 谷歌手機重磅推出了一款端到端、全神經、基于設備的語音識別器
谷歌手機重磅推出了一款端到端、全神經、基于設備的語音識別器

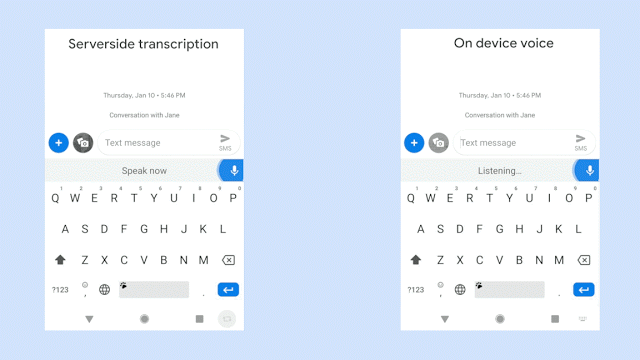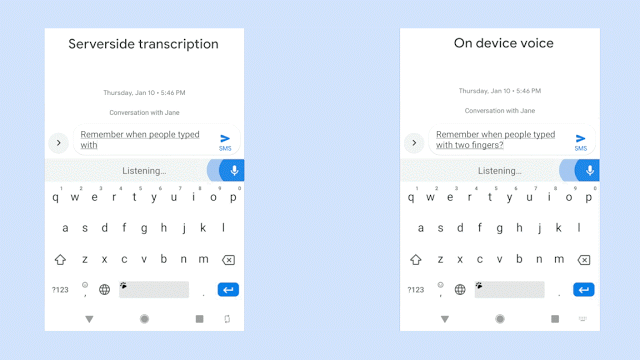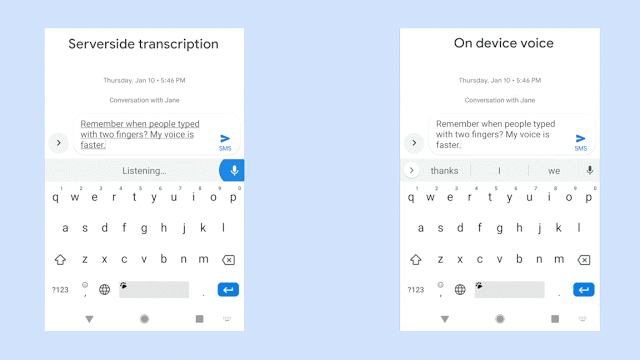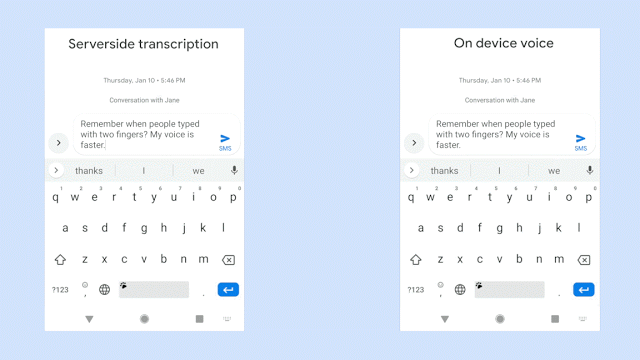
識別延遲一直是設備端語音識別技術需要解決的重大問題,谷歌手機今天更新了手機端的語音識別技術——Gboard,重磅推出了一款端到端、全神經、基于設備的語音識別器,支持Gboard中的語音輸入。通過谷歌最新的(RNN-T)技術訓練的模型,該模型精度超過CTC,并且只有80M,可直接在設備上運行。
2012年,語音識別研究獲得新突破——深度學習可以提高識別的準確性,最早探索這項技術的產品便是谷歌語音搜索了。這標志這語音識別革命的開始,從深層神經網絡(DNNs)到遞歸神經網絡(RNNs),長短期記憶網絡(LSTMs),卷積網絡(CNNs)等等,新的架構和開發質量每年都在快速提升。在發展過程中,識別延遲仍然是攻關難點。
今天,谷歌官方宣布,推出一款端到端、全神經、基于設備的語音識別器,支持Gboard中的語音輸入。
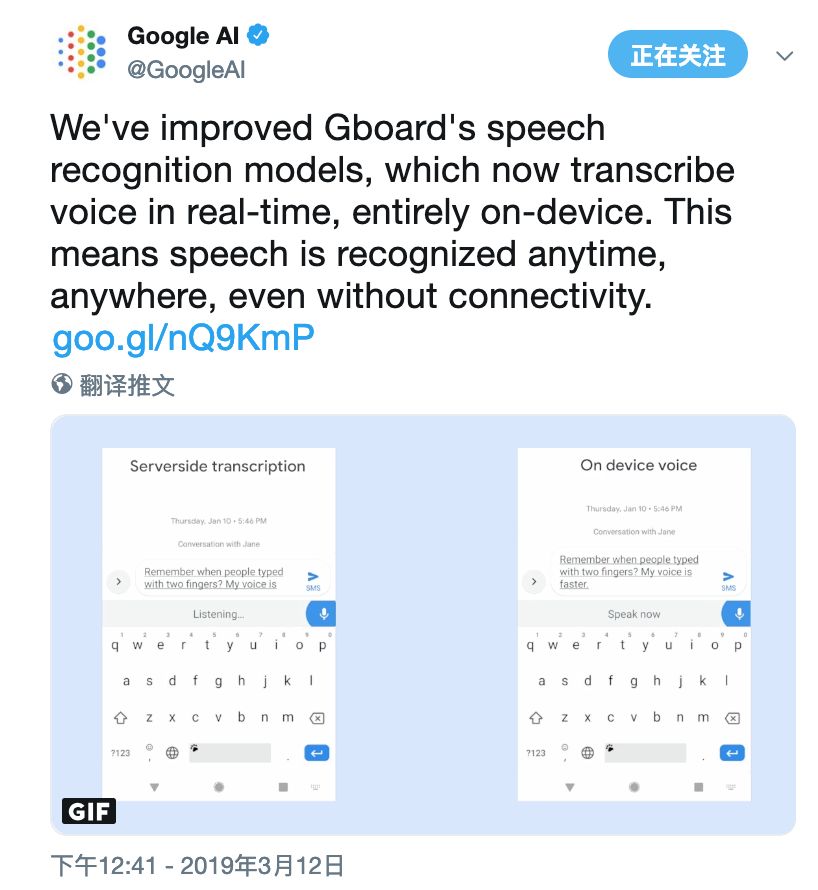
在谷歌最近的論文“移動設備的流媒體端到端語音識別”中,提出了一種使用RNN傳感器(RNN-T)技術訓練的模型,并且可以在手機上實現。這意味著即使你的手機網絡延遲,甚至處于離線狀態,新的識別器也始終可用。
谷歌論文下載鏈接:
https://arxiv.org/abs/1811.06621
該模型以單詞級別運行,也就是說,當你說話時,它會逐個字符地輸出單詞,就像是你自己在敲鍵盤一樣。
語音識別的歷史
最初,語音識別系統由這樣幾個部分組成,將音頻片段(通常為10毫秒幀)映射到音素的聲學模型,將音素連接在一起形成單詞的發音模型,語言模型給出相應的短語。這些組件在早期系統中都是相互獨立的。
大約在2014年,研究人員開始專注于訓練單個神經網絡,將輸入音頻波形直接映射到輸出句子。
也就是說,通過給定一系列音頻特征,生成一系列單詞或字形來建立學習模型,這種seq2seq模型的出現促進了“attention-based ”和“listen-attend-spell” 模型的進展。
這些模型期望在識別準確度上做出突破,但其需要通檢查整個輸入序列來工作,并且在輸入時不允許輸出,這就很難實現實時語音轉錄了。
幾乎同一時間,一個被稱為CTC的獨立技術出現了,成功解決了識別延時的問題,采用CTC技術也就成為邁向RNN-T架構最重要一步。
遞歸神經網絡傳感器
RNN-Ts是一種非注意機制的seq2seq模型。與大多數seq2seq模型(通常需要處理整個輸入序列(在我們的例子中是波形)以產生輸出(句子))不同,RNN-T可以連續處理輸入樣本和流輸出符號,這種屬性對于語音識別尤其友好。在實現過程中,輸出符號是字母表的字符。RNN-T識別器會逐個輸出字符,并在適當的位置輸入空格。它通過反饋循環執行此操作,該循環將模型預測的符號反饋到其中,以預測下一個符號,如下圖所示。
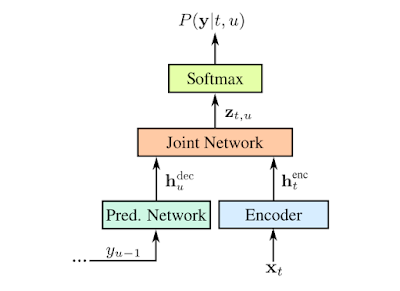
訓練這樣一只有效運行的模型已經很困難,并且隨著我們開發的進展——進一步將單詞錯誤率降低了5%,模型變得更加計算密集。為了解決這個問題,我們開發了并行實現,使得RNN-T損失功能可以在Google的高性能CloudTPU v2硬件上大批量運行。這在訓練中實現了約3倍的加速。
離線識別
在傳統的語音識別引擎中,我們上面描述的聲學、發音和語言模型會被“組合”成一個大的圖搜索算法。當語音波形被呈現給識別器時,“解碼器”在給定輸入信號的情況下,會在該圖中搜索相似度最高的路徑,并讀出該路徑所采用的字序列。
通常,解碼器采用基礎模型的有限狀態傳感器(FST)表示。然而,盡管有復雜的解碼技術,圖搜索算法仍然非常之大,以我們的模型為例,可以達到了2GB。如此大的模型根本無法在移動設備上運行,因此這種方法需要在連線時才能正常工作。
為了提高語音識別的有效性,我們試圖通過直接在設備上運行新模型,來避免通信網絡的延遲和不可靠性。因此,我們的端到端方法不需要在大型解碼器圖上進行搜索。
相反,只通過單個神經網絡的波束搜索進行。我們訓練的RNN-T提供與傳統的基于服務器的模型相同的精度,但只有450MB,可以更加智能地使用參數和打包信息。然而,即使在今天的智能手機上,450MB也不小了,并且,通過如此龐大的網絡傳輸信號依然很慢。
進一步的,我們通過使用參數量化和混合內核技術來縮小模型,我們在2016年開發了這一技術并在TensorFlow精簡版庫上公開提供了模型優化工具包。
模型量化相對于訓練的浮點模型提供4倍壓縮,在運行時提供4倍加速,使我們的RNN-T比單核上的實時語音運行得更快。壓縮后,我們模型的最終大小達到了80MB。
終于,當當當,我們的新型設備端神經網絡Gboard語音識別器上線了。最初的版本,我們僅提供英語語言,適配所有Pixel手機。鑒于行業趨勢,隨著專業硬件和算法改進的融合,我們希望這里介紹的技術可以很快用于更多語言和更廣泛的應用領域。
-
谷歌
+關注
關注
27文章
6231瀏覽量
108119 -
語音識別
+關注
關注
39文章
1780瀏覽量
114223 -
深度學習
+關注
關注
73文章
5561瀏覽量
122793
原文標題:全離線,無延遲!谷歌手機更新語音識別系統,模型大小僅80M
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中基于規則的決策和端到端大模型有何區別?
端到端自動駕駛技術研究與分析
準確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni

黑芝麻智能端到端算法參考模型公布
爆火的端到端如何加速智駕落地?
Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
端到端InfiniBand網絡解決LLM訓練瓶頸

端到端語音解決方案的Renesas RA8M1語音套件

恩智浦完整的Matter端到端解決方案






 工商網監
工商網監
評論