") 算力網(wǎng)絡(luò)的“神經(jīng)突觸”:AI互聯(lián)技術(shù)如何重構(gòu)分布式訓(xùn)練范式
算力網(wǎng)絡(luò)的“神經(jīng)突觸”:AI互聯(lián)技術(shù)如何重構(gòu)分布式訓(xùn)練范式
電子發(fā)燒友網(wǎng)綜合報道 隨著AI技術(shù)迅猛發(fā)展,尤其是大型語言模型的興起,對于算力的需求呈現(xiàn)出爆炸性增長。這不僅推動了智算中心的建設(shè),還對網(wǎng)絡(luò)互聯(lián)技術(shù)提出了新的挑戰(zhàn)。
在AI大模型訓(xùn)練過程中,由于單個AI芯片的算力提升速度無法跟上模型參數(shù)的增長速率,再加上龐大的模型參數(shù)和訓(xùn)練數(shù)據(jù),已遠(yuǎn)遠(yuǎn)超出單個AI芯片甚至單臺服務(wù)器的能力范圍。因此,需要將數(shù)據(jù)樣本和模型結(jié)構(gòu)分散到多個計算設(shè)備上,這導(dǎo)致了設(shè)備間的頻繁通信需求。為了適應(yīng)這一變化,智算中心服務(wù)器內(nèi)部的網(wǎng)絡(luò)互聯(lián)技術(shù)變得至關(guān)重要。
芯片間互聯(lián)技術(shù)
AI服務(wù)器的互聯(lián)技術(shù)是保障其高性能計算能力的關(guān)鍵,涉及芯片間、服務(wù)器內(nèi)以及服務(wù)器間等多個層面的高速數(shù)據(jù)傳輸。
芯片間互聯(lián)技術(shù)方面,英偉達(dá)、AMD、英特爾都推出了相關(guān)技術(shù),分別是NVLink、Infinity Fabric、CXL(Compute Express Link)等。NVLink是由NVIDIA開發(fā)的GPU之間的高速互連技術(shù),能加快CPU與GPU、GPU與GPU之間的數(shù)據(jù)傳輸速度,提高系統(tǒng)性能。從2016年到2022年,NVLink歷經(jīng)多次迭代更新,例如基于Hopper架構(gòu)的第四代NVLink,單鏈可實(shí)現(xiàn)50GB/s的雙向帶寬,單芯片可支持18鏈路,即900GB/s的總雙向帶寬。在NVIDIA的DGX H100服務(wù)器中,GPU(H100)之間互聯(lián)主要通過NV Switch芯片來實(shí)現(xiàn),而NV Switch芯片與GPU之間的數(shù)據(jù)傳輸就依賴于NVLink。
AMD推出的Infinity Fabric,由傳輸數(shù)據(jù)的Infinity Scalable Data Fabric(SDF)和負(fù)責(zé)控制的Infinity Scalable Control Fabric(SCF)兩個系統(tǒng)組成,連接了on-die和off-die以及多路CPU間的通信。最新的AMD Instinct MI300X GPU采用5nm制程,支持客戶將8個GPU整合為一個性能主導(dǎo)型節(jié)點(diǎn),并且具有全互聯(lián)式點(diǎn)對點(diǎn)環(huán)形設(shè)計,使用了第4代Infinity Fabric高速總線互聯(lián),總線帶寬達(dá)到896GB/s(與英偉達(dá)H100的900GB/s帶寬相當(dāng))。
CXL(Compute Express Link)是英特爾提出的一種開放性互聯(lián)協(xié)議,CXL是建立在PCIe物理層之上的協(xié)議,可以實(shí)現(xiàn)設(shè)備之間的緩存和內(nèi)存一致性。利用廣泛存在的PCIe接口,CXL允許內(nèi)存在各種硬件上共享:CPU、NIC和DPU、GPU和其它加速器、SSD和內(nèi)存設(shè)備,從而滿足高性能異構(gòu)計算的要求。
服務(wù)器內(nèi)互聯(lián)技術(shù)有PCIe Switch、Retimer芯片。PCIe Switch,即PCIe開關(guān)或PCIe交換機(jī),主要作用是實(shí)現(xiàn)PCIe設(shè)備互聯(lián)。由于PCIe的鏈路通信是一種端對端的數(shù)據(jù)傳輸,需要Switch提供擴(kuò)展或聚合能力,從而允許更多的設(shè)備連接到一個PCIe端口,以解決PCIe通道數(shù)量不夠的問題。例如在AI服務(wù)器中,GPU與CPU連接時可能需要用到PCIe Switch,并且隨著PCIe總線技術(shù)的升級,PCIe Switch每代速率提升,能提高數(shù)據(jù)傳輸?shù)乃俣取?br />
在AI服務(wù)器中,GPU與CPU連接時至少需要一顆Retimer芯片來保證信號質(zhì)量,很多AI服務(wù)器都會配置多顆Retimer芯片。例如Astera Labs在AI加速器中配置了4顆Retimer芯片。
AI服務(wù)器間互聯(lián)技術(shù)
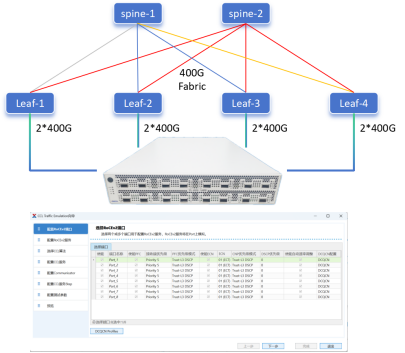
服務(wù)器間互聯(lián)技術(shù)有InfiniBand、RoCE、高速以太網(wǎng)。InfiniBand是一種高性能的網(wǎng)絡(luò)互聯(lián)技術(shù),具有低延遲、高帶寬的特點(diǎn),能夠滿足AI服務(wù)器之間超低延遲、超高帶寬的通信需求,適用于大規(guī)模AI模型訓(xùn)練時服務(wù)器之間的高效通信和數(shù)據(jù)同步。例如訓(xùn)練超大模型往往需要成百上千臺服務(wù)器組成集群,服務(wù)器之間就需要InfiniBand這樣的網(wǎng)絡(luò)進(jìn)行高效通信。
RoCE(RDMA over Converged Ethernet),基于以太網(wǎng)的RDMA(遠(yuǎn)程直接內(nèi)存訪問)技術(shù),它允許數(shù)據(jù)在網(wǎng)絡(luò)中直接從一臺計算機(jī)的內(nèi)存?zhèn)鬏數(shù)搅硪慌_計算機(jī)的內(nèi)存,而無需操作系統(tǒng)內(nèi)核的介入,從而降低了延遲,提高了帶寬利用率,可用于AI服務(wù)器間的互聯(lián),提升數(shù)據(jù)傳輸效率。
高速以太網(wǎng),如400Gbps甚至800Gbps以太網(wǎng)適配器,能為AI服務(wù)器間提供高速的網(wǎng)絡(luò)連接,保障大規(guī)模集群部署時服務(wù)器之間的數(shù)據(jù)傳輸性能。例如昆侖芯超節(jié)點(diǎn)結(jié)合百度智能云自研的基于導(dǎo)軌優(yōu)化的HPN(High Performance Network)架構(gòu),可支撐從數(shù)百卡到上萬卡的XPU集群構(gòu)建,其中就涉及到高速以太網(wǎng)技術(shù)的應(yīng)用。
小結(jié)
在AI服務(wù)器中,互聯(lián)技術(shù)的作用已從數(shù)據(jù)傳輸通道升級為算力釋放引擎。通過高帶寬、低延遲、可擴(kuò)展的互聯(lián)架構(gòu),AI服務(wù)器能夠突破單節(jié)點(diǎn)算力瓶頸,實(shí)現(xiàn)萬億參數(shù)模型的分布式訓(xùn)練;降低推理延遲,支撐實(shí)時AI應(yīng)用的商業(yè)化落地;優(yōu)化能效比,應(yīng)對超大規(guī)模數(shù)據(jù)中心的能耗挑戰(zhàn)。
-
AI
+關(guān)注
關(guān)注
87文章
34291瀏覽量
275471 -
算力
+關(guān)注
關(guān)注
2文章
1148瀏覽量
15461
發(fā)布評論請先 登錄
上海電信攜手華為打造分布式云邊協(xié)同訓(xùn)推方案
破局智算瓶頸:400G光模塊如何重構(gòu)AI時代的網(wǎng)絡(luò)神經(jīng)脈絡(luò)
AI原生架構(gòu)升級:RAKsmart服務(wù)器在超大規(guī)模模型訓(xùn)練中的算力突破
RAKsmart智能算力架構(gòu):異構(gòu)計算+低時延網(wǎng)絡(luò)驅(qū)動企業(yè)AI訓(xùn)練范式升級
適用于數(shù)據(jù)中心和AI時代的800G網(wǎng)絡(luò)
DeepSeek推動AI算力需求:800G光模塊的關(guān)鍵作用
信而泰CCL仿真:解鎖AI算力極限,智算中心網(wǎng)絡(luò)性能躍升之道
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
分布式通信的原理和實(shí)現(xiàn)高效分布式通信背后的技術(shù)NVLink的演進(jìn)
企業(yè)AI算力租賃是什么
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
AI網(wǎng)絡(luò)物理層底座: 大算力芯片先進(jìn)封裝技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論