 端到端的自動駕駛研發系統介紹
端到端的自動駕駛研發系統介紹
導讀:近日,吳恩達的 Drive.ai 被蘋果收購的消息給了自動駕駛領域一記警鐘,但這個領域的進展和成果猶在。本文將介紹一些端到端的自動駕駛研發系統,讓讀者可以從系統層面對自動駕駛有更加深刻的認識。
雖然不贊成,但有必要列出來這種研究和demo工作。
Nvidia是比較早做端到端控制車輛工作的公司,其方法訓練CNN模型完成從單個前向攝像頭的圖像像素到車輛控制的映射。 其系統自動學習一些處理步驟的內部表示,比如只用轉向角作為訓練信號去檢測道路特征。
下圖是其CNN模型訓練的流程圖,采用BP算法。而下下圖是模型推理的框圖,這時候只用一個中間的攝像頭。


下圖給出其數據收集系統的框架,包括3個攝像頭(左,右,中)輸入,輸出控制方向盤。

PilotNet如圖CNN模型架構細節,有2700萬個連結,25萬個參數。


駕駛仿真器

可以看出,這個模型不學習速度調整模型,如自適應巡航控制(ACC)那樣。當年,該系統曾在舊金山的著名觀景九曲花街做過演示,的確不需要控制速度,但是障礙物造成剎車也會造成人為接管。
Comma.ai 與 OpenPilot 駕駛模擬器
Comma.ai作為向特斯拉和Mobileye的視覺方法挑戰的黑客,的確在端到端的自動駕駛開發是最早的探索者。
其思想就是克隆駕駛員的駕駛行為,并模擬今后道路的操作規劃。采用的深度學習模型是基于GAN (generative adversarial networks)框架下的VAE(variational autoencoders)。利用一個行動(action)條件RNN模型通過15幀的視頻數據來學習一個過渡模型(transition model)。下圖給出了這個模擬器模型的架構,其中基于RNN的過渡模型和GAN結合在一起。

曾經在網上銷售其系統:
該方法沒有考慮感知模塊的單獨訓練,安全性較差,比如缺乏障礙物檢測,車道線檢測,紅綠燈檢測等等。
從大規模視頻中學習 E2E 駕駛模型
目的是學習一種通用的車輛運動模型,而這個端到端的訓練架構學會從單目相機數據預測今后車輛運動的分布。如圖應用一個FCN-LSTM 結構做到這種運動軌跡預測。


這種通用模型,輸入像素,還有車輛的歷史狀態和當今狀態,預測未來運動的似然函數,其定義為一組車輛動作或者運動粒度(離散和連續)。圖將這種方法和其他兩個做比較: “中介感知(Mediated Perception)“ 方法依賴于語義類別標簽;“運動反射(Motion Reflex)” 方法完全基于像素直接學習表示; 而 FCN-LSTM ,稱為“特權訓練(Privileged Training)“ 方法,仍然從像素學習,但允許基于語義分割的附加訓練。

基于逆向強化學習的人類自主駕駛開放框架
基于一個開放平臺,包括了定位和地圖的車道線檢測模塊,運動目標檢測和跟蹤模塊(DATMO),可以讀取車輛的里程計和發動機狀態。采用逆增強學習(IRL)建立的行為學習規劃模塊(BEhavior Learning LibrarY,Belly) ,其中特征右橫向偏移,絕對速度,相對車速限制的速度和障礙物的碰撞距離,輸出規劃的軌跡。圖是其系統框圖。

通過條件模仿學習進行端到端駕駛
模擬學習有缺陷,無法在測試時候控制,比如在交叉路口打U-turn。
提出條件模擬學習(Condition imitation learning),有以下特點:
訓練時候,輸入的不僅是感知和控制,還有專家的意圖。
測試時候,直接輸入命令,解決了感知電機(perceptuomotor)的多義性(ambiguity),同時可以直接被乘客或者拓撲規劃器控制,就像駕駛員的一步一步操作。
無需規劃,只需考慮駕駛的表達問題。
復雜環境下的視覺導航成為可能。
下面是實現條件模擬學習的兩個NN架構:
第一個:命令輸入。命令和圖像等測試數據一起作為輸入,可以用指向任務的向量取代命令構成任務條件的模擬學習。

第二個:分支。命令作為一個開關在專用的子模塊之間的切換。

物理系統:

虛擬和實際環境:

自動駕駛的失敗預測
駕駛模型在交通繁忙的地區、復雜的路口、糟糕的天氣和照明條件下很可能失敗。而這里就想給出一個方法能夠學習如何預測這些失敗出現,意識是估價某個場景對一個駕駛模型來說有多困難,這樣可以提前讓駕駛員當心。
這個方法是通過真實駕駛數據開發一個基于攝像頭的駕駛模型,模型預測和真實操作之間的誤差就稱為錯誤度。 這樣就定義了“場景可駕駛度(Scene Drivability),其量化的分數即安全和危險(Safe and Hazardous),圖給出整個架構圖。

圖是失敗預測模型訓練和測試的流程圖。預測失敗其實是對駕駛模型的考
驗,能及時發現不安全的因素。

結果如下

基于激光雷達的完全卷積神經網絡
驅動路徑生成
Note:past path (red),Lidar-IMU-INT’s future path prediction (blue).
這是一個機器學習方法,通過集成激光雷達點云,GPS-IMU數據和Google地圖導航信息而產生駕駛通路。還有一個FCN模型一起學習從真實世界的駕駛序列得到感知和駕駛通路。產生與車輛控制相接近并可理解的輸出,有助于填補低層的景物分解和端到端“行為反射”方法之間的間距。圖給出其輸入-輸出的張量信號,如速度,角速度,意圖,反射圖等等。
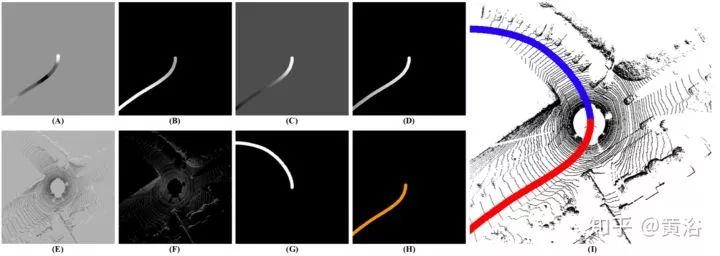

下面圖每列中,頂圖是過去/今后(紅/藍)通路預測,底圖是駕駛意圖近域(左)和駕駛意圖方向(右)。A列是駕駛意圖(右轉)和直路無出口的分歧,B–D列是存在多個可能方向 。
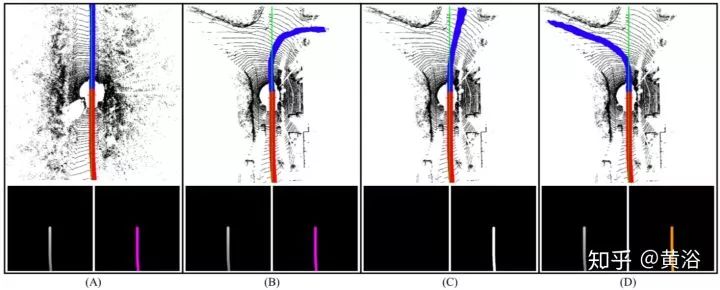
Note:driving intentionproximity(left),driving
intentiondirection(right).

上圖是FCN模型參數。
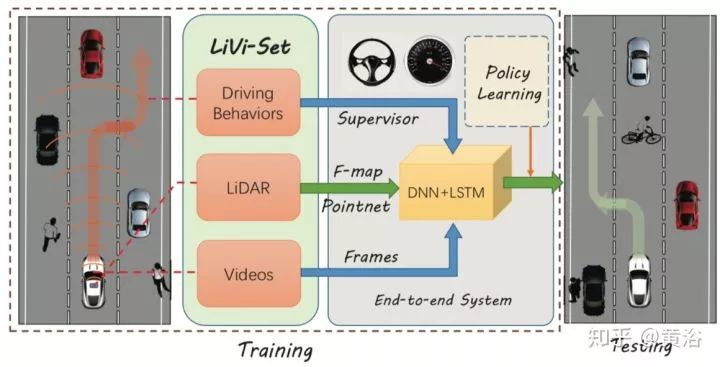
LiDAR視頻駕駛數據集:有效學習駕駛政策
離散動作預測,預測所有可能動作的概率分布。但離散預測的局限是,只能在有限的定義好的動作進行預測。連續預測是把預測車輛的現行狀態作為一個回歸任務,如果準確預測在實際狀態的駕駛策略,那么被訓練的模型可以成功駕駛車輛。所以,把駕駛過程看成一個連續的預測任務,訓練一個模型在輸入多個感知信息(包括視頻和點云)后能預測正確的方向盤轉角和車輛速度。

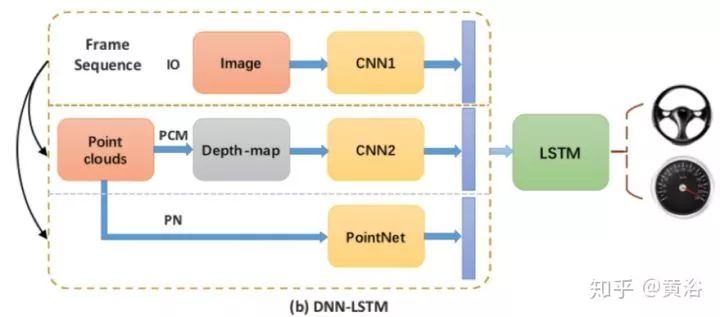
如圖是其系統框圖,其中深度學習模型是DNN加LSTM,激光雷達點云通過PointNet提取特征送入深度學習模型。
如圖給出傳感器數據在進入NN模型之前的預處理流水線框圖,需要時間同步,空間對齊。

下面圖是深度學習模型DNN和DNN+LSTM的架構圖

使用環視攝像機和路線規劃器進行駕駛模型的端到端學習
ETH的工作,采用一個環視視覺系統,一個路徑規劃器,還有一個CAN總線閱讀器。 采集的駕駛數據包括分散的駕駛場景和天氣/照明條件。集成環視視覺系統和路徑規劃器(以OpenStreetMap為地圖格式的GPS坐標或者TomTom導航儀)的信息,學習基于CNN,LSTM和FCN的駕駛模型,如圖所示。

實驗中,與采用單前向攝像頭訓練的模型還有人工操作比較(藍/黃/紅),如圖所示:其中(1)-(3)對應三種不同的模型訓練結果,即(1)只用TomTom路徑規劃器訓練,(2)只用環視視覺系統訓練, (3)用環視視覺和TomTom路徑規劃器一起訓練。

深度學習的模型架構,包括路徑規劃器和環視系統5個輸入通道,輸出到方向
盤和加速踏板。

下面結果是左右拐彎時候的三種方法比較:人,前向攝像頭和環視視覺加TomTom導航儀。

目前,該還沒有加入目標檢測和跟蹤的模塊(當然還有紅綠燈識別,車道線檢測之類的附加模塊),但附加的這些模型能夠改進整個系統的性能。
佐治亞理工學院端到端學習自動駕駛
還是模擬學習:采用DNN直接映射感知器數據到控制信號。下面系統框圖:

下面是DNN 控制策略:

TRI自動駕駛端到端控制
端到端DNN訓練,提出一種自監督學習方法去處理訓練不足的場景。下圖是自監督端到端控制的框架:NN編碼器訓練學習監督控制命令,還有量化圖像內容的各種非監督輸出。

提出新的VAE架構,如下圖,做端到端控制: 編碼器卷積層之后的圖像特征,進入一個監督學習方向盤控制的潛在變量(latent variables )的可變空間。最后潛在向量進入解碼器自監督學習重建原始圖像。

特斯拉 SW 2.0
特斯拉的2.0軟件思想,2018年8月提出。

自動雨刷:
-
圖像
+關注
關注
2文章
1092瀏覽量
41026 -
英偉達
+關注
關注
22文章
3922瀏覽量
93112 -
自動駕駛
+關注
關注
788文章
14198瀏覽量
169523
原文標題:從特斯拉到英偉達,那些端到端自動駕駛研發系統有何不同?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中基于規則的決策和端到端大模型有何區別?
東風汽車推出端到端自動駕駛開源數據集
動量感知規劃的端到端自動駕駛框架MomAD解析
DiffusionDrive首次在端到端自動駕駛中引入擴散模型

端到端自動駕駛技術研究與分析
端到端在自動泊車的應用
從車企實踐看自動駕駛端到端解決方案








 工商網監
工商網監
評論