") NLP中的深度學(xué)習(xí)技術(shù)概述
NLP中的深度學(xué)習(xí)技術(shù)概述
該項(xiàng)目是對(duì)基于深度學(xué)習(xí)的自然語(yǔ)言處理(NLP)的概述,包括用來(lái)解決不同 NLP 任務(wù)和應(yīng)用的深度學(xué)習(xí)模型(如循環(huán)神經(jīng)網(wǎng)絡(luò)、卷積神經(jīng)網(wǎng)絡(luò)和強(qiáng)化學(xué)習(xí))的理論介紹和實(shí)現(xiàn)細(xì)節(jié),以及對(duì) NLP 任務(wù)(機(jī)器翻譯、問(wèn)答和對(duì)話系統(tǒng))當(dāng)前最優(yōu)結(jié)果的總結(jié)。
該項(xiàng)目的主要?jiǎng)訖C(jī)如下:
維護(hù)最新 NLP 研究學(xué)習(xí)資源,如當(dāng)前最優(yōu)結(jié)果、新概念和應(yīng)用、新的基準(zhǔn)數(shù)據(jù)集、代碼/數(shù)據(jù)集發(fā)布等。
創(chuàng)建開(kāi)放性資源,幫助指引研究者和對(duì) NLP 感興趣的人。
這是一個(gè)合作性項(xiàng)目,專(zhuān)家研究人員可以基于他們近期的研究和實(shí)驗(yàn)結(jié)果提出變更建議。
第一章:簡(jiǎn)介
自然語(yǔ)言處理(NLP)是指對(duì)人類(lèi)語(yǔ)言進(jìn)行自動(dòng)分析和表示的計(jì)算技術(shù),這種計(jì)算技術(shù)由一系列理論驅(qū)動(dòng)。NLP 研究從打孔紙帶和批處理的時(shí)代就開(kāi)始發(fā)展,那時(shí)分析一個(gè)句子需要多達(dá) 7 分鐘的時(shí)間。到了現(xiàn)在谷歌等的時(shí)代,數(shù)百萬(wàn)網(wǎng)頁(yè)可以在不到一秒鐘內(nèi)處理完成。NLP 使計(jì)算機(jī)能夠執(zhí)行大量自然語(yǔ)言相關(guān)的任務(wù),如句子結(jié)構(gòu)解析、詞性標(biāo)注、機(jī)器翻譯和對(duì)話系統(tǒng)等。
深度學(xué)習(xí)架構(gòu)和算法為計(jì)算機(jī)視覺(jué)與傳統(tǒng)模式識(shí)別領(lǐng)域帶來(lái)了巨大進(jìn)展。跟隨這一趨勢(shì),現(xiàn)在的 NLP 研究越來(lái)越多地使用新的深度學(xué)習(xí)方法(見(jiàn)圖 1)。之前數(shù)十年,用于解決 NLP 問(wèn)題的機(jī)器學(xué)習(xí)方法一般都基于淺層模型(如 SVM 和 logistic 回歸),這些模型都在非常高維和稀疏的特征(one-hot encoding)上訓(xùn)練得到。而近年來(lái),基于稠密向量表征的神經(jīng)網(wǎng)絡(luò)在多種 NLP 任務(wù)上得到了不錯(cuò)結(jié)果。這一趨勢(shì)取決了詞嵌入和深度學(xué)習(xí)方法的成功。深度學(xué)習(xí)使多級(jí)自動(dòng)特征表征學(xué)習(xí)成為可能。而基于傳統(tǒng)機(jī)器學(xué)習(xí)的 NLP 系統(tǒng)嚴(yán)重依賴手動(dòng)制作的特征,它們及其耗時(shí),且通常并不完備。

圖 1:過(guò)去 6 年 ACL、EMNLP、EACL、NAACL 會(huì)議上深度學(xué)習(xí)論文的比例(長(zhǎng)論文)。
Ronan Collobert 等人 2011 年的研究《Natural Language Processing (Almost) from Scratch》展示了在多個(gè) NLP 任務(wù)上優(yōu)于當(dāng)時(shí)最優(yōu)方法的簡(jiǎn)單深度學(xué)習(xí)框架,比如命名實(shí)體識(shí)別(NER)、語(yǔ)義角色標(biāo)注(SRL)和詞性標(biāo)注。之后,研究人員提出了大量基于復(fù)雜深度學(xué)習(xí)的算法,用于解決有難度的 NLP 任務(wù)。本文綜述了用于自然語(yǔ)言任務(wù)的主要深度學(xué)習(xí)模型和方法,如卷積神經(jīng)網(wǎng)絡(luò)、循環(huán)神經(jīng)網(wǎng)絡(luò)和遞歸神經(jīng)網(wǎng)絡(luò)。本文還討論了記憶增強(qiáng)策略、注意力機(jī)制,以及如何使用無(wú)監(jiān)督模型、強(qiáng)化學(xué)習(xí)方法和深度生成模型解決語(yǔ)言任務(wù)。
本文綜述了 NLP 研究中最流行的深度學(xué)習(xí)方法,結(jié)構(gòu)如下:第二章介紹分布式表征的概念,它們是復(fù)雜深度學(xué)習(xí)模型的基礎(chǔ);第 3、4、5 章討論了流行的模型(如卷積、循環(huán)、遞歸神經(jīng)網(wǎng)絡(luò))及其在不同 NLP 任務(wù)中的應(yīng)用;第 6 章列舉了強(qiáng)化學(xué)習(xí)在 NLP 中的近期應(yīng)用,以及無(wú)監(jiān)督句子表征學(xué)習(xí)的近期發(fā)展;第 7 章介紹了深度學(xué)習(xí)模型結(jié)合記憶模塊這一近期趨勢(shì);第 8 章概述了多種深度學(xué)習(xí)方法在 NLP 任務(wù)標(biāo)準(zhǔn)數(shù)據(jù)集上的性能。機(jī)器之心選取了第 2、3、4、8 章進(jìn)行重點(diǎn)介紹。
第二章:分布式表征
基于統(tǒng)計(jì)的 NLP 已經(jīng)成為建模復(fù)雜自然語(yǔ)言任務(wù)的首要選擇。然而在它剛興起的時(shí)候,基于統(tǒng)計(jì)的 NLP 經(jīng)常遭受到維度災(zāi)難,尤其是在學(xué)習(xí)語(yǔ)言模型的聯(lián)合概率函數(shù)時(shí)。這為構(gòu)建能在低維空間中學(xué)習(xí)分布式詞表征的方法提供了動(dòng)力,這種想法也就導(dǎo)致了詞嵌入方法的誕生。
第一種在低維空間中學(xué)習(xí)密集型的分布式詞表征是 Yoshua Bengio 等人在 2003 年提出的 A Neural Probabilistic Language Model,這是一種基于學(xué)習(xí)而對(duì)抗維度災(zāi)難的優(yōu)美想法。
詞嵌入
如下圖 2 所示,分布式向量或詞嵌入向量基本上遵循分布式假設(shè),即具有相似語(yǔ)義的詞傾向于具有相似的上下文詞,因此這些詞向量嘗試捕獲鄰近詞的特征。分布式詞向量的主要優(yōu)點(diǎn)在于它們能捕獲單詞之間的相似性,使用余弦相似性等度量方法評(píng)估詞向量之間的相似性也是可能的。
詞嵌入常用于深度學(xué)習(xí)中的第一個(gè)數(shù)據(jù)預(yù)處理階段,一般我們可以在大型無(wú)標(biāo)注文本語(yǔ)料庫(kù)中最優(yōu)化損失函數(shù),從而獲得預(yù)訓(xùn)練的詞嵌入向量。例如基于上下文預(yù)測(cè)具體詞(Mikolov et al., 2013b, a)的方法,它能學(xué)習(xí)包含了一般句法和語(yǔ)義的詞向量。這些詞嵌入方法目前已經(jīng)被證明能高效捕捉上下文相似性,并且由于它們的維度非常小,因此在計(jì)算核心 NLP 任務(wù)是非常快速與高效的。

圖 2:分布式詞向量表征,其中每一個(gè)詞向量只有 D 維,且遠(yuǎn)小于詞匯量大小 V,即 D<
多年以來(lái),構(gòu)建這種詞嵌入向量的模型一般是淺層神經(jīng)網(wǎng)絡(luò),并沒(méi)有必要使用深層神經(jīng)網(wǎng)絡(luò)構(gòu)建更好的詞嵌入向量。不過(guò)基于深度學(xué)習(xí)的 NLP 模型常使用這些詞嵌入表示短語(yǔ)甚至句子,這實(shí)際上是傳統(tǒng)基于詞統(tǒng)計(jì)模型和基于深度學(xué)習(xí)模型的主要差別。目前詞嵌入已經(jīng)是 NLP 任務(wù)的標(biāo)配,大多數(shù) NLP 任務(wù)的頂尖結(jié)果都需要借助它的能力。
本身詞嵌入就能直接用于搜索近義詞或者做詞義的類(lèi)推,而下游的情感分類(lèi)、機(jī)器翻譯、語(yǔ)言建模等任務(wù)都能使用詞嵌入編碼詞層面的信息。最近比較流行的預(yù)訓(xùn)練語(yǔ)言模型其實(shí)也參考了詞嵌入的想法,只不過(guò)預(yù)訓(xùn)練語(yǔ)言模型在詞嵌入的基礎(chǔ)上進(jìn)一步能編碼句子層面的語(yǔ)義信息。總的而言,詞嵌入的廣泛使用早已體現(xiàn)在眾多文獻(xiàn)中,它的重要性也得到一致的認(rèn)可。
分布式表示(詞嵌入)主要通過(guò)上下文或者詞的「語(yǔ)境」來(lái)學(xué)習(xí)本身該如何表達(dá)。上個(gè)世紀(jì) 90 年代,就有一些研究(Elman, 1991)標(biāo)志著分布式語(yǔ)義已經(jīng)起步,后來(lái)的一些發(fā)展也都是對(duì)這些早期工作的修正。此外,這些早期研究還啟發(fā)了隱狄利克雷分配等主題建模(Blei et al., 2003)方法和語(yǔ)言建模(Bengio et al., 2003)方法。
在 2003 年,Bengio 等人提出了一種神經(jīng)語(yǔ)言模型,它可以學(xué)習(xí)單詞的分布式表征。他們認(rèn)為這些詞表征一旦使用詞序列的聯(lián)合分布構(gòu)建句子表征,那么就能構(gòu)建指數(shù)級(jí)的語(yǔ)義近鄰句。反過(guò)來(lái),這種方法也能幫助詞嵌入的泛化,因?yàn)槲匆?jiàn)過(guò)的句子現(xiàn)在可以通過(guò)近義詞而得到足夠多的信息。
圖 3:神經(jīng)語(yǔ)言模型(圖源:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)。
Collobert 和 Weston(2008) 展示了第一個(gè)能有效利用預(yù)訓(xùn)練詞嵌入的研究工作,他們提出的神經(jīng)網(wǎng)絡(luò)架構(gòu)構(gòu)成了當(dāng)前很多方法的基礎(chǔ)。這一項(xiàng)研究工作還率先將詞嵌入作為 NLP 任務(wù)的高效工具,不過(guò)詞嵌入真正走向 NLP 主流還是 Mikolov 等人在 2013 年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》。
Mikolov 等研究者在這篇論文中提出了連續(xù)詞袋模型(CBOW)和 Skip-Gram 模型,這兩種方法都能學(xué)習(xí)高質(zhì)量的分布式詞表征。此外,令這兩種方法受到極大關(guān)注的是另一種附加屬性:語(yǔ)義合成性,即兩個(gè)詞向量相加得到的結(jié)果是語(yǔ)義相加的詞,例如「man」+「royal」=「king」。這種語(yǔ)義合成性的理論依據(jù)最近已經(jīng)由 Gittens et al. (2017) 給出,他們表示只有保證某些特定的假設(shè)才能滿足語(yǔ)義合成性,例如詞需要在嵌入空間中處于均勻分布。
Pennington et al. (2014) 提出了另一個(gè)非常出名的詞嵌入方法 GloVe,它基本上是一種基于詞統(tǒng)計(jì)的模型。在有些情況下,CBOW 和 Skip-Gram 采用的交叉熵?fù)p失函數(shù)有劣勢(shì)。因此 GloVe 采用了平方損失,它令詞向量擬合預(yù)先基于整個(gè)數(shù)據(jù)集計(jì)算得到的全局統(tǒng)計(jì)信息,從而學(xué)習(xí)高效的詞詞表征。
一般 GloVe 模型會(huì)先對(duì)單詞計(jì)數(shù)進(jìn)行歸一化,并通過(guò)對(duì)數(shù)平滑來(lái)最終得到詞共現(xiàn)矩陣,這個(gè)詞共現(xiàn)矩陣就表示全局的統(tǒng)計(jì)信息。這個(gè)矩陣隨后可以通過(guò)矩陣分解得到低維的詞表征,這一過(guò)程可以通過(guò)最小化重構(gòu)損失來(lái)獲得。下面將具體介紹目前仍然廣泛使用的 CBOW 和 Skip-Gram 兩種Word2Vec方法(Mikolov et al., 2013)。
Word2Vec
可以說(shuō) Mikolov 等人徹底變革了詞嵌入,尤其是他們提出的 CBOW 和 Skip-Gram 模型。CBOW 會(huì)在給定上下文詞的情況下計(jì)算目標(biāo)詞(或中心詞)的條件概率,其中上下文詞的選取范圍通過(guò)窗口大小 k 決定。而Skip-Gram的做法正好與CBOW相反,它在給定目標(biāo)詞或中心詞的情況下預(yù)測(cè)上下文詞。一般上下文詞都會(huì)以目標(biāo)詞為中心對(duì)稱地分布在兩邊,且在窗口內(nèi)的詞與中心詞的距離都相等。也就是說(shuō)不能因?yàn)槟硞€(gè)上下文詞離中心詞比較遠(yuǎn),就認(rèn)為它對(duì)中心詞的作用比較弱。
在無(wú)監(jiān)督的設(shè)定中,詞嵌入的維度可以直接影響到預(yù)測(cè)的準(zhǔn)確度。一般隨著詞嵌入維度的增加,預(yù)測(cè)的準(zhǔn)確度也會(huì)增加,直到準(zhǔn)確率收斂到某個(gè)點(diǎn)。一般這樣的收斂點(diǎn)可以認(rèn)為是最佳的詞嵌入維度,因?yàn)樗诓挥绊憸?zhǔn)確率的情況下最精簡(jiǎn)。通常情況下,我們使用的詞嵌入維度可以是 128、256、300、500 等,相比于幾十萬(wàn)的詞匯庫(kù)大小已經(jīng)是很小的維度了。
下面我們可以考慮 CBOW 的簡(jiǎn)化版,上下文只考慮離中心詞最近的一個(gè)單詞,這基本上就是二元語(yǔ)言模型的翻版。
圖 4:CBOW 模型。
如圖 4 所示,CBOW 模型就是一個(gè)簡(jiǎn)單的全連接神經(jīng)網(wǎng)絡(luò),它只有一個(gè)隱藏層。輸入層是上下文詞的 one-hot 向量,它有 V 個(gè)神經(jīng)元(詞匯量),而中間的隱藏層只有 N 個(gè)神經(jīng)元,N 是要遠(yuǎn)遠(yuǎn)小于 V 的。最后的輸出層是所有詞上的一個(gè) Softmax 函數(shù)。層級(jí)之間的權(quán)重矩陣分別是 V*N 階的 W 和 N*V 階的 W',詞匯表中的每一個(gè)詞最終會(huì)表征為兩個(gè)向量:v_c 和 v_w,它們分別對(duì)應(yīng)上下文詞表征和目標(biāo)詞表征。若輸入的是詞表中第 k 個(gè)詞,那么我們有:
總體而言,在給定上下文詞 c 作為輸入的情況下,對(duì)于任意詞 w_i 有:
參數(shù) θ={V_w, V_c} 都是通過(guò)定義目標(biāo)函數(shù)而學(xué)習(xí)到的,一般目標(biāo)函數(shù)可以定義為對(duì)數(shù)似然函數(shù),且通過(guò)計(jì)算以下梯度更新權(quán)重:
在更廣泛的 CBOW 模型中,所有上下文詞的 one-hot 向量都會(huì)同時(shí)作為輸入,即:
詞嵌入的一個(gè)局限是它們無(wú)法表示短語(yǔ)(Mikolov et al., 2013),即兩個(gè)詞或多個(gè)詞的組合并不表示對(duì)應(yīng)的短語(yǔ)意義,例如「人民」+「大學(xué)」并不能組合成「人民大學(xué)」。Mikolov 提出的一種解決辦法是基于詞共現(xiàn)識(shí)別這些短語(yǔ),并為它們單獨(dú)地學(xué)一些詞嵌入向量,而 Rie Johnson 等研究者在 15 年更是提出直接從無(wú)監(jiān)督數(shù)據(jù)中學(xué)習(xí) n-gram 詞嵌入。
另一種局限性在于學(xué)習(xí)的詞嵌入僅基于周?chē)~的小窗口,有時(shí)候「good」和「bad」幾乎有相同的詞嵌入,這對(duì)于情感分析等下游任務(wù)很不友好。有時(shí)候這些相似的詞嵌入有正好相反的情感,這對(duì)于需要區(qū)別情感的下游任務(wù)簡(jiǎn)直是個(gè)災(zāi)難,它甚至比用 One-hot 向量的表征方法還要有更差的性能。Duyu Tang(2014)等人通過(guò)提出特定情感詞嵌入(SSWE)來(lái)解決這個(gè)問(wèn)題,他們?cè)趯W(xué)習(xí)嵌入時(shí)將損失函數(shù)中的監(jiān)督情感納入其中。
一個(gè)比較重要的觀點(diǎn)是,詞嵌入應(yīng)該高度依賴于他們要使用的領(lǐng)域。Labutov 和 Lipson(2013) 提出了一種用于特定任務(wù)的詞嵌入,他們會(huì)重新訓(xùn)練詞嵌入,因此將詞嵌入與將要進(jìn)行的下游任務(wù)相匹配,不過(guò)這種方法對(duì)計(jì)算力的需求比較大。而 Mikolov 等人嘗試使用負(fù)采樣的方法來(lái)解決這個(gè)問(wèn)題,負(fù)采樣僅僅只是基于頻率對(duì)負(fù)樣本進(jìn)行采樣,這個(gè)過(guò)程直接在訓(xùn)練中進(jìn)行。
此外,傳統(tǒng)的詞嵌入算法為每個(gè)詞分配不同的向量,這使得其不能解釋多義詞。在最近的一項(xiàng)工作中,Upadhyay 等人 (2017) 提出了一種新方法來(lái)解決這個(gè)問(wèn)題,他們利用多語(yǔ)平行數(shù)據(jù)來(lái)學(xué)習(xí)多語(yǔ)義詞嵌入。例如英語(yǔ)的「bank」在翻譯到法語(yǔ)時(shí)有兩種不同的詞:banc 和 banque,它們分別表示金融和地理意義,而多語(yǔ)言的分布信息能幫助詞嵌入解決一詞多義的問(wèn)題。
下表 1 提供了用于創(chuàng)建詞嵌入的現(xiàn)有框架,它們都可以訓(xùn)練詞嵌入并進(jìn)一步與深度學(xué)習(xí)模型相結(jié)合:
說(shuō)到這里,小編不得不宣傳一波我們的小項(xiàng)目,我們主要使用維基的中文語(yǔ)料訓(xùn)練了一個(gè)中文詞嵌入,并提供了 Skip-Gram 和 GloVe 兩種模型的訓(xùn)練方法。讀者可以簡(jiǎn)單地使用我們已訓(xùn)練的詞嵌入,或者根據(jù)我們提供的 Jupyter Notebook 教程學(xué)習(xí)如何訓(xùn)練詞嵌入。簡(jiǎn)單而言,訓(xùn)練主要可以分為 5 個(gè)步驟,即下載維基中文語(yǔ)料、將繁體轉(zhuǎn)化為簡(jiǎn)體、采用結(jié)巴分詞、預(yù)處理并構(gòu)建數(shù)據(jù)集、開(kāi)始訓(xùn)練。
當(dāng)然我們放在 Colab 的示例代碼只是訓(xùn)練部分維基語(yǔ)料,但也能做出了較為合理的中文詞嵌入。
項(xiàng)目地址:https://github.com/HoratioJSY/cn-words
第三章:卷積神經(jīng)網(wǎng)絡(luò)
隨著詞嵌入的流行及其在分布式空間中展現(xiàn)出的強(qiáng)大表征能力,我們需要一種高效的特征函數(shù),以從詞序列或 n-grams 中抽取高級(jí)語(yǔ)義信息。隨后這些抽象的語(yǔ)義信息能用于許多 NLP 任務(wù),如情感分析、自動(dòng)摘要、機(jī)器翻譯和問(wèn)答系統(tǒng)等。卷積神經(jīng)網(wǎng)絡(luò)(CNN)因?yàn)槠湓谟?jì)算機(jī)視覺(jué)中的有效性而被引入到自然語(yǔ)言處理中,實(shí)踐證明它也非常適合序列建模。
圖 5:用于執(zhí)行詞級(jí)分類(lèi)預(yù)測(cè)的 CNN 框架。(Collobert and Weston (2008))
使用 CNN 進(jìn)行句子建模可以追溯到 Collobert 和 Weston (2008) 的研究,他們使用多任務(wù)學(xué)習(xí)為不同的 NLP 任務(wù)輸出多個(gè)預(yù)測(cè),如詞性標(biāo)注、語(yǔ)塊分割、命名實(shí)體標(biāo)簽和語(yǔ)義相似詞等。其中查找表可以將每一個(gè)詞轉(zhuǎn)換為一個(gè)用戶自定義維度的向量。因此通過(guò)查找表,n 個(gè)詞的輸入序列 {s_1,s_2,... s_n } 能轉(zhuǎn)換為一系列詞向量 {w_s1, w_s2,... w_sn},這就是圖 5 所示的輸入。
這可以被認(rèn)為是簡(jiǎn)單的詞嵌入方法,其中權(quán)重都是通過(guò)網(wǎng)絡(luò)來(lái)學(xué)習(xí)的。在 Collobert 2011 年的研究中,他擴(kuò)展了以前的研究,并提出了一種基于 CNN 的通用框架來(lái)解決大量 NLP 任務(wù),這兩個(gè)工作都令 NLP 研究者嘗試在各種任務(wù)中普及 CNN 架構(gòu)。
CNN 具有從輸入句子抽取 n-gram 特征的能力,因此它能為下游任務(wù)提供具有句子層面信息的隱藏語(yǔ)義表征。下面簡(jiǎn)單描述了一個(gè)基于 CNN 的句子建模網(wǎng)絡(luò)到底是如何處理的。
基礎(chǔ) CNN
1. 序列建模
對(duì)于每一個(gè)句子,w_i∈R^d 表示句子中第 i 個(gè)詞的詞嵌入向量,其中 d 表示詞嵌入的維度。給定有 n 個(gè)詞的句子,句子能表示為詞嵌入矩陣 W∈R^n×d。下圖展示了將這樣一個(gè)句子作為輸入饋送到 CNN 架構(gòu)中。
圖 6:使用 CNN 的文本建模(Zhang and Wallace , 2015)。
若令 w_i:i+j 表示 w_i, w_i+1,...w_j 向量的拼接,那么卷積就可以直接在這個(gè)詞嵌入輸入層做運(yùn)算。卷積包含 d 個(gè)通道的卷積核 k∈R^hd,它可以應(yīng)用到窗口為 h 個(gè)詞的序列上,并生成新的特征。例如,c_i 即使用卷積核在詞嵌入矩陣上得到的激活結(jié)果:
若 b 是偏置項(xiàng),f 是非線性激活函數(shù),例如雙曲正切函數(shù)。使用相同的權(quán)重將濾波器 k 應(yīng)用于所有可能的窗口,以創(chuàng)建特征圖。
在卷積神經(jīng)網(wǎng)絡(luò)中,大量不同寬度的卷積濾波器(也叫做內(nèi)核,通常有幾百個(gè))在整個(gè)詞嵌入矩陣上滑動(dòng)。每個(gè)內(nèi)核提取一個(gè)特定的 n-gram 模式。卷積層之后通常是最大池化策略 c^=max{c},該策略通過(guò)對(duì)每個(gè)濾波器應(yīng)用最大運(yùn)算來(lái)對(duì)輸入進(jìn)行二次采樣。使用這個(gè)策略有兩大原因。
首先,最大池化提供固定長(zhǎng)度的輸出,這是分類(lèi)所需的。因此,不管濾波器的大小如何,最大池化總是將輸入映射到輸出的固定維度上。其次,它在降低輸出維度的同時(shí)保持了整個(gè)句子中最顯著的 n-gram 特征。這是通過(guò)平移不變的方式實(shí)現(xiàn)的,每個(gè)濾波器都能從句子的任何地方提取特定的特征(如,否定),并加到句子的最終表示中。
詞嵌入可以隨機(jī)初始化,也可以在大型未標(biāo)記語(yǔ)料庫(kù)上進(jìn)行預(yù)訓(xùn)練。第二種方法有時(shí)對(duì)性能提高更有利,特別是當(dāng)標(biāo)記數(shù)據(jù)有限時(shí)。卷積層和最大池化的這種組合通常被堆疊起來(lái),以構(gòu)建深度 CNN 網(wǎng)絡(luò)。這些順序卷積有助于改進(jìn)句子的挖掘,以獲得包含豐富語(yǔ)義信息的真正抽象表征。內(nèi)核通過(guò)更深的卷積覆蓋了句子的大部分,直到完全覆蓋并創(chuàng)建了句子特征的總體概括。
2. 窗口方法
上述架構(gòu)將完整句子建模為句子表征。然而,許多 NLP 任務(wù)(如命名實(shí)體識(shí)別,詞性標(biāo)注和語(yǔ)義角色標(biāo)注)需要基于字的預(yù)測(cè)。為了使 CNN 適應(yīng)這樣的任務(wù),需要使用窗口方法,其假定單詞的標(biāo)簽主要取決于其相鄰單詞。因此,對(duì)于每個(gè)單詞,存在固定大小的窗口,窗口內(nèi)的子句都在處理的范圍內(nèi)。如前所述,獨(dú)立的 CNN 應(yīng)用于該子句,并且預(yù)測(cè)結(jié)果歸因于窗口中心的單詞。按照這個(gè)方法,Poira 等人(2016)采用多級(jí)深度 CNN 來(lái)標(biāo)記句子中的每個(gè)單詞為 aspect 或 non-aspect。結(jié)合一些語(yǔ)言模式,它們的集成分類(lèi)器在 aspect 檢測(cè)方面表現(xiàn)很好。
詞級(jí)分類(lèi)的最終目的通常是為整個(gè)句子分配一系列的標(biāo)簽。在這樣的情況下,有時(shí)會(huì)采用結(jié)構(gòu)化預(yù)測(cè)技術(shù)來(lái)更好地捕獲相鄰分類(lèi)標(biāo)簽間的關(guān)系,最終生成連貫標(biāo)簽序列,從而給整個(gè)句子提供最大分?jǐn)?shù)。
為了獲得更大的上下文范圍,經(jīng)典窗口方法通常與時(shí)延神經(jīng)網(wǎng)絡(luò)(TDNN)相結(jié)合。這種方法中,可以在整個(gè)序列的所有窗口上進(jìn)行卷積。通過(guò)定義特定寬度的內(nèi)核,卷積通常會(huì)受到約束。因此,相較于經(jīng)典窗口方法(只考慮要標(biāo)記單詞周?chē)翱谥械膯卧~),TDNN 會(huì)同時(shí)考慮句子中的所有單詞窗口。TDNN 有時(shí)也能像 CNN 架構(gòu)一樣堆疊,以提取較低層的局部特征和較高層的總體特征。
應(yīng)用
在這部分,研究者介紹了一些使用 CNN 來(lái)處理 NLP 任務(wù)的研究,這些研究在它們當(dāng)時(shí)所處時(shí)代屬于前沿。
Kim 探討了使用上述架構(gòu)進(jìn)行各種句子分類(lèi)任務(wù),包括情感、主觀性和問(wèn)題類(lèi)型分類(lèi),結(jié)果很有競(jìng)爭(zhēng)力。因其簡(jiǎn)單有效的特點(diǎn),這種方法很快被研究者接受。在針對(duì)特定任務(wù)進(jìn)行訓(xùn)練之后,隨機(jī)初始化的卷積內(nèi)核成為特定 n-gram 的特征檢測(cè)器,這些檢測(cè)器對(duì)于目標(biāo)任務(wù)非常有用。但是這個(gè)網(wǎng)絡(luò)有很多缺點(diǎn),最主要的一點(diǎn)是 CNN 沒(méi)有辦法構(gòu)建長(zhǎng)距離依存關(guān)系。
圖 7:4 種預(yù)訓(xùn)練 7-gram 內(nèi)核得到的最好核函數(shù);每個(gè)內(nèi)核針對(duì)一種特定 7-gram。
Kalchbrenner 等人的研究在一定程度上解決了上述問(wèn)題。他們發(fā)表了一篇著名的論文,提出了一種用于句子語(yǔ)義建模的動(dòng)態(tài)卷積神經(jīng)網(wǎng)絡(luò)(DCNN)。他們提出了動(dòng)態(tài) k-max 池化策略,即給定一個(gè)序列 p,選擇 k 種最有效的特征。選擇時(shí)保留特征的順序,但對(duì)其特定位置不敏感。在 TDNN 的基礎(chǔ)上,他們?cè)黾恿藙?dòng)態(tài) k-max 池化策略來(lái)創(chuàng)建句子模型。這種結(jié)合使得具有較小寬度的濾波器能跨越輸入句子的長(zhǎng)范圍,從而在整個(gè)句子中積累重要信息。在下圖中,高階特征具有高度可變的范圍,可能是較短且集中,或者整體的,和輸入句子一樣長(zhǎng)。他們將模型應(yīng)用到多種任務(wù)中,包括情感預(yù)測(cè)和問(wèn)題類(lèi)型分類(lèi)等,取得了顯著的成果。總的來(lái)說(shuō),這項(xiàng)工作在嘗試為上下文語(yǔ)義建模的同時(shí),對(duì)單個(gè)內(nèi)核的范圍進(jìn)行了注釋?zhuān)⑻岢隽艘环N擴(kuò)展其范圍的方法。
圖 8:DCNN 子圖,通過(guò)動(dòng)態(tài)池化,較高層級(jí)上的寬度較小濾波器也能建立輸入句子中的長(zhǎng)距離相關(guān)性。
情感分類(lèi)等任務(wù)還需要有效地抽取 aspect 與其情感極性(Mukherjee and Liu, 2012)。Ruder 等人(2016)還將 CNN 應(yīng)用到了這類(lèi)任務(wù),他們將 aspect 向量與詞嵌入向量拼接以作為輸入,并獲得了很好的效果。CNN 建模的方法一般因文本的長(zhǎng)短而異,在較長(zhǎng)文本上的效果比較短文本上好。Wang et al. (2015) 提出利用 CNN 建模短文本的表示,但是因?yàn)槿鄙倏捎玫纳舷挛男畔ⅲ麄冃枰~外的工作來(lái)創(chuàng)建有意義的表征。因此作者提出了語(yǔ)義聚類(lèi),其引入了多尺度語(yǔ)義單元以作為短文本的外部知識(shí)。最后 CNN 組合這些單元以形成整體表示。
CNN 還廣泛用于其它任務(wù),例如 Denil et al. (2014) 利用 DCNN 將構(gòu)成句子的單詞含義映射到文本摘要中。其中 DCNN 同時(shí)在句子級(jí)別和文檔級(jí)別學(xué)習(xí)卷積核,這些卷積核會(huì)分層學(xué)習(xí)并捕獲不同水平的特征,因此 DCNN 最后能將底層的詞匯特征組合為高級(jí)語(yǔ)義概念。
此外,CNN 也適用于需要語(yǔ)義匹配的 NLP 任務(wù)。例如我們可以利用 CNN 將查詢與文檔映射到固定維度的語(yǔ)義空間,并根據(jù)余弦相似性對(duì)與特定查詢相關(guān)的文檔進(jìn)行排序。在 QA 領(lǐng)域,CNN 也能度量問(wèn)題和實(shí)體之間的語(yǔ)義相似性,并借此搜索與問(wèn)題相關(guān)的回答。機(jī)器翻譯等任務(wù)需要使用序列信息和長(zhǎng)期依賴關(guān)系,因此從結(jié)構(gòu)上來(lái)說(shuō),這種任務(wù)不太適合 CNN。但是因?yàn)?CNN 的高效計(jì)算,還是有很多研究者嘗試使用 CNN 解決機(jī)器翻譯問(wèn)題。
總體而言,CNN 在上下文窗口中挖掘語(yǔ)義信息非常有效,然而它們是一種需要大量數(shù)據(jù)訓(xùn)練大量參數(shù)的模型。因此在數(shù)據(jù)量不夠的情況下,CNN 的效果會(huì)顯著降低。CNN 另一個(gè)長(zhǎng)期存在的問(wèn)題是它們無(wú)法對(duì)長(zhǎng)距離上下文信息進(jìn)行建模并保留序列信息,其它如遞歸神經(jīng)網(wǎng)絡(luò)等在這方面有更好的表現(xiàn)。
第四章:循環(huán)神經(jīng)網(wǎng)絡(luò)
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的思路是處理序列信息。「循環(huán)」表示 RNN 模型對(duì)序列中的每一個(gè)實(shí)例都執(zhí)行同樣的任務(wù),從而使輸出依賴于之前的計(jì)算和結(jié)果。通常,RNN 通過(guò)將 token 挨個(gè)輸入到循環(huán)單元中,來(lái)生成表示序列的固定大小向量。一定程度上,RNN 對(duì)之前的計(jì)算有「記憶」,并在當(dāng)前的處理中使用對(duì)之前的記憶。該模板天然適合很多 NLP 任務(wù),如語(yǔ)言建模、機(jī)器翻譯、語(yǔ)音識(shí)別、圖像字幕生成。因此近年來(lái),RNN 在 NLP 任務(wù)中逐漸流行。
對(duì) RNN 的需求
這部分將分析支持 RNN 在大量 NLP 任務(wù)中廣泛使用的基本因素。鑒于 RNN 通過(guò)建模序列中的單元來(lái)處理序列,它能夠捕獲到語(yǔ)言中的內(nèi)在序列本質(zhì),序列中的單元是字符、單詞甚至句子。語(yǔ)言中的單詞基于之前的單詞形成語(yǔ)義,一個(gè)簡(jiǎn)單的示例是「dog」和「hot dog」。RNN 非常適合建模語(yǔ)言和類(lèi)似序列建模任務(wù)中的此類(lèi)語(yǔ)境依賴,這使得大量研究者在這些領(lǐng)域中使用 RNN,頻率多于 CNN。
RNN 適合序列建模任務(wù)的另一個(gè)因素是它能夠建模不定長(zhǎng)文本,包括非常長(zhǎng)的句子、段落甚至文檔。與 CNN 不同,RNN 的計(jì)算步靈活,從而提供更好的建模能力,為捕獲無(wú)限上下文創(chuàng)造了可能。這種處理任意長(zhǎng)度輸入的能力是使用 RNN 的主要研究的賣(mài)點(diǎn)之一。
很多 NLP 任務(wù)要求對(duì)整個(gè)句子進(jìn)行語(yǔ)義建模。這需要在固定維度超空間中創(chuàng)建句子的大意。RNN 對(duì)句子的總結(jié)能力使得它們?cè)跈C(jī)器翻譯等任務(wù)中得到更多應(yīng)用,機(jī)器翻譯任務(wù)中整個(gè)句子被總結(jié)為固定向量,然后映射回不定長(zhǎng)目標(biāo)序列。
RNN 還對(duì)執(zhí)行時(shí)間分布式聯(lián)合處理(time distributed joint processing)提供網(wǎng)絡(luò)支持,大部分序列標(biāo)注任務(wù)(如詞性標(biāo)注)屬于該領(lǐng)域。具體用例包括多標(biāo)簽文本分類(lèi)、多模態(tài)情感分析等應(yīng)用。
上文介紹了研究人員偏好使用 RNN 的幾個(gè)主要因素。然而,就此認(rèn)為 RNN 優(yōu)于其他深度網(wǎng)絡(luò)則大錯(cuò)特錯(cuò)。近期,多項(xiàng)研究就 CNN 優(yōu)于 RNN 提出了證據(jù)。甚至在 RNN 適合的語(yǔ)言建模等任務(wù)中,CNN 的性能與 RNN 相當(dāng)。CNN 與 RNN 在建模句子時(shí)的目標(biāo)函數(shù)不同。RNN 嘗試建模任意長(zhǎng)度的句子和無(wú)限的上下文,而 CNN 嘗試提取最重要的 n-gram。盡管研究證明 CNN 是捕捉 n-gram 特征的有效方式,這在特定長(zhǎng)度的句子分類(lèi)任務(wù)中差不多足夠了,但 CNN 對(duì)詞序的敏感度有限,容易限于局部信息,忽略長(zhǎng)期依賴。
《Comparative Study of CNN and RNN for Natural Language Processing》對(duì) CNN 和 RNN 的性能提供了有趣的見(jiàn)解。研究人員在多項(xiàng) NLP 任務(wù)(包括情感分類(lèi)、問(wèn)答和詞性標(biāo)注)上測(cè)試后,發(fā)現(xiàn)沒(méi)有明確的贏家:二者的性能依賴于任務(wù)所需的全局語(yǔ)義。
下面,我們討論了文獻(xiàn)中廣泛使用的一些 RNN 模型。
RNN 模型
1. 簡(jiǎn)單 RNN
在 NLP 中,RNN 主要基于 Elman 網(wǎng)絡(luò),最初是三層網(wǎng)絡(luò)。圖 9 展示了一個(gè)較通用的 RNN,它按時(shí)間展開(kāi)以適應(yīng)整個(gè)序列。圖中 x_t 作為網(wǎng)絡(luò)在時(shí)間步 t 處的輸入,s_t 表示在時(shí)間步 t 處的隱藏狀態(tài)。s_t 的計(jì)算公式如下:
因此,s_t 的計(jì)算基于當(dāng)前輸入和之前時(shí)間步的隱藏狀態(tài)。函數(shù) f 用來(lái)做非線性變換,如 tanh、ReLU,U、V、W 表示在不同時(shí)間上共享的權(quán)重。在 NLP 任務(wù)中,x_t 通常由 one-hot 編碼或嵌入組成。它們還可以是文本內(nèi)容的抽象表征。o_t 表示網(wǎng)絡(luò)輸出,通常也是非線性的,尤其是當(dāng)網(wǎng)絡(luò)下游還有其他層的時(shí)候。
圖 9:簡(jiǎn)單 RNN 網(wǎng)絡(luò)(圖源:https://www.nature.com/articles/nature14539)
RNN 的隱藏狀態(tài)通常被認(rèn)為是其最重要的元素。如前所述,它被視為 RNN 的記憶元素,從其他時(shí)間步中累積信息。但是,在實(shí)踐中,這些簡(jiǎn)單 RNN 網(wǎng)絡(luò)會(huì)遇到梯度消失問(wèn)題,使學(xué)習(xí)和調(diào)整網(wǎng)絡(luò)之前層的參數(shù)變得非常困難。
該局限被很多網(wǎng)絡(luò)解決,如長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)、門(mén)控循環(huán)單元(GRU)和殘差網(wǎng)絡(luò)(ResNet),前兩個(gè)是 NLP 應(yīng)用中廣泛使用的 RNN 變體。
2. 長(zhǎng)短期記憶(LSTM)
LSTM 比簡(jiǎn)單 RNN 多了『遺忘』門(mén),其獨(dú)特機(jī)制幫助該網(wǎng)絡(luò)克服了梯度消失和梯度爆炸問(wèn)題。
圖 10:LSTM 和 GRU 門(mén)圖示(圖源:https://arxiv.org/abs/1412.3555)
與原版 RNN 不同,LSTM 允許誤差通過(guò)無(wú)限數(shù)量的時(shí)間步進(jìn)行反向傳播。它包含三個(gè)門(mén):輸入門(mén)、遺忘門(mén)和輸出門(mén),并通過(guò)結(jié)合這三個(gè)門(mén)來(lái)計(jì)算隱藏狀態(tài),如下面的公式所示:
3. 門(mén)控循環(huán)單元(GRU)
另一個(gè)門(mén)控 RNN 變體是 GRU,復(fù)雜度更小,其在大部分任務(wù)中的實(shí)驗(yàn)性能與 LSTM 類(lèi)似。GRU 包括兩個(gè)門(mén):重置門(mén)和更新門(mén),并像沒(méi)有記憶單元的 LSTM 那樣處理信息流。因此,GRU 不加控制地暴露出所有的隱藏內(nèi)容。由于 GRU 的復(fù)雜度較低,它比 LSTM 更加高效。其工作原理如下:
研究者通常面臨選擇合適門(mén)控 RNN 的難題,這個(gè)問(wèn)題同樣困擾 NLP 領(lǐng)域開(kāi)發(fā)者。縱觀歷史,大部分對(duì) RNN 變體的選擇都是啟發(fā)式的。《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》對(duì)前面三種 RNN 變體進(jìn)行了對(duì)比評(píng)估,不過(guò)評(píng)估不是在 NLP 任務(wù)上進(jìn)行的,而是復(fù)調(diào)音樂(lè)建模和語(yǔ)音信號(hào)建模相關(guān)任務(wù)。他們的評(píng)估結(jié)果明確表明門(mén)控單元(LSTM 和 GRU)優(yōu)于傳統(tǒng)的簡(jiǎn)單 RNN(實(shí)驗(yàn)中用的是 tanh 激活函數(shù)),如下圖所示。但是,他們對(duì)這兩種門(mén)控單元哪個(gè)更好沒(méi)有定論。其他研究也注意到了這一點(diǎn),因此人們?cè)诙咧g作出選擇時(shí)通常利用算力等其他因素。
圖 11:不同 RNN 變體在訓(xùn)練集和驗(yàn)證集上的學(xué)習(xí)曲線,上圖 x 軸表示迭代次數(shù),下圖 x 軸表示掛鐘時(shí)間,y 軸表示模型的負(fù)對(duì)數(shù)似然(以對(duì)數(shù)標(biāo)尺顯示)。
應(yīng)用
1. 用于單詞級(jí)別分類(lèi)任務(wù)的 RNN
之前,RNN 經(jīng)常出現(xiàn)在單詞級(jí)別的分類(lèi)任務(wù)中。其中的很多應(yīng)用到現(xiàn)在仍然是所在任務(wù)中的最優(yōu)結(jié)果。論文《Neural Architectures for Named Entity Recognition》提出 LSTM+CRF 架構(gòu)。它使用雙向 LSTM 解決命名實(shí)體識(shí)別問(wèn)題,該網(wǎng)絡(luò)捕捉目標(biāo)單詞周?chē)娜我忾L(zhǎng)度上下文信息(緩解了固定窗口大小的約束),從而生成兩個(gè)固定大小的向量,再在向量之上構(gòu)建另一個(gè)全連接層。最終的實(shí)體標(biāo)注部分使用的是 CRF 層。
RNN 在語(yǔ)言建模任務(wù)上也極大地改善了基于 count statistics 的傳統(tǒng)方法。該領(lǐng)域的開(kāi)創(chuàng)性研究是 Alex Graves 2013 年的研究《Generating Sequences With Recurrent Neural Networks》,介紹了 RNN 能夠有效建模具備長(zhǎng)距離語(yǔ)境結(jié)構(gòu)的復(fù)雜序列。該研究首次將 RNN 的應(yīng)用擴(kuò)展到 NLP 以外。之后,Sundermeyer 等人的研究《From Feedforward to Recurrent LSTM Neural Networks for Language Modeling》對(duì)比了在單詞預(yù)測(cè)任務(wù)中用 RNN 替換前饋神經(jīng)網(wǎng)絡(luò)獲得的收益。該研究提出一種典型的神經(jīng)網(wǎng)絡(luò)層級(jí)架構(gòu),其中前饋神經(jīng)網(wǎng)絡(luò)比基于 count 的傳統(tǒng)語(yǔ)言模型有較大改善,RNN 效果更好,LSTM 的效果又有改進(jìn)。該研究的一個(gè)重點(diǎn)是他們的結(jié)論可應(yīng)用于多種其他任務(wù),如統(tǒng)計(jì)機(jī)器翻譯。
2. 用于句子級(jí)別分類(lèi)任務(wù)的 RNN
Xin Wang 等人 2015 年的研究《Predicting Polarities of Tweets by Composing Word Embeddings with Long Short-Term Memory》提出使用 LSTM 編碼整篇推文(tweet),用 LSTM 的隱藏狀態(tài)預(yù)測(cè)情感極性。這種簡(jiǎn)單的策略被證明與 Nal Kalchbrenner 等人 2014 年的研究《A Convolutional Neural Network for Modelling Sentences》提出的較復(fù)雜 DCNN 結(jié)構(gòu)性能相當(dāng),DCNN 旨在使 CNN 模型具備捕捉長(zhǎng)期依賴的能力。在一個(gè)研究否定詞組(negation phrase)的特殊案例中,Xin Wang 等人展示了 LSTM 門(mén)的動(dòng)態(tài)可以捕捉單詞 not 的反轉(zhuǎn)效應(yīng)。
與 CNN 類(lèi)似,RNN 的隱藏狀態(tài)也可用于文本之間的語(yǔ)義匹配。在對(duì)話系統(tǒng)中,Lowe 等人 2015 年的研究《The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems》提出用 Dual-LSTM 匹配信息和候選回復(fù),Dual-LSTM 將二者編碼為固定大小的向量,然后衡量它們的內(nèi)積用于對(duì)候選回復(fù)進(jìn)行排序。
3. 用于生成語(yǔ)言的 RNN
NLP 領(lǐng)域中的一大難題是生成自然語(yǔ)言,而這是 RNN 另一個(gè)恰當(dāng)?shù)膽?yīng)用。基于文本或視覺(jué)數(shù)據(jù),深度 LSTM 在機(jī)器翻譯、圖像字幕生成等任務(wù)中能夠生成合理的任務(wù)特定文本。在這些案例中,RNN 作為解碼器。
在 Ilya Sutskever 等人 2014 年的研究《Sequence to Sequence Learning with Neural Networks》中,作者提出了一種通用深度 LSTM 編碼器-解碼器框架,可以實(shí)現(xiàn)序列之間的映射。使用一個(gè) LSTM 將源序列編碼為定長(zhǎng)向量,源序列可以是機(jī)器翻譯任務(wù)中的源語(yǔ)言、問(wèn)答任務(wù)中的問(wèn)題或?qū)υ捪到y(tǒng)中的待回復(fù)信息。然后將該向量作為另一個(gè) LSTM(即解碼器)的初始狀態(tài)。在推斷過(guò)程中,解碼器逐個(gè)生成 token,同時(shí)使用最后生成的 token 更新隱藏狀態(tài)。束搜索通常用于近似最優(yōu)序列。
該研究使用了一個(gè) 4 層 LSTM 在機(jī)器翻譯任務(wù)上進(jìn)行端到端實(shí)驗(yàn),結(jié)果頗具競(jìng)爭(zhēng)力。《A Neural Conversational Model》使用了同樣的編碼器-解碼器框架來(lái)生成開(kāi)放域的有趣回復(fù)。使用 LSTM 解碼器處理額外信號(hào)從而獲取某種效果現(xiàn)在是一種普遍做法了。《A Persona-Based Neural Conversation Model》提出用解碼器處理恒定人物向量(constant persona vector),該向量捕捉單個(gè)說(shuō)話人的個(gè)人信息。在上述案例中,語(yǔ)言生成主要基于表示文本輸入的語(yǔ)義向量。類(lèi)似的框架還可用于基于圖像的語(yǔ)言生成,使用視覺(jué)特征作為 LSTM 解碼器的初始狀態(tài)(圖 12)。
視覺(jué) QA 是另一種任務(wù),需要基于文本和視覺(jué)線索生成語(yǔ)言。2015 年的論文《Ask Your Neurons: A Neural-based Approach to Answering Questions about Images》是首個(gè)提供端到端深度學(xué)習(xí)解決方案的研究,他們使用 CNN 建模輸入圖像、LSTM 建模文本,從而預(yù)測(cè)答案(一組單詞)。
圖 12:結(jié)合 LSTM 解碼器和 CNN 圖像嵌入器,生成圖像字幕(圖源:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf)
《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》提出動(dòng)態(tài)記憶網(wǎng)絡(luò)(dynamic memory network,DMN)來(lái)解決這個(gè)問(wèn)題。其思路是重復(fù)關(guān)注輸入文本和圖像,以使每次迭代中的信息都得到改善。注意力網(wǎng)絡(luò)用于關(guān)注輸入文本詞組。
圖 13:神經(jīng)圖像 QA(圖源:https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Malinowski_Ask_Your_Neurons_ICCV_2015_paper.pdf)
注意力機(jī)制
傳統(tǒng)編碼器-解碼器框架的一個(gè)潛在問(wèn)題是:有時(shí)編碼器會(huì)強(qiáng)制編碼可能與目前任務(wù)不完全相關(guān)的信息。這個(gè)問(wèn)題在輸入過(guò)長(zhǎng)或信息量過(guò)大時(shí)也會(huì)出現(xiàn),選擇性編碼是不可能的。
例如,文本摘要任務(wù)可以被視為序列到序列的學(xué)習(xí)問(wèn)題,其中輸入是原始文本,輸出是壓縮文本。直觀上看,讓固定大小向量編碼長(zhǎng)文本中的全部信息是不切實(shí)際的。類(lèi)似的問(wèn)題在機(jī)器翻譯任務(wù)中也有出現(xiàn)。
在文本摘要和機(jī)器翻譯等任務(wù)中,輸入文本和輸出文本之間存在某種對(duì)齊,這意味著每個(gè) token 生成步都與輸入文本的某個(gè)部分高度相關(guān)。這啟發(fā)了注意力機(jī)制。該機(jī)制嘗試通過(guò)讓解碼器回溯到輸入序列來(lái)緩解上述問(wèn)題。具體在解碼過(guò)程中,除了最后的隱藏狀態(tài)和生成 token 以外,解碼器還需要處理基于輸入隱藏狀態(tài)序列計(jì)算出的語(yǔ)境向量。
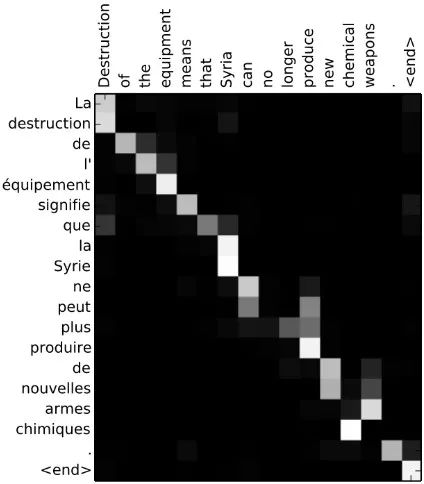
《Neural Machine Translation by Jointly Learning to Align and Translate》首次將注意力機(jī)制應(yīng)用到機(jī)器翻譯任務(wù),尤其改進(jìn)了在長(zhǎng)序列上的性能。該論文中,關(guān)注輸入隱藏狀態(tài)序列的注意力信號(hào)由解碼器最后的隱藏狀態(tài)的多層感知機(jī)決定。通過(guò)在每個(gè)解碼步中可視化輸入序列的注意力信號(hào),可以獲得源語(yǔ)言和目標(biāo)語(yǔ)言之間的清晰對(duì)齊(圖 14)。
圖 14:詞對(duì)齊矩陣(圖源:https://arxiv.org/abs/1409.0473)
類(lèi)似的方法也被應(yīng)用到摘要任務(wù)中,《A Neural Attention Model for Abstractive Sentence Summarization》用注意力機(jī)制處理輸入句子從而得到摘要中的每個(gè)輸出單詞。作者執(zhí)行 abstractive summarization,它與 extractive summarization 不同,但可以擴(kuò)展到具備最小語(yǔ)言輸入的大型數(shù)據(jù)。
在圖像字幕生成任務(wù)中,《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》用 LSTM 解碼器在每個(gè)解碼步中處理輸入圖像的不同部分。注意力信號(hào)由之前的隱藏狀態(tài)和 CNN 特征決定。《Grammar as a Foreign Language》將解析樹(shù)線性化,從而將句法解析問(wèn)題作為序列到序列學(xué)習(xí)任務(wù)。該研究證明注意力機(jī)制更加數(shù)據(jù)高效。指回輸入序列的進(jìn)一步步驟是:在特定條件下,直接將輸入中的單詞或子序列復(fù)制到輸出序列,這在對(duì)話生成和文本摘要等任務(wù)中也有用。解碼過(guò)程中的每個(gè)時(shí)間步可以選擇復(fù)制還是生成。
在基于 aspect 的情感分析中,《Attention-based LSTM for Aspect-level Sentiment Classification》提出基于注意力的解決方案,使用 aspect 嵌入為分類(lèi)提供額外支持(圖 15)。注意力模塊選擇性關(guān)注句子的某些區(qū)域,這會(huì)影響 aspect 的分類(lèi)。圖 16 中,對(duì)于 a 中的 aspect「service」,注意力模塊動(dòng)態(tài)聚焦詞組「fastest delivery times」,b 中對(duì)于 aspect「food」,注意力在整個(gè)句子中識(shí)別了多個(gè)關(guān)鍵點(diǎn),包括「tasteless」和「too sweet」。近期,《Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM》用層級(jí)注意力機(jī)制(包含目標(biāo)級(jí)注意力和句子級(jí)注意力)增強(qiáng) LSTM,利用常識(shí)處理基于目標(biāo) aspect 的情感分析。
圖 15:使用注意力機(jī)制進(jìn)行 aspect 分類(lèi)(圖源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)
圖 16:對(duì)于特定 aspect,注意力模塊對(duì)句子的關(guān)注點(diǎn)(圖源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)
另一方面,《Aspect Level Sentiment Classification with Deep Memory Network》采用基于記憶網(wǎng)絡(luò)(也叫 MemNet)的解決方案,使用多跳注意力(multiple-hop attention)。記憶網(wǎng)絡(luò)上的多個(gè)注意力計(jì)算層可以改善對(duì)記憶中大部分信息區(qū)域的查找,從而有助于分類(lèi)。這一研究目前仍是該領(lǐng)域的當(dāng)前最優(yōu)結(jié)果。
由于注意力模塊應(yīng)用的直觀性,NLP 研究者和開(kāi)發(fā)者在越來(lái)越多的應(yīng)用中積極使用注意力模塊。
并行化注意力:Transformer
CNN 和 RNN 在包括編碼器-解碼器架構(gòu)在內(nèi)的序列傳導(dǎo)應(yīng)用中非常關(guān)鍵。注意力機(jī)制可以進(jìn)一步提升這些模型的性能。但是,這些架構(gòu)面臨的一個(gè)瓶頸是編碼步中的序列處理。為了解決該問(wèn)題,《Attention Is All You Need》提出了 Transformer,它完全去除了編碼步中的循環(huán)和卷積,僅依賴注意力機(jī)制來(lái)捕捉輸入和輸出之間的全局關(guān)系。因此,整個(gè)架構(gòu)更加并行化,在翻譯、解析等任務(wù)上訓(xùn)練得到積極結(jié)果所需的時(shí)間也更少。
圖 17:multi-head 注意力(圖源:https://arxiv.org/abs/1706.03762)
Transformer 的編碼器和解碼器部分都有一些堆疊層。每個(gè)層有兩個(gè)由 multi-head 注意力層組成的子層(圖 17),之后是 position-wise 前饋網(wǎng)絡(luò)。對(duì)于查詢集 Q、關(guān)鍵 K 和值 V,multi-head 注意力模塊執(zhí)行注意力 h 次,計(jì)算公式如下:
此處,W_i^{[.]} 和 W^o 是投影參數(shù)。該模型融合了殘差連接、層歸一化、dropout、位置編碼等技術(shù),在英語(yǔ)-德語(yǔ)、英語(yǔ)-法語(yǔ)翻譯和 constituency parsing 中獲得了當(dāng)前最優(yōu)結(jié)果。
第八章:不同模型在不同 NLP 任務(wù)上的表現(xiàn)
在下面表 2 到表 7 中,我們總結(jié)了一系列深度學(xué)習(xí)方法在標(biāo)準(zhǔn)數(shù)據(jù)集上的表現(xiàn),這些數(shù)據(jù)集都是近年來(lái)最流行的探究主題。我們的目標(biāo)是向讀者展示深度學(xué)習(xí)社區(qū)常用的數(shù)據(jù)集以及不同模型在這些數(shù)據(jù)集上的當(dāng)前最佳結(jié)果。
詞性標(biāo)注
WSJ-PTB(the Wall Street Journal part of the Penn Treebank Dataset)語(yǔ)料庫(kù)包含 117 萬(wàn)個(gè) token,已被廣泛用于開(kāi)發(fā)和評(píng)估詞性標(biāo)注系統(tǒng)。Giménez 和 arquez(2004)在 7 個(gè)單詞窗口內(nèi)采用了基于人工特征的一對(duì)多 SVM,其中有些基本的 n-gram 模式被評(píng)估用來(lái)構(gòu)成二元特征,如:「前一個(gè)單詞是 the」,「前兩個(gè)標(biāo)簽是 DT NN」等。詞性標(biāo)注問(wèn)題的一大特征是相鄰標(biāo)簽之間的強(qiáng)依賴性。通過(guò)簡(jiǎn)單的從左到右標(biāo)注方案,該方法僅通過(guò)特征工程建模相鄰標(biāo)簽之間的依賴性。
為了減少特征工程,Collobert 等人(2011)通過(guò)多層感知機(jī)僅依賴于單詞窗口中的詞嵌入。Santos 和 Zadrozny(2014)將詞嵌入和字符嵌入連接起來(lái),以便更好地利用形態(tài)線索。在論文《Learning Character-level Representations for Part-of-Speech Tagging》中,他們沒(méi)有考慮 CRF,但由于單詞級(jí)的決策是在上下文窗口上做出的,可以看到依賴性被隱式地建模。Huang 等人(2015)把單詞嵌入和手動(dòng)設(shè)計(jì)的單詞級(jí)特征連接起來(lái),并采用雙向 LSTM 來(lái)建模任意長(zhǎng)度的上下文。
一系列消融分析(ablative analysis)表明,雙向 LSTM 和 CRF 都提升了性能。Andor 等人(2016)展示了一種基于轉(zhuǎn)換(transition-based)的方法,該方法通過(guò)簡(jiǎn)單的前饋神經(jīng)網(wǎng)絡(luò)上產(chǎn)生了具有競(jìng)爭(zhēng)性的結(jié)果。當(dāng)應(yīng)用于序列標(biāo)注任務(wù)時(shí),DMN(Kumar et al., 2015)允許通過(guò)把每個(gè) RNN 的隱藏狀態(tài)視為記憶實(shí)體來(lái)多次關(guān)注上下文,且每次都關(guān)注于上下文的不同部分。
表 2:詞性標(biāo)注
句法分析
有兩種句法分析:依存句法分析(dependency parsing)和成分句法分析(constituency parsing)。前者將單個(gè)單詞及其關(guān)系聯(lián)系起來(lái),后者依次將文本拆分成子短語(yǔ)(sub-phrase)。基于轉(zhuǎn)換的方法是很多人的選擇,因?yàn)樗鼈冊(cè)诰渥娱L(zhǎng)度上是線性的。解析器(parser)會(huì)做出一系列決定:根據(jù)緩沖器(buffer)順序讀取單詞,然后逐漸將它們組合到句法結(jié)構(gòu)中(Chen and Manning, 2014)。
在每個(gè)時(shí)間步,決策是基于包含可用樹(shù)節(jié)點(diǎn)的堆棧、包含未讀單詞的緩沖器和獲得的依存關(guān)系集來(lái)確定的。Chen and Manning 利用帶有一個(gè)隱藏層的神經(jīng)網(wǎng)絡(luò)來(lái)建模每個(gè)時(shí)間步做出的決定。輸入層包含特定單詞、詞性標(biāo)注和弧標(biāo)簽的嵌入向量,這些分別來(lái)自堆棧、緩沖器和依存關(guān)系集。
Tu 等人(2015)擴(kuò)展了 Chen and Manning 的工作,他們用了帶有兩個(gè)隱藏層的深度模型。但是,不管是 Tu 等人還是 Chen 和 Manning,他們都依賴于從解析器狀態(tài)中選擇手動(dòng)特征,而且他們只考慮了少數(shù)最后的幾個(gè) token。Dyer 等人(2015)提出堆棧-LSTMs 來(lái)建模任意長(zhǎng)度的 token 序列。當(dāng)我們對(duì)樹(shù)節(jié)點(diǎn)的堆棧進(jìn)行 push 或 pop 時(shí),堆棧的結(jié)束指針(end pointer)會(huì)改變位置。Zhou 等人(2017)整合集束搜索和對(duì)比學(xué)習(xí),以實(shí)現(xiàn)更好的優(yōu)化。
基于變換的模型也被應(yīng)用于成分句法分析。Zhu 等人(2013)基于堆棧和緩沖器頂部幾個(gè)單詞的特征(如詞性標(biāo)簽、成分標(biāo)簽)來(lái)進(jìn)行每個(gè)轉(zhuǎn)換動(dòng)作。通過(guò)用線性標(biāo)簽序列表示解析樹(shù),Vinyals 等人(2015)將 seq2seq 學(xué)習(xí)方法應(yīng)用于該問(wèn)題。
表 3.1:依存句法分析(UAS/LAS=未標(biāo)記/標(biāo)記的 Attachment 分?jǐn)?shù);WSJ=The Wall Street Journal Section of Penn Treebank)
表 3.2:成分句法分析
命名實(shí)體識(shí)別
CoNLL 2003 是用于命名實(shí)體識(shí)別(NER)的標(biāo)準(zhǔn)英語(yǔ)數(shù)據(jù)集,其中主要包含四種命名實(shí)體:人、地點(diǎn)、組織和其它實(shí)體。NER 屬于自然語(yǔ)言處理問(wèn)題,其中詞典非常有用。Collobert 等人(2011)首次通過(guò)用地名索引特征增強(qiáng)的神經(jīng)架構(gòu)實(shí)現(xiàn)了具有競(jìng)爭(zhēng)性的結(jié)果。Chiu and Nichols(2015)將詞典特征、字符嵌入和單詞嵌入串聯(lián)起來(lái),然后將其作為雙向 LSTM 的輸入。
另一方面,Lample 等人(2016)僅靠字符和單詞嵌入,通過(guò)在大型無(wú)監(jiān)督語(yǔ)料庫(kù)上進(jìn)行預(yù)訓(xùn)練嵌入實(shí)現(xiàn)了具有競(jìng)爭(zhēng)性的結(jié)果。與 POS 標(biāo)簽類(lèi)似,CRF 也提升了 NER 的性能,這一點(diǎn)在 Lample 等人(2016)的《Neural Architectures for Named Entity Recognition》中得到了證實(shí)。總體來(lái)說(shuō),帶有 CRF 的雙向 LSTM 對(duì)于結(jié)構(gòu)化預(yù)測(cè)是一個(gè)強(qiáng)有力的模型。
Passos 等人(2014)提出經(jīng)修正的 skip-gram 模型,以更好地學(xué)習(xí)與實(shí)體類(lèi)型相關(guān)的詞嵌入,此類(lèi)詞嵌入可以利用來(lái)自相關(guān)詞典的信息。Luo 等人(2015)聯(lián)合優(yōu)化了實(shí)體以及實(shí)體和知識(shí)庫(kù)的連接。Strubell 等人(2017)提出用空洞卷積,他們希望通過(guò)跳過(guò)某些輸入來(lái)定義更寬的有效輸入,因此實(shí)現(xiàn)更好的并行化和上下文建模。該模型在保持準(zhǔn)確率的同時(shí)展示出了顯著的加速。
表 4:命名實(shí)體識(shí)別
語(yǔ)義角色標(biāo)注
語(yǔ)義角色標(biāo)注(SRL)旨在發(fā)現(xiàn)句子中每個(gè)謂詞的謂詞-論元(predicate-argument)結(jié)構(gòu)。至于每個(gè)目標(biāo)動(dòng)詞(謂語(yǔ)),句子中充當(dāng)動(dòng)詞語(yǔ)義角色的所有成分都會(huì)被識(shí)別出來(lái)。典型的語(yǔ)義論元包括施事者、受事者、工具等,以及地點(diǎn)、時(shí)間、方式、原因等修飾語(yǔ) (Zhou and Xu, 2015)。表 5 展示了不同模型在 CoNLL 2005 & 2012 數(shù)據(jù)集上的性能。
傳統(tǒng) SRL 系統(tǒng)包含幾個(gè)階段:生成解析樹(shù),識(shí)別出哪些解析樹(shù)節(jié)點(diǎn)代表給定動(dòng)詞的論元,最后給這些節(jié)點(diǎn)分類(lèi)以確定對(duì)應(yīng)的 SRL 標(biāo)簽。每個(gè)分類(lèi)過(guò)程通常需要抽取大量特征,并將其輸入至統(tǒng)計(jì)模型中(Collobert et al., 2011)。
給定一個(gè)謂詞,T?ckstr?m 等人(2015)基于解析樹(shù),通過(guò)一系列特征對(duì)該謂詞的組成范圍以及該范圍與該謂詞的可能關(guān)系進(jìn)行打分。他們提出了一個(gè)動(dòng)態(tài)規(guī)劃算法進(jìn)行有效推斷。Collobert 等人(2011)通過(guò)解析以附加查找表形式提供的信息,并用卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)了類(lèi)似的結(jié)果。Zhou 和 Xu(2015)提出用雙向 LSTM 來(lái)建模任意長(zhǎng)度的上下文,結(jié)果發(fā)現(xiàn)不使用任何解析樹(shù)的信息也是成功的。
表 5:語(yǔ)義角色標(biāo)注
情感分類(lèi)
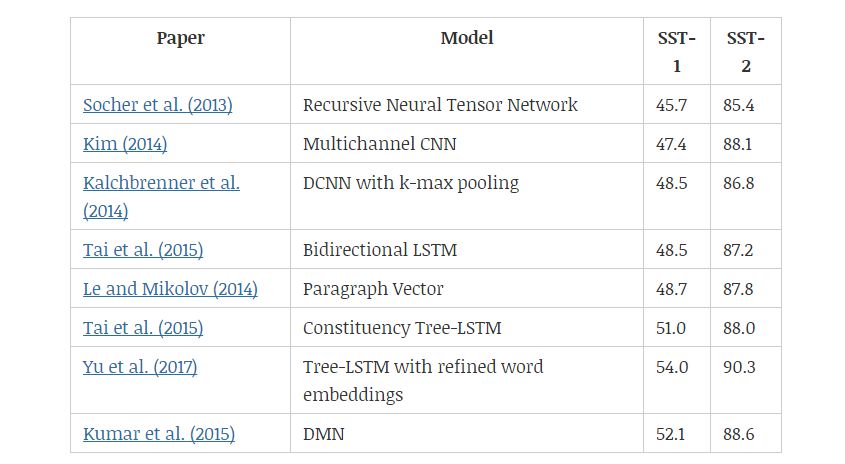
SST 數(shù)據(jù)集(Stanford Sentiment Treebank)包含從電影評(píng)論網(wǎng) Rotten Tomatoe 上收集的句子。它由 Pang 和 Lee(2005)提出,后來(lái)被 Socher 等人(2013)進(jìn)一步拓展。該數(shù)據(jù)集的標(biāo)注方案啟發(fā)了一個(gè)新的情感分析數(shù)據(jù)集——CMU-MOSI,其中模型需要在多模態(tài)環(huán)境中研究情感傾向。
Socher 等人(2013)和 Tai 等人(2015)都是通過(guò)成分解析樹(shù)及遞歸神經(jīng)網(wǎng)絡(luò)來(lái)改善語(yǔ)義表征。另一方面,樹(shù)形 LSTM(tree-LSTM)比線性雙向 LSTM 表現(xiàn)更好,說(shuō)明樹(shù)結(jié)構(gòu)能夠更好地捕捉自然句子的句法特性。Yu 等人(2017)提出用情感詞匯微調(diào)預(yù)訓(xùn)練的詞嵌入,然后基于 Tai 等人(2015)的研究觀察改進(jìn)結(jié)果。
Kim(2014)和 l Kalchbrenner 等人(2014)都使用卷積層。Kim 等人提出的模型與圖 5 中的相似,而 Kalchbrenner 等人通過(guò)將 k-max 池化層和卷積層交替使用,以分層方式構(gòu)建模型。
表 6:不同情感分類(lèi)模型在 SST-1 和 SST-2 數(shù)據(jù)集上的效果。
機(jī)器翻譯
基于短語(yǔ)的 SMT 框架(Koehn et al., 2003)將翻譯模型分解為原語(yǔ)短語(yǔ)和目標(biāo)語(yǔ)短語(yǔ)之間的概率匹配問(wèn)題。Cho et al. (2014) 進(jìn)一步提出用 RNN 編碼器-解碼器框架學(xué)習(xí)原語(yǔ)與目標(biāo)語(yǔ)的匹配概率。而基于循環(huán)神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器架構(gòu),再加上注意力機(jī)制在一段時(shí)間內(nèi)成為了業(yè)內(nèi)最標(biāo)準(zhǔn)的架構(gòu)。Gehring et al. (2017) 提出了基于 CNN 的 Seq2Seq 模型,CNN 以并行的方式利用注意力機(jī)制計(jì)算每一個(gè)詞的表征,解碼器再根據(jù)這些表征確定目標(biāo)語(yǔ)序列。Vaswani et al. (2017) 隨后提出了完全基于注意力機(jī)制的 Transformer,它目前已經(jīng)是神經(jīng)機(jī)器翻譯最常見(jiàn)的架構(gòu)了。
表 7:不同機(jī)器翻譯模型和 BLEU 值。
問(wèn)答系統(tǒng)
QA 問(wèn)題有多種形式,有的研究者根據(jù)大型知識(shí)庫(kù)來(lái)回答開(kāi)放性問(wèn)題,也有的研究者根據(jù)模型對(duì)句子或段落的理解回答問(wèn)題。對(duì)于基于知識(shí)庫(kù)的問(wèn)答系統(tǒng),學(xué)習(xí)回答單關(guān)系查詢的核心是數(shù)據(jù)庫(kù)中找到支持的事實(shí)。
表 8:不同模型在不同問(wèn)答數(shù)據(jù)集上的效果。
上下文嵌入
2018 年,使用預(yù)訓(xùn)練的語(yǔ)言模型可能是 NLP 領(lǐng)域最顯著的趨勢(shì),它可以利用從無(wú)監(jiān)督文本中學(xué)習(xí)到的「語(yǔ)言知識(shí)」,并遷移到各種 NLP 任務(wù)中。這些預(yù)訓(xùn)練模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 項(xiàng) NLP 任務(wù)中都獲得當(dāng)時(shí)最佳的性能。不過(guò)目前有 9 項(xiàng)任務(wù)都被微軟的新模型超過(guò)。下圖展示了不同模型在 12 種 NLP 任務(wù)中的效果:
小編曾解讀過(guò) BERT 的的核心過(guò)程,它會(huì)先從數(shù)據(jù)集抽取兩個(gè)句子,其中第二句是第一句的下一句的概率是 50%,這樣就能學(xué)習(xí)句子之間的關(guān)系。其次隨機(jī)去除兩個(gè)句子中的一些詞,并要求模型預(yù)測(cè)這些詞是什么,這樣就能學(xué)習(xí)句子內(nèi)部的關(guān)系。最后再將經(jīng)過(guò)處理的句子傳入大型 Transformer 模型,并通過(guò)兩個(gè)損失函數(shù)同時(shí)學(xué)習(xí)上面兩個(gè)目標(biāo)就能完成訓(xùn)練。
如上所示為不同預(yù)訓(xùn)練模型的架構(gòu),BERT 可以視為結(jié)合了 OpenAI GPT 和 ELMo 優(yōu)勢(shì)的新模型。其中 ELMo 使用兩條獨(dú)立訓(xùn)練的 LSTM 獲取雙向信息,而 OpenAI GPT 使用新型的 Transformer 和經(jīng)典語(yǔ)言模型只能獲取單向信息。
BERT 的主要目標(biāo)是在 OpenAI GPT 的基礎(chǔ)上對(duì)預(yù)訓(xùn)練任務(wù)做一些改進(jìn),以同時(shí)利用 Transformer 深度模型與雙向信息的優(yōu)勢(shì)。這種「雙向」的來(lái)源在于 BERT 與傳統(tǒng)語(yǔ)言模型不同,它不是在給定所有前面詞的條件下預(yù)測(cè)最可能的當(dāng)前詞,而是隨機(jī)遮掩一些詞,并利用所有沒(méi)被遮掩的詞進(jìn)行預(yù)測(cè)。








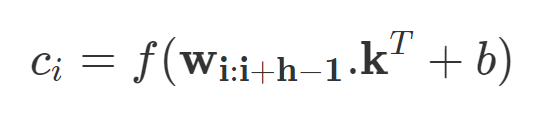







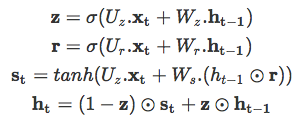
















-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122469 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22477
原文標(biāo)題:萬(wàn)字長(zhǎng)文概述NLP中的深度學(xué)習(xí)技術(shù)
文章出處:【微信號(hào):aicapital,微信公眾號(hào):全球人工智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
拿高薪必備的深度學(xué)習(xí)nlp技術(shù),這篇文章講得很透徹
基于深度學(xué)習(xí)的異常檢測(cè)的研究方法
基于深度學(xué)習(xí)的異常檢測(cè)的研究方法
專(zhuān)欄 | 深度學(xué)習(xí)在NLP中的運(yùn)用?從分詞、詞性到機(jī)器翻譯、對(duì)話系統(tǒng)
從語(yǔ)言學(xué)到深度學(xué)習(xí)NLP,一文概述自然語(yǔ)言處理
對(duì)2017年NLP領(lǐng)域中深度學(xué)習(xí)技術(shù)應(yīng)用的總結(jié)
NLP的介紹和如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP以及三種NLP技術(shù)的詳細(xì)介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論