 奇異摩爾攜手UALink聯盟助力AI網絡繁榮發展
奇異摩爾攜手UALink聯盟助力AI網絡繁榮發展
隨著AI大模型訓推集群的規模不斷擴大,Scale-up網絡的重要性已不限于訓練集群側,云端推理集群對于多機之間組成超節點HBD方案的需求正在逐步增加。面對其對互聯性能的極致追求,目前業內主要采用專門設計的協議比如NVIDIA的NVLink及NVSwitch技術。在今年的GTC大會上,NVIDIA已經明確將GPU 的HBD域互聯從72卡推進到576卡。 然而,NVIDIA的解決方案是基于私有協議,不僅成本高昂,且不對外開放。為了打破這一局面,AI網絡產業鏈在去年共同發起了UALink 加速器互聯協議聯盟,旨在推動AI網絡Scale-up互聯的創新技術發展。
奇異摩爾在2024年就加入了UALink(Ultra Accelerator Link ) 加速器間互聯協議聯盟,并積極參與UALink標準的制定。 就在本周,UALink聯盟終于迎來了1.0標準的正式發布,這一標準的發布將進一步加速AI訓推基礎設施的生態完善,助力AI網絡的繁榮發展。
關于第一版標準,UALink 聯盟董事會主席 Kurtis Bowman 表示:“隨著對 AI 計算的需求不斷增長,我們很高興能夠提供一項必不可少的開放行業標準技術,使下一代 AI/ML 應用能夠推向市場。UALink 是唯一一款針對擴展 AI 的內存語義解決方案,它針對降低功耗、延遲和成本進行了優化,同時增加了有效帶寬。UALink 200G 1.0 規范帶來的突破性性能將徹底改變云服務提供商、系統 OEM 和 IP/芯片提供商處理 AI 工作負載的方式。
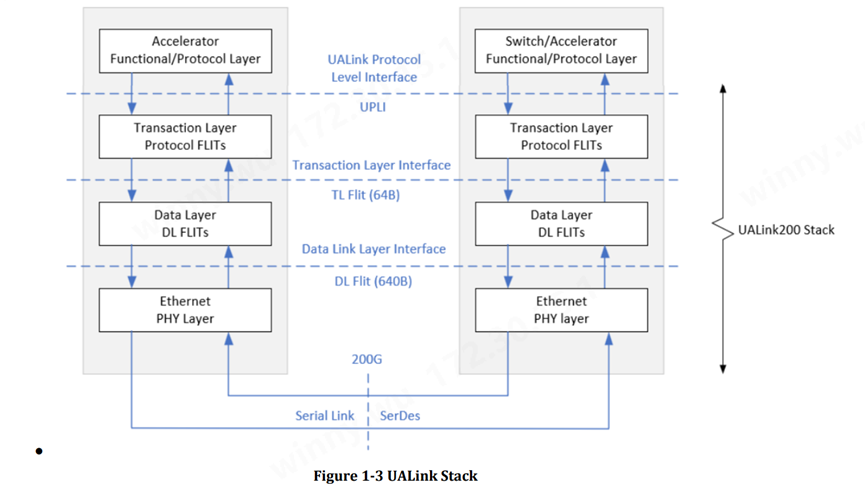
UALink 協議棧包括四個硬件優化層:物理層(physical)、數據鏈路層(data link)、事務層(transaction)和協議層(protocol)。
基于內存語義的快速GPU HBM訪問
(圖:UALink Specification 1.0Rev)
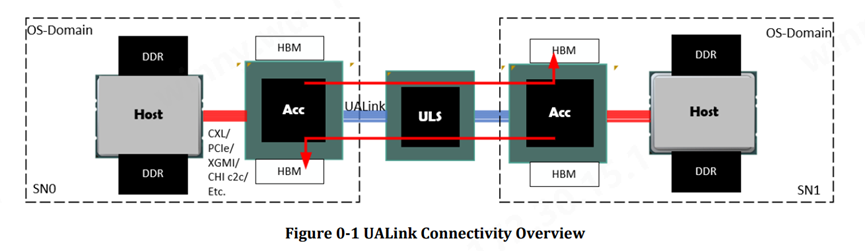
和其他Scale-up生態有所區別的是UALink從誕生那刻起就是基于內存語義。上述表格描述了兩個基于UALink的系統節點通過UAL交換機實現互聯。在這個Domain中,CPU Host可通過CXL, PCIe, AMD Infinity Fabric, XGMI等協議與GPU加速器互聯。基于UALink協議,GPU之間通過UAlink Switch交換機與HBD域內的其他GPU互聯。
圖中特別突出的是紅線所指示的部分,在該HBD Domain中的任意GPU 都可以訪問其他GPU的HBM,從而實現加速器之間的快速讀取和寫入,相較于消息語義,它的通信和互聯效率是非常高的。
奇異摩爾作為Scale-up網絡主要芯粒提供商自研的 NDSA-G2G IO Die 未來將支持內存語義,通過與UAlink生態適配,建立更完善的內存語義互聯系統。
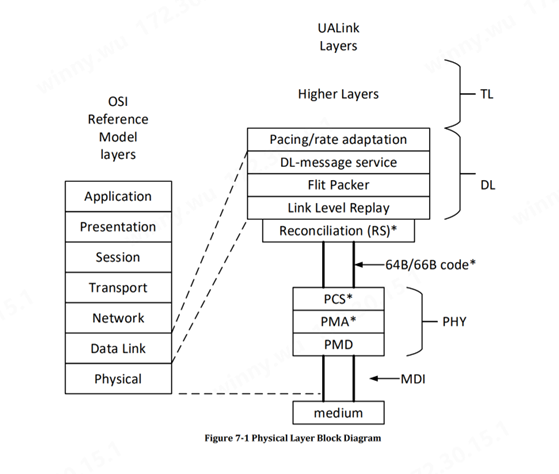
物理層特點Physical Layer
(圖:UALink Specification 1.0Rev)
UALink 物理層基于 802.3 以太網物理層。UALink 定義了 1、2 或 4 個串行通道,運行速率為 212.5Gbps(200GBASE-KR1/CR1、400GBASE-KR2/CR2、800GBASE-KR4/CR4)。物理層包括了使用 FEC 減少延遲的修改。該以太網物理層具有標準的前向 (FEC) 并遵循 IEEE P802.3dj 規范。通過單向和雙向碼字交錯,讓延遲得到改善,并且有一點變化以支持 680 字節的 flit。(Flit 或流控制單元是鏈路級別的原子數據單元)
在 PCI-Express 6.0 中,控制該標準(并且主要由英特爾主導)的 PCI-SIG 組織,并沒有僅僅實現標準的 FEC,而新的FEC是轉向了一種流量控制和循環冗余檢查 (CRC) 錯誤檢測的混合方式,實際上提高了信號傳輸的可靠性,同時降低了延遲。這樣的一些機制被 UALink 采納,并且許多對于內存架構來說不必要的東西并沒有包含在其中從而輕量化了該協議。
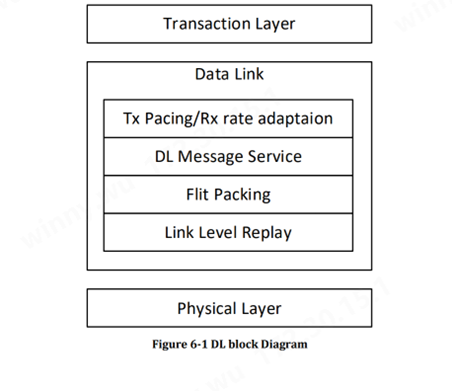
數據鏈路層特點Data Link Layer
(圖:UALink Specification 1.0Rev)
數據鏈路層位于事務層和物理層之間。數據鏈路層將事務層的 64 字節 Flit 打包成物理層的 640 字節 Flit。數據鏈路層還提供鏈接伙伴之間在數據鏈路層發起和終止的消息服務。消息服務用于宣傳事務層速率、查詢連接鏈路伙伴上的設備和端口 ID 以及其他功能。消息服務還提供鏈接伙伴之間的 UART 式通信,用于固件通信。鏈路級重放是基于 640 字節 Flit 提供的。計算并檢查 32 位 CRC,并且是 640 字節 Flit 的一部分。此外Link Level Replay的功能確保了物理層 FEC 無法糾正的比特錯誤存在的情況下,DL Flits 的有序傳遞。發送器保留有效負載 Flits的副本,直到接收器確認它們。
事務層特點Transaction Layer
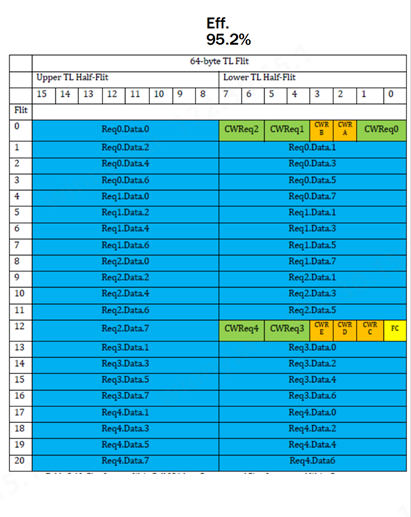
(圖:UALink Specification 1.0Rev)
UALink 1.0 Spec實現壓縮尋址,在實際工作負載下以高達 95% 的協議效率簡化數據傳輸。它支持直接內存操作,例如加速器之間的讀取、寫入和原子事務(atomic transactions),從而保留本地和遠程內存空間之間的順序。
協議層特點Protocol Layer
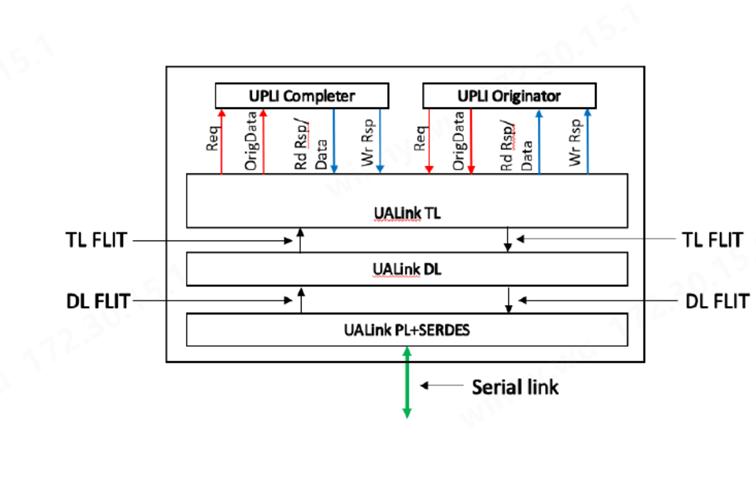
(圖:UALink Specification 1.0Rev)
UALink 的協議層稱為 UALink 協議級接口 (UPLI)。UPLI 定義了一個邏輯信號接口和協議,通過該協議,設備可以通過一組請求和響應消息交換數據和控制信息。UALink 規范完全定義了 UPLI 協議,并期望遵循該協議的實現將與 UALink 交換機兼容。UPLI 協議具有內置的靈活性,允許供應商創建自定義協議消息,用于相同類型的加速器之間的通信,而無需對 UALink 交換機進行任何修改。UALink 協議級接口是主要接口,實現可能在此基礎上開發,通常使用第三方供應商提供的堆棧其余部分的 IP。
協議輕量化降低數據中心功耗
UALink的一個非常突出的特點就是整體設計簡單輕量化。據悉,UALink 的功耗僅為同等以太網 ASIC 芯片面積的一半到三分之一(每個端口),并且每個內存結構加速器可節省 150 瓦到 200 瓦的功耗。更小的芯片尺寸意味著更便宜的芯片,更低的功耗意味著更少的電力和冷卻消耗,從而降低整體 TCO。
UALink如何在中國市場落地
UALink國際互聯系統開發標準在中國的應用落地,需要產業鏈上下游的協同配合。因此,聯盟成員囊括了國內芯片制造商、以奇異摩爾為代表的芯粒廠商,以及交換機提供商等關鍵角色。在今年的ODCC春季全體會議上,ODCC新測組組長郭亮與UALink董事會成員孔陽博士簽署了MOU合作備忘錄,這標志著國內AI網絡Scale-up技術創新與應用將步入快車道。
奇異摩爾作為ALS系統及UALink聯盟的生態成員,正與阿里云等頭部云廠商、GPU廠商通力合作,通過制定生態標準、提供GPU IO Die(NDSA-G2G)等解決方案,加速國產大模型訓練推理技術的發展。
關于我們
AI網絡全棧式互聯架構產品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業領先的AI網絡全棧式互聯產品及解決方案提供商。公司依托于先進的高性能RDMA 和Chiplet技術,創新性地構建了統一互聯架構——Kiwi Fabric,專為超大規模AI計算平臺量身打造,以滿足其對高性能互聯的嚴苛需求。
我們的產品線豐富而全面,涵蓋了面向不同層次互聯需求的關鍵產品,如面向北向Scale out網絡的AI原生智能網卡、面向南向Scale up網絡的GPU片間互聯芯粒、以及面向芯片內算力擴展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產品共同構成了全鏈路互聯解決方案,為AI計算提供了堅實的支撐。
奇異摩爾的核心團隊匯聚了來自全球半導體行業巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯產品研發和管理經驗,致力于推動技術創新和業務發展。團隊擁有超過50個高性能網絡及Chiplet量產項目的經驗,為公司的產品和服務提供了強有力的技術保障。我們的使命是支持一個更具創造力的芯世界,愿景是讓計算變得簡單。奇異摩爾以創新為驅動力,技術探索新場景,生態構建新的半導體格局,為高性能AI計算奠定穩固的基石。
-
加速器
+關注
關注
2文章
823瀏覽量
38930 -
AI
+關注
關注
87文章
34274瀏覽量
275453 -
奇異摩爾
+關注
關注
0文章
54瀏覽量
3665
原文標題:生態共建 | UALink 加速器互聯協議聯盟1.0版本正式發布
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
奇異摩爾以互聯之長推進OISA GPU卡間互聯生態適配

奇異摩爾受邀出席第三屆HiPi Chiplet論壇
衢州市領導蒞臨奇異摩爾考察調研
蘋果加入UALink聯盟,共推AI加速器新標準
奇異摩爾分享計算芯片Scale Up片間互聯新途徑

奇異摩爾加入UALink加速器間互聯協議聯盟
潤欣科技與奇異摩爾簽署CoWoS-S封裝服務協議
摩爾斯微電子推出社區論壇與開源GitHub資源庫,新資源的上線將加速全球工程師與開發者的Wi-Fi開發進程
智原科技與奇異摩爾2.5D封裝平臺量產
奇異摩爾賦能萬卡集群互聯
是德科技加入AI-RAN聯盟,推動無線網絡AI創新
摩爾線程攜手東華軟件完成AI大模型推理測試與適配
奇異摩爾上海總部進駐上海浦東科海大樓






 工商網監
工商網監
評論