 AI演進的核心哲學:使用通用方法,然后Scale Up!
AI演進的核心哲學:使用通用方法,然后Scale Up!
作者:算力魔方創始人/英特爾創新大使劉力
一,AI演進的核心哲學:通用方法 + 計算能力
Richard S. Sutton在《The Bitter Lesson》一文中提到,“回顧AI研究歷史,得到一個AI發展的重要歷史教訓:利用計算能力的通用方法最終是最有效的,而且優勢明顯”。核心原因是摩爾定律,即單位計算成本持續指數級下降。大多數 AI 研究假設可用計算資源是固定的,所以依賴人類知識來提高性能,但長期來看,計算能力的大幅提升才是推進AI演進的關鍵。
《The Bitter Lesson》原文鏈接:
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
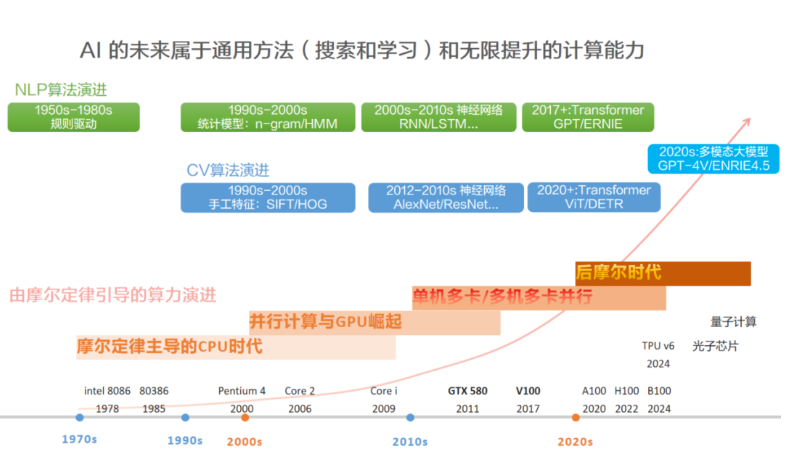
把不同時期的AI代表算法和典型計算硬件放到一起,可以看出,依賴人類知識的算法(比如手工設計規則)在某段時期內效果暫時領先,但隨著計算能力的發展,會被 “更通用的方法 + 更強的計算” 碾壓。計算機視覺和自然語言處理的算法演進,都符合這個規律。
計算機視覺:在CPU時代,手工特征(SIFT/HOG) + SVM的方法暫時領先。到了GPU時代,基于更通用的方法(CNN) + 更強的計算(GTX-580)的AlexNet在2012年,以15.3%的Top-5 錯誤率碾壓了所有基于人類手工提取特征的方法。在多卡并行時代,Transformer擯棄了CNN注入的人類知識(認為相鄰像素關聯性強),使用自身的自注意力能力自行捕捉全局依賴,使得通用目標識別水平更上一層樓,碾壓CNN。
自然語言處理:在CPU時代,最初使用n-gram方法學習單詞分布,以此通過前一個字符來預測后一個字符(單詞分布決定字符關聯就是人類知識)。n-gram的記憶能力有限,能生成一定長度的語句,但在幾十個詞規模的生成能力就不行了。到了GPU時代,更通用的方法RNN,可以逐個閱讀單詞的同時更新思維狀態,具備了短期記憶能力;LSTM在RNN基礎上增加了長期記憶能力,能在百詞內較好的生成內容,但在幾百詞的生成規模上,就會逐漸偏離主題。在多卡并行時代,Transformer擯棄了RNN注入的人類知識(時序依賴關系是關鍵,當前狀態依賴歷史狀態),使用自身的自注意力能力自行捕捉長程依賴,其生成能力在多個領域能超過人類水平,碾壓RNN。
AI 的未來屬于通用方法(搜索和學習)+ 無限提升的計算能力,而不是人類對具體問題的 “聰明解法”。越通用的人工智能,方法應該越簡單,建模時應該越少人類知識的假設才對。我們應該讓 AI 自己通過計算和數據去發現規律,而不是教它 “我們認為正確”的東西。
二,Transformer: 更加通用的神經網絡架構
《Attention is All You Need》在2017年首次提出了一種全新的神經網絡架構Transformer架構,它完全基于注意力機制,從全局角度“觀察和學習”數據的重要特征,相比循環神經網絡(RNN)和卷積神經網絡(CNN),注入的人類先驗知識更少,方法更通用:
CNN注入了相鄰像素關聯性強的人類知識,導致CNN無法處理不具備該假設的信息,例如:自然語言。
RNN假設了“時序依賴關系”是關鍵,當前狀態依賴歷史狀態(通過隱藏狀態傳遞信息),導致RNN無法處理不具備該假設的信息,例如:圖像。
Transformer使用自身的自注意力能力自行捕捉數據中的關系,即通過自注意力能力從全局角度“觀察和學習”數據的重要特征。只要信息能從全局角度被觀察和學習,那么該信息就能被Transformer處理。文本、圖像、聲音等信息,都滿足該要求,所以,都能統一到Transformer架構上進行處理。各種模態信息在進入Transformer前,只需要把信息Token化,即切成一個個小塊就行。
《Attention is All You Need》原文鏈接:
https://arxiv.org/pdf/1706.03762
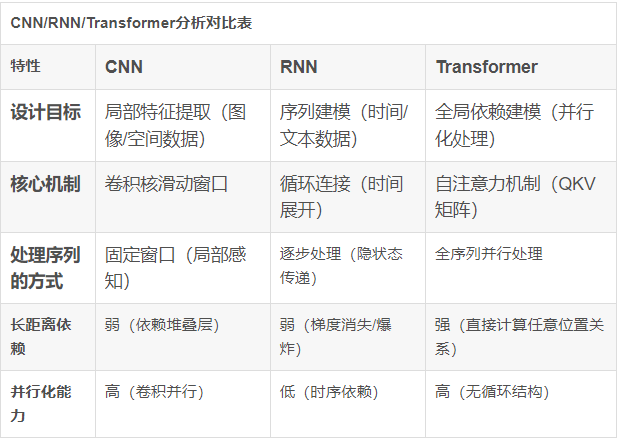
CNN/RNN/Transformer分析對比表
在多機多卡算力時代,Transformer是比CNN和RNN更加通用的神經網絡架構。
三,Decode-Only: 更加通用的大語言模型架構
《Attention is All You Need》提出了Transformer架構后,大語言模型的技術探索出現三個方向:僅使用左邊紅色框部分的Encoder-Only,僅使用右邊綠色框的Decoder-Only和全部都使用的Encoder-Decoder。???????
《Attention is All You Need》原文鏈接:
https://arxiv.org/pdf/1706.03762
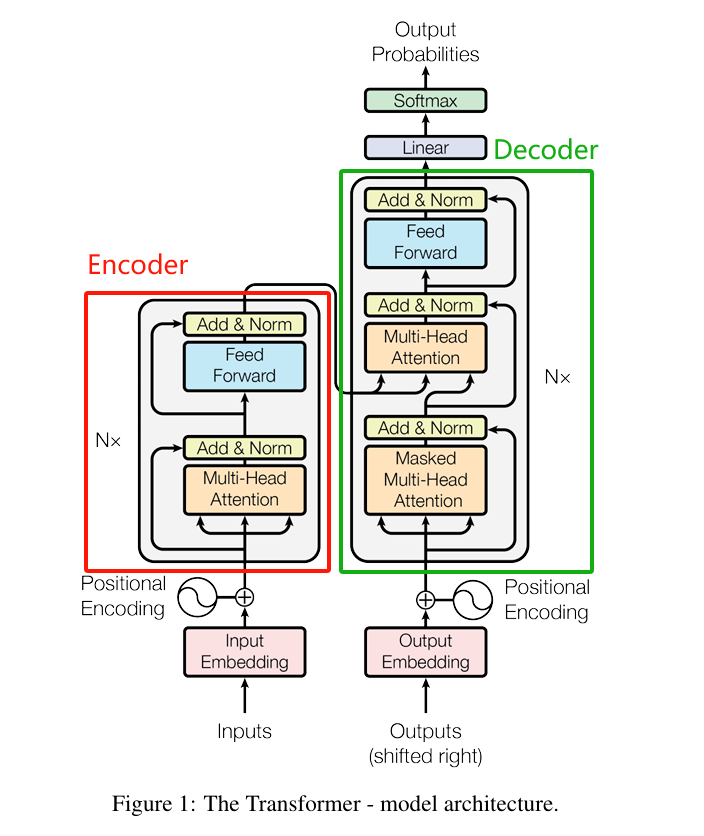
Encoder-Only:僅使用左邊紅色框中的編碼器部分構建大語言模型,這個方向一開始主要有Google、Baidu等參與,代表模型有BERT、ERNIE等。Encoder-Only模型是掩碼語言模型(Masked Language Model),使用雙向注意力機制,即訓練模型時,提供預測字符的雙向上下文,這有點兒類似完形填空,從一句話中隨機挖掉一個字(例如:白_依山盡),然后預測被挖掉字。由于模型能獲得預測字符之前(過去)和之后(未來)的上下文,所以能高效學習上下文語義,體現出強大的文本語義理解能力,常用于情感分析、閱讀理解和文本分類等任務。但也正是由于模型在預測時同時受過去和未來雙向的上下文限制,導致在生成文本時表現質量不高和多樣性低,不太符合用戶的預期。隨著 AI 應用向文本創作、對話系統、代碼生成等方向擴展,Encoder-only 架構難以滿足AIGC應用的生成需求,所以,在2021年后,這個方向就停止演進了。
Decoder-Only: 僅使用右邊綠色框中的解碼器部分構建大語言模型,這個方向主要由OpenAI主導,代表模型是GPT系列模型。Decoder-Only模型是自回歸語言模型(Autoregressive Language Modeling),使用因果注意力機制,即訓練模型時,不能看見右側(未來)的上下文,只能使用左側(過去)的上下文預測下一個字符(Token),這有點兒類似故事續寫,給出前面的字(例如:白_),然后預測下一個字。由于模型只能獲得預測字符之前(過去)的上下文,訓練起來更難,需要更大的數據集和更強的算力。2020年發布的GPT-3證明了 Decoder-Only 架構在大規模數據上能夠更好地學習語言的統計規律和模式,不僅在生成文本時表現出更高的質量和多樣性,還顯著增強了語言理解的能力,使得模型能夠更好地理解用戶的意圖和需求,并據此生成更加符合用戶期望的文本。由此,在2021年后,Google、Baidu、Meta等廠家都轉向了Decoder-Only架構。
Encoder-Decoder:同時使用編碼器和解碼器部分構建大語言模型,這個方向主要由Google、ZhipuAI在探索,代表模型有T5、GLM等。該構架雖然能兼顧Encoder-Only和Decoder-Only架構的優勢,但相對Decoder-Only架構,訓練成本高2~5倍、推理成本高2~3倍,所以,僅用于一些需要嚴格雙向理解的細分領域(如多模態生成任務),其發展被 Decoder-only 大大超越。
JINGFENG YANG等在《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,
https://arxiv.org/pdf/2304.13712
展現出了大語言模型架構的演進全景圖。上述演進趨勢可以從下圖中看出:
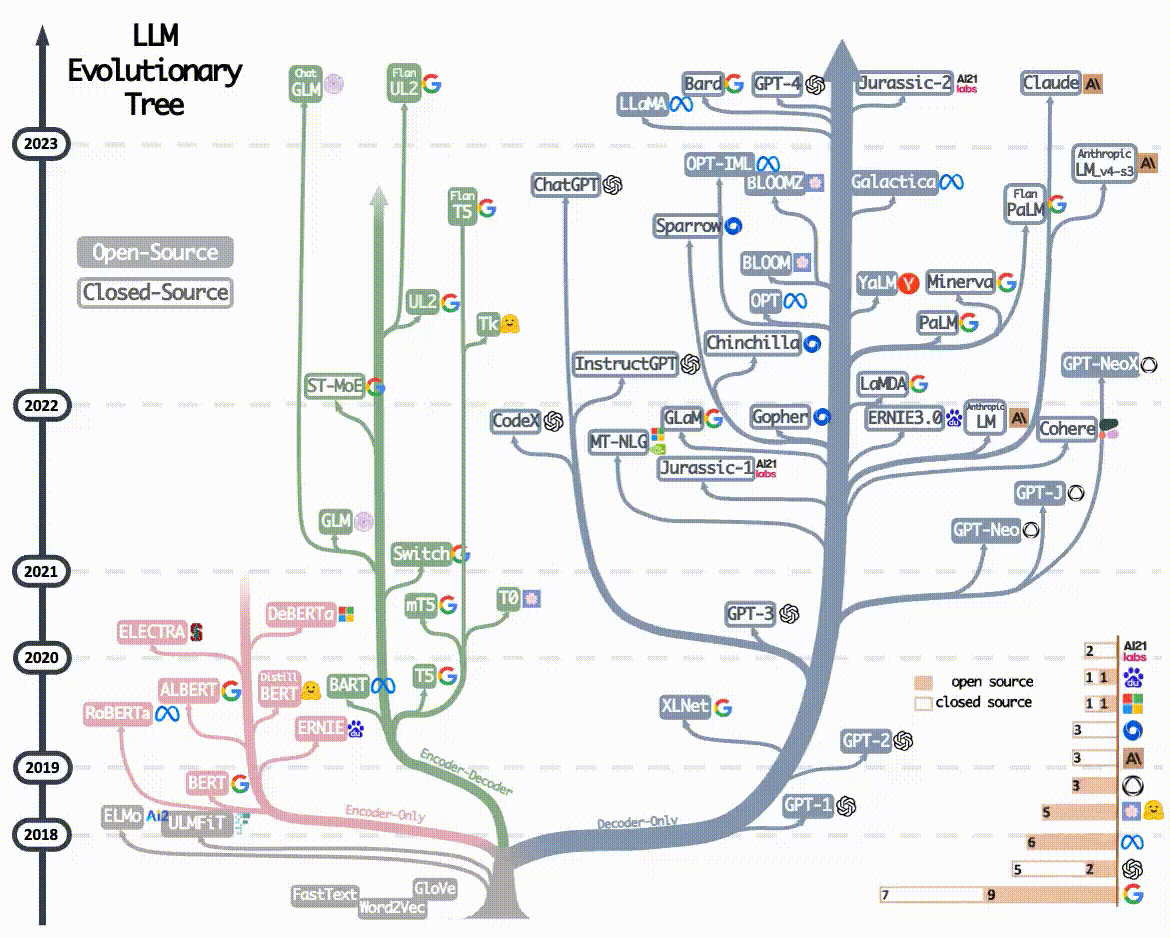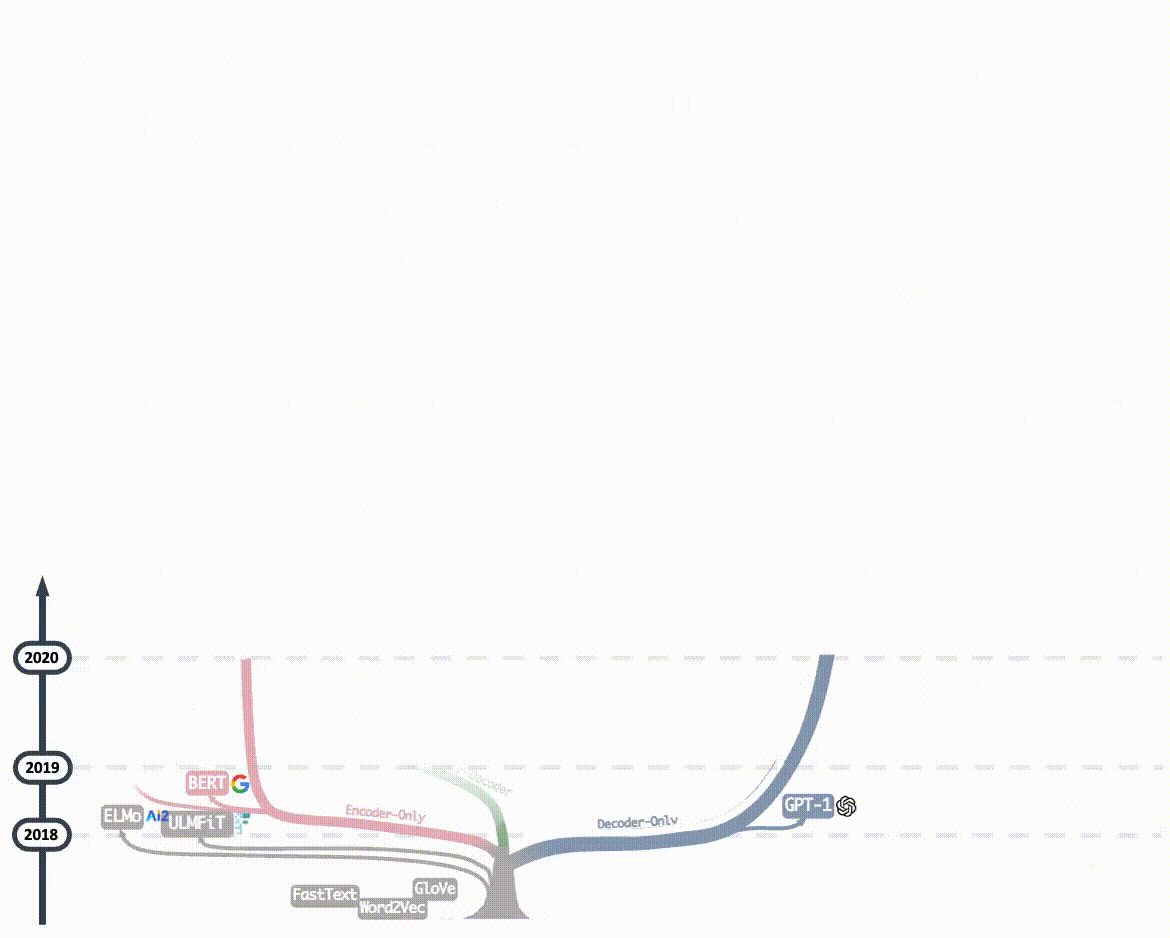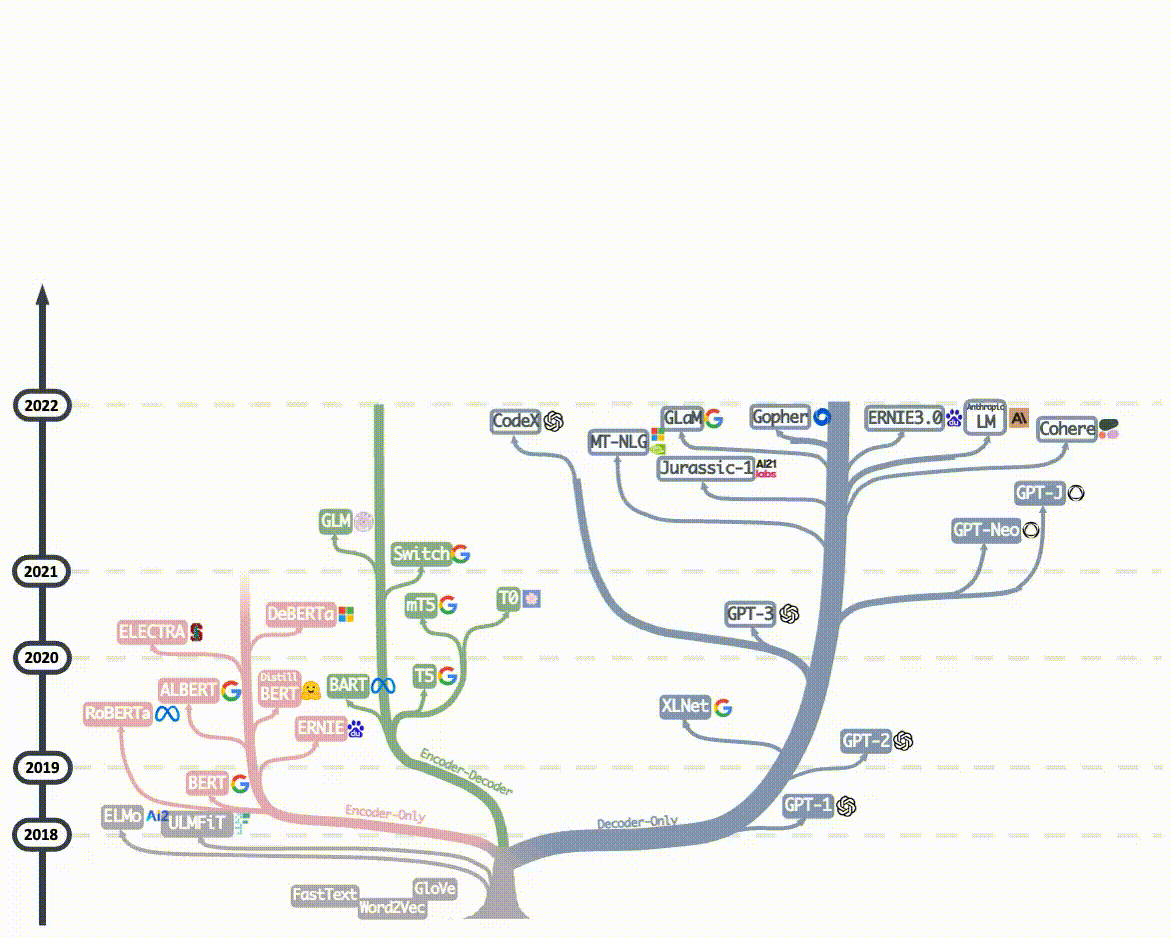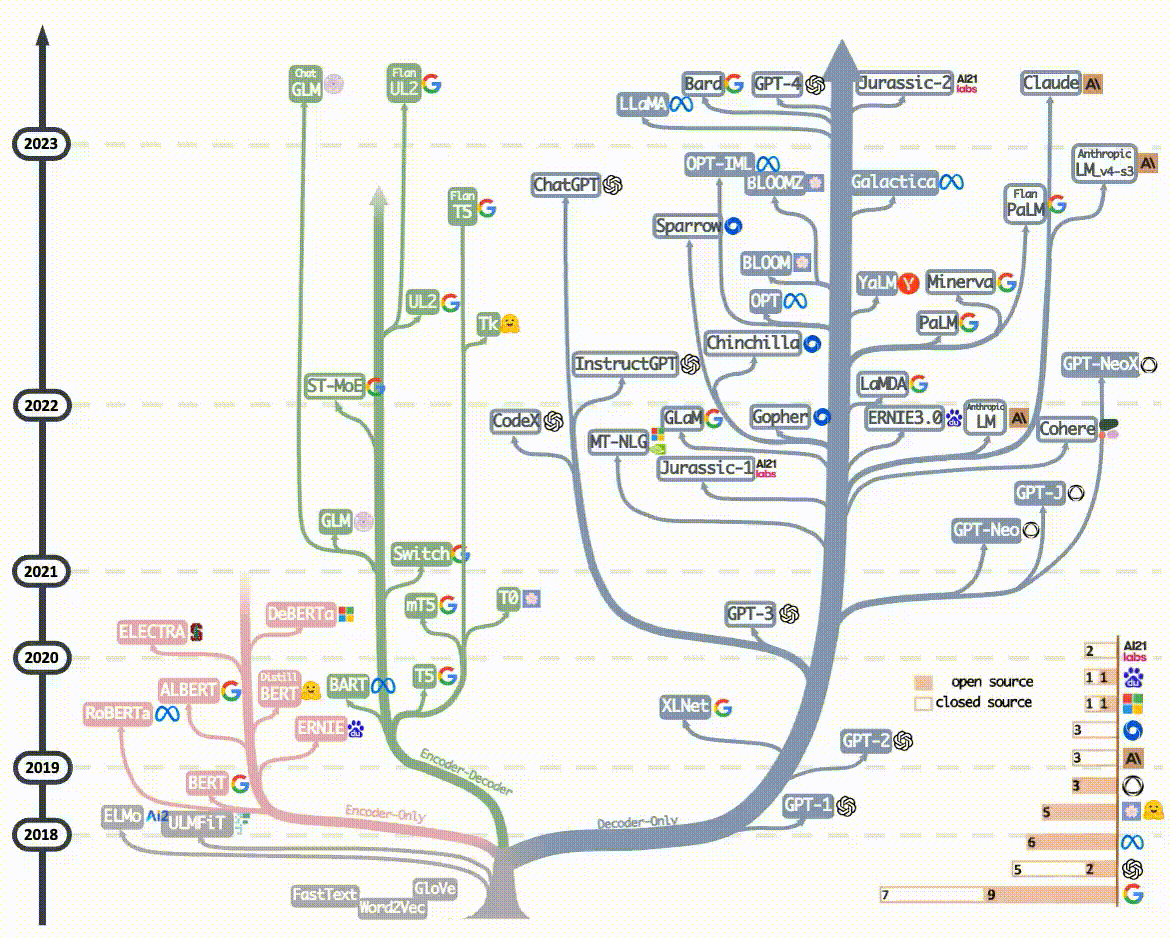
2023年后的主流大語言模型(如GPT-4、ERNIE4.0、Llama3...)均采用Decoder-Only架構,核心原因正是 Decoder-Only架構比其它兩個架構更簡單、更通用,在計算能力飛速發展的大趨勢下, Decoder-Only架構擁有更大的Scale up的潛力 -- 即保持核心架構不變的情況下,通過增加訓練數據,擴大模型參數規模和提升計算能力,可以進一步提升模型能力。
四???????,總結
大語言模型的演進過程,再次證明了Richard S. Sutton在《The Bitter Lesson》
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
提到的AI能力演進的哲學思想:使用通用方法,然后借助計算能力Scale Up。
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:[email protected]
更多精彩內容請關注“算力魔方?”!
審核編輯 黃宇
-
AI
+關注
關注
87文章
34173瀏覽量
275339 -
語言模型
+關注
關注
0文章
558瀏覽量
10668
發布評論請先 登錄
一文詳解基于以太網的GPU Scale-UP網絡

Scale out成高性能計算更優解,通用互聯技術大有可為

Unix哲學歸納
AI的核心是什么?
深度學習推理和計算-通用AI核心
AGI:走向通用人工智能的【生命學&哲學&科學】第一篇——生命、意識、五行、易經、量子 精選資料分享
TB-96AI是什么?TB-96AI核心板有哪些核心功能
CDMA2000核心網演進組網策略探討

IBM推出專為AI打造的全新Storage Scale System 6000
人工智能初創企業Scale AI融資10億美元
奇異摩爾分享計算芯片Scale Up片間互聯新途徑






 工商網監
工商網監
評論