") 輕松上手邊緣AI:MemryX MX3芯片與Orange Pi 5 Plus的完美結(jié)合
輕松上手邊緣AI:MemryX MX3芯片與Orange Pi 5 Plus的完美結(jié)合

一、概述
當(dāng)今 AI 技術(shù)已無處不在,從智慧城市、工業(yè) 4.0 到自動(dòng)駕駛與智慧醫(yī)療,人工智能不再只是理論,而是推動(dòng)世界進(jìn)步的核心引擎。然而,AI真正的挑戰(zhàn)在于實(shí)時(shí)反應(yīng)與低功耗運(yùn)算,這也是邊緣計(jì)算(Edge Computing)崛起的關(guān)鍵原因。雖然云端AI計(jì)算具備強(qiáng)大運(yùn)算能力,但面臨數(shù)據(jù)傳輸延遲與高帶寬需求的瓶頸,導(dǎo)致許多需要毫秒級(jí)決策的應(yīng)用,如自動(dòng)駕駛車輛的行車識(shí)別、工業(yè)機(jī)械臂控制、監(jiān)控系統(tǒng)實(shí)時(shí)警報(bào),無法依賴云端響應(yīng)。
為了讓 AI 運(yùn)算更接近數(shù)據(jù)源并提升實(shí)時(shí)性,MemryX提出了專為邊緣計(jì)算設(shè)計(jì)的AI加速解決方案。MemryX MX3 AI加速卡采用 BF16 浮點(diǎn)計(jì)算架構(gòu),突破傳統(tǒng)邊緣設(shè)備僅支持整數(shù)運(yùn)算(INT8)的限制,在圖像識(shí)別、語音處理與目標(biāo)檢測(cè)等高精度AI任務(wù)上展現(xiàn)卓越性能,提供5 TFLOPS/W的能效比與高達(dá)20 TFLOPS的運(yùn)算能力,實(shí)現(xiàn)低延遲、高精度的AI推理。
除此之外,MemryX 也打造完整的開發(fā)生態(tài)系統(tǒng),讓開發(fā)者能夠無縫整合 AI 模型的設(shè)計(jì)、編譯、部署與優(yōu)化包含 Neural Compiler(將 AI 模型轉(zhuǎn)換為 DFP 格式)、Simulator(預(yù)測(cè)吞吐量與延遲)、Benchmark(性能基準(zhǔn)測(cè)試)以及 Viewer(GUI 可視化工具),讓 AI 應(yīng)用開發(fā)更加直觀高效。通過這些即插即用的開發(fā)工具,MemryX 能夠幫助開發(fā)者快速部署 AI 模型,靈活適配 TensorFlow、PyTorch、ONNX 等主流框架,無需重新訓(xùn)練模型即可應(yīng)用于各類邊緣場(chǎng)景。
隨著 AI 與 IoT 技術(shù)的融合加速,MemryX 以強(qiáng)大的計(jì)算能力與低功耗設(shè)計(jì),驅(qū)動(dòng) AI 邊緣計(jì)算新時(shí)代,為智慧城市、工業(yè)自動(dòng)化與 AIoT 設(shè)備提供創(chuàng)新解決方案。MemryX 的目標(biāo)不僅是提升 AI 推理性能,更是讓 AI 計(jì)算變得簡單、靈活、高效,成為 AI 開發(fā)者手中的關(guān)鍵武器,推動(dòng)邊緣智能技術(shù)的快速演進(jìn)。
二、開發(fā)套件
MemryX 提供了一套軟件開發(fā)工具包(Software Development Kit)其中包含了編譯工具(Neural Compiler Tool)、芯片模擬工具(Simulator Tool)、加速器應(yīng)用工具(Accelerator)、可視化界面(Viewer)。目前此套件僅能應(yīng)用于 PC 端,并支持Ubuntu 與 Windows 操作系統(tǒng),其安裝方式請(qǐng)按照以下步驟操作:
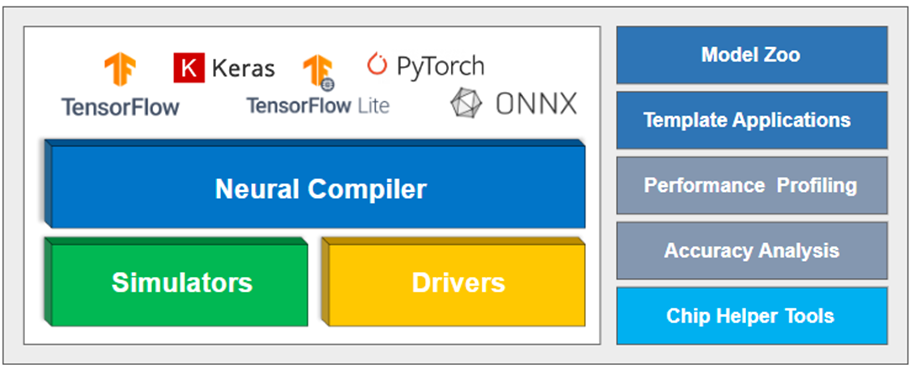
SDK 軟件開發(fā)套件示意圖 – 資料來源官方網(wǎng)站
資料來源 - 官方網(wǎng)站
1. 編譯器(Neural Compiler)
神經(jīng)編譯器(Neural Compiler)為 MemryX 制式化的編譯工具(建議在 PC 電腦上使用)能夠?qū)⒏鞣N模塊格式轉(zhuǎn)換編譯成DFP格式(Dataflow Program),通過此格式能夠告訴 MX3 芯片如何配置核心以及如何將傳入的模塊架構(gòu)與參數(shù)信息進(jìn)行處理。同時(shí)支持多種機(jī)器學(xué)習(xí)框架,如TensorFlow、Keras、ONNX、Pytorch等。
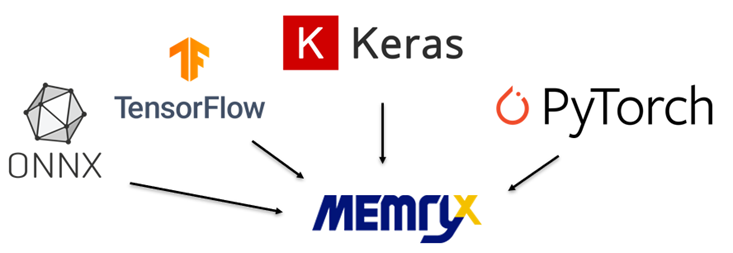
各模塊格式轉(zhuǎn)換為 MemryX DFP 格式示意圖
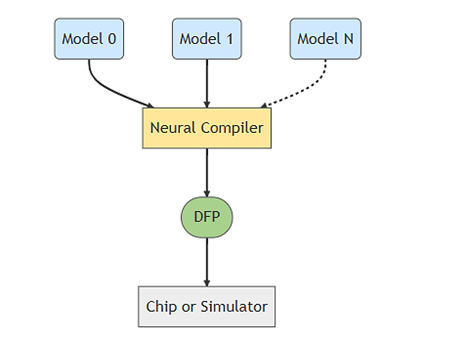
編譯器細(xì)節(jié)能夠分為四層,如下圖所示,依次為
(1)框架接口:將模塊形式轉(zhuǎn)換為內(nèi)部圖(internal graph)的形式。
(2)圖處理:通過重新拆解并優(yōu)化內(nèi)部圖。
(3)Mapper:將內(nèi)部圖映射至最佳可配置的 MX3 硬件資源,以最大吞吐量(FPS)為目標(biāo)。
(4)匯編器:生成 DFP 文件。

DFP文件生成示意圖
來源出處 Memry 文件
單一模型應(yīng)用(Single-Model)
使用方式:
句子: $ mx_nc -v -m
-m, --model : 設(shè)置實(shí)際的模塊路徑,支持 .h5 / .pb / .py / .onnx / .tflite 格式
-g, --chip_gen:設(shè)置芯片的世代(默認(rèn)值:mx3)
-c, --num_chips:設(shè)置芯片的數(shù)量(默認(rèn)值:1)
-v:查看編譯器程序信息。
※ 一顆 MX3 芯片約可以處理 10 MB 的數(shù)據(jù)量。
※ 更多操作,請(qǐng)參考官網(wǎng)軟件開發(fā)工具包。
多模型應(yīng)用(Multi-Model)
在眾多使用AI應(yīng)用場(chǎng)景下,難免會(huì)需要將多種模塊應(yīng)用至一個(gè)模塊的情境例如檢測(cè)人臉表情判斷,需要先定位到人臉位置,再通過判斷人臉的喜怒哀樂進(jìn)行分類。
使用方法:
$ mx_nc -v -m
來源出處 Memry 開發(fā)者網(wǎng)站
多芯片應(yīng)用(Multi-Chip)
編譯器會(huì)自動(dòng)將給定模型的工作負(fù)載分配到可用芯片上。
使用方法:
$ mx_nc -v-c 2-m
來源出處 Memry 開發(fā)者網(wǎng)站
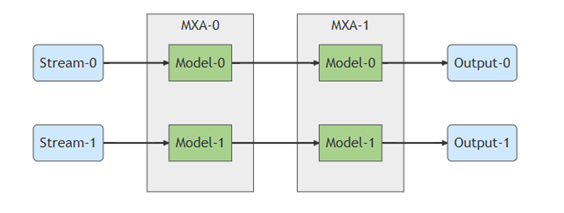
多流(Multiple Input Streams)& 共享輸入流(Shared Input Stream)應(yīng)用
通常每個(gè)模型是獨(dú)立使用一個(gè)數(shù)據(jù)流。
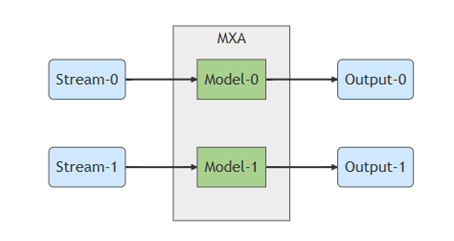
來源出處 Memry 開發(fā)者網(wǎng)站
在多個(gè)模型且相同輸入流的情況下,編譯器允許共同使用同一個(gè)輸入。
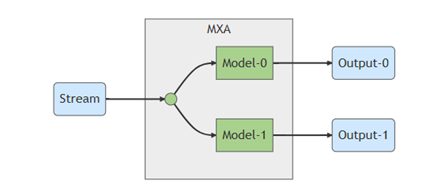
來源出處 Memry 開發(fā)者網(wǎng)站
使用方法:
$ mx_nc -v -m --models_share_ifmap
改變輸入形狀(reshape)
以下示例展示了如何從命令行為傳遞到神經(jīng)編譯器的單輸入模型的典型情況提供輸入形狀。
使用方式(單一模塊):
$ mx_nc -m -是“300,300,3”
使用方式(多模塊):
$ mx_nc -m -是“224,224,3”“300,300,3”
模組裁剪(Model Cropping)
在使用 AI 芯片時(shí),難免會(huì)遇到必須要移除特定的架構(gòu)層或運(yùn)算單元(operators)才能更有效地發(fā)揮效能。因此,MemryX 也提供了這一功能,可以將模塊拆分為圖像前處理(Pre-Processing)、神經(jīng)網(wǎng)絡(luò)架構(gòu)處理(Neural Network)、圖像后處理(Post-Processing)等架構(gòu),能夠?qū)⑵浞止そ唤o圖像處理單元 ISP(image signal processor)、圖形處理器 GPU 或中央處理器 CPU,以實(shí)現(xiàn)更高效的異構(gòu)多核運(yùn)算。
自動(dòng)裁剪使用方式:
$ mx_nc -g -m -v --autocrop -so
-- autocrop:系統(tǒng)自動(dòng)裁剪前后處理。
手動(dòng)裁剪使用方式:
$ mx_nc -m -v --so --outputs -v -so
-is, --input_shapes:設(shè)置輸入端大小
--input_format:設(shè)置輸入端格式(默認(rèn)值:BF16)
--inputs:指定預(yù)處理裁剪框架的名稱
--outputs:指定后處理裁剪框架的名稱
-so:查看編譯器程序的優(yōu)化步驟
其運(yùn)行結(jié)果如下,從圖片上可以查看計(jì)算單元、權(quán)重內(nèi)存等的使用量。
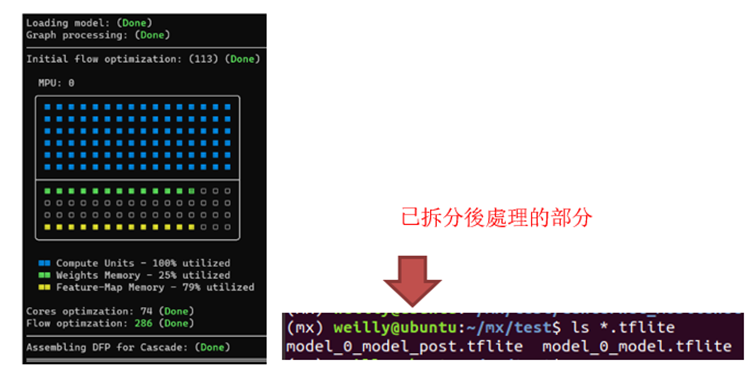
模塊裁剪的示意圖
2. 基準(zhǔn)測(cè)試 (Benchmark)
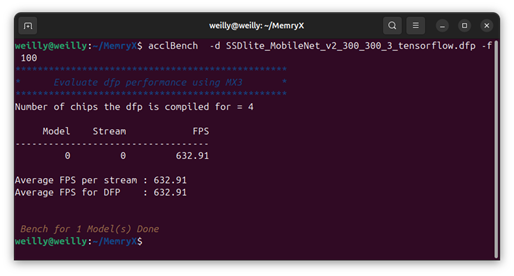
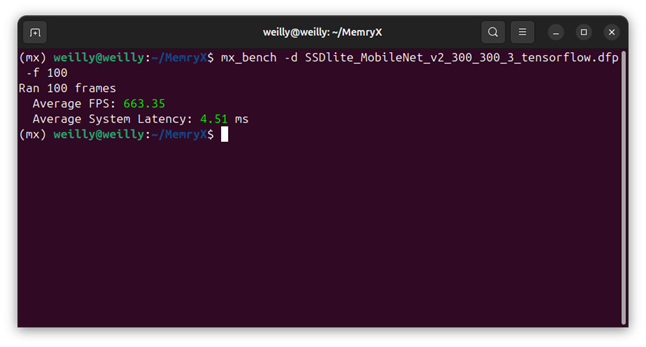
基準(zhǔn)測(cè)試(Benchmark)是 AI 芯片的標(biāo)準(zhǔn)工具之一,用來測(cè)試運(yùn)行模塊的性能。其中 MemryX 設(shè)計(jì)了用于 C/C++ 和 Python 的基準(zhǔn)測(cè)試工具,分別是 acclBench 和 mx_bench。可以使用這些工具來測(cè)量 FPS 和延遲數(shù)據(jù)。
下載測(cè)試模塊SSDlite-MobileNet-v2_300_300_3_tensorflow.zip
$ unzipSSDlite_MobileNet_v2_300_300_3_tensorflow.zip
(2)acclBench(C++)
acclBench [-h] [-v] [-d] [-m] [-n] [-f] [-iw] [-ow] [-device_ids] [-ls]
指令:
$ acclBench -d SSDlite_MobileNet_v2_300_300_3_tensorflow.dfp -f 100
(3) mx_bench (Python)
$mx_bench [-h] [-v] [-d] [-f]
3. 模擬器(Simulator)
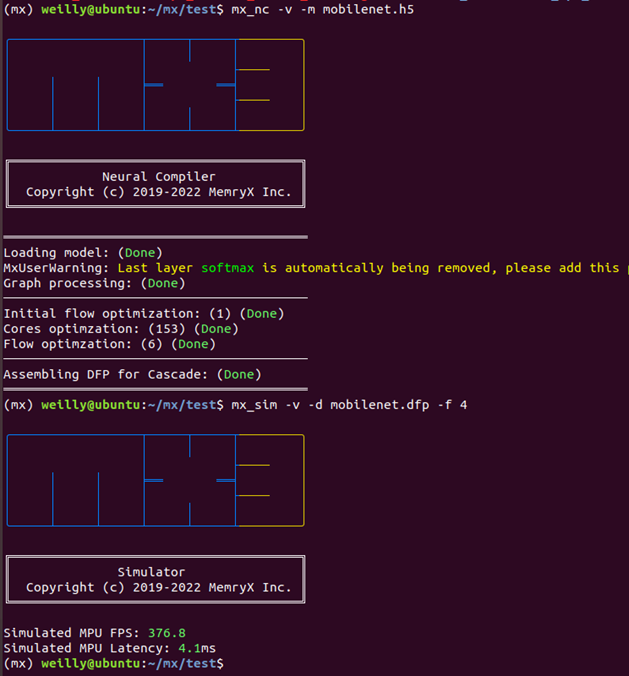
模擬器(Simulator)為 MemryX 制式化的工具(用于 PC 電腦使用)提供高精度的模擬性能,能夠準(zhǔn)確模擬 MemryX AI 芯片的性能,并展示 FPS(幀數(shù))和 Latency(延遲)的測(cè)試數(shù)據(jù)。
使用方法:
$ mx_sim -v -d -f 4
-d, --dfp:設(shè)置實(shí)際的 DFP 文件路徑
-f, --frames:設(shè)置模擬的幀數(shù)(隨機(jī)數(shù)值)
-v:查看編譯器程序信息。
--no_progress_bar:關(guān)閉進(jìn)度條
--sim_directory:模擬的文件夾路徑(默認(rèn)值:./simdir)
※ 模擬器無法指定芯片的數(shù)量,必須由 dfp 所設(shè)置的芯片大小來決定。
模擬工具的示意圖
來源出處 Memry 文件
4. 視覺化工具(Viewer)
可視化工具(Viewer)是 MemryX 提供的 GUI 界面,包含上述編譯器、模擬器、加速器。
使用方法:
$ mx_viewer
編譯器 :
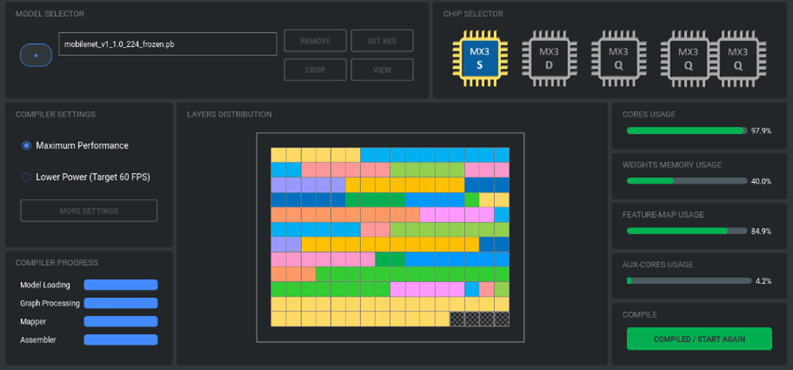
步驟1:選擇神經(jīng)網(wǎng)絡(luò)模型
步驟 2:選擇目標(biāo)系統(tǒng)

步驟 3:編譯模塊
步驟4:運(yùn)行結(jié)果
模擬器 :
步驟 1:設(shè)置張數(shù)

步驟 2:運(yùn)行模擬
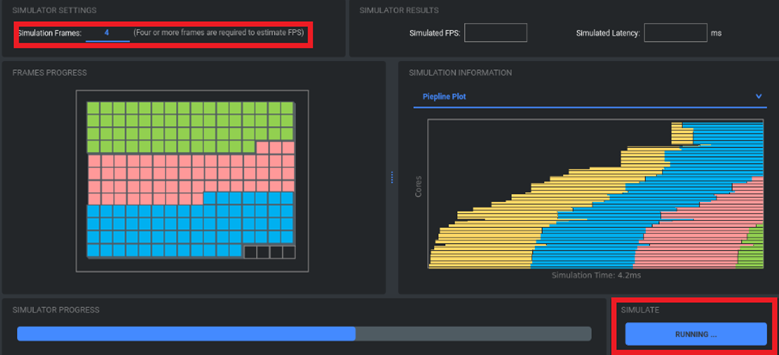
步驟 3:查看結(jié)果
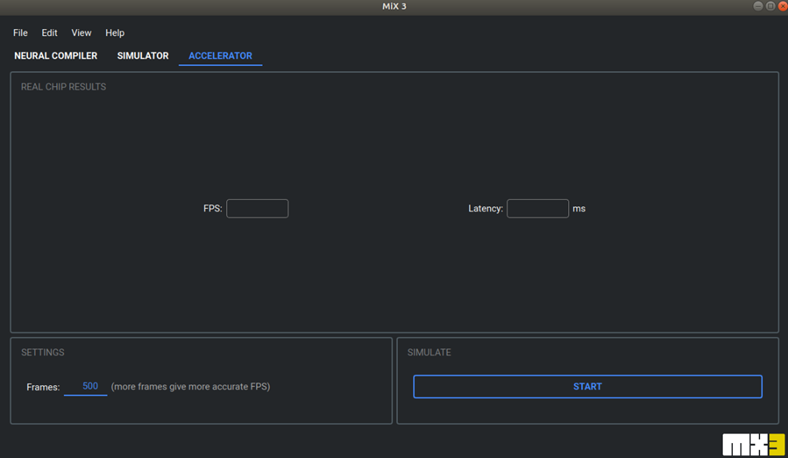
加速器
需要連接上實(shí)體的 MX3 EVK,其操作方式與模擬器相似。

5. 檢視器(DFP Inspect)
檢視器(DFP Inspect)為 MemryX 提供的一套檢查 dfp 文件的工具。
使用方法:
$ dfp_inspect
輸出信息
● DFP
■ 使用的編譯器版本
■ 編譯日期和時(shí)間
■ 目標(biāo)芯片數(shù)量
■ 目標(biāo)架構(gòu)生成
■ 模擬器配置與 MXA 硬件配置的文件大小(以 MB 為單位)
● 編譯模型的文件名
● 主動(dòng)輸入和輸出端口配置
示例 :

6. 開源模塊資源(Model Zoo)
原廠官網(wǎng)也提供豐富的開源模塊資源與分析,如下圖所示。
模塊分析
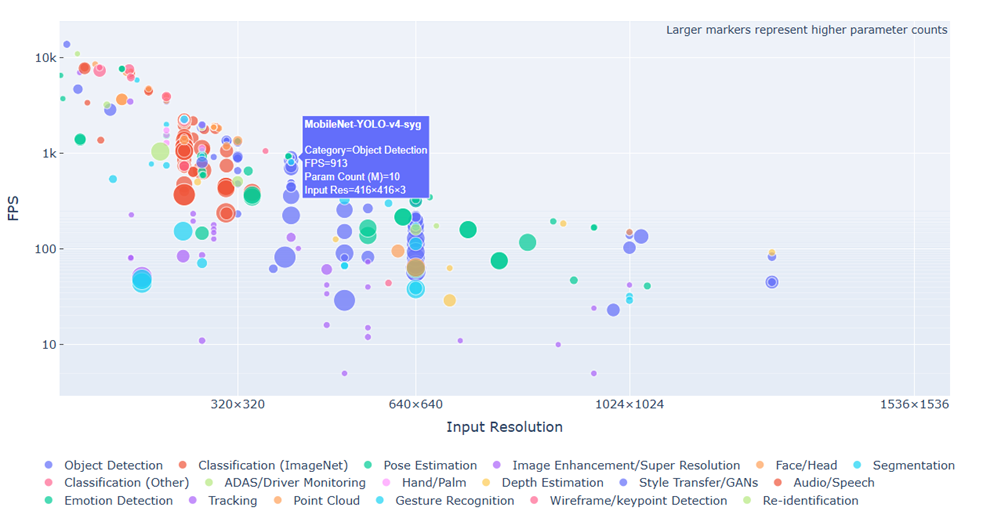
來源出處 Memry 開發(fā)者網(wǎng)站
模塊資源
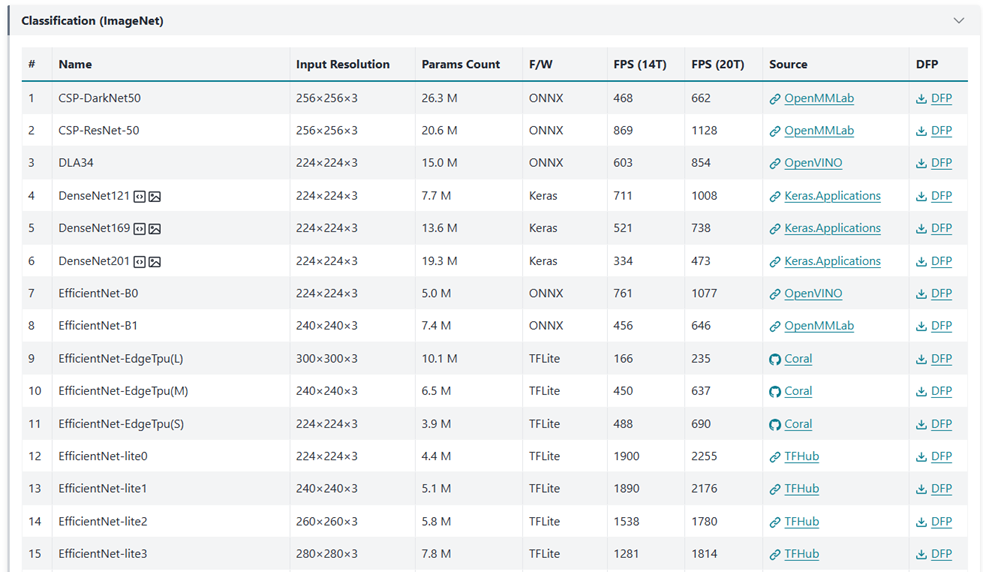
來源出處 Memry 開發(fā)者網(wǎng)站
三、結(jié)語
MemryX MX3+ AI 加速卡以其卓越的計(jì)算性能與低功耗特性,為 AI 開發(fā)者提供了一個(gè)強(qiáng)大且靈活的解決方案。更重要的是,內(nèi)置完整的軟件開發(fā)工具鏈,讓開發(fā)者能夠快速部署 AI 模型,同時(shí)輕松調(diào)整前后處理流程實(shí)現(xiàn)優(yōu)化的 AI 推理性能。從模型轉(zhuǎn)換到性能優(yōu)化,MemryX 提供了一站式的開發(fā)支持,使 AI 開發(fā)更加高效且直觀。
為了滿足開發(fā)者的需求,MemryX 精心打造了一系列專業(yè)工具,包括 Neural Compiler、Simulator、Benchmark 和 Viewer。這些工具不僅功能強(qiáng)大,還以簡單易用為核心設(shè)計(jì)理念。Neural Compiler 讓模型轉(zhuǎn)換變得快速且無縫;Simulator 可在部署前模擬運(yùn)行性能,幫助開發(fā)者預(yù)測(cè)實(shí)際應(yīng)用表現(xiàn);Benchmark 提供詳細(xì)的吞吐量與延遲分析;而 Viewer 則以可視化界面呈現(xiàn)數(shù)據(jù),讓開發(fā)過程更加直觀。這些工具的整合,讓開發(fā)者能專注于創(chuàng)新,而不必被繁瑣的技術(shù)細(xì)節(jié)所困擾。
在實(shí)際測(cè)試中,MemryX 芯片展現(xiàn)了其卓越的性能與靈活性。在 C/C++ Python DEMO 測(cè)試中,單顆芯片即可同時(shí)處理多路攝像機(jī)流,并支持多個(gè) AI 模型的并行運(yùn)行,充分展現(xiàn)其在邊緣計(jì)算場(chǎng)景中的優(yōu)勢(shì)。此外,MemryX 的自動(dòng)化模型裁剪與編譯流程,讓開發(fā)者無需修改原始模型即可直接部署,顯著降低了開發(fā)門檻,并大幅提升了開發(fā)效率。
隨著 AI 技術(shù)的快速演進(jìn),MemryX 正引領(lǐng)邊緣計(jì)算的技術(shù)潮流,為各行各業(yè)提供高性能、低功耗且靈活的 AI 解決方案。本篇所介紹的工具與應(yīng)用示例,旨在幫助開發(fā)者快速掌握 MemryX MX3+ 的使用方法,讓 AI 技術(shù)的應(yīng)用更加普及化,推動(dòng)智慧生活的實(shí)現(xiàn)。如果您對(duì) MemryX 產(chǎn)品感興趣,或希望獲得更多技術(shù)支持與合作機(jī)會(huì),請(qǐng)隨時(shí)聯(lián)系。聯(lián)系伊布小編!謝謝!
四、參考文件
[1]MemryX 官方網(wǎng)站
[2] MemryX開發(fā)者中心技術(shù)網(wǎng)站
[3] EE Awards 2022 亞洲金選獎(jiǎng)
[4] MemryX_示例
[5] 美通社 - MemryX宣布MX3邊緣AI加速器正式投產(chǎn)
如有任何相關(guān)MemryX技術(shù)問題,歡迎在點(diǎn)擊文末閱讀原文,登錄大大通網(wǎng)站博文底下留言提問!
歡迎關(guān)注大大通博主:ATU 伊布小編 (一部)
了解MPU技術(shù)整合、深度學(xué)習(xí)、電腦視覺技術(shù)與人工智能(AI)的發(fā)展等更多相關(guān)內(nèi)容!
登錄大大通網(wǎng)站閱讀原文,了解更多詳情!
原文鏈接:https://www.wpgdadatong.com.cn/reurl/vU3qqy
-
NPU
+關(guān)注
關(guān)注
2文章
330瀏覽量
19747 -
邊緣AI
+關(guān)注
關(guān)注
0文章
162瀏覽量
5458
發(fā)布評(píng)論請(qǐng)先 登錄
邊緣AI的優(yōu)勢(shì)和技術(shù)基石

輕松上手邊緣AI:MemryX MX3+結(jié)合Orange Pi 5 Plus的C/C++實(shí)戰(zhàn)指南

邊緣AI運(yùn)算革新 DeepX DX-M1 AI加速卡結(jié)合Rockchip RK3588多路物體檢測(cè)解決方案

在i.MX93和i.MX8M Plus上都使用UART,遇到了RTS/CTS連接問題求解決
**【技術(shù)干貨】Nordic nRF54系列芯片:傳感器數(shù)據(jù)采集與AI機(jī)器學(xué)習(xí)的完美結(jié)合**
有獎(jiǎng)直播 | @4/8 輕松部署,強(qiáng)大擴(kuò)展邊緣運(yùn)算 AI 新世代

Banana Pi 發(fā)布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計(jì)算與嵌入式開發(fā)
Banana Pi 與瑞薩電子攜手共同推動(dòng)開源創(chuàng)新:BPI-AI2N
邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測(cè)方案

AI賦能邊緣網(wǎng)關(guān):開啟智能時(shí)代的新藍(lán)海
研華邊緣AI Box MIC-ATL3S部署Deepseek R1模型

Orange Business推出Live Intelligence:簡化企業(yè)級(jí)生成式AI部署
Orin芯片與邊緣計(jì)算結(jié)合
邊緣計(jì)算與5G技術(shù)的結(jié)合
什么是邊緣AI?邊緣AI的供電挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論