") 全面剖析用于人工智能isolation_forest算法技術(shù)
全面剖析用于人工智能isolation_forest算法技術(shù)
隨著機(jī)器學(xué)習(xí)近年來的流行,尤其是深度學(xué)習(xí)的火熱。機(jī)器學(xué)習(xí)算法在很多領(lǐng)域的應(yīng)用越來越普遍。最近,作者在一家廣告公司做廣告點擊反作弊算法研究工作。想到了異常檢測算法,并且上網(wǎng)調(diào)研發(fā)現(xiàn)有一個算法非常火爆,那就是本文要介紹的算法 Isolation Forest,簡稱 iForest 。
南大周志華老師的團(tuán)隊在2010年提出一個異常檢測算法Isolation Forest,在工業(yè)界很實用,算法效果好,時間效率高,能有效處理高維數(shù)據(jù)和海量數(shù)據(jù),這里對這個算法進(jìn)行簡要總結(jié)。
iTree的構(gòu)造
提到森林,自然少不了樹,畢竟森林都是由樹構(gòu)成的,那么我們在看Isolation Forest(簡稱iForest)前,我們先來看看Isolation-Tree(簡稱iTree)是怎么構(gòu)成的,iTree是一種隨機(jī)二叉樹,每個節(jié)點要么有兩個女兒,要么就是葉子節(jié)點,一個孩子都沒有。給定一堆數(shù)據(jù)集D,這里D的所有屬性都是連續(xù)型的變量,iTree的構(gòu)成過程如下:
-
隨機(jī)選擇一個屬性Attr;
-
隨機(jī)選擇該屬性的一個值Value;
-
根據(jù)Attr對每條記錄進(jìn)行分類,把Attr小于Value的記錄放在左女兒,把大于等于Value的記錄放在右孩子;
-
然后遞歸的構(gòu)造左女兒和右女兒,直到滿足以下條件:
-
傳入的數(shù)據(jù)集只有一條記錄或者多條一樣的記錄;
-
樹的高度達(dá)到了限定高度;

iTree構(gòu)建好了后,就可以對數(shù)據(jù)進(jìn)行預(yù)測啦,預(yù)測的過程就是把測試記錄在iTree上走一下,看測試記錄落在哪個葉子節(jié)點。iTree能有效檢測異常的假設(shè)是:異常點一般都是非常稀有的,在iTree中會很快被劃分到葉子節(jié)點,因此可以用葉子節(jié)點到根節(jié)點的路徑h(x)長度來判斷一條記錄x是否是異常點;對于一個包含n條記錄的數(shù)據(jù)集,其構(gòu)造的樹的高度最小值為log(n),最大值為n-1,論文提到說用log(n)和n-1歸一化不能保證有界和不方便比較,用一個稍微復(fù)雜一點的歸一化公式:
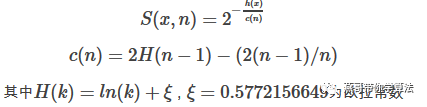
s(x,n)就是記錄x在由n個樣本的訓(xùn)練數(shù)據(jù)構(gòu)成的iTree的異常指數(shù),s(x,n)取值范圍為[0,1]異常情況的判斷分以下幾種情況:
-
越接近1表示是異常點的可能性高;
-
越接近0表示是正常點的可能性比較高;
-
如果大部分的訓(xùn)練樣本的s(x,n)都接近于0.5,整個數(shù)據(jù)沒有明顯的異常。
由于是隨機(jī)選屬性,隨機(jī)選屬性值,一棵樹這么隨便搞肯定是不靠譜,但是把多棵樹結(jié)合起來就變強(qiáng)大了;
iForest的構(gòu)造
iTree搞明白了,我們現(xiàn)在來看看iForest是怎么構(gòu)造的,給定一個包含n條記錄的數(shù)據(jù)集D,如何構(gòu)造一個iForest。iForest和Random Forest的方法有些類似,都是隨機(jī)采樣一部分?jǐn)?shù)據(jù)集去構(gòu)造每一棵樹,保證不同樹之間的差異性,不過iForest與RF不同,采樣的數(shù)據(jù)量
左邊是原始數(shù)據(jù),右邊是采樣了數(shù)據(jù),藍(lán)色是正常樣本,紅色是異常樣本。可以看到,在采樣之前,正常樣本和異常樣本出現(xiàn)重疊,因此很難分開,但我們采樣之和,異常樣本和正常樣本可以明顯的分開。
除了限制采樣大小Ψ以外,我們還要給每棵iTree設(shè)置最大高度為l=ceilng(log2Ψ),這是因為異常數(shù)據(jù)記錄都比較少,其路徑長度也比較低,而我們也只需要把正常記錄和異常記錄區(qū)分開來,因此只需要關(guān)心低于平均高度的部分就好,這樣算法效率更高,不過這樣調(diào)整了后,后面可以看到計算h(x)需要一點點改進(jìn),先看iForest的偽代碼:

IForest構(gòu)造好后,對測試進(jìn)行預(yù)測時,需要進(jìn)行綜合每棵樹的結(jié)果,于是
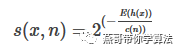
E(h(x))表示記錄x在每棵樹的高度均值,另外h(x)計算需要改進(jìn),在生成葉節(jié)點時,算法記錄了葉節(jié)點包含的記錄數(shù)量,這時候要用這個數(shù)量Size估計一下平均高度,h(x)的計算方法如下:

對高維數(shù)據(jù)的處理
在處理高維數(shù)據(jù)時,可以對算法進(jìn)行改進(jìn),采樣之后并不是把所有的屬性都用上,而是用峰度系數(shù)Kurtosis挑選一些有價值的屬性,再進(jìn)行iTree的構(gòu)造,這跟隨機(jī)森林就更像了,隨機(jī)選記錄,再隨機(jī)選屬性。
只使用正常樣本
這個算法本質(zhì)上是一個無監(jiān)督學(xué)習(xí),不需要數(shù)據(jù)的類標(biāo),有時候異常數(shù)據(jù)太少了,少到我們只舍得拿這幾個異常樣本進(jìn)行測試,不能進(jìn)行訓(xùn)練,論文提到只用正常樣本構(gòu)建IForest也是可行的,效果有降低,但也還不錯,并可以通過適當(dāng)調(diào)整采樣大小來提高效果。
總結(jié)
-
iForest具有線性時間復(fù)雜度。因為是ensemble的方法,所以可以用在含有海量數(shù)據(jù)的數(shù)據(jù)集上面。通常樹的數(shù)量越多,算法越穩(wěn)定。由于每棵樹都是互相獨立生成的,因此可以部署在大規(guī)模分布式系統(tǒng)上來加速運算。
-
iForest不適用于特別高維的數(shù)據(jù)。由于每次切數(shù)據(jù)空間都是隨機(jī)選取一個維度,建完樹后仍然有大量的維度信息沒有被使用,導(dǎo)致算法可靠性降低。高維空間還可能存在大量噪音維度或無關(guān)維度(irrelevant attributes),影響樹的構(gòu)建。對這類數(shù)據(jù),建議使用子空間異常檢測(Subspace Anomaly Detection)技術(shù)。此外,切割平面默認(rèn)是axis-parallel的,也可以隨機(jī)生成各種角度的切割平面,詳見“On Detecting Clustered Anomalies Using SCiForest”。
-
iForest僅對Global Anomaly 敏感,即全局稀疏點敏感,不擅長處理局部的相對稀疏點 (Local Anomaly)。目前已有改進(jìn)方法發(fā)表于PAKDD,詳見“Improving iForest with Relative Mass”。
-
iForest推動了重心估計(Mass Estimation)理論發(fā)展,目前在分類聚類和異常檢測中都取得顯著效果,發(fā)表于各大頂級數(shù)據(jù)挖掘會議和期刊(如SIGKDD,ICDM,ECML)。
注意
目前燕哥還沒有發(fā)現(xiàn)有Java開源庫實現(xiàn)了該算法。目前只有Python機(jī)器學(xué)習(xí)庫scikit-learn的0.18版本對此算法進(jìn)行了實現(xiàn)。而我的項目絕大多數(shù)都是Java實現(xiàn)的,因此我需要自己實現(xiàn)該算法。算法源碼已實現(xiàn)并開源到我的GitHub上,讀者可以下載源碼并用IDEA集成開發(fā)環(huán)境直接打開項目,并運行測試程序以查看算法的檢測效果。-
人工智能
+關(guān)注
關(guān)注
1804文章
48798瀏覽量
247098
原文標(biāo)題:Isolation Forest算法原理詳解
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論