") 拿高薪必備的深度學習nlp技術,這篇文章講得很透徹
拿高薪必備的深度學習nlp技術,這篇文章講得很透徹
過去幾年,深度學習架構和算法在圖像識別和語音處理等領域取得了重大的進步。而在NLP(自然語言處理)領域,起初并沒有太大的進展。不過現(xiàn)在,NLP領域取得的一系列進展已證明深度學習技術將會對自然語言處理做出重大貢獻。一些常見的任務如實體命名識別,詞類標記及情感分析等,自然語言處理都能提供最新的結果,并超越了傳統(tǒng)方法。另外,在機器翻譯領域的應用上,深度學習技術所取得的進步應該是最顯著的。
這篇文章中,我將在通過一些深度學習技術來闡述2017年NLP領域所取得的一系列進步。相關的科技論文,框架和工具有很多,在這里我沒辦法逐一列出,內(nèi)容也不詳盡。我只是想和大家分享并介紹今年一系列我最喜歡的研究。
我認為,2017年是深度學習的一個重要年份,隨著深度學習技術在NLP領域中的應用不斷深入且產(chǎn)生了令人驚喜的結果,所有的跡象都表明,NLP領域將在深度學習技術的輔助下繼續(xù)高效前進。
從訓練word2vec到使用預訓練模型
可以說,詞嵌入模型(Word embedding)是深度學習技術在NLP領域最顯著的技術。他們遵循了Harris (1954) 提出的分布式假說。根據(jù)這個假說可知,具有相似含義得此通常會出現(xiàn)在上下文的語境中。關于詞嵌入的詳細解釋,你也可以閱讀Gabriel Mordecki的文獻。
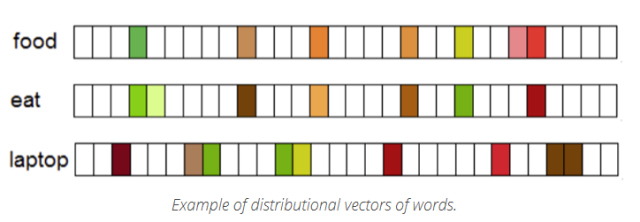
諸如word2vec(Mikolov等,2013)和Glove(Pennington等,2014)等算法已經(jīng)成為NLP領域的代表性算法。盡管它們不能被認為是深度學習技術在該領域的應用(word2vec中應用淺層神經(jīng)網(wǎng)絡,而Glove是基于計數(shù)模型的一種算法),但是用他們訓練得到的模型作為大量深度學習模型的輸入,也是深度學習技術與自然語言處理領域相結合的一種常見方式。因此,目前在我們領域中應用詞嵌入模型,通常被視為是一種好的嘗試。
一開始,給定一個需要詞嵌入模型的NLP問題,我們更希望在一個與領域相關的大語料庫中訓練我們自己的模型。當然,這不是使用詞嵌入模型最好的方式,所以需要從預訓練模型開始慢慢進行。通過維基百科,Twitter,Google新聞,網(wǎng)頁抓取等數(shù)據(jù)的訓練,這些模型可以很容易地讓你將詞嵌入模型整合到深度學習算法中去。
今年的研究進展證實了預訓練詞嵌入模型仍然是NLP領域的一個關鍵性的問題。例如,來自Facebook AI Research(FAIR)實驗室的fastText模型,用294種語言發(fā)布預訓練好的模型向量,這是一項偉大的工作,對于我們研究領域來說更是一重大的貢獻。除了大量的語言的使用,由于fastText使用字符n-grams作為語義特征,使得該模型能夠得到很大的應用。
此外,fastText模型還能避免OOV問題(超出詞匯量問題),因為即使是一個非常罕見的詞(如特定領域的專業(yè)術語)也有可能與一個常見詞共享同一個n-gram字符。因此,從這個意義上來說,fastText模型比word2vec和Glove模型表現(xiàn)得更好,并且對于小數(shù)據(jù)庫有著更優(yōu)的性能。
然而,盡管我們可以看到該領域一些進步,但是對這領域的研究還有很長一段路要走。例如,著名的NLP框架spaCy以本地的方式將詞嵌入模型和深度學習模型集成并應用到諸如NER和Dependency Parsing等NLP任務中,并允許用戶更新模型或使用自己的模型。
我認為這是需要研究的東西。未來,對于這些易于應用到特定領域(諸如生物學,文學,經(jīng)濟學等)的NLP框架來說,進行預訓練得到模型是一種非常好的方式。根據(jù)我們的情況,以最簡單的方式對模型進行一系列的微調優(yōu)化,來提高模型的性能。同時,一些適用于詞嵌入模型的方法也開始慢慢出現(xiàn)。
調整通用嵌入模型應用于特定的案例
也許使用預訓練的詞嵌入模型的最大缺點是訓練數(shù)據(jù)與我們問題中使用的實際數(shù)據(jù)之間存在詞分布差距(word distributional gap)。這么說吧,假設你有生物學論文集,食譜和經(jīng)濟領域的研究文章,由于你可能沒有足夠大的語料庫來訓練得到良好性能的詞嵌入模型,所以你需要通用嵌入模型來幫助你改善研究結果。但是如果通用嵌入模型可以進行調整并應用于你所需要的特定案例呢?
這個想法是簡單而又有效的。想象一下,我們知道在源域中單詞w的詞嵌入是w_s。為了計算w_t(目標域)的嵌入,作者向w_s添加了兩個域之間的一定量的傳輸。基本上,如果這個詞在這兩個領域出現(xiàn)的都很頻繁,那就意味著它的語義不具有領域依賴性。
在這種情況下,由于傳輸量很高,因此在兩個域中產(chǎn)生的詞嵌入趨勢是相似的。但是,對于特定領域的詞,會在一個領域出現(xiàn)的更頻繁,所需要傳輸?shù)牧渴呛苄〉摹?/span>
關于詞嵌入的研究課題至今還沒有得到廣泛的研究和探索,但我認為在近期會得到更多的關注。
情感分析將有一個難以置信的作用
今年,Ranford等人發(fā)現(xiàn)訓練模型中的單個神經(jīng)元對于情感價值有著高度的預測性,為進一步預測Amazon評論文本中的下一個字符,他們探索了字節(jié)級循環(huán)語言模型的特性。結果表明,這個單一的“情感神經(jīng)元”的確能夠相當準確地預測并將評論分類為正負面。
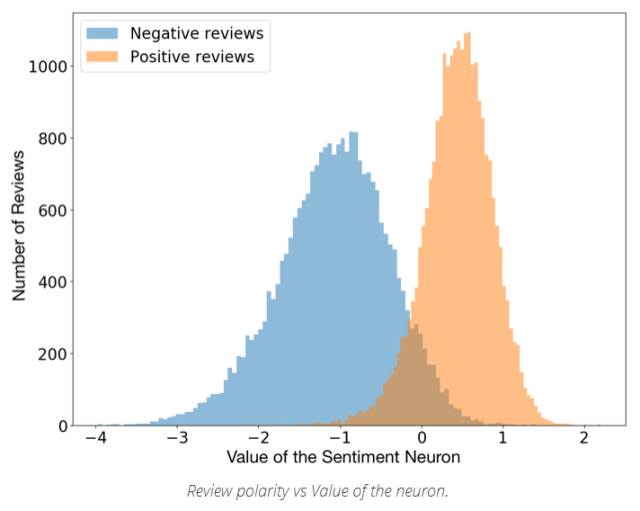
注意到這種行為之后,他們決定在 Stanford Sentiment Treebank數(shù)據(jù)庫上測試模型,并發(fā)現(xiàn)模型的準確性高達91.8%,而之前最好的模型準確度為90.2%。這說明,使用很少的樣本,以無監(jiān)督的方式進行訓練的模型,至少在一個特定但廣泛研究的數(shù)據(jù)庫上得到了最先進的情感分析結果。
工作中的情感神經(jīng)元
由于模型的表現(xiàn)是基于字符水平的,所以神經(jīng)元在文本中改變了每個字符的狀態(tài),這是相當驚人的行為。
例如,在一個單詞后面,神經(jīng)元的值變?yōu)閺姷恼担欢@種作用效果將隨著詞的消失而消失,這看起來也是有道理的。
生成帶極偏見性文本
當然,訓練好的模型仍然是一個有效的生成模型,所以它可以用來生成類似Amazon評論的文本。但是,我覺得很棒的是,你可以通過簡單地覆蓋情感神經(jīng)元的價值來選擇生成樣本的極性。

文本生成示例(來源-https://blog.openai.com/unsupervised-sentiment-neuron/)
Krause等(2016)所選擇的NN模型是由Krause等人提出的乘式LSTM模型。這是因為他們觀察到,該模型的超參數(shù)設置方式能比正常的LSTM模型更快地收斂。它有4096個神經(jīng)元,并用8200萬條Amazon的評論語料庫來進行訓練。
為什么訓練有素的模型能夠準確地捕捉到情感概念中一些開放而迷人的問題呢。與此同時,你也可以嘗試訓練自己的模型并進行實驗。當然,如果你有充裕的時間和GPU的話,那么用四款NVIDIA Pasca GPUs,對這個特定的模型進行訓練,仍需要花費一個月時間才能完成。
Twitter上的情感分析
無論是人們對企業(yè)品牌的評價,分析營銷活動的影響,還是衡量上次競選期間民眾對希拉里·克林頓和唐納德·特朗普的整體感受,Twitter的情感分析都是一個非常強大的工具。
SemEval 2017
Twitter上的情感分析已經(jīng)引起了NLP研究人員的興趣,同時也得到政治和社會科學界的廣泛關注。這就是為什么自2013年以來,SemEval比賽都會提出一系列具體的任務。
今年的比賽共有48支參賽隊伍參與了競賽,表現(xiàn)出極大的熱情和興趣。為了讓你更好地了解Twitter推出的SemEval比賽究竟是什么(http://www.aclweb.org/anthology/S17-2088),讓我們來看看今年提出的五個子任務。
-
子任務A:給定一個推文,來判斷所表達的情緒是積極的、消極的還是中性的。
-
子任務B:給定一個推文和一個話題,分兩種情況下表達對這個話題的觀點:正面與負面。
-
子任務C:給定一個推文和一個話題,分五種情況來表達對這個話題的觀點:強勢、弱勢、中性、弱肯定性和強大的消極。
-
子任務D:給定一個關于某個話題的推文,評估推文在正性和負性類別中的分布情況。
-
子任務E:給定一組關于某個話題的推文,評估推文在五中情緒類別中的分布情況:強勢、弱勢、中性、弱弱及強大。
正如你所看到的,子任務A是最常見的任務,有38個團隊參與了這個任務的評估,而其他的任務則更具挑戰(zhàn)性。今年有20支團隊使用了卷積神經(jīng)網(wǎng)絡(CNN)和長短期記憶網(wǎng)絡(LSTM)模型。此外,盡管SVM模型仍然非常流行,但是一些參賽隊伍都將它與神經(jīng)網(wǎng)絡的方法或詞嵌入特征相結合。
BB_twtr系統(tǒng)
今年讓我比較驚奇的發(fā)現(xiàn)是BB_twtr系統(tǒng)(Cliche,2017),它是一個純粹的深度學習系統(tǒng),并且在英語的5個子任務中排名第一。 作者將10個CNN結構和10個biLSTM結構集合(ensemble)起來,采用不同的超參數(shù)和預訓練策略來進行訓練。
為了訓練這些模型,作者使用了人工標注的推文(tweets)(給定一個數(shù)量級,子任務A有49,693個),并且構建了一個包含1億條推文的未標記數(shù)據(jù)集,這個數(shù)據(jù)集只是通過簡單的標記一條推文來獲取,比如表示推文內(nèi)容積極的表情符號是:-),對于內(nèi)容消極的推文就是相反的表情。這些推文中的小寫,標記,URL和表情符號被替換為特定的標記(,, etc.),并且字符重復的內(nèi)容將會統(tǒng)一,例如,“niiice”和“niiiiiiiice”變成“niice”。
為了對用作CNN和biLSTM結構輸入的單詞嵌入信息進行預訓練,作者在未標記的數(shù)據(jù)集上使用了word2vec,GloVe和fastText(全部使用默認設置)詞向量。然后他使用距離數(shù)據(jù)集(distant dataset)來提煉嵌入特征是為了增加作用力信息,然后使用人工標記的數(shù)據(jù)集再次提取它們的特征。
作者使用以前的SemEval數(shù)據(jù)集進行實驗表明,使用GloVe詞向量會降低性能,而且對于所有好的數(shù)據(jù)集都沒有唯一的最佳模型。 然后作者將所有模型與軟投票策略結合起來。 由此產(chǎn)生的模型結果比2014年和2016年的歷史最好的歷史成績更勝一籌,而且也與其他年份非常接近。最后,它在2017自然語言競賽 SemEval 數(shù)據(jù)集5子任務中排名第一。
即便這種組合采取的簡單的軟投票策略并不能看作是一種有效的方式,但是這項工作表明了將深度學習模型結合起來的可能性,以及一種幾乎端到端的方法(輸入必須經(jīng)過預處理 )。并且是在Twitter的情感分析中是可以超越監(jiān)督方法的。
一個令人興奮的抽象概括系統(tǒng)
自動概括和自動翻譯一樣,是最早的NLP任務之一。目前有兩種主要的方法:基于提取的方法,其概括是通過從源文本中提取最重要的段而建立的,而基于抽象的方法則是通過生成文本來構建概括。
從發(fā)展歷史上看,基于提取的方法是最常用的,因為它們比基于抽象的方法簡單。在過去的幾年里,基于RNN的模型在文本生成方面取得了驚人的成果。它們在簡短的輸入輸出文本上表現(xiàn)得非常好,但是對于長文本往往是不連貫和重復的。
在Paulus等人的工作中,他們提出了一種新的神經(jīng)網(wǎng)絡模型來克服這個局限性。結果令人興奮,如下圖所示
生成概括的模型說明(https://einstein.ai/research/your-tldr-by-an-ai-a-deep-reinforced-model-for-abstractive-summarization)
作者使用了一個biLSTM編碼器來讀取輸入和一個LSTM解碼器來產(chǎn)生輸出。他們的主要貢獻是一種新的內(nèi)部注意(intra-attention)策略,這種策略是分別關注輸入和連續(xù)產(chǎn)生的輸出,和一種結合了標準的有監(jiān)督的詞預測和強化學習的新的訓練方法。
內(nèi)部注意策略
提出內(nèi)部注意策略的目的是為了避免輸出中的重復。為了達到這個目的,它們在解碼時使用時間上的注意力來查看輸入文本的已輸入片段,然后決定下一個將要產(chǎn)生的字。這迫使模型在生成過程中使用輸入的不同部分。他們還允許模型訪問解碼器以前的隱藏狀態(tài)。然后將這兩個函數(shù)組合起來,為輸出概括選擇最好的下一個單詞。
強化學習
為了創(chuàng)建一個概括,需要兩個不同的人使用不同的單詞和句子順序,這兩個概括才可能被認為是有效的。因此,一個好的概括不一定非要是盡可能匹配訓練數(shù)據(jù)集中單詞序列的序列。
由于知道這一點,作者沒有采用標準的教師強迫算法來使每個解題步驟的損失最小化,而是依靠強化學習策略,并且證明了這是一個很好的選擇。
幾乎是端到端模型最好的結果
該模型在美國有線電視新聞網(wǎng)和每日郵報數(shù)據(jù)集上進行了測試,并取得了最先進的成果。此外,一項帶有人類評估者的具體實驗結果也顯示了人類對于生成的文本在可讀性和質量方面的提高。
這些結果是令人欽佩的,該模型的基本預處理過程是:輸入文本進行分詞,小寫字母,數(shù)字用“0”替換,然后刪除數(shù)據(jù)集中一些特定的實體。
邁出無監(jiān)督機器翻譯的第一步?
雙語詞典歸納,即用兩種語言的源語和單語語料庫來識別單詞翻譯對,這其實是一個古老的NLP任務。自動生成的雙語詞典有助于其他的NLP任務,如信息檢索和統(tǒng)計機器翻譯。 然而,這些方法大部分時間都依賴于某種資源,通常是一個初始的雙語詞典,但是這個詞典并不總是可用或者很容易建立。
隨著詞嵌入方法的成功,跨語言詞嵌入的設想也出現(xiàn)了,目標是對齊嵌入空間而不是詞典。 不幸的是,第一種方法也依賴于雙語詞典或平行的語料庫。Conneau等(2018)提出了一個非常超前的方法,它不依賴于任何特定的資源,并且在多個語言對(language pairs)的語言翻譯,句子翻譯檢索和跨語言單詞相似性三個任務上優(yōu)于現(xiàn)有的監(jiān)督方法。
作者開發(fā)的方法是將輸入的兩組單詞嵌入在單語數(shù)據(jù)上進行獨立訓練來學習它們之間的映射,使得翻譯后的內(nèi)容在空間上接近。他們使用fastText詞向量是在維基百科文檔上訓練出無監(jiān)督的詞向量。
以下圖片詮釋了他們的核心想法:
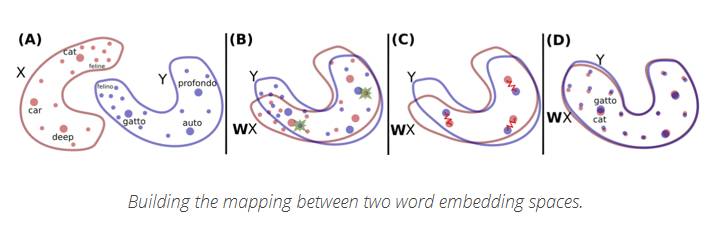
建立兩個詞在嵌入空間之間的映射(https://arxiv.org/abs/1710.04087)
紅色的X分布是英語單詞的嵌入,藍色的Y分布是意大利語單詞的分布。
首先,他們使用對抗學習(adversarial learning-https://en.wikipedia.org/wiki/Adversarial_machine_learning)來學習用于第一次原始對齊的旋轉矩陣W.。他們根據(jù)Goodfellow等人在2014年提出的想法,主要是是訓練了一個生成對抗網(wǎng)絡(GAN)。要了解GAN是如何工作的,我建議你讀這篇由Pablo Soto撰寫的文章(https://tryolabs.com/blog/2016/12/06/major-advancements-deep-learning-2016/)。
為了在對抗學習方面對問題進行建模,他們將判別器定義為確定的角色,給定從WX和Y隨機采樣的一些元素(參見上圖中的第二列),每個元素代表一種語言。然后,他們訓練W以防止判別器做出好的預測。
這在我看來非常聰明和優(yōu)雅的做法,并且直接得出的結果也是相當不錯的。
之后,他們再采用了兩個步驟來完善整個映射。第一個步驟是為了避免映射計算中由罕見字引入的噪聲。另一個步驟是為了使用學習的映射和距離度量來建立實際的翻譯。
在某些情況下的結果是非常好的。 例如,對于英語—意大利語之間單詞的翻譯,在P @ 10的情況下,他們勝過了最佳平均精確度近17%。
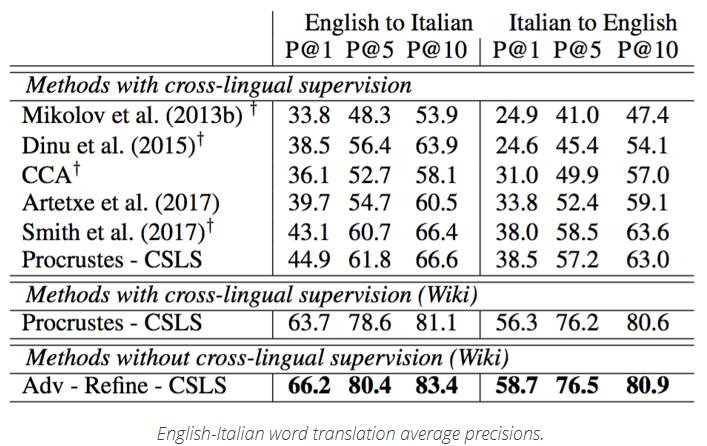
英語-意大利語單詞翻譯的平均精度
作者聲稱,他們的方法可以看作是邁向了無監(jiān)督機器翻譯的第一步。我們可以看一看這個新的有前景的方法到底能走多遠。
專業(yè)化的框架和工具
通用的DL框架和工具有很多種,比如說被廣泛應用的Tensorflow,Keras還有PYTorch。不過,具體到開源的NLP方向的DL框架和工具卻剛嶄露頭腳。今年對我們來說是非常棒的一年,因為有很多有用的開源框架已經(jīng)在社區(qū)里實現(xiàn)了。這其中有三個框架吸引了我的注意力,我覺得各位肯定也會非常感興趣。
Allen NLP
Allen NLP 框架(http://allennlp.org/papers/AllenNLP_white_paper.pdf)是建立在PyTorch之上的平臺,設計之初的目的是為了在語義NLP的任務中用起來更簡單。它的目的是讓研究者能夠設計和評價新的模型。它包括了通用語義NLP任務中的模型的參考實現(xiàn),這些任務包括語義角色標簽、文本蘊含以及共指消解。
Parl AI
Parl AI框架(https://arxiv.org/pdf/1705.06476.pdf)是一個針對對話研究的開源軟件平臺。該平臺是用Python來實現(xiàn)的,旨在為分享、訓練以及對話模型測試提供一個聯(lián)合框架。ParlAI提供了一個非常簡單的可以與亞馬遜的Mechanical Turk合并機制。它也提供了當下很流行的數(shù)據(jù)集并且支持好幾種模型,包括神經(jīng)模型,例如:記憶網(wǎng)絡、seq2seq和LSTMs。
Open NMT
OpenNMT工具集是一個通用的針對序列到序列的模型的框架。它可以用來執(zhí)行機器翻譯、總結以及圖像到文字、語音識別的任務。
終極思考
DL技術的使用在解決NLP問題中的穩(wěn)步增長是不容置疑的。最能說明的一個指標就是過去幾年中,深度學習論文中使用關鍵NLP會議中的占比的變化,例如ACL、EMNLP、EACL和NAACL。
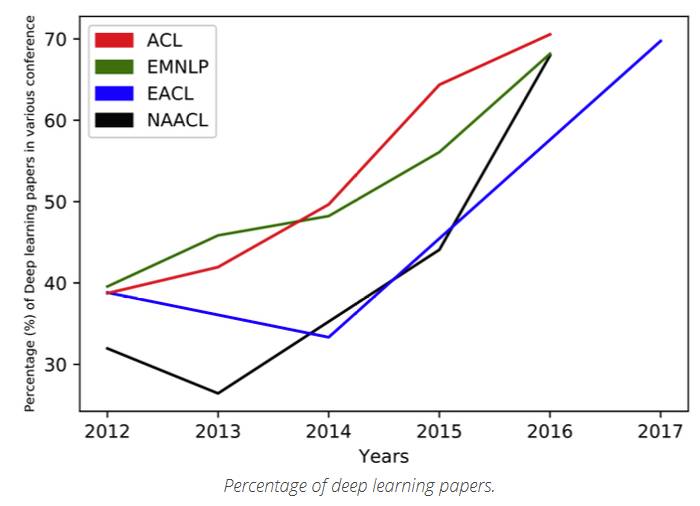
深度學習論文的比例
然而,真正的端到端的學習才剛剛開始。我們正在處理典型的NLP任務來為數(shù)據(jù)集做準備,例如,清理,標記化或者一些實體的統(tǒng)一(例如:URL,數(shù)字、電子郵箱等)。我們也用通用的嵌入式,缺點就是它們不能抓住特殊領域的關鍵詞的重要性,而且它們在多文字表達中表現(xiàn)的很糟糕,這是我在工作的項目中反復發(fā)現(xiàn)的一個關鍵問題。
對應用于NLP的深度學習來說,今年是非常不錯的一年,希望2018年能有更多端到端的學習著作,能有更多趨于成熟的開源框架。你可以在評論區(qū)和我們盡情分享你對這些著作和框架的思考和意見,更歡迎你分享本文沒有提到的框架和著作。
-
深度學習
+關注
關注
73文章
5554瀏覽量
122475 -
nlp
+關注
關注
1文章
490瀏覽量
22480
原文標題:盤點 2017 年深度學習 NLP 重磅技術
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
專欄 | 深度學習在NLP中的運用?從分詞、詞性到機器翻譯、對話系統(tǒng)
對2017年NLP領域中深度學習技術應用的總結
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

回顧2018年深度學習NLP十大創(chuàng)新思路

AI 深度學習 機器學習和NLP四種先進技術的不同

一文讀懂何為深度學習1
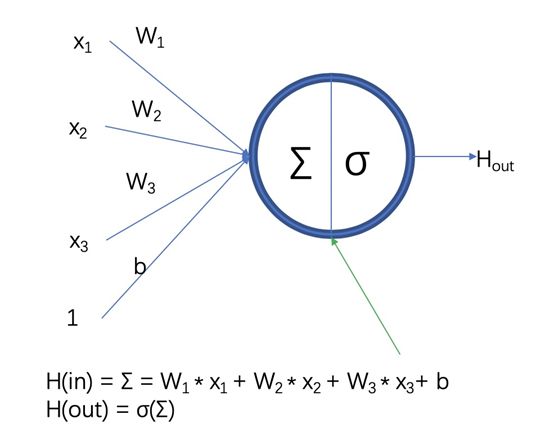
一文讀懂何為深度學習2
一文讀懂何為深度學習3






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論