 如何在基于Arm Neoverse平臺的CPU上構建分布式Kubernetes集群
如何在基于Arm Neoverse平臺的CPU上構建分布式Kubernetes集群
作者:Arm 基礎設施事業部 AI 解決方案架構師 Na Li
如今,社交媒體影響力廣泛,涵蓋個人、社會、政治、經濟和文化等諸多領域。洞察用戶情緒可以幫助企業快速了解公眾對各類事件、趨勢和產品的反應。這種基于數據的洞察對于企業的聲譽管理、市場研究和決策制定至關重要。社交媒體提供了一個實時交流和信息共享的平臺,使其成為衡量公眾情緒的強大實時渠道。因此,實時追蹤用戶情緒變化能夠幫助企業洞察情緒模式并迅速做出明智決策,從而及時采取適當行動。然而,實時情緒監控是一項計算密集型任務,如果管理不善,可能會迅速增加資源消耗,包括計算和成本等。
在本文中,我們將以 X(原 Twitter)為例,演示如何在基于 Arm Neoverse 平臺的 CPU 上構建分布式 Kubernetes 集群,以根據推文實時監控情緒變化。如此一來,你可以充分利用 Arm Neoverse 平臺的計算基礎,獲得更好的性能、效率和出色的靈活性。
你也可以借鑒本用例的主要原則,對其他社交媒體平臺部署類似的解決方案,并在多個主要云服務提供商(包括 AWS、Google Cloud 、Microsoft Azure 和阿里云)中充分利用基于 Arm Neoverse 平臺的云實例。
基于 Arm Neoverse 平臺的EC2 AWS Graviton 實例的性能和效率
亞馬遜云科技 (AWS) 提供由基于 Arm Neoverse 架構的 AWS Graviton 處理器賦能的 EC2 實例。這些實例基于 Graviton2、Graviton3 和 Graviton4 構建,不僅性能強大,而且成本效益顯著。為了充分利用這些優勢,我們在 AWS Graviton 實例上開發了我們的用例,使用了 Amazon Kinesis、Apache Spark、Amazon EKS(Graviton3 實例)、Amazon EC2(Graviton4 實例)、Amazon Elastic Search 和 Kibana dashboard、Prometheus 以及 Grafana(見圖 1)。我們的用例可以快速創建和執行大規模并行機器學習作業,通過啟用不同的節點來獲得實時洞察。這樣,企業就能利用實時洞察,在瞬息萬變的世界中保持適應性、響應性和韌性。
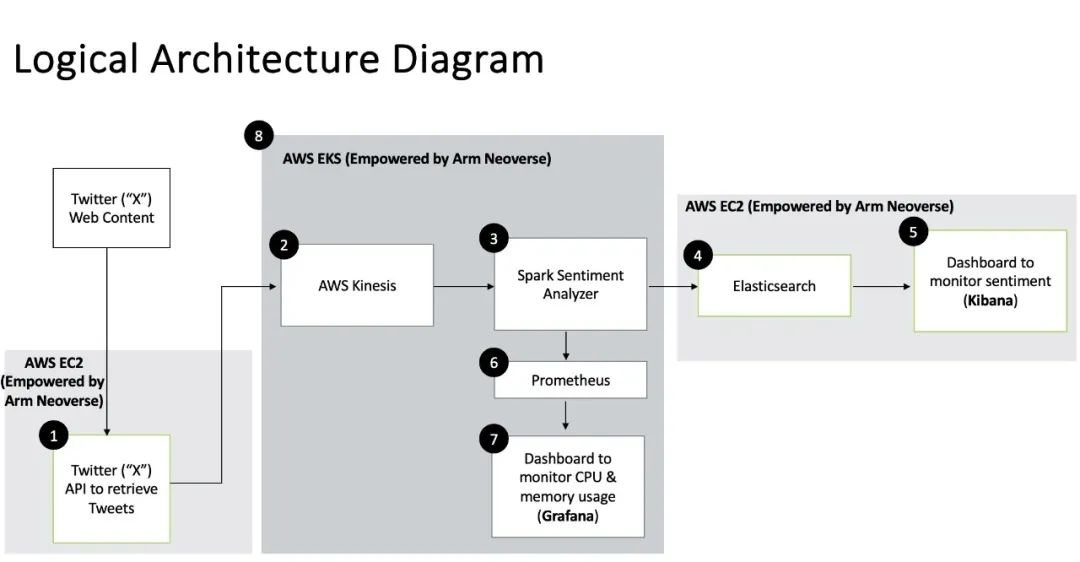
圖 :以 AWS 為例的邏輯架構圖
此外,請注意,基于 Arm Neoverse 平臺的實例可在 Google Cloud 和 Microsoft Azure 中使用。因此,使用這種邏輯架構,你同樣可以使用 Google Cloud 和 Microsoft Azure 服務搭建類似的解決方案。現在,我們將以 AWS 為例,逐一介紹架構圖中的每個組件,解釋其用途和構建方式,幫助你全面了解整個系統。我們也將發布包含代碼示例的學習路徑,以便你復制和構建自己的解決方案。
1設置 X API 以檢索推文
為了及時檢索 X 上發布的新推文,我們將使用 X 開發者 API,這是一套由 X 提供的編程工具和協議,允許開發者以編程方式訪問 X 數據并與之交互。通過它,我們可以從 X 龐大的推文、用戶信息和其他社交媒體內容數據庫中收集、過濾和分析信息。
要開始使用,首先需要創建一個 X 開發者賬戶以使用 X API。你必須首先使用開發者門戶創建一個項目和一個應用。然后,創建 API Key、API Secret、Access Token 和 Access Token Secret,以對你的應用進行身份驗證并讀取推文。請注意,X 會根據你的應用訂閱類型,對你可檢索的推文數量設置速率限制和約束,以確保服務的可靠性。
2使用 AWS Kinesis 處理數據
AWS Kinesis 是一種完全托管的數據流服務,專為處理大量實時數據而構建。在我們的設置中,我們將使用 AWS Kinesis 從 XAPI 采集實時數據,確保每一條符合我們篩選條件(如標簽、關鍵詞、賬戶、語言、時間范圍等)的推文在發布后立即直接流入 Kinesis。為了完成這一配置,請按照指南進行操作。Twitter API 腳本將每條推文作為 JSON 對象發送到 Kinesis 流中,使訂閱者可以隨時使用這些數據。
3執行情緒分析
情緒分析器是一種文本分類模型,可檢測推文的情緒基調,并根據所使用的詞匯將其分為三個或更多類別。這樣,應用用戶無需手動閱讀每條推文,就能快速了解關于特定主題的實時觀點。分析結果提供了寶貴的情緒洞察,幫助用戶基于數據做出明智的決策。有幾種方法可以計算情緒:你可以自行訓練文本分類模型,但這需要標注數據,而且耗時較長;或者像我們的方法一樣,你可以使用預訓練的情緒分類模型。
我們使用 Spark Streaming 處理推文中的情緒信息,這是 Spark 中的一個 API,用于對高吞吐量數據流(如 Kafka、AWS Kinesis、HDFS/S3 和 Flume)進行可靠的流處理。它會將輸入數據流分割成小批次,并通過 Spark 引擎進行處理,生成一系列處理后的數據流。在 Spark SQL 的基礎上,Spark 提供了名為 Structured Streaming 的流式 API。它允許數據以數據集/數據幀(RDD 上的 API)的形式呈現,并允許對流式數據上使用優化的 Spark SQL 引擎處理。
Spark Streaming API 從 Kinesis 流中讀取推文流。Spark 引擎對接收的數據幀運行作業,使用斯坦福核心自然語言處理 (NLP) 庫中的預訓練情緒分類模型進行處理,為每條推文生成以下標簽之一的輸出結果:[非常消極、消極、中立、積極、非常積極]。然后將結果發送到 Elasticsearch。
4設置 Elasticsearch
Elasticsearch 是一款強大的開源搜索和分析引擎,專為近乎實時的高效存儲、搜索和分析大規模數據而設計。它能夠快速攝取數據,并能近乎即時地進行搜索。其實時索引功能對于處理從 API 或事件流持續流入的高速數據流(如推文)至關重要。要在 AWS EC2 實例上設置 Elasticsearch,你可以參考相關說明。
5在 Kibana dashboard 中的可視化數據
Kibana 是一款開源可視化工具,可與 Elasticsearch 無縫協作,提供了一個用于探索、可視化和交互數據的界面。利用 Elasticsearch 和 Kibana,用戶可以與數據交互、應用過濾器,并在情緒急劇下降時收到警報,全部功能都是實時的。如果你的 Elasticsearch 部署最初不包括 Kibana 實例,可以按照說明首先啟用 Kibana。
對于新的 Elasticsearch 集群,會自動為你創建一個 Kibana 實例,以便你可以直接訪問。啟用 Kibana 后,你可以參考文件設置所需的可視化,以顯示來自 Elasticsearch 的數據。
6使用 Prometheus 監控 Kubernetes 指標
Prometheus 是一個監控和警報工具包。它廣泛用于收集和查詢 Kubernetes 等云原生環境中的實時指標。Prometheus 收集有助于監控 Kubernetes 集群的健康狀況和性能的關鍵指標(如 CPU、內存使用率、pod 數量、請求延遲)。
7使用 Grafana 可視化呈現 Prometheus
Grafana 是一款可視化和分析工具,能夠與 Prometheus 數據源集成,用于創建交互式儀表盤來監控和分析 Kubernetes 指標隨時間的變化。我們使用 Helm 在 Kubernetes 上部署了 Prometheus 和 Grafana。
8設置 AmazonElastic Kubernetes Service
AmazonEKS是 AWS 管理的 Kubernetes 服務,允許你部署、管理和擴展應用。對于我們的應用而言,由于推文數量會因熱門話題或事件而大幅波動,因此 EKS 允許自動擴展 Kubernetes pod 和節點,確保情緒分析應用有足夠的資源來處理峰值負載,并在流量減少時自動縮減,從而優化成本效益。
HashiCorp 提供了關于如何在 AWS 上配置 EKS 集群的文檔。另外還提供了 Terraform 腳本來幫助自動設置。要在基于 Graviton3 的實例上運行,需要進行一些調整:
確定你希望用于運行集群的 EKS 支持的 Kubernetes 版本。可以在 eks-cluster.tf 中設置版本;
確定該 Kubernetes 版本的優化 Amazon Linux AMI;
更新 worker 組參數。

結果和總結
每條推文的推理時間取決于其長度和所使用的模型。為了實現準確的情緒預測,可以選擇較大的模型,與較小的模型相比,雖會增加延遲,但情緒預測的準確性更高。由于推文長度各不相同,推理時間也會相應波動,每條推文平均約為幾百毫秒。這意味著我們的用例在使用大的模型時,每秒可處理約 5-10 條推文。運行較小的模型通常更快,延遲時間縮短一半,每秒可處理 20-30 條推文。歡迎各位一起動手親自體驗!
-
ARM
+關注
關注
134文章
9304瀏覽量
374897 -
集群
+關注
關注
0文章
101瀏覽量
17366 -
開源
+關注
關注
3文章
3582瀏覽量
43456 -
kubernetes
+關注
關注
0文章
239瀏覽量
8967 -
Neoverse
+關注
關注
0文章
12瀏覽量
4743
原文標題:如何在基于 Arm Neoverse 平臺的 Kubernetes 集群上實現實時情緒分析
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Kubernetes 網絡模型如何實現常見網絡任務
EasyGo使用筆記丨分布式光伏集群并網控制硬件在環仿真應用
阿里云上Kubernetes集群聯邦
阿里云彈性計算Apsara Block Storage正式發布 構建企業級分布式塊存儲服務平臺
spark集群使用hanlp進行分布式分詞操作說明
如何在Arm上利用Istio搭建一個基于Kubernetes的Service Mesh平臺
ARM Neoverse IP的AWS實例上etcd分布式鍵對值存儲性能提升
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
如何部署基于Mesos的Kubernetes集群





 工商網監
工商網監
評論