") FunASR語音大模型在Arm Neoverse平臺上的優(yōu)化實踐流程
FunASR語音大模型在Arm Neoverse平臺上的優(yōu)化實踐流程
Arm 架構(gòu)在服務(wù)器領(lǐng)域發(fā)展勢頭前景看好。目前已有許多頭部云服務(wù)提供商和服務(wù)器制造商推出了基于 Arm Neoverse 平臺的服務(wù)器產(chǎn)品,例如 AWS Graviton、阿里云的倚天 710 系列等。這些廠商提供了完整的軟硬件支持和優(yōu)化,使得大模型推理在基于 Arm 架構(gòu)的服務(wù)器上運行更加便捷和高效。
Arm 架構(gòu)的服務(wù)器通常具備低功耗的特性,能帶來更優(yōu)異的能效比。相比于傳統(tǒng)的 x86 架構(gòu)服務(wù)器,Arm 服務(wù)器在相同功耗下能夠提供更高的性能。這對于大模型推理任務(wù)來說尤為重要,因為大模型通常需要大量的計算資源,而能效比高的 Arm 架構(gòu)服務(wù)器可以提供更好的性能和效率。
Armv9 新特性提高大模型推理的計算效率
Armv9 架構(gòu)引入了 SVE2 (Scalable Vector Extension,可擴展向量延伸指令集)。SVE2 是一種可擴展的向量處理技術(shù),它允許處理器同時執(zhí)行多個數(shù)據(jù)元素的操作,可以提供更高效的向量計算和人工智能 (AI) 硬件加速,從而加快了 AI 任務(wù)的執(zhí)行速度,提高了能效和性能。這對于在 Arm 架構(gòu)的服務(wù)器上進行大規(guī)模 AI 推理和訓(xùn)練任務(wù)非常有益,不論是實現(xiàn)更好的用戶體驗或是更高的計算效率。
SVE2 對 AI 推理引擎的支持有效地使用了 BFloat16 (BF16) 格式,BF16 是一種浮點數(shù)格式,它使用 16 位表示浮點數(shù),其中 8 位用于指數(shù)部分,7 位用于尾數(shù)部分,還有 1 位用于符號位。相比于傳統(tǒng)的 32 位浮點數(shù)格式(如 FP32),BF16 在表示范圍和精度上有所減少,但仍然能夠滿足大多數(shù) AI 推理任務(wù)的需求。
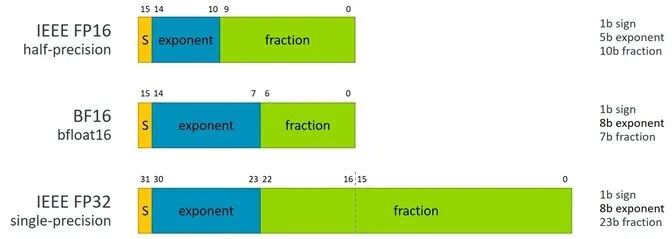
圖 1:BFloat16 格式
BF16 格式可以在減少存儲和帶寬需求之余,同時提供足夠的精度,來滿足大多數(shù) AI 推理任務(wù)的要求。由于 SVE2 提供了針對 BF16 的向量指令,可以在同一條指令中同時處理多個 BF16 數(shù)據(jù)元素,從而提高計算效率。理論上來說,采用 BF16 可以實現(xiàn)雙倍的 FP32 的性能。
SVE2 的矩陣運算在 AI 推理中扮演著重要的角色,它可以顯著提高計算效率和性能。比如矩陣乘法 (Matrix Multiplication) 是許多 AI 任務(wù)中常見的運算,如卷積運算和全連接層的計算。SVE2 的向量指令可以同時處理多個數(shù)據(jù)元素,使得矩陣乘法的計算能夠以向量化的方式進行,從而提高計算效率。指令 FMMLA 可以實現(xiàn) FP32 格式下兩個 2x2 矩陣乘法運算,指令 BFMMLA 可以通過單指令實現(xiàn) BF16 格式下 4x2 矩陣和 2x4 矩陣的乘法,UMMLA、SMMLA 等可以實現(xiàn) INT8 格式下 8x2 矩陣和 2x8 矩陣的矩陣乘法運算。通過 SVE2 的硬件加速功能,AI 推理可以在 Arm 架構(gòu)中獲得更高效的矩陣運算執(zhí)行,提高計算效率和性能。
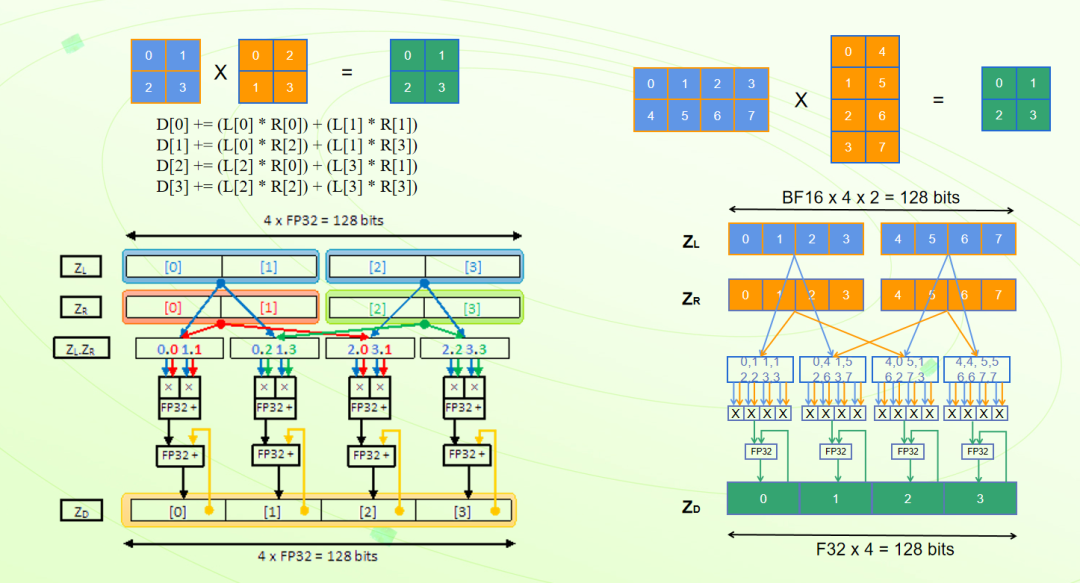
圖 2:矩陣乘指令
ACL 實現(xiàn) PyTorch 的計算加速
PyTorch 可以支持 Arm 架構(gòu)的硬件加速資源,但需要安裝適用于 Arm 架構(gòu)的 PyTorch 版本,或者是從開源源代碼編譯支持 Arm 架構(gòu)硬件加速的 PyTorch 版本。Arm Compute Library (ACL, Arm 計算庫) 實現(xiàn)了 Arm 架構(gòu)的硬件加速資源的優(yōu)化封裝,通過 OneDNN 來使 PyTorch 對 Arm 優(yōu)化加速調(diào)用。下面介紹如何生成帶 ACL 加速的 PyTorch 版本。
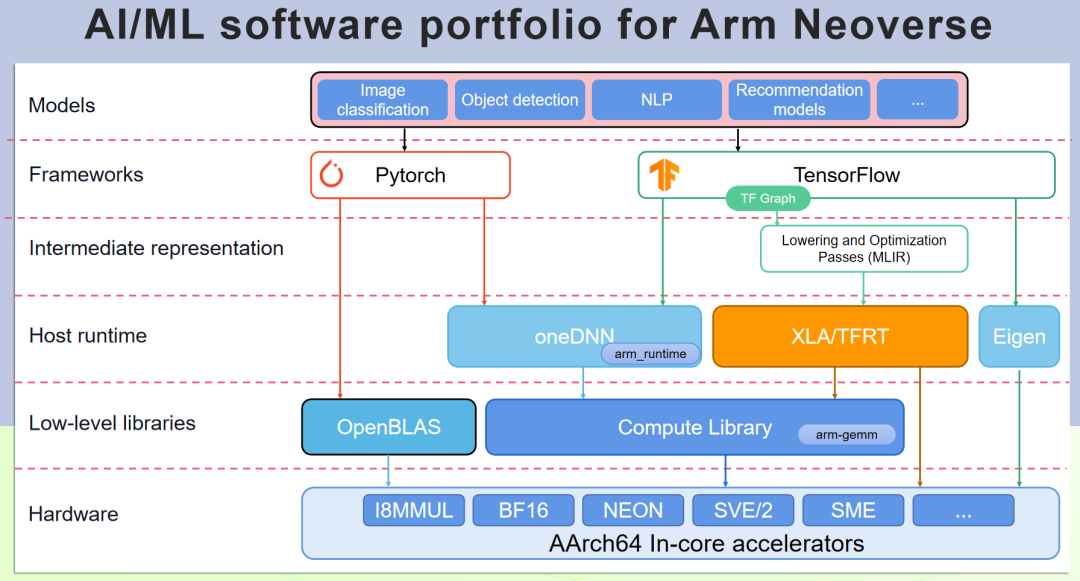
圖 3:Arm Neoverse 平臺 AI/ML 軟件組合
ACL 是開源軟件,下載后編譯并設(shè)定相應(yīng)的系統(tǒng)路徑。
鏈接:https://github.com/arm-software/ComputeLibrary
# git clone https://github.com/ARM-software/ComputeLibrary.git
# scons arch=armv8.6-a-sve debug=0 neon=1 os=linux opencl=0 build=native -j 32 Werror=false
validation_tests=0 multi_isa=1 openmp=1 cppthreads=0 fixed_format_kernels=1
# export ACL_ROOT_DIR=/path_to_ACL/ComputeLibrary
開源軟件 OpenBLAS 也實現(xiàn)了部分 Neon 的加速,PyTorch 同樣也要依賴 OpenBLAS,下載相應(yīng)源代碼編譯和安裝。
鏈接:https://github.com/OpenMathLib/OpenBLAS
# git clone https://github.com/OpenMathLib/OpenBLAS.git
# cmake & make & make install
獲取開源的 PyTorch 代碼,下載相應(yīng)的依賴開源軟件,指定使能 ACL 的方法進行編譯,獲取 PyTorch 的安裝包并更新。
# git clone https://github.com/pytorch/pytorch
# git submodule update --init –recursive
# MAX_JOBS=32 PYTORCH_BUILD_VERSION=2.1.0 PYTORCH_BUILD_NUMBER=1 OpenBLAS_HOME=/opt/openblas
BLAS="OpenBLAS" CXX_FLAGS="-O3 -mcpu=neoverse-n2 -march=armv8.4-a" USE_OPENMP=1 USE_LAPACK=1 USE_CUDA=0
USE_FBGEMM=0 USE_DISTRIBUTED=0 USE_MKLDNN=1 USE_MKLDNN_ACL=1 python setup.py bdist_wheel
# pip install --force-reinstall dist/torch-2.x.x-cp310-cp310-linux_aarch64.whl
配置了運行環(huán)境,就可以利用 Arm 架構(gòu)的硬件加速資源來加速 PyTorch 的計算。盡管 PyTorch 可以在 Arm 架構(gòu)上利用硬件加速資源,但針對具體模型和應(yīng)用場景,需要對模型和代碼進行一些調(diào)整以最大程度地發(fā)揮硬件的加速優(yōu)勢。
基于 FunASR 的優(yōu)化實踐
FunASR 是阿里巴巴達摩院開發(fā)的開源的基于 Paraformer 的大模型語音識別模型,提供包括語音識別 (ASR)、語音端點檢測 (VAD)、標點恢復(fù)、語言模型、說話人驗證、說話人分離和多人對話語音識別等在內(nèi)的多種功能。本文以 FunASR 在 Arm Neoverse 平臺上優(yōu)化的過程做為大模型的優(yōu)化實踐案例。
倉庫地址:https://github.com/alibaba-damo-academy/FunASR
圖 4:FunASR
本次優(yōu)化是基于 ACL v23.08、oneDNN v3.3、PyTorch v2.1 進行,測試平臺基于阿里云的 ECS 公有云,包括 C8Y、C8I、C7 等云實例。
為了確保 PyTorch 已經(jīng)啟動 ACL 進行加速,可以加上 “DNNL_VERBOSE=1” 來查看運行的日志輸出。
# OMP_NUM_THREADS=16 DNNL_VERBOSE=1 python runtimes.py
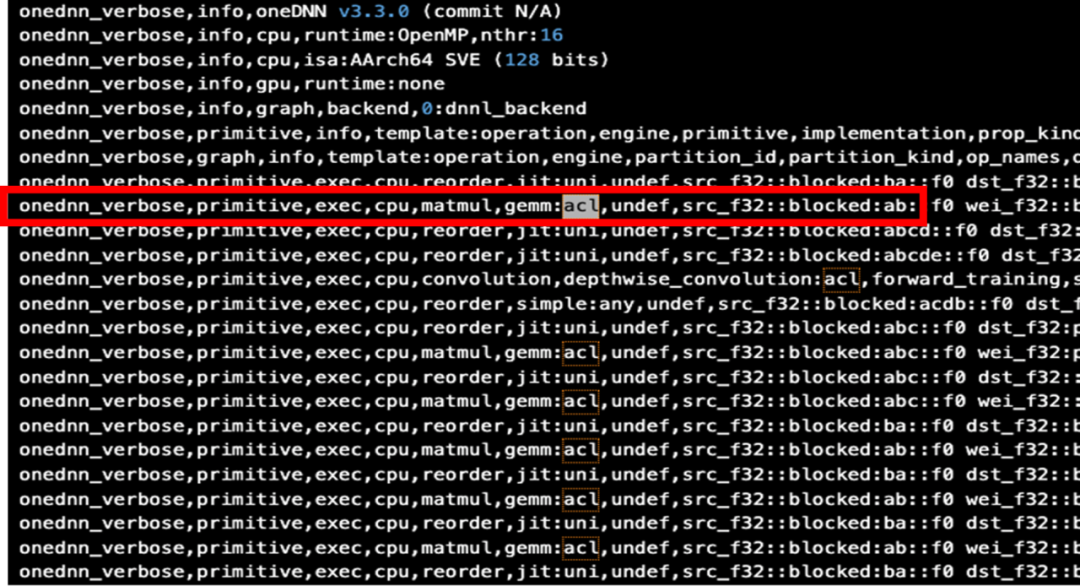
圖 5:使能 ACL 的 PyTorch 運行日志
得到如上的輸出結(jié)果,可以看到已經(jīng)啟用了 ACL。
為了使優(yōu)化有明確的目標,在運行大模型時,用 PyTorch 的 profiler 做整個模型的數(shù)據(jù)統(tǒng)計,即在調(diào)用大模型之前加上統(tǒng)計操作,為了減少單次運行的統(tǒng)計誤差,可以在多次運行之后做統(tǒng)計并輸出統(tǒng)計結(jié)果,如下面的示例:

默認運行是用 FP32 的格式,如果需要指定 BF16 的格式運行,需要加上 “ONEDNN_DEFAULT_FPMATH_MODE=BF16” 的參數(shù)。
# OMP_NUM_THREADS=16 ONEDNN_DEFAULT_FPMATH_MODE=BF16 python profile.py
得到 profile 的統(tǒng)計數(shù)據(jù):
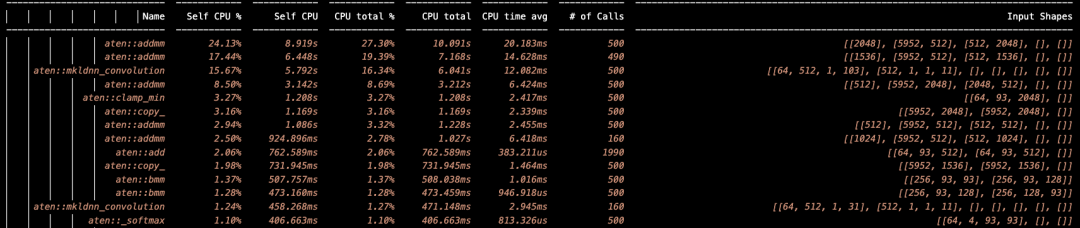
圖 6:統(tǒng)計分析日志
分析運行的結(jié)果,找出需要優(yōu)化的算子,在這個示例中,mkldnn_convolution 運行的時間顯著較長。
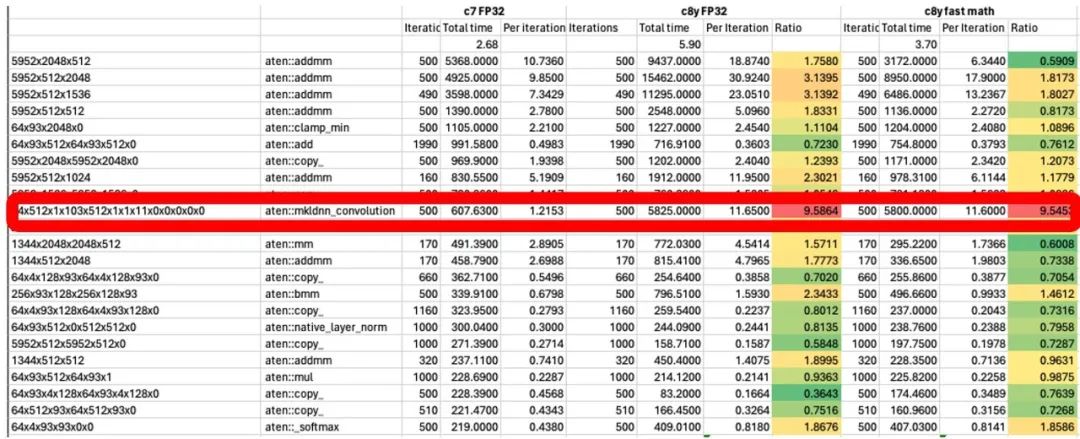
圖 7:優(yōu)化前統(tǒng)計分析
通過分析定位,發(fā)現(xiàn)在 OMP 的操作中,數(shù)據(jù)并沒有按照多處理器進行并行數(shù)據(jù)處理,修復(fù)問題后,再次測試,發(fā)現(xiàn) Convolution 的效率大大提升。
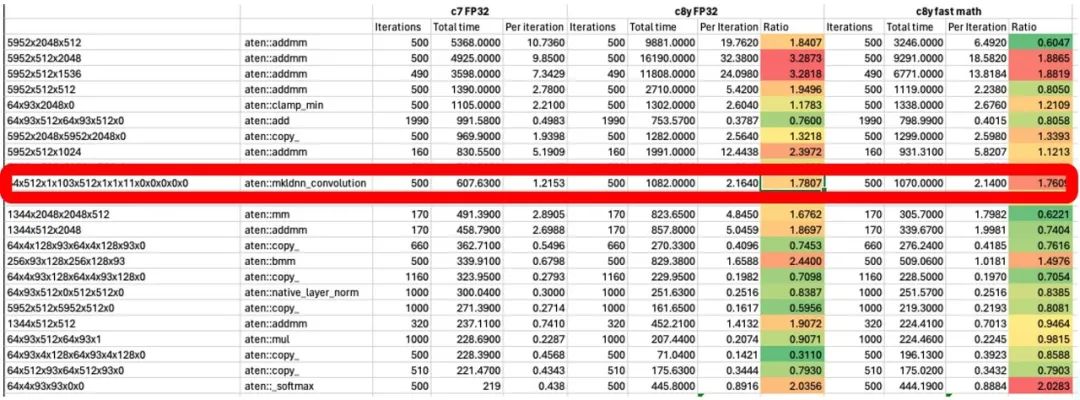
圖 8:卷積優(yōu)化后統(tǒng)計分析
在 Arm 架構(gòu)處理器中,SVE2 可以對 INT8 進行并行數(shù)據(jù)處理,比如單指令周期可以做到 16 個 INT8 的乘累加操作,對 INT8 的執(zhí)行效率非常高,在對模型執(zhí)行效率有更高要求的場景下,可以用 INT8 來動態(tài)量化模型,進一步提高效率。當然,也可以把 INT8 和 BF16 相結(jié)合,模型用 INT8 量化,中間計算用 BF16 格式,相較其他平臺,有 1.5 倍的效率提升。
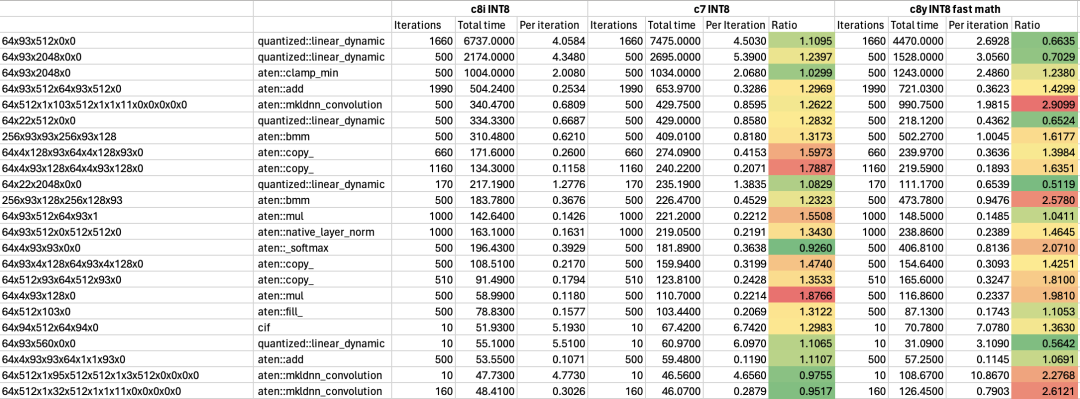
圖 9:動態(tài)量化優(yōu)化
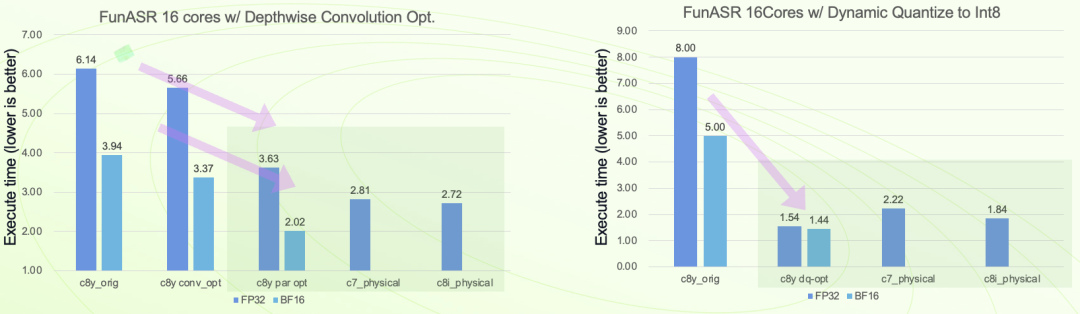
圖 10:優(yōu)化結(jié)果對比
綜上,通過充分利用 Armv9 架構(gòu)中的 SVE2 指令、BF16 數(shù)據(jù)類型等特性,并引入動態(tài)量化等技術(shù),能夠?qū)崿F(xiàn)以 FunASR 為例的大模型在 Arm Neoverse 平臺的服務(wù)器上高效率運行。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19802瀏覽量
233520 -
ARM
+關(guān)注
關(guān)注
134文章
9305瀏覽量
374972 -
語音識別
+關(guān)注
關(guān)注
39文章
1773瀏覽量
113899 -
pytorch
+關(guān)注
關(guān)注
2文章
809瀏覽量
13760
原文標題:FunASR 語音大模型在 Arm Neoverse 平臺上的優(yōu)化實踐
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
解讀基于Arm Neoverse V2平臺的Google Axion處理器
智能語音交互方案在客服領(lǐng)域的應(yīng)用
Arm助力開發(fā)者加速遷移至Arm架構(gòu)云平臺 Arm云遷移資源分享
如何在基于Arm Neoverse平臺的CPU上構(gòu)建分布式Kubernetes集群
使用OpenVINO?進行優(yōu)化后,為什么DETR模型在不同的硬件上測試時顯示不同的結(jié)果?
利用Arm Kleidi技術(shù)實現(xiàn)PyTorch優(yōu)化

HAL庫在Arduino平臺上的使用
Arm Neoverse如何加速實現(xiàn)AI數(shù)據(jù)中心
基于Arm Neoverse N2實現(xiàn)自動語音識別技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論