 機器學習異常檢測實戰:用Isolation Forest快速構建無標簽異常檢測系統
機器學習異常檢測實戰:用Isolation Forest快速構建無標簽異常檢測系統
本文轉自:DeepHub IMBA
無監督異常檢測作為機器學習領域的重要分支,專門用于在缺乏標記數據的環境中識別異常事件。本文深入探討異常檢測技術的理論基礎與實踐應用,通過Isolation Forest算法進行異常檢測,并結合LightGBM作為主分類器,構建完整的欺詐檢測系統。文章詳細闡述了從無監督異常檢測到人工反饋循環的完整工作流程,為實際業務場景中的風險控制提供參考。
異常檢測是一種識別與正常數據模式顯著偏離的數據點的技術方法。這些異常點,也稱為離群值,通常表示系統中的異常狀態、潛在威脅或需要特別關注的事件。
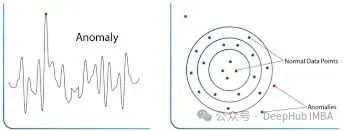
異常檢測技術在多個關鍵領域發揮著重要作用。在金融領域,通過識別異常交易模式和支出行為來實現欺詐檢測;在制造業中,通過監控質量指標的異常波動來保障產品質量;在醫療健康領域,通過檢測生理指標的異常變化來進行健康監測。這些應用的核心目標是將異常事件標記出來,供相關專業人員進行進一步審查和處理,從而有效降低潛在風險。
根據數據標記情況和應用場景的不同,異常檢測方法可以分為監督學習、半監督學習和無監督學習三大類別。
監督異常檢測方法基于已標記的正常和異常樣本進行模型訓練。這種方法在擁有可靠標記數據且異常模式相對明確的場景中表現優異。常用的算法包括貝葉斯網絡、k近鄰算法和決策樹等傳統機器學習方法。
半監督異常檢測,也稱為潔凈異常檢測,主要用于識別高質量數據中正常模式的顯著偏差。這種方法適用于數據結構良好且模式相對可預測的應用場景,如欺詐檢測和制造質量控制等領域。
無監督異常檢測方法通過尋找顯著偏離大部分數據分布的數據點來識別異常。當異常事件相對罕見或缺乏充分了解,且訓練數據中不包含標記異常樣本時,這種方法特別有效。典型算法包括K-means聚類和一類支持向量機等。
無監督異常檢測的主要技術方法
無監督異常檢測方法根據其技術原理可以分為統計方法、聚類方法、基于鄰近度的方法、時間序列分析方法和機器學習算法等幾個主要類別。
統計方法
統計方法通過分析數據的統計特性來識別異常觀測值。Z分數方法通過計算數據點距離均值的標準差倍數來量化異常程度,將遠離均值的數據點標記為異常。百分位數方法則通過設置基于分位數的閾值來識別落在正常范圍之外的數據點。這類方法最適用于具有明確統計分布特征的數據,其中異常表現為對統計正態性的明顯偏離。
聚類方法
聚類方法通過將相似數據點分組來識別異常,其中異常通常表現為不屬于任何明確定義簇的孤立點。DBSCAN算法基于密度進行聚類,將位于低密度區域且不屬于任何簇的點視為異常。K-Means聚類則通過計算數據點到簇中心的距離來識別遠離所有簇中心的異常點。這類方法在正常數據形成明顯聚類結構的場景中效果最佳。
基于鄰近度的方法
基于鄰近度的方法通過測量數據點之間的距離或相似性來識別那些異常遠離其鄰居或偏離數據中心趨勢的點。馬哈拉諾比斯距離考慮特征間的相關性來計算數據點到分布中心的距離。局部離群因子(LOF)通過計算數據點相對于其鄰居的局部密度偏差來識別在密度變化區域中的離群值。這類方法特別適用于異常由其孤立性或與其他數據點的距離來定義的場景,以及處理復雜多維數據集時密度變化具有重要意義的情況。
時間序列分析方法
時間序列分析方法專門針對序列數據設計,基于時間模式來識別異常。移動平均方法通過檢測數據點對特定時期內計算的移動平均的顯著偏離來識別異常。季節性分解方法將時間序列分解為趨勢、季節性和殘差成分,異常通常在無法通過趨勢或季節性解釋的殘差成分中被發現。這類方法最適用于觀察順序重要的序列數據,以及異常表現為對預期趨勢、季節性或時間模式偏離的場景。
機器學習算法
機器學習算法通過從數據中學習復雜模式來進行異常檢測。Isolation Forest作為一種集成方法,通過構建樹狀結構來有效隔離異常。一類支持向量機通過在正常數據周圍定義邊界來將數據點分類為正常或異常。K近鄰算法基于到K個最近鄰居的距離來分配異常分數。自編碼器作為神經網絡模型,通過學習數據的壓縮表示來檢測具有高重構誤差的異常。這類方法在復雜非線性模式定義正常行為且異常相對微妙的場景中表現最佳。
異常檢測與無監督聚類的區別
雖然異常檢測和無監督聚類都用于分析未標記數據中的模式,但兩者在目標和應用方式上存在根本差異。
以欺詐檢測為例,聚類方法有助于識別潛在欺詐交易的群組或不同的行為細分,其中某些群組可能比其他群組具有更高的風險水平。小規模的聚類簇并不一定表示欺詐行為,它們可能只是代表不同的用戶行為群組。
相比之下,異常檢測直接針對標記異常到足以需要調查的單個交易作為潛在欺詐,無論這些交易是否形成群組。這兩種方法在基本目標上存在差異,因此產生不同類型的輸出結果。
在目標定位上,聚類旨在發現未標記數據中的自然分組或細分,而異常檢測專注于識別顯著偏離正常模式的單個數據點。在輸出結果上,聚類為每個數據點分配聚類標識符,而異常檢測提供異常分數或二進制標志。
無監督聚類的典型應用場景包括:識別協同作案的欺詐團伙,他們的個別交易可能不顯示強異常特征,但集體模式可疑;發現多個客戶共享同一聯系信息的貸款申請模式;幫助安全管理員識別本質上風險較高的商戶類型。
無監督異常檢測的典型應用場景包括:檢測新型信用卡詐騙模式;識別員工對內部系統的未授權訪問;發現合法客戶賬戶被入侵后的異常交易;檢測用戶在短時間內從不同地理位置的登錄行為;識別使用一次性郵箱從相同IP范圍創建多個新賬戶的行為。
這些應用場景通常涉及尋找非常微妙的個別不規律性,在缺乏標記數據或先前示例的情況下,主要模型可能忽略這些不規律模式。
Isolation Forest算法原理
Isolation Forest是一種基于二叉樹結構的異常檢測算法,通過利用異常的固有特征來隔離異常點,而不是對正常數據進行建模。這種直觀且高效的方法使其成為異常檢測任務的熱門選擇。
算法的核心特征包括:采用集成方法構建多個隔離樹;通過異常點被隔離的難易程度來識別異常(需要更少的分割步驟來被分離的點更可能是異常);對高維數據具有相對快速和可擴展的處理能力;作為無監督方法不需要標記數據進行訓練;直接針對離群值檢測而不分析正常點的分布;在處理具有眾多特征的高維數據集時表現優異。
算法工作機制
Isolation Forest的工作原理可以通過以下流程來理解:首先,數據點需要遍歷森林中的每棵樹(樹1、樹2、...、樹T)。
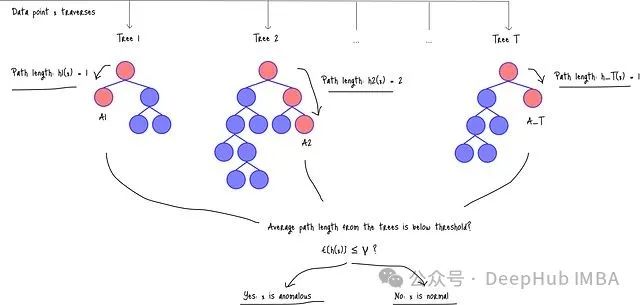 圖:Isolation Forest架構以及數據點處理流程
圖:Isolation Forest架構以及數據點處理流程
在算法執行過程中,h_i(x)表示數據點在第i棵樹中的路徑長度,即數據點從根節點到葉節點所經過的邊數。路徑長度越短,表明數據點越可能是異常。
接下來,算法計算數據點在所有T個隔離樹中的平均路徑長度E[h(x)]:
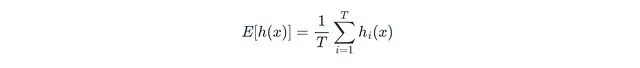
其中T表示森林中隔離樹的總數,h_i(x)表示數據點x在第i棵隔離樹中的路徑長度。
異常分數計算
Isolation Forest模型將平均路徑長度轉換為標準化的異常分數s(x):
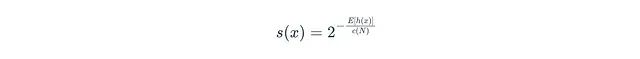
公式中各參數的含義為:E[h(x)]表示x的平均路徑長度;N表示用于構建單棵樹的訓練子集中的數據點數量(子采樣大小);c(N)表示標準化因子,代表在N個點的二叉搜索樹中不成功搜索的平均路徑長度:
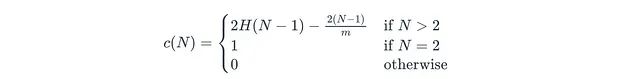
其中m表示樣本大小。
異常分數的取值范圍為0到1,分數越高表示成為異常的可能性越大。最終,模型將計算得到的分數與預設閾值(γ)進行比較,如果分數低于閾值,則將該數據點標記為異常。
無標記數據環境下的評估方法
在實際應用中,由于缺乏標記數據或歷史記錄,無法直接確認檢測到的異常是否確實需要被標記。因此需要通過多種方式來評估來自Isolation Forest的異常標記結果。
人工參與循環評估
人工審查是評估異常標記的關鍵步驟,包括向欺詐調查專家展示標記的異常事件。調查專家對真實欺詐和誤報數量的反饋為異常檢測系統提供了寶貴的改進信息。關鍵評估問題包括:模型輸出是否導致實際調查發現真實欺詐,還是主要產生噪音;模型是否能夠持續一致地將相似類型的事件標記為異常。
半監督評估方法
當擁有少量保留的標記數據集時(即使由于數量太少而不用于訓練),可以使用這些數據計算相關指標。Precision@k指標評估模型標記的前k個異常中真正欺詐的百分比。Recall@k指標類似于Precision@k,但專注于前k個標記中包含的實際欺詐案例數量。ROC AUC和PR AUC指標將異常分數視為連續變量并繪制相應的性能曲線。
合成異常注入測試
通過向干凈數據集中注入已知數量的合成異常,觀察模型成功識別的比例。這種方法有助于對不同無監督算法進行基準測試比較。
這些評估方法的價值在于:生成新的標記數據用于重新訓練主要模型;創建新特征或規則來應對新興威脅;調整Isolation Forest超參數(如contamination參數)以優化檢測準確性。
實驗設計與實現
本節通過信用卡交易數據集演示異常檢測的完整周期,包括Isolation Forest調優、人工反饋循環評估,以及使用新標記數據訓練LightGBM模型。
數據預處理
Isolation Forest與其他基于決策樹的模型類似,需要進行適當的數據預處理。從Financial Transactions Dataset: Analytics數據集加載數據后,對數值特征執行列轉換以進行標準化和歸一化處理。
原始數據集結構:

經過列轉換后的數據:
[[-1.39080197 -0.03606896 0.04983562 -1.30648276 0.37940361 -1.67063883]
[-0.192827 -0.52484299 -0.42640285 -0.52439344 1.85293745 -0.46941254]
[ 0.66316843 -0.62795398 -0.5266197 -0.03136157 -0.46709455 -0.40267775]
...
[ 0.66316843 -0.96249769 -0.85253289 -1.06913227 1.39833658 -1.53716925]
[-1.56087595 -0.67663075 -0.57406012 0.17866552 -1.97198017 0.26467019]
[-0.3129254 -0.53653239 -0.43765848 -0.20775319 -1.59575877 0.06446581]]
數據形狀:(1000, 6)
Isolation Forest參數調優
在沒有任何欺詐線索的初始階段,采用相對寬松的超參數設置,使模型具有較高的靈活性:
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
isolation_forest = IsolationForest(
n_estimators=500, # 森林中樹的最大數量
contamination="auto", # 初始設置為auto(后續調整)
max_samples='auto',
max_features=1, # 每次分割僅考慮一個特征
bootstrap=True, # 使用bootstrap樣本確保魯棒性
random_state=42,
n_jobs=-1
)
y_pred_iso = isolation_forest.fit_predict(X_processed)
inliers_iso = X[y_pred_iso == 1]
outliers_iso = X[y_pred_iso == -1]
print(f"Isolation Forest detected {len(outliers_iso)} outliers.")
One-Class SVM對比實驗
為了進行性能比較,同時調優一類支持向量機,設置相對寬松的nu值:
one_class_svm = OneClassSVM(
kernel='rbf',
gamma='scale',
tol=1e-7,
nu=0.1, # 寬松的nu值設置
shrinking=True,
max_iter=5000,
)
y_pred_ocsvm = one_class_svm.fit_predict(X_processed)
inliers_ocsvm = X[y_pred_ocsvm == 1]
outliers_ocsvm = X[y_pred_ocsvm == -1]
print(f"One-Class SVM detected {len(outliers_ocsvm)} outliers.")
實驗結果分析
實驗結果顯示:
Isolation Forest檢測到166個異常點
One-Class SVM檢測到101個異常點
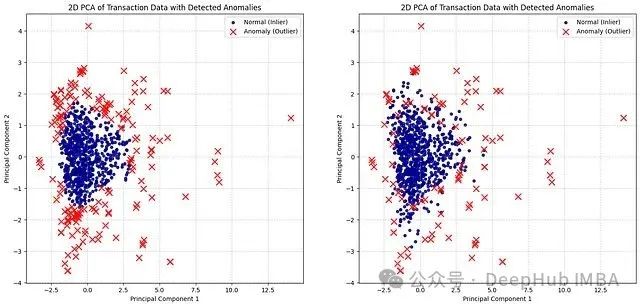
圖:Isolation Forest(左)和One-Class SVM(右)的無監督異常檢測結果對比
Isolation Forest在尋找容易被"隔離"的點方面表現更為積極,擅長發現新穎的、真正異常的點,即使這些點與主要數據簇的距離并不是非常遠。如果對"異常"的定義相對寬泛,這種特性可能導致檢測到更多的異常點。
One-Class SVM在正常數據周圍定義了更加結構化的邊界,將邊界之外的點標記為異常。這種方法相對保守,需要從"正常"流形更顯著的偏差才會被標記為異常。
人工反饋循環評估
為了實際演示評估過程,將標記的記錄按照以下四個類別進行逐一審查:
類別1(真正例,TP):模型標記的交易確實是欺詐性的。類別2(假正例,FP):模型標記的交易實際上是合法的,表示"虛假警報"。過多的假正例可能使分析師工作負擔過重并導致效率低下。類別3(新欺詐模式):識別出被捕獲的新類型欺詐,或以前錯過的欺詐類型,為不斷演變的威脅態勢提供新的洞察。類別4(合法但異常行為):交易看似合法但對該客戶或客戶群體確實異常,了解模型標記原因具有重要價值。
需要注意的是,假陰性(FN)記錄通常來自其他來源,如客戶投訴或退單,因為這些交易未被模型標記但后來發現是欺詐性的。在這個實驗中,由于重點關注模型標記的準確性,暫時排除了假陰性分析。在實際應用中,欺詐專家對記錄進行準確分類至關重要。
以下是一些標記記錄的示例和相應的人工審查結果:
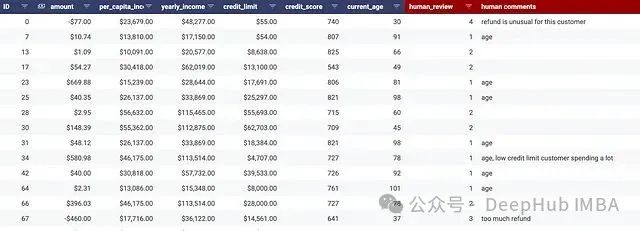
圖:標記的交易記錄列表(合成數據)和人工審查示例
以記錄#0為例,77美元的退款雖然不一定可疑或欺詐,但確實代表了該特定客戶的異常行為模式。記錄#67(底部)同樣顯示了大量退款行為。如果將此識別為新的欺詐方案,可以將其標記為類別3。
對于記錄#23、#25等,客戶年齡超過90歲。來自該年齡群體個人的如此高交易量通常是異常的,需要特別關注。
在166個潛在異常中,按類別分布情況為:類別1占94個,類別2占30個,類別3占10個,類別4占23個。
污染度參數調整
基于審查結果的分析顯示:總標記數為166個;真正例(TP)為94個;假正例(FP)為72個(166-94);標記集的精確度為TP/(TP+FP) = 94/166 ≈ 56.63%。
這表明雖然模型預測了16.6%的污染率,但該數據集的實際可觀察污染率為9.4%(1000個總樣本中的94個異常)。同時必須考慮模型在此實驗中未標記的假陰性(遺漏的異常),因此真實污染率可能大于等于9.4%。
基于這一發現,在下一次迭代中將contamination參數設置為0.1(10%):
refined_isolation_forest = IsolationForest(
n_estimators=500,
contamination=0.1, # 更新為0.1
max_samples='auto',
max_features=1,
bootstrap=True,
random_state=42,
n_jobs=-1
)
訓練樣本標簽更新
另一個重要步驟是基于更新的數據集重新訓練主要模型。向原始DataFrame添加三個新列,將human_review類別1標記為is_fraud = true(1):
human_review:存儲審查類別(0,1,2,3,4),非異常情況為零
is_fraud_iforest:存儲來自Isolation Forest的初始異常檢測結果(二進制:1,-1)
is_fraud:存儲最終欺詐判定結果(二進制:0,1),其中1表示欺詐
is_fraud列作為目標變量用于訓練主要模型:
import pandas as pd
df_human_review = pd.read_csv(csv_file_path, index_col=1)
df_merged = df_new.merge(
df_human_review[['human_review']],
left_index=True,

right_index=True,
how='left'
)
df_merged['human_review'] = df_merged['human_review'].fillna(0).astype(int)
df_merged['is_fraud'] = (df_merged['human_review'] == 1).astype(int)
圖:更新后的數據框,右側三列為新添加的列
主要模型重新訓練
由于數據集存在類別不平衡問題,首先使用SMOTE技術對少數類進行過采樣:
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from collections import Counter
X = df_merged.copy().drop(columns='is_fraud', axis='columns')
y = df_merged.copy()['is_fraud']
X_tv, X_test, y_tv, y_test = train_test_split(X, y, test_size=300, shuffle=True, stratify=y, random_state=12)
X_train, X_val, y_train, y_val = train_test_split(X_tv, y_tv, test_size=300, shuffle=True, stratify=y_tv, random_state=12)
print(Counter(y_train))
smote = SMOTE(sampling_strategy={1: 75}, random_state=42)
X_train, y_train = smote.fit_resample(X_train, y_train)
print(Counter(y_train))
輸出結果:Counter({0: 370, 1: 30}) → Counter({0: 370, 1: 75})
然后使用更新的訓練樣本重新訓練主要模型(LightGBM)和基線模型:
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
# 主要模型
lgbm = HistGradientBoostingClassifier(
learning_rate=0.05,
max_iter=500,
max_leaf_nodes=20,
max_depth=5,
min_samples_leaf=32,
l2_regularization=1.0,
max_features=0.7,
max_bins=255,
early_stopping=True,
n_iter_no_change=5,
scoring="f1",
validation_fraction=0.2,
tol=1e-5,
random_state=42,
class_weight='balanced'
)
# 基線模型
lr = LogisticRegression(
penalty='l2',
dual=False,
tol=1e-5,
C=1.0,
class_weight='balanced',
random_state=42,
solver="lbfgs",
max_iter=500,
n_jobs=-1,
)
性能評估結果
使用訓練集、驗證集和測試集對主要模型與邏輯回歸基線進行評估。為了減少假陰性,將F1分數作為主要評估指標:
邏輯回歸(L2正則化):訓練性能0.9886-0.9790 → 泛化性能0.9719
LightGBM:訓練性能0.9133-0.8873 → 泛化性能0.9040
兩個模型都表現出良好的泛化能力,其泛化分數接近訓練分數。在這個比較中,帶有L2正則化的邏輯回歸是性能更優的模型,在訓練數據和更重要的未見泛化數據上都達到了更高的準確性。其泛化性能(0.9719)優于LightGBM(0.9040)。
合成異常注入測試
最后,創建50個合成數據點來測試模型的適應性:
from sklearn.metrics import f1_score
num_synthetic_fraud = 50
synthetic_fraud_X = generate_synthetic_fraud(num_synthetic_fraud, X_test, df_merged)
y_pred_test_with_synthetic = pipeline.predict(X_test_with_synthetic)
f1_test_with_synthetic = f1_score(y_test_with_synthetic, y_pred_test_with_synthetic, average='weighted')
測試結果表明,LightGBM在檢測合成欺詐方面達到了完美的F1分數1.0000,顯著優于邏輯回歸(F1分數:0.8764,精確度0.90,召回率0.84)。

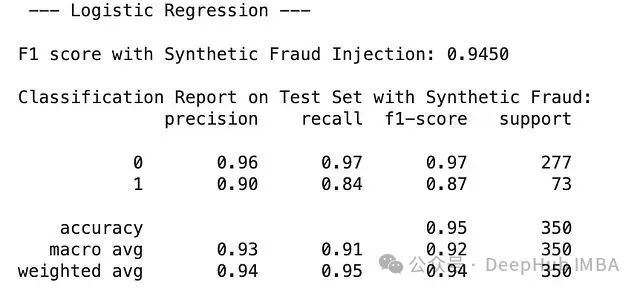
雖然LightGBM完美識別了注入的欺詐案例,但在當前階段,帶有L2正則化的邏輯回歸可能為欺詐分類提供更好的整體平衡性能。
總結
本研究通過實驗演示了異常標記如何逐步完善異常檢測方案和主要分類模型在欺詐檢測中的應用。實驗結果表明,Isolation Forest作為一個強大的異常檢測模型,無需顯式建模正常模式即可有效工作,在處理未見風險事件方面具有顯著優勢。
研究發現,通過人工反饋循環可以有效提升模型性能,將無監督異常檢測的結果轉化為有價值的訓練數據。這種方法特別適用于缺乏歷史標記數據但需要快速響應新興威脅的場景。
對于實際應用而言,自動化人工審查系統和開發創建欺詐交易規則的結構化方法將是對所提出方法的關鍵增強。未來的研究方向可以包括:建立更加智能化的人工反饋收集機制;開發自適應的閾值調整算法;集成多種異常檢測算法以提高檢測精度;構建實時異常檢測系統以應對動態變化的威脅環境。
作者:Kuriko IWAI
-
檢測系統
+關注
關注
3文章
974瀏覽量
43778 -
檢測
+關注
關注
5文章
4624瀏覽量
92622 -
機器學習
+關注
關注
66文章
8499瀏覽量
134269
發布評論請先 登錄
全面剖析用于人工智能isolation_forest算法技術

提高IT運維效率,深度解讀京東云AIOps落地實踐(異常檢測篇)
基于深度學習的異常檢測的研究方法
云計算平臺的異常探測







 工商網監
工商網監
評論