") DiffusionDrive首次在端到端自動駕駛中引入擴散模型
DiffusionDrive首次在端到端自動駕駛中引入擴散模型
近年來,端到端自動駕駛成為研究熱點,其核心在于從傳感器數(shù)據(jù)直接學(xué)習(xí)駕駛決策。然而,駕駛行為本質(zhì)上是多模態(tài)的——同一場景下可能存在多種合理軌跡,例如在復(fù)雜路口,車輛可選擇左轉(zhuǎn)、右轉(zhuǎn)或直行。這種多樣性是提升自動駕駛魯棒性和安全性的關(guān)鍵,但現(xiàn)有方法往往受限于單一軌跡回歸或固定錨點采樣,難以全面建模駕駛決策空間。
擴散模型 (Diffusion Model) 憑借強大的多模態(tài)建模能力,已在機器人決策學(xué)習(xí)中得到驗證。其逐步去噪機制能從復(fù)雜數(shù)據(jù)分布中生成多樣性強、符合物理約束的軌跡,使其成為自動駕駛多模態(tài)規(guī)劃的理想選擇。然而,擴散模型直接應(yīng)用于端到端自動駕駛?cè)悦媾R計算開銷高和模式崩潰 (Mode Collapse) 的問題——傳統(tǒng)擴散模型需多輪迭代去噪,導(dǎo)致推理速度難以滿足實時需求,同時在高度動態(tài)的交通場景下,生成軌跡往往趨于重疊,無法充分展現(xiàn)駕駛決策的多樣性。
為此,我們提出截斷擴散策略 (Truncated Diffusion Policy) ,結(jié)合多模態(tài)錨點先驗 (Multi-mode Anchors Prior) ,通過截斷擴散過程,使模型從錨定的高斯分布 (Anchored Gaussian Distribution) 直接去噪至多模態(tài)駕駛軌跡分布。該方法避免了從純隨機噪聲開始的冗長迭代,僅需2步即可完成高質(zhì)量軌跡推理,相比傳統(tǒng)擴散策略加速10倍。此外,我們設(shè)計了級聯(lián)擴散解碼器 (Cascade Diffusion Decoder) ,增強模型對場景信息的交互能力,提升軌跡預(yù)測精度。
我們提出的DiffusionDrive首次在端到端自動駕駛中引入擴散模型,并通過截斷擴散策略與級聯(lián)擴散解碼器,有效解決計算開銷與模式崩潰問題,為構(gòu)建高效、魯棒的多模態(tài)自動駕駛規(guī)劃提供了新思路。
范式對比
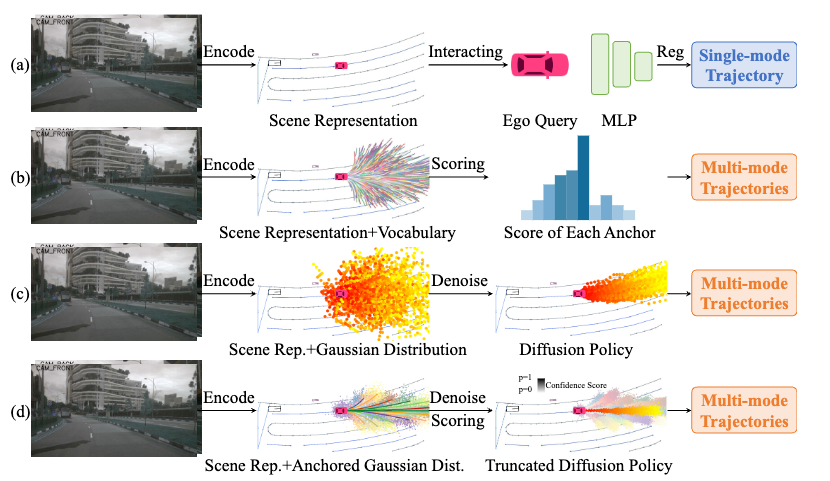
對比不同的端到端自動駕駛范式:
(a) 單模態(tài)回歸方法,通過Ego Query機制直接預(yù)測單一軌跡,但忽略了駕駛行為的多模態(tài)特性,難以適應(yīng)復(fù)雜交通場景。
(b) 預(yù)定義錨定軌跡采樣方法,通過固定的錨定軌跡集來離散化軌跡空間,并基于評分機制進行選擇,雖然能夠一定程度上捕捉多模態(tài)行為,但受限于錨定軌跡數(shù)量和分布,難以泛化到未見場景。
(c) 傳統(tǒng)擴散策略通過在高斯分布上迭代去噪來生成軌跡,能夠捕捉多模態(tài)駕駛行為,但由于去噪步驟多,計算成本高,并且在復(fù)雜交通環(huán)境中容易出現(xiàn)模式崩潰,導(dǎo)致軌跡多樣性不足。
(d) 我們提出的截斷擴散策略,通過引入錨定高斯分布,利用多模態(tài)錨點作為初始分布,使模型從更合理的軌跡分布開始去噪,從而顯著減少計算開銷,僅需少量去噪步驟即可生成高質(zhì)量的多模態(tài)軌跡,在保證多樣性的同時大幅提升推理效率,使其更適用于實時自動駕駛。
截斷擴散策略
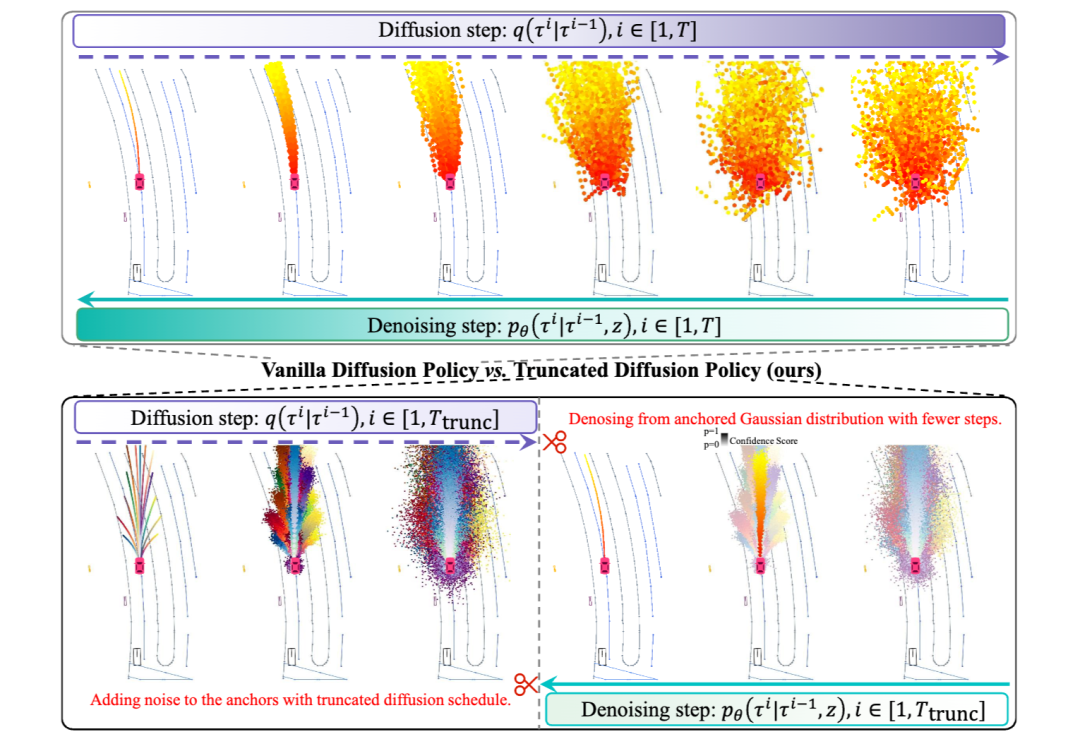
傳統(tǒng)擴散策略在端到端自動駕駛?cè)蝿?wù)中的應(yīng)用面臨兩大核心挑戰(zhàn):高計算成本和模式崩潰。擴散模型的去噪過程通常需要多輪迭代,例如20輪,以逐步將純高斯噪聲轉(zhuǎn)化為可行的駕駛軌跡。然而,這種逐步推理方式導(dǎo)致計算開銷極高,難以滿足實時自動駕駛的要求。此外,由于自動駕駛場景高度動態(tài)且充滿不確定性,擴散模型從隨機噪聲生成軌跡時,可能會產(chǎn)生高度相似、甚至完全重疊的軌跡分布,導(dǎo)致模式崩潰,使得生成的軌跡多樣性不足,難以覆蓋真實世界中的駕駛決策空間。
為了解決這些問題,我們提出截斷擴散策略,通過結(jié)合多模態(tài)錨點先驗,優(yōu)化擴散模型的初始化和去噪過程,使其能夠從更合理的軌跡分布出發(fā),而非從完全隨機的高斯噪聲開始。具體而言,我們首先在訓(xùn)練數(shù)據(jù)中對駕駛軌跡進行聚類,得到一組代表性的錨點軌跡 (Anchor Trajectories) ,這些錨點能夠較好地覆蓋不同駕駛場景下的典型軌跡模式。在訓(xùn)練時,我們不再讓模型從純隨機高斯分布中學(xué)習(xí)去噪,而是在錨點軌跡的基礎(chǔ)上添加少量噪聲,形成一個更具物理合理性的初始分布。相比于傳統(tǒng)擴散模型直接從隨機噪聲學(xué)習(xí)駕駛行為,這種方式大幅減少了去噪步驟的需求,讓模型可以從更接近真實駕駛行為的軌跡分布中進行優(yōu)化。
在推理階段,我們直接從這些錨定的軌跡分布中采樣,而不是從完全隨機的高斯噪聲開始,并大幅縮短去噪過程,僅需2輪去噪步驟即可生成高質(zhì)量的駕駛軌跡,相比傳統(tǒng)擴散策略加速10倍。此外,為了進一步提升軌跡的合理性,我們在去噪過程中引入了置信度評分機制 (Confidence Scoring Mechanism) ,通過對去噪后的軌跡進行動態(tài)評分,篩選出最符合物理約束和場景要求的軌跡。這種評分機制可以有效過濾掉異常或重疊的軌跡,避免模式崩潰問題,使最終生成的軌跡既具備多樣性,又保持合理性。
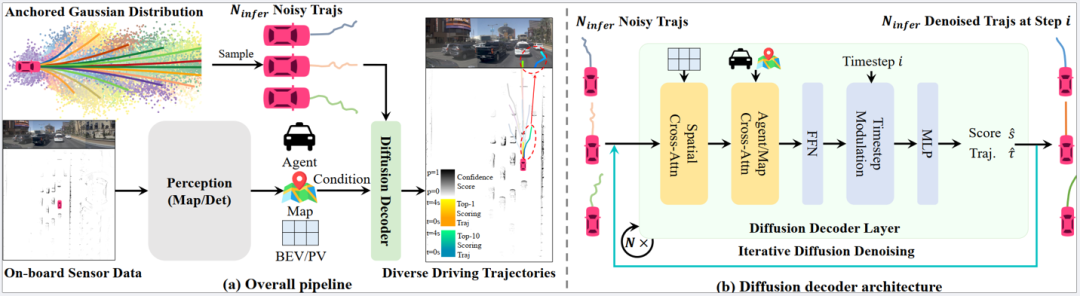
此外,我們設(shè)計了一種級聯(lián)擴散解碼器,提升模型在去噪過程中的場景感知能力。傳統(tǒng)擴散模型通常采用單步解碼,即直接在每一步去噪后輸出軌跡,而我們的級聯(lián)擴散解碼器允許模型在每個去噪步驟中與環(huán)境感知信息進行多輪交互,通過層層遞進的方式優(yōu)化軌跡質(zhì)量。這種級聯(lián)機制結(jié)合了稀疏可變形注意力 (Sparse Deformable Attention) ,使得模型能夠高效地從鳥瞰視角 (BEV) 和透視視角 (PV) 提取關(guān)鍵信息,提升軌跡生成的穩(wěn)定性和魯棒性。
綜上,我們的截斷擴散策略不僅保留了擴散模型在多模態(tài)軌跡建模上的強大能力,還通過錨點先驗和去噪優(yōu)化,顯著提升了推理效率,并通過置信度評分和級聯(lián)解碼器,有效解決了模式崩潰問題,最終使得生成的駕駛軌跡更加貼近真實駕駛行為,使其更適用于實時自動駕駛系統(tǒng)。
實驗驗證
我們選擇采用更加嚴格的閉環(huán)評測方式,針對駕駛決策的數(shù)據(jù)集NAVSIM,來驗證我們的設(shè)計:
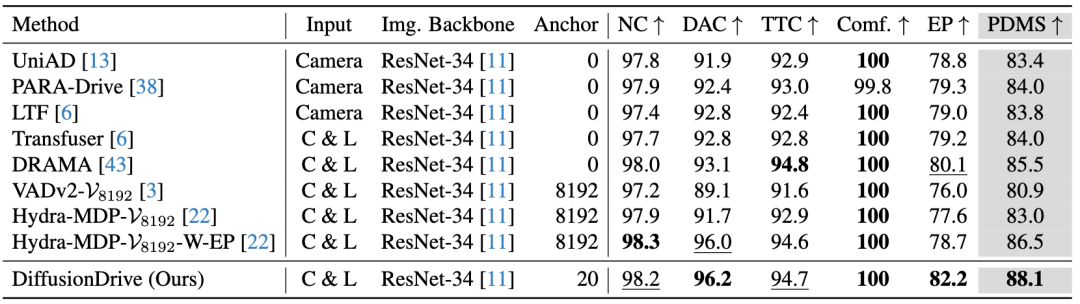
可以看到DiffusionDrive大幅領(lǐng)先之前所有的端到端方案,僅僅通過學(xué)習(xí)人類駕駛行為,不引入額外監(jiān)督與后處理,我們超過了之前的冠軍方案Hydra-MDP。
EP指標的明顯優(yōu)勢更是凸顯了DiffusionDrive方法的魯棒性。因為EP指標用于評測planning的完成度以及對干擾的魯棒性,而DiffusionDrive在這一指標上具有十分突出的優(yōu)勢。

在消融實驗中,顯示我們提出的截斷式擴散策略和設(shè)計的Diffusion Decoder相比于傳統(tǒng)擴散策略能夠帶來更高的planning質(zhì)量 (PDMS) ,更高的planning多模態(tài)特性 (D) ,更快的速度 (FPS) 。
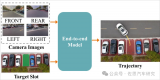
可視化驗證
我們將模型在驗證集上推理得到的多模態(tài)軌跡可視化出來:
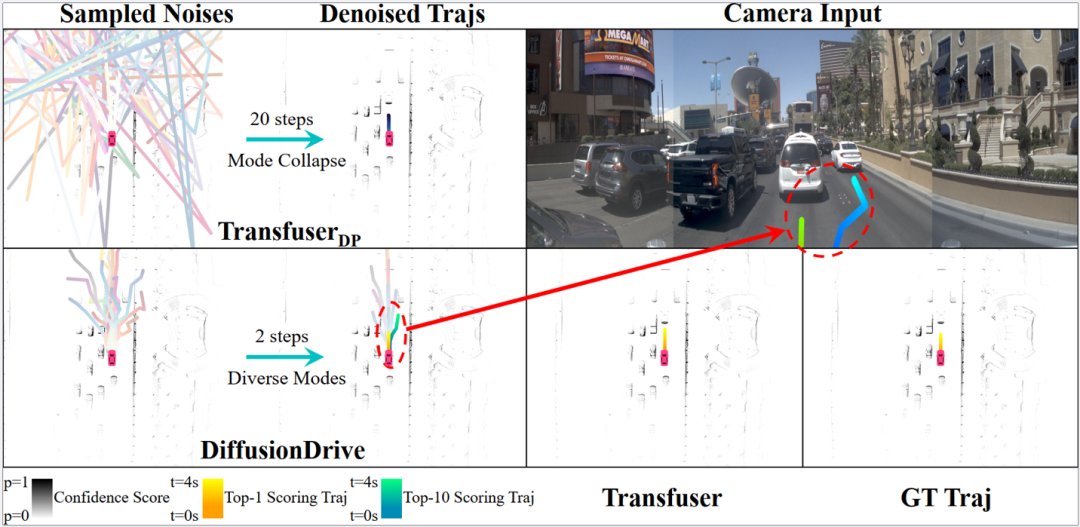
如上圖所示,我們不僅能夠輸出保守的跟車,也能夠輸出合理換道超車的行為。
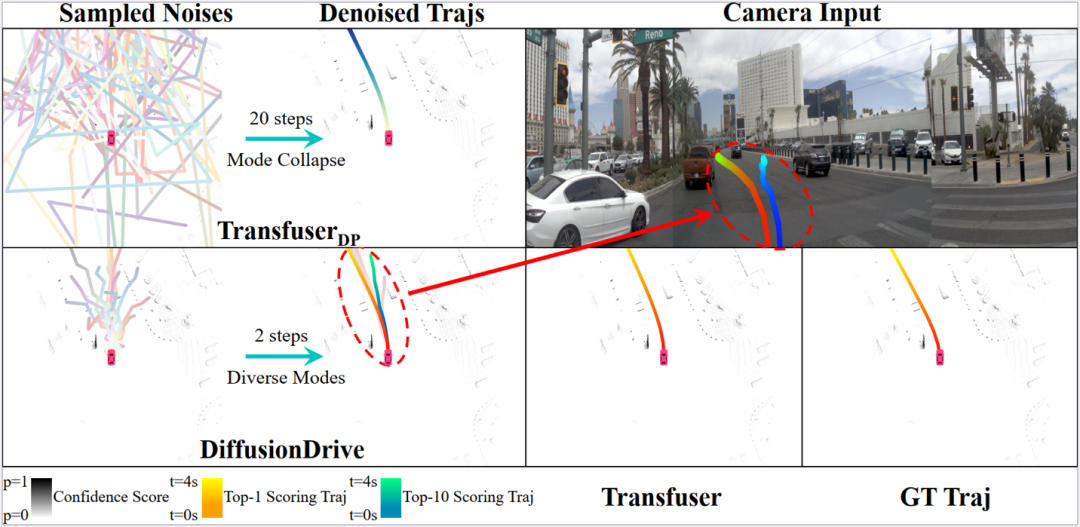
上圖也是進一步驗證DiffusionDrive魯棒的多模態(tài)特性,輸出多樣化的planning軌跡能夠進一步與環(huán)境交互,避免碰撞。
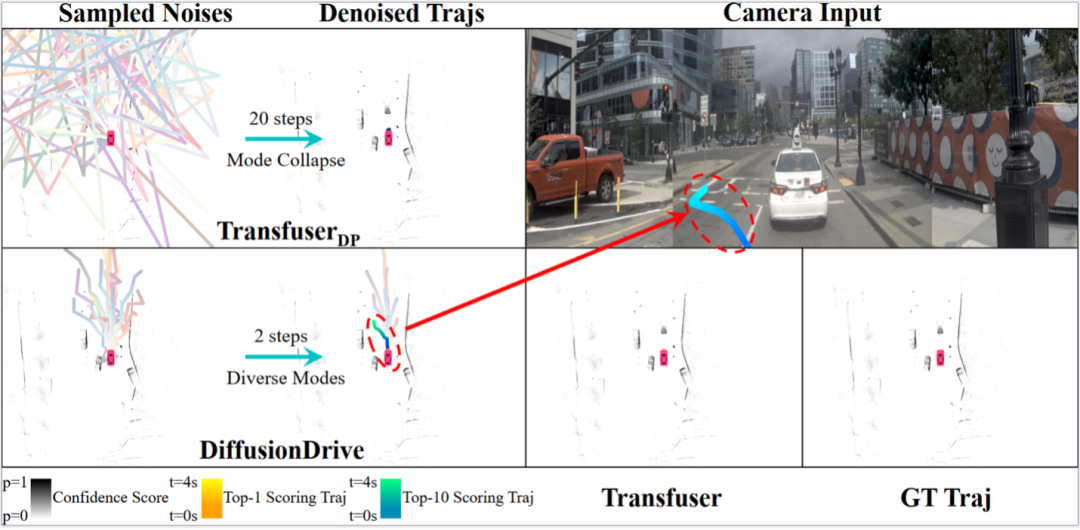
上圖顯示DiffusionDrive還能和紅綠燈交互,所以在除了跟車行為之外的換道行為時,選擇停在停止線上,而模型在訓(xùn)練中并沒有紅綠燈的標注,通過提出的范式,使得模型學(xué)習(xí)到了潛在的駕駛底層邏輯。
業(yè)務(wù)驗證
DiffusionDrive也在業(yè)務(wù)數(shù)據(jù)集上進行了規(guī)模化驗證。下面是實車測試的視頻:
總結(jié)
我們提出DiffusionDrive,一種基于擴散模型的端到端自動駕駛方法,以截斷擴散策略解決傳統(tǒng)擴散方法的高計算成本和模式崩潰問題。通過引入多模態(tài)錨點先驗,我們將去噪過程從錨定的高斯分布開始,而非從純隨機噪聲進行迭代,大幅減少計算量,僅需2步即可生成高質(zhì)量軌跡,相較于傳統(tǒng)擴散策略推理加速10倍。此外,我們設(shè)計了級聯(lián)擴散解碼器,結(jié)合場景感知信息逐步優(yōu)化軌跡,提升軌跡預(yù)測的多樣性和準確性。
實驗表明,DiffusionDrive在NAVSIM和nuScenes數(shù)據(jù)集上均取得最優(yōu)表現(xiàn),顯著提升了規(guī)劃質(zhì)量、軌跡多樣性和計算效率。相比現(xiàn)有SOTA方法,DiffusionDrive在保證實時性的同時,提高了20.8%軌跡精度,降低63.6%碰撞率。此外,我們更是在真實場景中驗證了DiffusionDrive的有效性。
本研究首次將截斷擴散策略引入端到端自動駕駛,突破了擴散模型計算開銷大、模式崩潰的瓶頸,為實時高效的多模態(tài)駕駛決策提供了一種全新范式。
-
解碼器
+關(guān)注
關(guān)注
9文章
1163瀏覽量
41672 -
機器人
+關(guān)注
關(guān)注
213文章
29446瀏覽量
211399 -
模型
+關(guān)注
關(guān)注
1文章
3480瀏覽量
49947 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14182瀏覽量
169364
原文標題:CVPR 2025|DiffusionDrive: 邁向生成式多模態(tài)端到端自動駕駛
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
自動駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?
FPGA在自動駕駛領(lǐng)域有哪些應(yīng)用?
自動駕駛真的會來嗎?
如何基于深度神經(jīng)網(wǎng)絡(luò)設(shè)計一個端到端的自動駕駛模型?
端到端自動駕駛到底是什么?
理想汽車自動駕駛端到端模型實現(xiàn)

理想汽車加速自動駕駛布局,成立“端到端”實體組織
實現(xiàn)自動駕駛,唯有端到端?

Mobileye端到端自動駕駛解決方案的深度解析

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動駕駛系統(tǒng)
連接視覺語言大模型與端到端自動駕駛

端到端在自動泊車的應(yīng)用
端到端自動駕駛技術(shù)研究與分析
一文帶你厘清自動駕駛端到端架構(gòu)差異





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論