 Xavier的硬件架構特性!Xavier推理性能評測
Xavier的硬件架構特性!Xavier推理性能評測
01
背景
如果把信息科技產業劃分為三個時代:PC 時代、移動互聯網時代和人工智能(AI)時代。目前,我們處于移動互聯網時代的末期和下一個時代的早期,即以深度神經網絡算法為核心的AI 時代。
深度神經網絡模擬人類大腦的工作原理,是近年來機器學習領域最令人矚目的方向。2006年深度學習泰斗Geoffrey Hinton提出了基于“逐層訓練”和“精調”的兩階段策略,解決了深度神經網絡中參數訓練的難題后,學術界和工業界對深度神經網絡的研究熱情高漲,并逐漸在語音識別、圖像識別、自然語言處理等領域取得突破性進展。2012年深度卷積神經網絡在ImageNet圖像分類競賽中取得了世界第一,標志著端到端的方法取得了超越手工設計特征的傳統方法。此后深度神經網絡的發展進入了快車道。2016年基于深度學習的AlphaGo打敗了圍棋世界冠軍李世石,同度舉辦的人工智能知名學術會議CVPR、NIPS、AAAI和ICLR上深度神經網絡的主題占主導地位。2017年以深度神經網絡為核心的DeepStack算法在德州撲克游戲中擊敗了人類職業玩家。2018年,人工智能的芯片已經應用于云計算和移動終端中。目前,深度神經網絡的研究向著更深更廣的方向前進,一方面深度神經網絡的理論研究越來越深入,另外一方面如何開發基于深度神經網絡的智能系統成為關鍵,特別是如何將人工智能技術與邊緣計算結合起來。
云計算作為一種計算模式已經滲透進我們日常生活之中,但是有很多很多應用場合,由于網絡不可用、網絡帶寬不足和網絡延遲大等原因使得基于云計算的模式不能滿足需求,這就是邊緣計算覆蓋的領域。中國邊緣計算產業聯盟(Edge Computing Consortium,ECC)定義的邊緣計算是指在靠近物或數據源頭的網絡邊緣側,融合網絡、計算、存儲、應用核心能力的開放平臺,就近提供邊緣智能服務,滿足業務在敏捷聯接、實時業務、數據優化和應用智能等方面的關鍵需求。由此可見要想在邊緣計算中部署人工智能應用,必須要有高性能低功耗的超級計算平臺。NVIDIA最近發布的Jetson AGX Xavier就是在邊緣計算場景中部署人工智能應用的一個利器。
嵌入式超級計算機Jetson AGX Xavier可以用于自主物流車、機器人、無人機和其他智能機器,從而加速制造、物流、零售、服務、農業、醫療等產業的智能化發展,為智能城市的發展做出貢獻。
02
Xavier的硬件架構特性
Xavier是最新一代NVIDIA業界領先的嵌入式Linux高性能計算機,主要包括一個8核NVIDIA Carmel ARMv8.2 64位CPU,由8個流多處理器組成的512核Volta架構的GPU,支持并行計算語言CUDA 10,支持多精度計算,FP16計算能力為11 TFLOPS(每秒浮點運算次數),INT8為22 TOPS。64個Tensor核心, 16GB 256位LPDDR4x,雙深度學習加速器 (DLA)引擎,NVIDIA視覺加速器引擎,高清視頻編解碼器,Xavier集成的Volta GPU,具體參數如表1所示,GPU架構如圖1所示。
用戶可根據應用需要配置Xavier工作在10W、15W和30W的模式,憑借多種工作模式,Jetson AGX Xavier的能效比其前身Jetson TX2高出10倍以上,性能超過20倍。
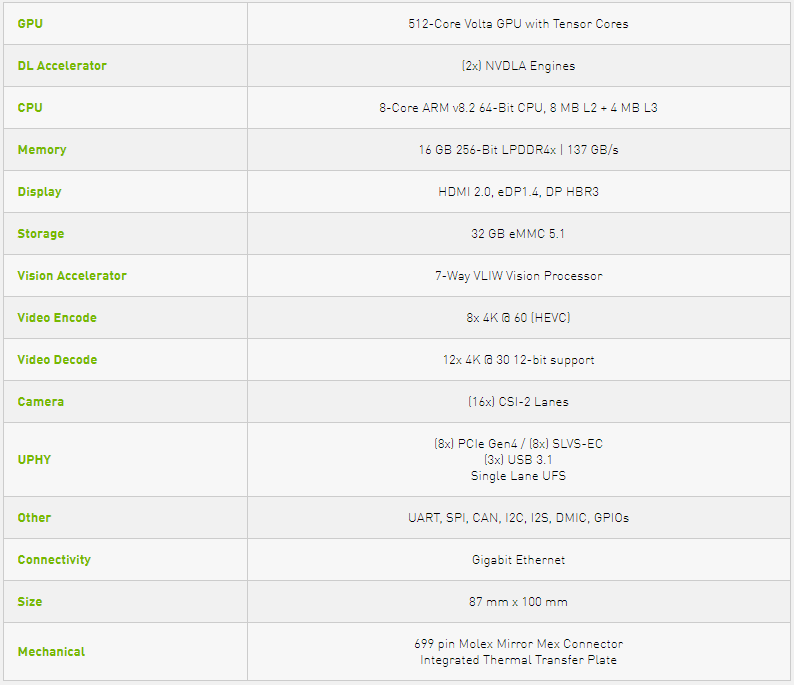
表1 Xavier主要參數
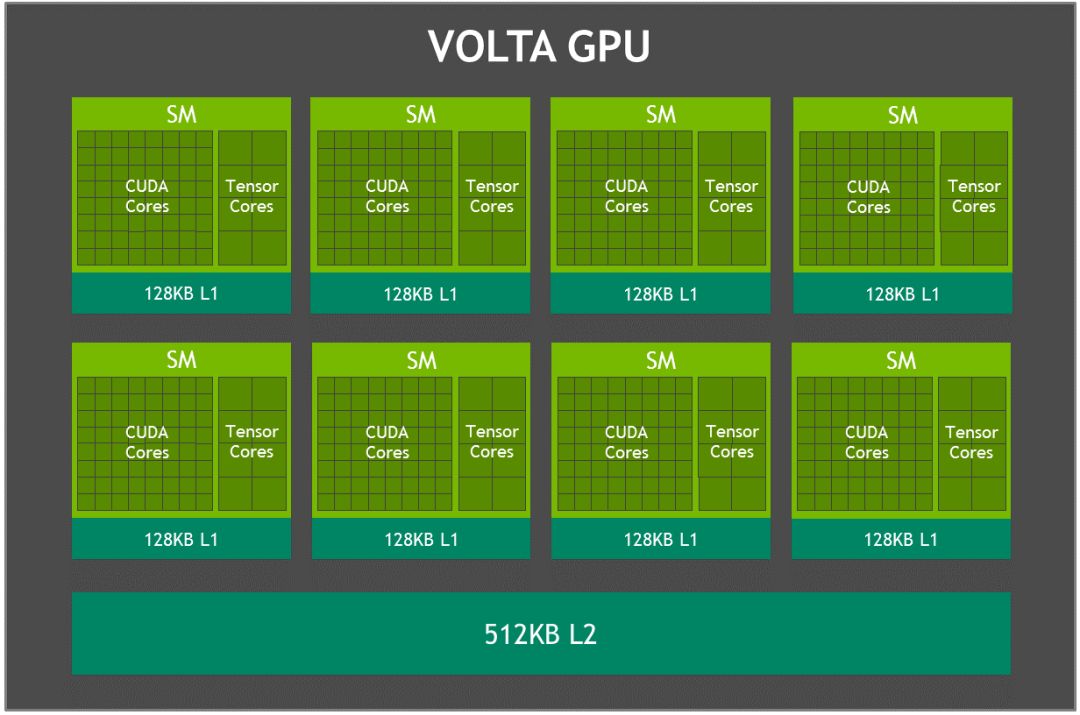
圖1 Xavier Volta GPU架構
Xavier內置的 Tensor Core支持混合精度計算。可以完成以下的融合乘法加法:執行兩個4*4 FP16矩陣相乘,將結果添加到4*4 FP16或FP32矩陣中,最終輸出新的4*4 FP16或FP32矩陣。深度神經網絡最耗時的卷積操作在訓練和推理時都可以轉成上述的矩陣乘法,Tensor Core極大的提高了計算效率。
Xavier具有兩個NVIDIA 深度學習加速器(DLA)引擎,可以進行高性能的深度神經網絡推理計算,其結構如圖2所示。這每個DLA具有高達5 TOPS INT8或2.5 TFLOPS FP16計算性能,功耗僅為0.5-1.5W。DLA支持加速CNN層,例如卷積、反卷積、激活函數、最小/最大/平均池化、局部響應歸一化和全連接層。
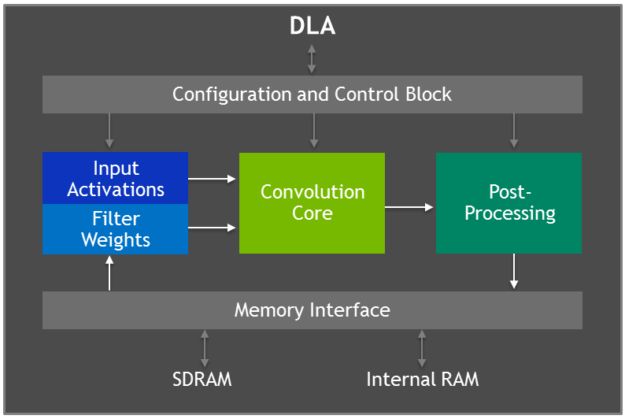
圖2 深度學習加速器(DLA)架構
03
Xavier的軟件平臺
Xavier主要用于邊緣計算的深度神經網絡推理,其支持Caffe、Tensorflow、PyTorch等多種深度學習框架導出的模型。為進一步提高計算效率,還可以使用TensorRT對訓練好的模型利用計算圖優化、算子融合、量化等方法精簡進行優化。Xavier通過TensorRT使開發者能充分的利用GPU中的Tensor core和DLA單元等計算模塊。
04
Xavier推理性能評測
4.1 測試平臺參數
為了測試Xavier的推理性能,我們使用目標檢測算法分別在GeForce 840M、Jetson TX2和Xavier三個計算平臺上進行測試。Jetson TX2工作在默認的MAXP_CORE_ARM模式,Xavier工作在默認的MODE_15W模式。三個計算平臺的關鍵技術參數如表2所述,測試實驗場景如圖3所示。

表2 三個測試平臺參數
圖3 測試環境實景
(作者朱虎明實景拍攝,授權NVIDIA發布)
4.2 Faster R-CNN目標檢測算法介紹
我們利用Faster R-CNN目標檢測算法測試Xavier的推理性能。Faster R-CNN是Fast R-CNN和RPN(區域候選網絡)的融合。RPN使用全卷積網絡(FCN,fully-convolutional network)可以針對生成檢測候選框的任務端到端地訓練,能夠同時預測出目標的邊界和分數。這里使用基于VGG16的Faster R-CNN網絡,其算法主要流程如4所示。Faster R-CNN卷積網絡的結構主要包括:①13個conv層:kernel_size=3,pad=1,stride=1;②13個relu層:激活函數,不改變圖片大小;③4個pooling層:kernel_size=2,stride=2;pooling層會讓輸出圖片是輸入圖片的1/2;
4.3 測試結果介紹
測試時在TensorRT給出的示例代碼sampleFasterR-CNN.cpp上找到推理函數,在其前后添加時間函數gettimeofday(),計算其推理時間。在不同的硬件平臺上重復實驗五次取時間平均值,結果如表3所示。
從實驗結果表可以看出來,Xavier在使用TensorRT進行推理時,性能相比Jetson TX2提升了不少。需要注意的是Xavier使用的TensorRT版本相比TX2版本在軟件架構上有很大的變化,特別是結構性更好。另外,由于時間的原因,我們沒有測試DLA加速的效果。

表3 不同平臺目標檢測計算性能對比
05
總結
Xavier平臺配備了完整的 AI 開發軟件包NVIDIA JetPack SDK,包括最新版本的 CUDA、cuDNN 和 TensorRT等軟件。這些開發軟件使用起來非常方便,再加上Xavier 平臺強大的推理計算能力,Xavier必將在制造、物流、零售、服務等邊緣計算人工智能應用場景大放異彩。
-
神經網絡
+關注
關注
42文章
4807瀏覽量
102765 -
人工智能
+關注
關注
1804文章
48701瀏覽量
246444 -
硬件架構
+關注
關注
0文章
30瀏覽量
9189
原文標題:開發者實測:NVIDIA Jetson AGX Xavier開發套件使用初體驗
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
英特爾FPGA 助力Microsoft Azure機器學習提供AI推理性能
NVIDIA擴大AI推理性能領先優勢,首次在Arm服務器上取得佳績

NVIDIA打破AI推理性能記錄
NVIDIA 在首個AI推理基準測試中大放異彩
JETSON AGX Xavier的相關資料下載
Xavier入門踩坑PWM問題解決方法
怎么做才能通過Jetson Xavier AGX構建android圖像呢?
求助,為什么將不同的權重應用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
英特爾FPGA為人工智能(AI)提供推理性能
基于Xavier SoC的AI計算平臺的自動駕駛處理器芯片
NVIDIA Jetson AGX Xavier應用在AI和
Nvidia 通過開源庫提升 LLM 推理性能
開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能







 工商網監
工商網監
評論