。憑借出色的云端通用計算性能與能效表現,Arm Neoverse 已成為云數據中心領域的事實標準。如今,Neoverse 技術的部署更是達到了新的高度:2025 年出貨到頭部超大規模云服務提供商的算力中,將有近 50% 是基于 Arm 架構。亞馬遜云科技(AWS)、Google Cloud 和 Microsoft Azure 等超大規模云服務提供商,均采用 Arm Neoverse 計算平臺打造通用定制芯片,以優化數據中心和云計算的能源利用效率。
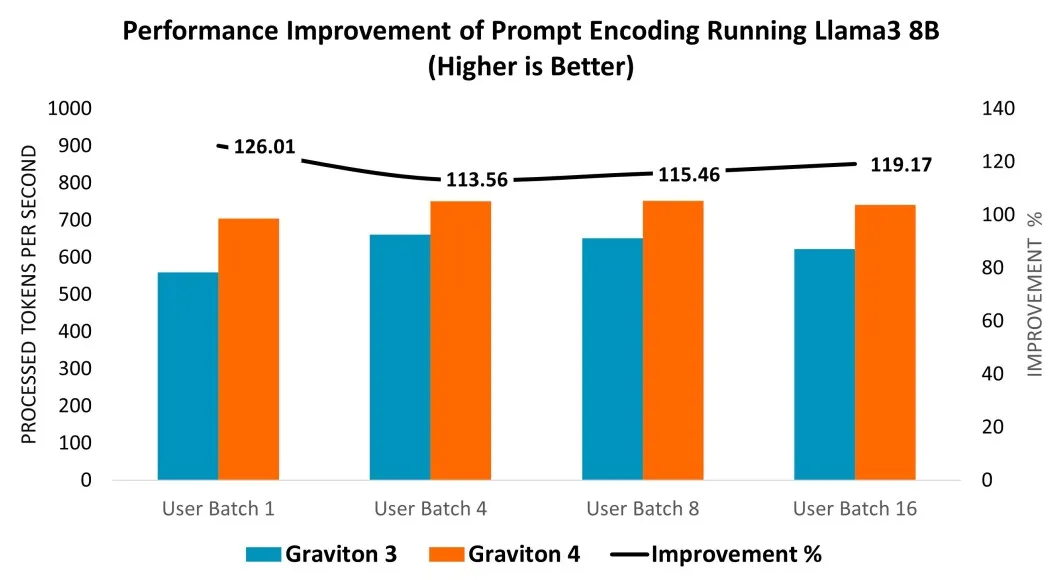
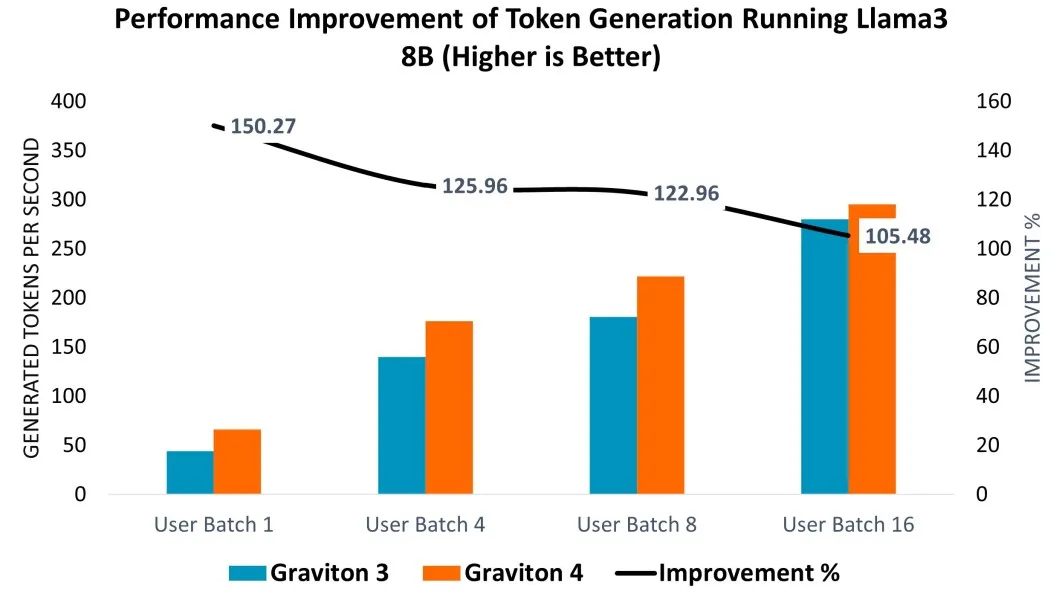
以 AWS Graviton4 CPU 為例,該處理器基于 64 位 Arm 指令集架構的 Arm Neoverse V2 核心設計,為各類云應用提供高效且高性能的解決方案。通過在 Graviton3(C7g.16xlarge)和 Graviton4(C8g.16xlarge)實例上部署 Llama 3 8B 模型進行性能評估,結果顯示:在提示詞編碼環節,Graviton4 性能相較 Graviton3 提升 14%-26%;詞元生成性能方面,在不同用戶批次大小測試中,Graviton4 在較小批次下效率提升更為顯著,達 5%-50%。
在端側領域,Arm 終端 CSS 集成最新的 Armv9.2 Cortex CPU 集群、Arm Immortalis 與 Arm Mali GPU、CoreLink 互連系統 IP,以及知名代工廠基于三納米工藝生產就緒的 CPU 和 GPU 物理實現。作為 AI 體驗的計算基礎,Arm 終端 CSS在消費電子設備中實現了性能、效率與可擴展性的跨越式提升。例如,Arm Cortex-X925 的 AI 性能提升了 41%,可顯著增強設備端生成式 AI(如 LLM)的響應能力。
這里展開介紹一下 Armv9 架構,該架構集成了加速和保護 LLM 等先進生成式 AI 工作負載的關鍵特性,如可伸縮矩陣擴展(SME)和可伸縮矢量擴展(SVE2)。SME 作為 Armv9-A 架構的指令集擴展,可加速 AI/ML 工作負載,為 Arm CPU 上運行的相關應用提供更高性能、能效與靈活性;SVE2 則提升 DSP 任務性能,使復雜算法處理更快速高效,尤其適用于高算力需求的 AI/ML 場景。
在邊緣 AI 領域,Arm 今年還發布了全新邊緣 AI 計算平臺,以全新基于 Armv9 架構的超高能效 CPU——Arm Cortex-A320 及原生支持 Transformer 網絡的 Ethos-U85 AI 加速器為核心,進一步助力 AI 大模型在端側的落地。
在軟件生態層面,Arm 在 2024 年推出 KleidiAI 軟件庫,助力 AI 框架開發者在各類設備上充分發揮 Arm CPU 性能,支持 Neon、SVE2 和 SME2 等關鍵 Arm 架構功能。作為一套面向 AI 框架開發者的計算內核,KleidiAI 可與 PyTorch、TensorFlow、MediaPipe、Angel 等熱門 AI 框架集成,旨在加速 Meta Llama 3、Phi-3、混元大模型等關鍵模型的性能表現,為生成式 AI 工作負載帶來顯著優化。此外,KleidiAI 還具備前后兼容性,確保 Arm 在引入新技術的同時持續滿足市場需求。目前,其支持范圍已覆蓋從基礎設施、智能終端到物聯網及汽車的全部 Arm 業務領域。
結語
從云端算力密度突破到端側能效平衡,AI 大模型的全面部署正重塑計算產業格局。Arm 架構憑借 “云 - 邊 - 端” 全鏈條技術協同優勢,成為激活新質生產力的關鍵引擎 —— 無論是 Neoverse 計算平臺在數據中心打破 x86 架構的能效瓶頸,還是終端 CSS 以及邊緣 AI 計算平臺在端側加速 AI 部署及應用,亦或是 KleidiAI 在軟件生態中搭建框架與硬件的高效橋梁,Arm 正以全棧式創新構建助推 AI 大模型發展的完整技術版圖。
政策與市場需求雙輪驅動下,中國 AI 大模型市場高速增長。根據 IDC數據,2024年,中國大模型應用市場規模達到了47.9億元人民幣,預計2028 年整體市場規模將達 211 億元人民幣。高速發展的 AI 大模型不僅拉動云端算力需求增長,還將在端側廣泛落地 —— 在具身智能、人形機器人等領域,將形成 “大模型 + 傳感器 + 場景” 的生態協同效應。
然而,在巨大的市場機遇背后,挑戰亦不容忽視。典型挑戰之一是:隨著 AI 大模型部署在向更廣泛、更深度、更高效方向演進,推理任務也正從集中化的云端向端側延伸,這使得產業對高性能、低延遲、強本地處理能力的需求愈發迫切。
從云到端:AI 大模型驅動計算需求升級
生成式 AI 的爆發式發展,推動大模型從云端集中式推理向 “云 - 邊 - 端” 全棧部署演進。這一趨勢對計算資源提出多維度嚴苛要求:云端需突破算力密度天花板,端側則需追求極致能效比。
云端層面,大模型訓練與推理的算力需求呈指數級增長,參數量從千億級向萬億級躍進,訓練階段依賴萬卡甚至十萬卡 GPU 集群的分布式計算能力。云端推理成本隨用戶訪問量也同步上升,實時響應需求加劇服務器負載。傳統 x86 架構的數據中心面臨嚴峻挑戰,單服務器功耗、機架密度和推理成本均接近極限。
端側層面,端側 AI 通過模型剪枝、知識蒸餾等技術壓縮大模型體積,以減少對云端算力的依賴,但這也使邊緣端部署面臨更嚴苛的約束,算力與能效的平衡成為核心挑戰。端側設備需適配高性能 CPU、大顯存顯卡及高速存儲模組以支持低延遲推理。當前,智能手機、車載終端等消費電子領域對計算資源的爭奪已趨白熱化,工業、醫療、教育等領域亦迸發出大量需求。
未來,AI 大模型在端側的增長潛力更強,其核心驅動力來自技術突破、場景需求及政策支持的三重疊加效應。與此同時,端云協同正逐漸成為行業發展的主流趨勢 —— 云端負責復雜訓練與全局推理,端側聚焦實時響應與隱私保護。企業需相應構建 “云 - 邊 - 端” 一體化架構,通過模型壓縮、硬件加速等技術突破,在智能制造、智能駕駛、智慧醫療等關鍵領域實現規模化應用。在這個過程中,Arm 領先的計算平臺憑借其高能效、高性能及靈活性優勢正脫穎而出,為釋放 AI 大模型的潛能提供強大支撐,助力大模型從云到端的高效部署與運行。
Arm技術全棧賦能 AI 大模型發展
面對 AI 大模型在云端、端側及端云協同場景下的計算需求,Arm 提供了從架構到平臺、從硬件到軟件的全棧解決方案。
在云端領域,早在 AI 時代全面到來之前,Arm Neoverse 平臺就憑借其卓越的高能效特性,在基礎設施領域獲得了廣泛認可,特別是在 AI 推理這一對算力與能效有著嚴苛要求的場景中,展現出了不可比擬的獨特優勢。憑借出色的云端通用計算性能與能效表現,Arm Neoverse 已成為云數據中心領域的事實標準。如今,Neoverse 技術的部署更是達到了新的高度:2025 年出貨到頭部超大規模云服務提供商的算力中,將有近 50% 是基于 Arm 架構。亞馬遜云科技(AWS)、Google Cloud 和 Microsoft Azure 等超大規模云服務提供商,均采用 Arm Neoverse 計算平臺打造通用定制芯片,以優化數據中心和云計算的能源利用效率。
以 AWS Graviton4 CPU 為例,該處理器基于 64 位 Arm 指令集架構的 Arm Neoverse V2 核心設計,為各類云應用提供高效且高性能的解決方案。通過在 Graviton3(C7g.16xlarge)和 Graviton4(C8g.16xlarge)實例上部署 Llama 3 8B 模型進行性能評估,結果顯示:在提示詞編碼環節,Graviton4 性能相較 Graviton3 提升 14%-26%;詞元生成性能方面,在不同用戶批次大小測試中,Graviton4 在較小批次下效率提升更為顯著,達 5%-50%。
從 Graviton3 (C7g.16xlarge) 到 Graviton4 (C8g.16xlarge) 運行 Llama 3 8B 模型的提示詞編碼所實現的性能提升。圖源:Arm
從 Graviton 3 (C7g.16xlarge) 到 Graviton 4 (C8g.16xlarge) 運行 Llama 3 8B 模型實現的詞元生成性能提升。圖源:Arm
在端側領域,Arm 終端 CSS 集成最新的 Armv9.2 Cortex CPU 集群、Arm Immortalis 與 Arm Mali GPU、CoreLink 互連系統 IP,以及知名代工廠基于三納米工藝生產就緒的 CPU 和 GPU 物理實現。作為 AI 體驗的計算基礎,Arm 終端 CSS在消費電子設備中實現了性能、效率與可擴展性的跨越式提升。例如,Arm Cortex-X925 的 AI 性能提升了 41%,可顯著增強設備端生成式 AI(如 LLM)的響應能力。
這里展開介紹一下 Armv9 架構,該架構集成了加速和保護 LLM 等先進生成式 AI 工作負載的關鍵特性,如可伸縮矩陣擴展(SME)和可伸縮矢量擴展(SVE2)。SME 作為 Armv9-A 架構的指令集擴展,可加速 AI/ML 工作負載,為 Arm CPU 上運行的相關應用提供更高性能、能效與靈活性;SVE2 則提升 DSP 任務性能,使復雜算法處理更快速高效,尤其適用于高算力需求的 AI/ML 場景。
在邊緣 AI 領域,Arm 今年還發布了全新邊緣 AI 計算平臺,以全新基于 Armv9 架構的超高能效 CPU——Arm Cortex-A320 及原生支持 Transformer 網絡的 Ethos-U85 AI 加速器為核心,進一步助力 AI 大模型在端側的落地。
在軟件生態層面,Arm 在 2024 年推出 KleidiAI 軟件庫,助力 AI 框架開發者在各類設備上充分發揮 Arm CPU 性能,支持 Neon、SVE2 和 SME2 等關鍵 Arm 架構功能。作為一套面向 AI 框架開發者的計算內核,KleidiAI 可與 PyTorch、TensorFlow、MediaPipe、Angel 等熱門 AI 框架集成,旨在加速 Meta Llama 3、Phi-3、混元大模型等關鍵模型的性能表現,為生成式 AI 工作負載帶來顯著優化。此外,KleidiAI 還具備前后兼容性,確保 Arm 在引入新技術的同時持續滿足市場需求。目前,其支持范圍已覆蓋從基礎設施、智能終端到物聯網及汽車的全部 Arm 業務領域。
結語
從云端算力密度突破到端側能效平衡,AI 大模型的全面部署正重塑計算產業格局。Arm 架構憑借 “云 - 邊 - 端” 全鏈條技術協同優勢,成為激活新質生產力的關鍵引擎 —— 無論是 Neoverse 計算平臺在數據中心打破 x86 架構的能效瓶頸,還是終端 CSS 以及邊緣 AI 計算平臺在端側加速 AI 部署及應用,亦或是 KleidiAI 在軟件生態中搭建框架與硬件的高效橋梁,Arm 正以全棧式創新構建助推 AI 大模型發展的完整技術版圖。























 工商網監
工商網監
評論