") 準(zhǔn)確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni
準(zhǔn)確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni
GPT-4o 提供的全雙工語音對話帶來了一股研究熱潮,目前諸多工作開始研究如何利用 LLM 來實(shí)現(xiàn)端到端的語音到語音(Speech-to-Speech)對話能力,但是目前大部分開源方案存在以下兩個問題:
LLM 災(zāi)難性遺忘:由于現(xiàn)有方案在語音模態(tài)與 LLM 進(jìn)行對齊時,會或多或少對 LLM 進(jìn)行微調(diào),但由于要采集到與 LLM 本身訓(xùn)練的文本數(shù)據(jù)同等量級的語音數(shù)據(jù)是非常困難的,所以這一微調(diào)過程往往會導(dǎo)致 LLM 出現(xiàn)遺忘現(xiàn)象,造成 LLM 的聰明度下降
語音問答(Spoken Question Answering)任務(wù)的評估:多數(shù)工作對于語音問答的準(zhǔn)確性并沒有進(jìn)行定量評估,從已有的一些評估結(jié)果也可以看出同一模型語音問答和文本問答相比準(zhǔn)確性會有明顯的差距
針對上述這些問題,近日騰訊&西工大&南大的研究人員提出了一種低延遲的端到端語音雙工對話模型 Freeze-Omni(VITA 大模型系列第二個工作),其可以在完全凍結(jié) LLM 的情況下,為 LLM 接入語音輸入和輸出,使其能夠支持端到端的語音對話能力,且通過一系列優(yōu)化使得其具備低延遲的雙工對話能力,其主要特性如下:
在整個訓(xùn)練過程中,LLM 的參數(shù)被完全凍結(jié),確保大型語言模型的知識能力被完全保留;
訓(xùn)練過程中所依賴的數(shù)據(jù)規(guī)模較小,消耗的計(jì)算資源也較少。Freeze-Omni 僅需要文本-語音配對數(shù)據(jù)(如 ASR 和 TTS 訓(xùn)練數(shù)據(jù),比較容易獲得)以及僅少量的文本模態(tài)的問答數(shù)據(jù),語音問答準(zhǔn)確性顯著超越 Moshi 與 GLM-4-Voice 等目前 SOTA 的模型;
Freeze-Omni 可以支持任何具有文本模態(tài)的(多模態(tài))大語言模型,能夠保留基底大語言模型的能力,如提示服從和角色扮演等。此外,如果有必要改變大語言模型的領(lǐng)域或者回應(yīng)方式,只需要用相應(yīng)的文本數(shù)據(jù)對大語言模型進(jìn)行微調(diào)即可,不需要采集大量語音的問答和對話數(shù)據(jù)。

論文標(biāo)題:
Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM
論文鏈接:
https://arxiv.org/abs/2411.00774
項(xiàng)目主頁:
https://freeze-omni.github.io/
開源代碼:
https://github.com/VITA-MLLM/Freeze-Omni
三階段訓(xùn)練策略實(shí)現(xiàn)語音輸入輸出能力
Freeze-Omni 的整體結(jié)構(gòu)如圖 1 所示,其包含有語音編碼器(Speech Encoder)和語音解碼器(Speech Decoder)以及基底 LLM 三部分。 在運(yùn)行過程中,流式的語音輸入通過語音編碼器形成分塊(Chunk)特征,然后通過 Adapter 連接到 LLM,LLM 生成的 Hidden State 和文本 Token 的在分塊分割后,分別以塊的形式送入非自回歸前綴語音解碼器(NAR Prefix Speech Decoder)和非自回歸語音解碼器(NAR Speech Decoder)以進(jìn)行 Prefill 操作。 最后自回歸語音解碼器(AR Speech Decoder)將會完成 Generate 操作以生成語音 Token,并由 Codec Decoder 將其流式解碼為語音信號輸出。
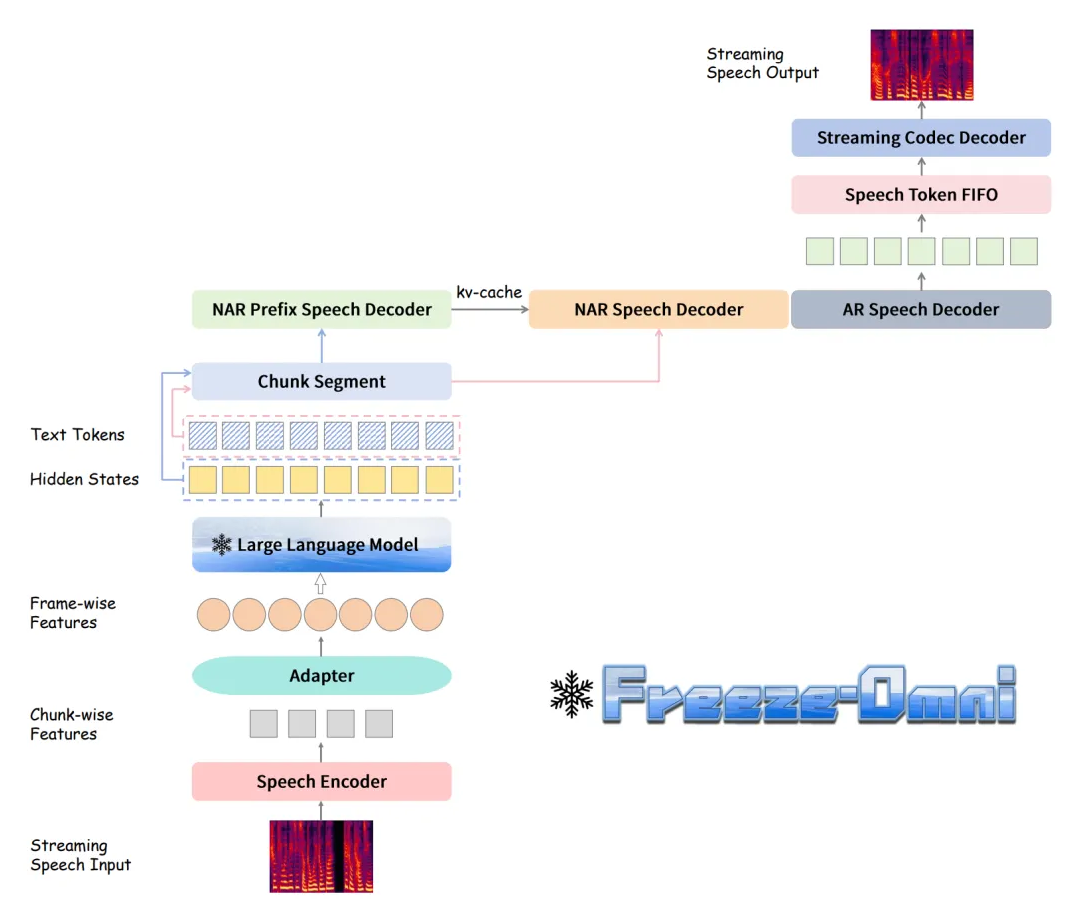
▲ 圖1. Freeze-Omni框架圖 Freeze-Omni 各個模塊的三階段訓(xùn)練策略如下: 流式語音編碼器的三階段訓(xùn)練:如圖 2 所示,第一階段(a)會先使用 ASR 數(shù)據(jù)訓(xùn)練一個具有 ASR 能力的語音編碼。 第二階段(b)會以 ASR 任務(wù)為優(yōu)化目標(biāo),將語音編碼器與 LLM 做模態(tài)對齊,這個過程中 LLM 是處于凍結(jié)狀態(tài)的。 第三階段(c)會使用由 TTS 系統(tǒng)合成的語音輸入-文本回答的多輪 QA 數(shù)據(jù)進(jìn)行訓(xùn)練,這里會使用第二階段訓(xùn)練好的語音編碼器,但是其參數(shù)保持凍結(jié)以保留其語音魯棒性,而可訓(xùn)練的參數(shù)只有每個問題前的 Prompt Embedding,用于指導(dǎo) LLM 從 ASR 任務(wù)遷移到 QA 任務(wù)中。
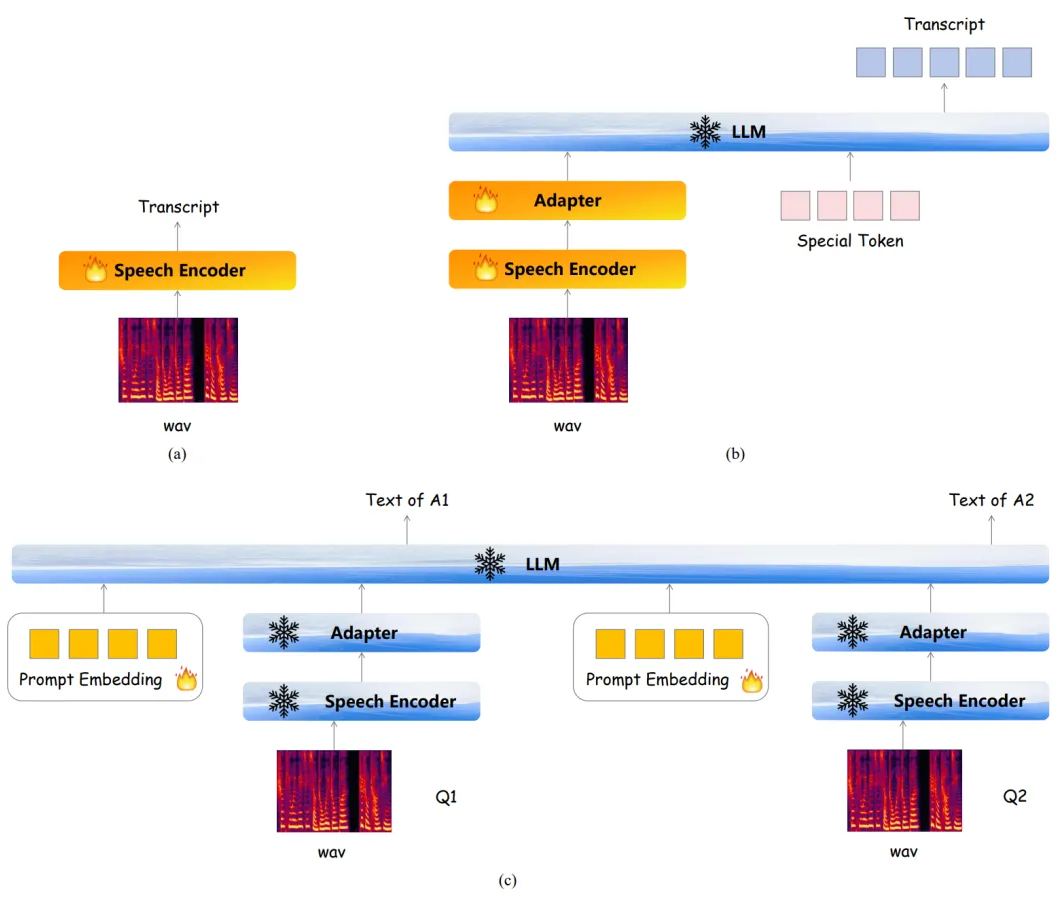
▲ 圖2. 流式語音編碼器的三階段訓(xùn)練示意圖 流式語音解碼器的三階段訓(xùn)練:如圖 3 所示,第一階段(a)會先訓(xùn)練一個單碼本的語音編解碼模型,使用單碼本的目的主要是為了降低計(jì)算復(fù)雜度和時延。 第二階段(b)將會訓(xùn)練 NAR 語音編碼器和 AR 語音編碼器,這里會使用文本-語音的 TTS 數(shù)據(jù),其文本會通過基底 LLM 的 Tokenizer 轉(zhuǎn)化為 Token,再經(jīng)過基底 LLM 的 Embedding 層轉(zhuǎn)化為文本特征,這個過程中 Embedding 的參數(shù)是凍結(jié)的,訓(xùn)練目標(biāo)的語音 Token 是由第一階段的語音編碼器提供。 第三階段(c)將會凍結(jié)第二階段訓(xùn)練得到的所有網(wǎng)絡(luò),但同時加入了一個 NAR Prefix 語音編碼器,其用于接受 LLM 輸出的 Hidden State,并將輸出的 kv-cache 作為第二階段模型的初始 kv-cache,該過程使用的數(shù)據(jù)是文本輸入-語音輸出的 QA 數(shù)據(jù),主要目的是為了使得語音編碼器遷移到 LLM 的輸出領(lǐng)域中。
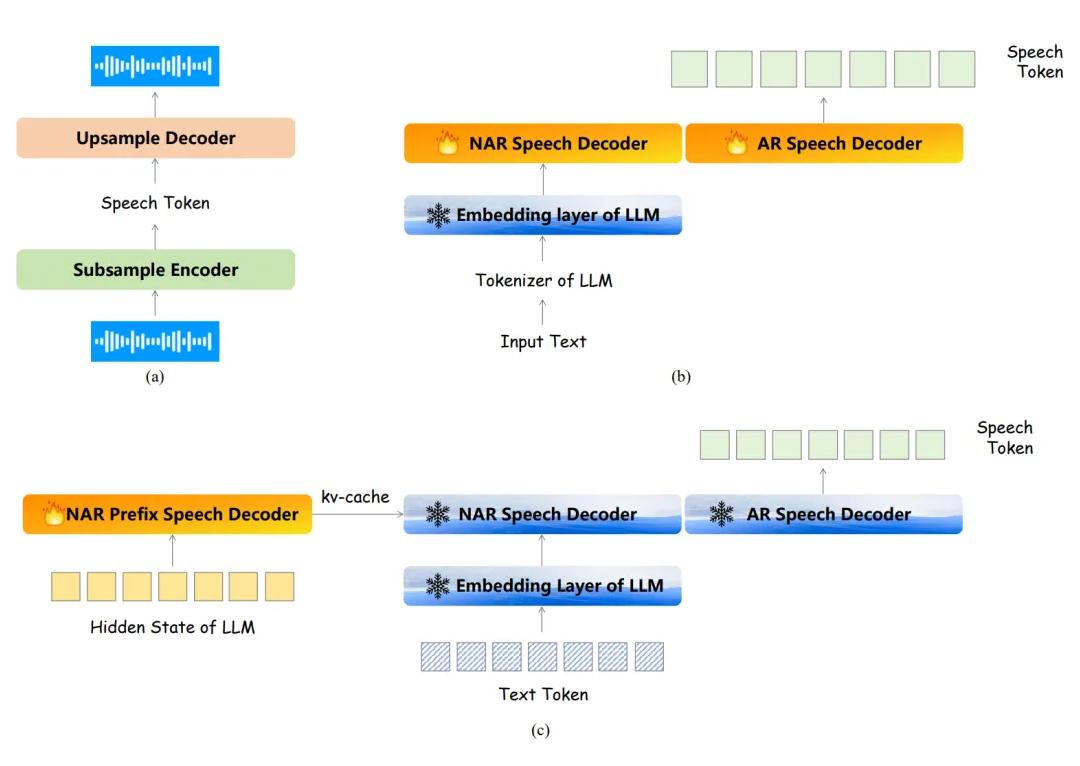
▲ 圖3. 流式語音解碼器的三階段訓(xùn)練示意圖 雙工對話的狀態(tài)標(biāo)簽訓(xùn)練:如圖 4 所示,為了實(shí)現(xiàn)雙工交互,F(xiàn)reeze-Omni 在語音編碼器訓(xùn)練的第三階段中,會為每個 Chunk 的最后一個語音幀對應(yīng)的 LLM 輸出 Hidden State 加入一個額外的分類層進(jìn)行多任務(wù)訓(xùn)練,其目的主要是為了輸出狀態(tài)標(biāo)簽。 當(dāng)使用 VAD 激活語音流輸入后,狀態(tài)標(biāo)簽 0 表示 LLM 將會繼續(xù)接受語音 Chunk 的輸入,狀態(tài)標(biāo)簽 1 表示 LLM 將會停止接收語音,且會打斷用戶并進(jìn)入 LLM 的 Generate 階段輸出回復(fù),狀態(tài)標(biāo)簽 2 表示 LLM 也會停止接收語音,但不會打斷用戶,相當(dāng)于對這次語音激活做了拒識。
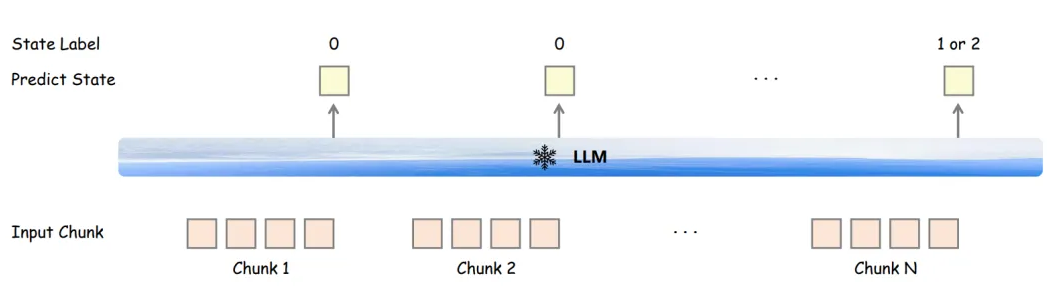
▲ 圖4. 全雙工對話的狀態(tài)標(biāo)簽訓(xùn)練示意圖
模型性能測評
訓(xùn)練配置:Freeze-Omni 在訓(xùn)練過程中,使用了開源 Qwen2-7B-Instruct 作為基底模型,語音編碼器在訓(xùn)練過程中使用了 11 萬小時中文英文混合的 ASR 數(shù)據(jù),語音解碼器訓(xùn)練過程使用了 3000 小時由 TTS 系統(tǒng)合成的文本-語音數(shù)據(jù),所提到的 QA 數(shù)據(jù)是由 6 萬條從 moss-003-sft-data 中抽取的多輪對話經(jīng)過 TTS 系統(tǒng)合成得到的。 語音輸入理解能力評估:Freeze-Omni 提供了其在常見的英文測試集上的 ASR 性能測試結(jié)果,從中可以看出,其 ASR 準(zhǔn)確性處于較為領(lǐng)先的水平。
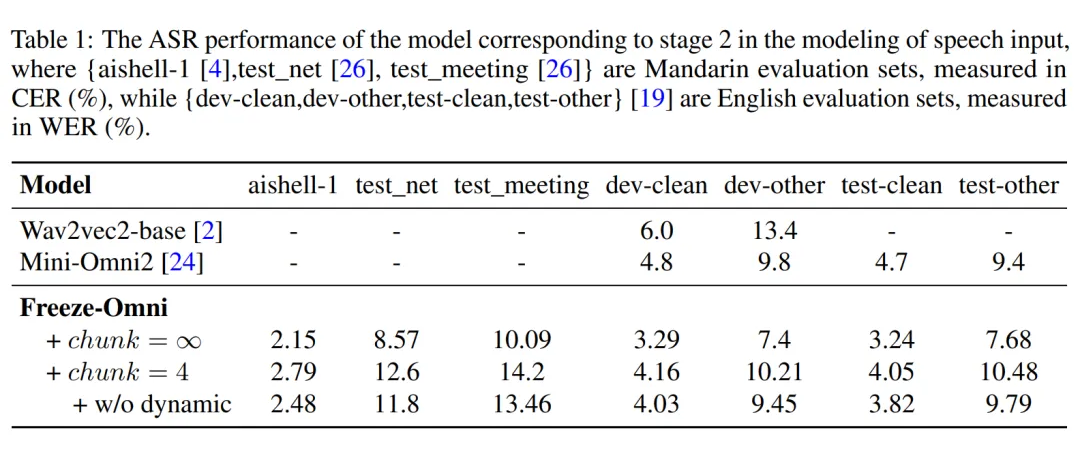
▲ 圖5. 語音理解能力評估 語音輸出質(zhì)量評估:Freeze-Omni 提供了其在 1000 條 LLM 輸出的 Hidden State 與 Text Token 上語音解碼器生成的語音在使用 ASR 模型測試得到的詞錯誤率(CER),從結(jié)果中可以看出 NAR Prefix 語音解碼器的引入會有效降低詞錯誤率,提高生成語音的質(zhì)量。
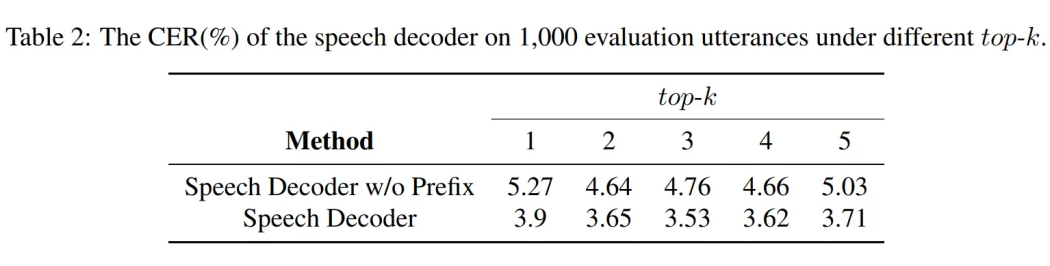
▲ 圖6. 語音輸出質(zhì)量評估 語音問答準(zhǔn)確性評估:Freeze-Omni 提供了其在 LlaMA-Questions, Web Questions, 和 Trivia QA 三個集合上的語音問答準(zhǔn)確率評估。 從結(jié)果中可以看出 Freeze-Omni 的準(zhǔn)確率具有絕對的領(lǐng)先水平,超越 Moshi 與 GLM-4-Voice 等目前 SOTA 的模型,并且其語音模態(tài)下的準(zhǔn)確率相比其基底模型 Qwen2-7B-Instruct 的文本問答準(zhǔn)確率而言,差距明顯相比 Moshi 與其文本基底模型 Helium 的要小,足以證明 Freeze-Omni 的訓(xùn)練方式可以使得 LLM 在接入語音模態(tài)之后,聰明度和知識能力受到的影響最低。
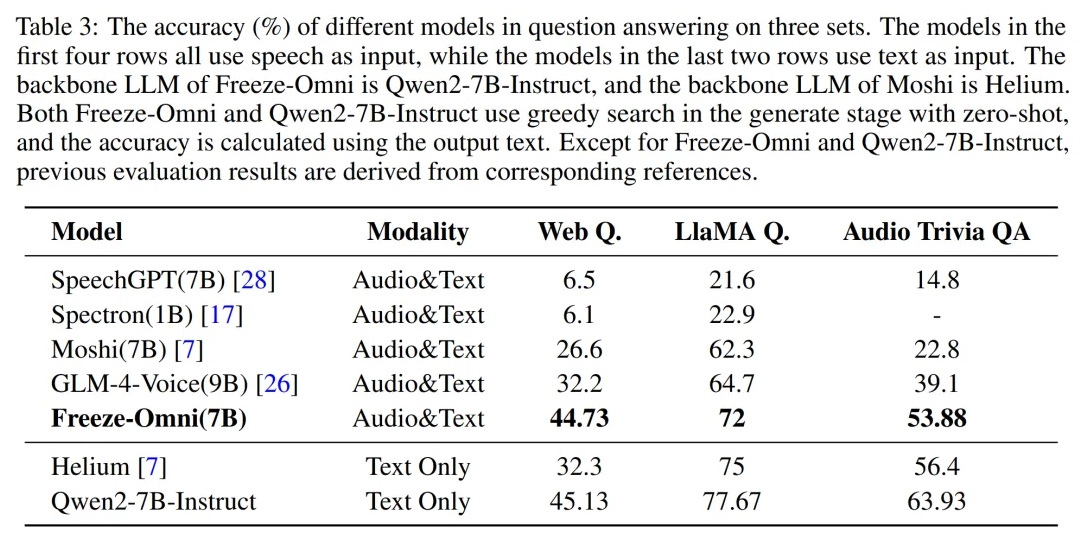
▲ 圖7. 語音問答準(zhǔn)確性評估 系統(tǒng)延遲評估:Freeze-Omni 還提供了端到端時延分析(即用戶說完后到 LLM 輸出音頻的時間差),作者將其分為了可統(tǒng)計(jì)時延和不可統(tǒng)計(jì)時延兩部分,其中可統(tǒng)計(jì)時延的總時長平均數(shù)僅為 745ms,而作者也提到如果經(jīng)過測量考慮到網(wǎng)絡(luò)延遲和不可統(tǒng)計(jì)時延部分,則系統(tǒng)的平均響應(yīng)時延在 1.2s 左右,在行業(yè)內(nèi)仍為領(lǐng)先水平。

▲ 圖8. 系統(tǒng)延遲評估
-
模型
+關(guān)注
關(guān)注
1文章
3479瀏覽量
49932 -
LLM
+關(guān)注
關(guān)注
1文章
318瀏覽量
671
原文標(biāo)題:準(zhǔn)確性超Moshi和GLM-4-Voice!端到端語音雙工模型Freeze-Omni
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
自動駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?
階躍星辰發(fā)布國內(nèi)首個千億參數(shù)端到端語音大模型
利用OpenVINO部署GLM-Edge系列SLM模型
黑芝麻智能端到端算法參考模型公布
智譜推出四個全新端側(cè)模型 攜英特爾按下AI普及加速鍵
如何提升ASR模型的準(zhǔn)確性
連接視覺語言大模型與端到端自動駕駛

如何評估 ChatGPT 輸出內(nèi)容的準(zhǔn)確性
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論