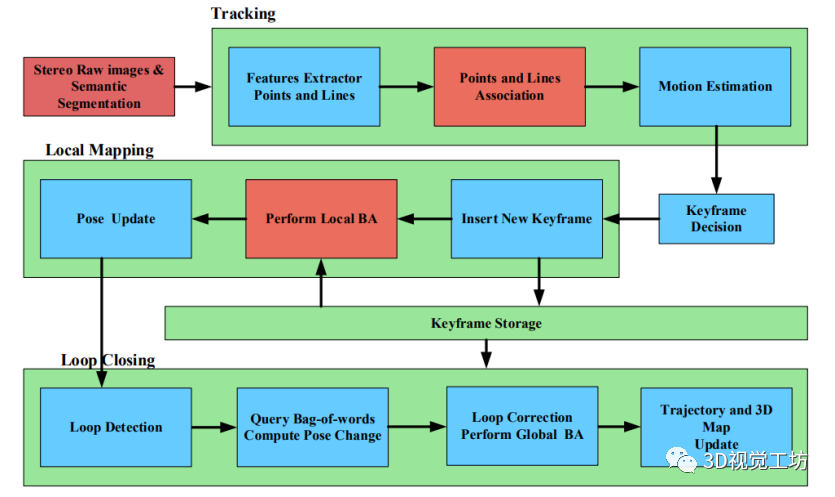
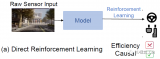
通常,模塊化系統被稱為中間范式,并被構建為離散組件的管道(圖3),連接傳感器輸入和運動輸出。模塊化系....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-04 16:25
?1422次閱讀

將BEV下的每個grid作為query,在高度上采樣N個點,投影到圖像中sample到對應像素的特征....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-04 10:22
?1675次閱讀

傳統的同步定位與制圖(SLAM)系統使用環境的靜態點作為實時定位和制圖的特征。當可用的點特征很少時,....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-01 17:16
?869次閱讀
神經輻射場(NeRF)通過將三維場景編碼成隱式表示,在視覺領域中廣泛應用。通過學習多層感知機(MLP....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-01 16:14
?862次閱讀

該方法具體通過六個步驟實現:圖像的采集、系統相機標定、特征模板匹配、圖像處理、三維仿真匹配以及三維重....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-01 16:12
?2645次閱讀
算法景深與光機和相機景深的關聯的確有點不好理解,這玩意兒有點復雜,和不同的硬件實現方法還有區別。正常....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 09-01 15:21
?1257次閱讀
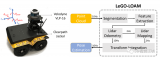
激光slam中,LOAM(Lidar Odometry and Mapping in Real-ti....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-31 15:54
?1025次閱讀
本文提出從兩個方面解決dToF數據的空間模糊:利用RGB-dToF視頻序列中的多幀信息融合和dToF....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-30 15:15
?1847次閱讀

卡爾曼濾波是一種用于估算線性動態系統狀態的優化算法,其基礎數學理論為貝葉斯定理,將傳感器測量值和系統....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-30 10:18
?2678次閱讀
卡爾曼濾波是一種用于估算線性動態系統狀態的優化算法,其基礎數學理論為貝葉斯定理,將傳感器測量值和系統....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-30 10:18
?1177次閱讀
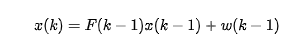
大多數現有的視覺SLAM方法嚴重依賴于靜態世界假設,在動態環境中很容易失效。本文提出了一個動態環境下....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-25 16:49
?967次閱讀
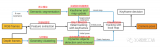
Transformer來源于自然語言處理領域,首先被應用于機器翻譯。后來,大家發現它在計算機視覺領域....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-22 14:52
?883次閱讀

圖7 TrackFormer 流程圖圖7TrackFormer得具體流程圖,該方法采用類似Motr和....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-22 14:44
?1037次閱讀

1 前言 大多數現有的3D網絡架構通過稠密且規則的三維體素網格來代替2D像素陣列,并使用3D卷積和池....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-21 09:53
?1184次閱讀
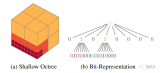
SfM是指給定一組無序圖像,恢復出相機位姿以及場景點云。通用場景下的SfM效果已經很好,而且COLM....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-21 09:22
?2496次閱讀

就以這兩天的最新進展來說,國外,馬克斯·普朗克固體物理和材料研究所猛下血本,直接整出了Pb????C....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-18 16:14
?547次閱讀

LOG-LIO的流程接收來自3D激光雷達和慣性測量單元(IMU)的輸入,如圖2所示。對于新的輸入掃描....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-18 15:45
?1137次閱讀
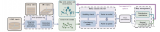
PnP是指根據2D-3D對應關系集合估計相機絕對位姿,集合最小的情況是P3P問題。P3P是將2D-3....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-18 15:40
?1500次閱讀
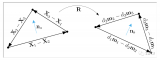
但是最近有一個團隊就推出了這樣的工作,也就是CMU、IIIT Hyderabad、MIT、AIML聯....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-14 11:58
?983次閱讀
語義占用網格感知對于自動駕駛至關重要,因為自動駕駛車輛需要對3D城市場景進行細粒度感知。
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-14 09:37
?1195次閱讀

卡爾曼濾波(Kalman Filter),以下簡稱KF,是由Swerling(1958)和Kalma....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-10 09:58
?11310次閱讀

說到純視覺的自動駕駛方案,大家第一個想到的就是Tesla吧。的確,早在2021年,Tesla就已經實....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-07 16:34
?1045次閱讀

當車輛位于十字路口時,自車的路徑實際上應該是根據信號燈來決定的。但是在圖像上信號燈很小,周圍車輛很大....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-07 15:07
?923次閱讀
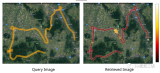
dToF(直接飛行時間)雷達的發展前景非常廣闊。隨著技術的不斷進步和應用場景的增多,dToF雷達在許....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-07 10:31
?734次閱讀
作者對多個 DETR 類檢測器的 GFLOPs 和時延進行了對比分析,如圖 1 所示。從圖中發現,在....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-02 15:34
?1005次閱讀

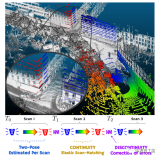
通過在每一幀掃描的開始和結束時刻聯合優化兩個姿勢,并根據時間戳進行插值,使掃描進行彈性變形以與地圖(....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 08-02 15:29
?1545次閱讀
dToF(直接飛行時間)雷達的發展前景非常廣闊。
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 07-31 09:22
?2681次閱讀

WormGPT 基于 2021 年開源的 LLM GPT-J 模型開發,也是對話聊天機器人,可以處理....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 07-29 16:35
?1854次閱讀
目標檢測的結果可以和場景流估計結合,可以通過多任務框架將兩個任務統一到一個網絡框架中。例如,一種方法....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 07-29 16:27
?993次閱讀
現有的文本到三維模型的生成方法通常使用NeRF等隱式表達,通過體積渲染將幾何和外觀耦合在一起,但在恢....
![的頭像]() 3D視覺工坊 發表于
3D視覺工坊 發表于 07-29 16:25
?668次閱讀






 工商網監
工商網監