") 如何適配新架構?TPU-MLIR代碼生成CodeGen全解析!
如何適配新架構?TPU-MLIR代碼生成CodeGen全解析!
背景介紹
TPU-MLIR的CodeGen是BModel生成的最后一步,該過程目的是將MLIR文件轉(zhuǎn)換成最終的Bmodel。本文介紹了CodeGen的基本原理和流程,并記錄了針對BM1684X等新架構的CodeGen重構過程。
與后端的關系
由于一些歷史的因素,MLIR文件中的每個OP對應的指令并不直接在TPU-MLIR工程中生成,而是需要調(diào)用后端的函數(shù)完成最終指令的生成,這也帶來了兩個問題
- 如何設計編譯器與后端的接口
- 生成指令的數(shù)據(jù)結構存在后端還是編譯器中
關于問題1,目前的設計是采用CodeGen與后端隔離的形式,也就是CodeGen過程不直接調(diào)用后端函數(shù),而是將不同處理器的相應函數(shù)全部封裝到類中,在CodeGen中調(diào)用類方法間接使用后端接口,達成解耦。
而關于問題2,依據(jù)不同的處理器其數(shù)據(jù)結構位置也不同,1684的數(shù)據(jù)結構放在編譯器這邊,而BM1684X等新架構的處理器數(shù)據(jù)結構放在后端。無論放在哪里,其全部封裝于問題1答案中的相應類中,對于CodeGen過程來說,看到的接口是一樣的。
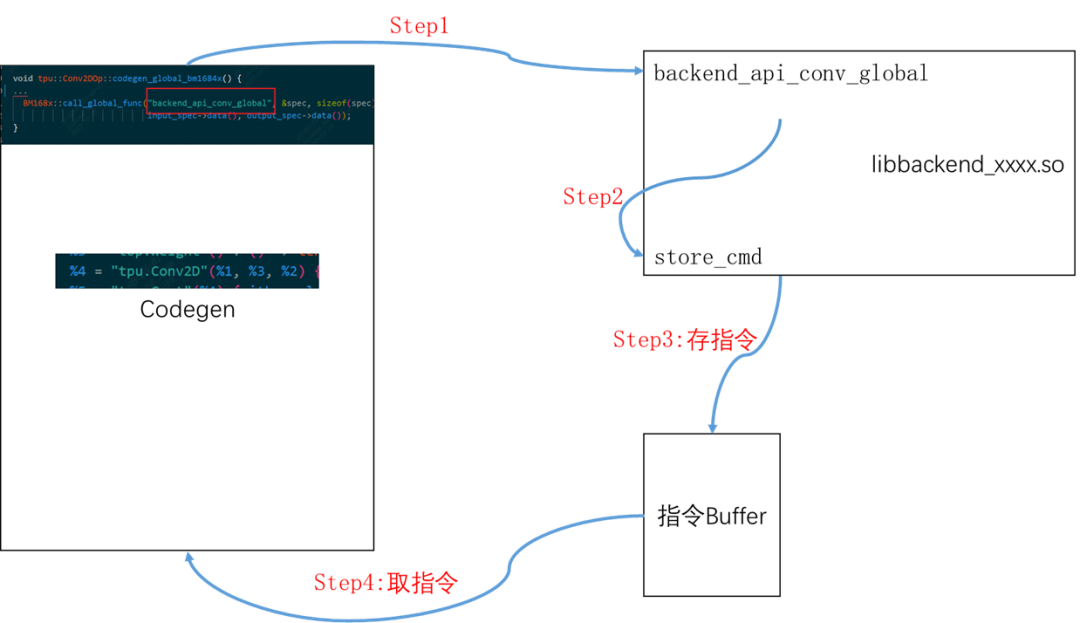
一個OP生成指令的大致流程
代碼位置:lib/Dialect/Tpu/Transforms/Codegen/BM168xCodegen.cpp
該流程忽略CodeGen代碼內(nèi)部細節(jié),這里只講解類似于把大象裝冰箱主要分幾步這樣的通俗介紹。
- 在BM168XCodegen.cpp會遇到某個Op時會調(diào)用該op的codegen_local_bm168x/codegen_global_bm168x,算子的這個函數(shù)都在lib/Dialect/Tpu/Interfaces/中
- 在具體OP中會設置一些參數(shù),然后調(diào)用到后端的具體op的指令生成,比如Conv2d算子會調(diào)用后端函數(shù)backend_api_conv_global
- (后端過程)直接做一系列檢查后,會直接生成指令(二進制碼),這些二進制碼會通過store_cmd存儲在指定數(shù)據(jù)結構中,
- 等所有op的二進制碼全部都生成完畢后,在編譯器會調(diào)用BM1684X系列類中封裝的函數(shù)取走指令,生成Bmodel
做個形象點的例子:
原來裝冰箱只需要我,現(xiàn)在我嫌大象沉,我叫個張三幫我裝。
我:張三,你把這個大象給我裝冰箱里
張三吭哧吭哧幫我裝完了
我:行了,張三,你走吧;我自己把裝的運走。
指令生成所需要的數(shù)據(jù)結構
指令依據(jù)處理器的engine不同而有所差別,比如1684有GDMA和TIU,而新架構的處理器SG2260會存在sdma、cdma等engine。這里拿最通用的兩種engine即BDC(后更名為TIU)和GDMA為例:
std::vector<uint32_t>bdc_buffer;
std::vector<uint32_t>gdma_buffer;
uint32_tgdma_total_id=0;
uint32_tbdc_total_id=0;
std::vector<uint32_t>gdma_group_id;
std::vector<uint32_t>bdc_group_id;
std::vector<uint32_t>gdma_bytes;
std::vector<uint32_t>bdc_bytes;
intcmdid_groupnum=0;
CMD_ID_NODE*cmdid_node;
CMD_ID_NODE*bdc_node;
CMD_ID_NODE*gdma_node;
- bdc_buffer和gdma_buffer:放指令
- gdma_total_id和bdc_total_id:存指令總數(shù)目,因為指令不一定是32位的,因此使用buffer的長度不能獲取到指令的總數(shù)目
- gdma_group_id和bdc_group_id:每個group中的指令數(shù),這個group是什么意思待調(diào)查清楚,后端對其進行控制時代碼如下所示
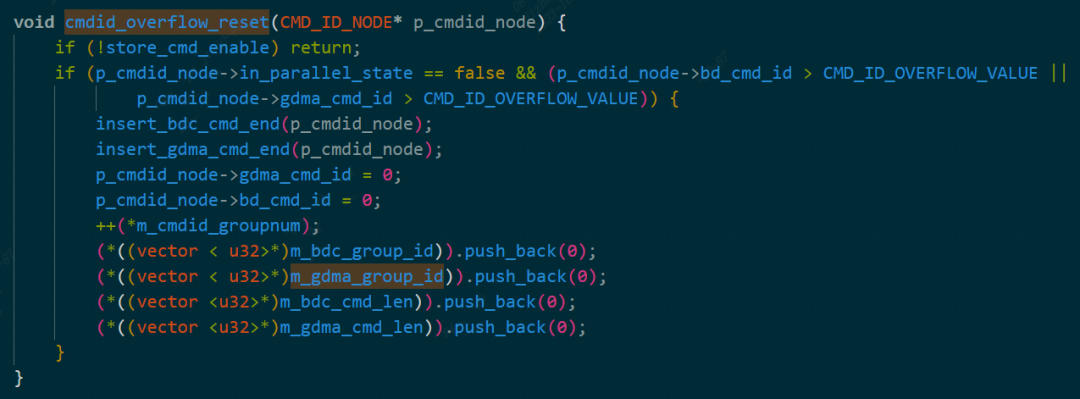
cmdid_overflow
- cmdid_groupnum:group的數(shù)量
- gdma_bytes和bdc_bytes:內(nèi)部是每個group中指令的字節(jié)(Bytes)數(shù)
- cmdid_node、bdc_node和gdma_node:這個node是為了并行生成GroupOp內(nèi)部所需要指令而形成指的,具體機制還有待研究
TPU-MLIR中l(wèi)ayer group和上述行為中group的概念區(qū)分
TPU-MLIR中的layer group是指可以存放在Lmem的一系列算子,組成一個Group Op。
而上述的group,指的是指令組。這個指令組存在的意義是防止內(nèi)存不夠用,比方說1684只有16位尋址空間,那么大于這個數(shù)字的指令無法一次性全部搬運到內(nèi)存,所以當指令超出某個數(shù)時候,就會重新建一個組。
TPU-MLIR中BM168X及其相關類
這邊的相關類tpu-mlir/include/tpu_mlir/Backend該文件夾下定義的類,目的就是將不同的處理器后端封裝,從而實現(xiàn)后端于Codegen過程的隔離。
其繼承關系為:
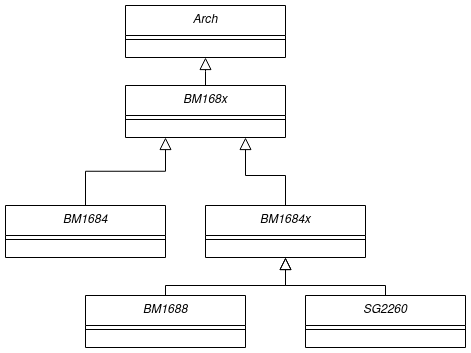
在一次運行中只存在一個類(設計模式中單例),該類初始化時候會經(jīng)過:讀取后端動態(tài)鏈接庫、加載函數(shù)(設置后端的函數(shù)指針)、指令數(shù)據(jù)結構的初始化、設置一些處理器相關的參數(shù)例如NPU_NUM、L2_SRAM起始地址等。
后端函數(shù)的加載
后端作為一個動態(tài)庫放入了TPU-MLIR工程里,具體在third_party/nntoolchain/lib/libbackend_xxx.so。在我們要使用backend時候,先在需要函數(shù)的類中定義好函數(shù)指針,然后再將動態(tài)庫加載后,使函數(shù)指針指向動態(tài)庫中真正的函數(shù)。
以同步函數(shù)tpu_sync_all為例,由于之后要加上多核支持的,所以需要在相關后端Bmodel庫中定義好,
- 注意必須和后端的函數(shù)名和參數(shù)保持一致typedef void (*tpu_sync_all)();
- 在類內(nèi)部加入該函數(shù)成員tpu_sync_all, dl_tpu_sync_all;
- 有成員后,在該類load_functions函數(shù)的實現(xiàn)中加入宏,CAST_FUNCTION(tpu_sync_all);該宏可以將dl_tpu_sync_all指向動態(tài)庫中真正的函數(shù)
這時候在我們獲得到該類實例后即可使用動態(tài)庫中的函數(shù)了。
后端store_cmd設計
后端的store_cmd功能是指編譯器調(diào)用算子的過程中,把配置的指令保存到約定空間的過程。(以下是后端代碼,以后會選擇性開放)。后端的重點函數(shù)在store_cmd.cpp中,以cmodel/src/store_cmd.cpp;cmodel/include/store_cmd.h為例
注:store_cmd類設計的非常復雜,參雜各種設計模式在里面,只大概梳理一下類之間關系
store_cmd分別有EngineStorer系列類和CmdStorer系列類:
- EngineStoreInterface(接口類)、繼承于EngineStoreInterface接口的GDMAEngineStorer、BDEngineStorer等具體類、EngineStorerDecorator(裝飾類接口)、繼承于EngineStorerDecorator的VectorDumpEngineStorerDecorator等具體裝飾類
- CmdStorerInterface(接口)、繼承于接口的ConcretCmdStorer、StorerDecorator:裝飾接口、VectorDumpStorerDecorator具體裝飾類。
關于類之間的關系與邏輯
- 使用單例設計模式,在store_cmd中只存在一個ConcretCmdStorer類,該類中會存所有EngineStorer的類,當調(diào)用不同的engine時,會調(diào)用不同EengineStorer,如下代碼
virtualvoidstore_cmd(intengine_id,void*cmd,CMD_ID_NODE*cur_id_node,
intport)override
{
switch(engine_id)
{
caseENGINE_BD:
caseENGINE_GDMA:
caseENGINE_HAU:
caseENGINE_SDMA:
port=0;
break;
caseENGINE_CDMA:
ASSERT(port break;
caseENGINE_VSDMA:
engine_id=ENGINE_SDMA;
break;
default:
ASSERT(0);
break;
}
returnthis->get(engine_id,port)->store(cmd,cur_id_node);
}
- Cmd裝飾類的作用是將所有的EngineStorer套上其裝飾器的殼子(目的實現(xiàn)其他功能),以VectorDumpStorerDecorator為例,會使用宏為每個EngineStorer、套上VectorDumpEngineStorerDecorator的殼子。
voiddecorate_engines()
{
#defineDECOR_STORER(name,idx)\
if(outputs_[ENGINE_##name][idx])\
{\
autoname##_str=std::make_shared(\
StorerDecorator::get(ENGINE_##name,idx),\
&(outputs_[ENGINE_##name][idx]));\
StorerDecorator::get(ENGINE_##name,idx)=name##_str;\
engine_decorators_.push_back(name##_str);\
}
DECOR_STORER(BD,0)
DECOR_STORER(GDMA,0)
DECOR_STORER(HAU,0)
DECOR_STORER(SDMA,0)
for(inti=0;i{
DECOR_STORER(CDMA,i)
}
#undefDECOR_STORER
}
每個具體的EngineStorer,注意其功能并非把命令存下來,他只干解析命令,比方說拿到一條320位的命令(瞎說的),EngineStorer會將其解析成長度為10的32位數(shù)組(std::vector)。
真正存命令是使用VectorDumpEngineStorerDecorator,裝飾器的作用是:執(zhí)行被裝飾類的特定函數(shù)時,進行更多的操作,具體可以《設計模式》的書。這點對于理解store_cmd非常重要,作者在設計store_cmd時,使用了很多裝飾器、為每個EngineStorer賦予了額外的功能,其中把指令儲存也看作一個裝飾器。VectorDumpEngineStorerDecorator該裝飾器執(zhí)行EngineStorer類中的store函數(shù)后,會追加執(zhí)行take_cmds函數(shù),該函數(shù)將所有指令存儲到output_中。
classVectorDumpEngineStorerDecorator:publicEngineStorerDecorator
{
private:
std::vector<uint32_t>*&output_;
voidtake_cmds()
{
autocmds=EngineStorerDecorator::get_cmds();
(*output_).insert((*output_).end(),cmds.begin(),cmds.end());
}
public:
VectorDumpEngineStorerDecorator(ComponentPtrcomponent,
std::vector<uint32_t>**output)
:EngineStorerDecorator(component),output_(*output){}
virtualvoidstore(void*cmd,CMD_ID_NODE*cur_id_node)override
{
EngineStorerDecorator::store(cmd,cur_id_node);
if(!enabled_)
return;
this->take_cmds();
}
virtualvoidstore_cmd_end(unsigneddep)override
{
EngineStorerDecorator::store_cmd_end(dep);
this->take_cmds();
}
};
store_cmd中類與暴露給編譯器接口的關系
實際上上述的各種類不能直接暴露給編譯器,因為必須傳的是c函數(shù)的函數(shù)接口,因此必須將類中各種函數(shù)封裝進c語言函數(shù)形式,以store_cmd為例,get_storer會獲得唯一的ConcretCmdStorer類
voidstore_cmd(void*cmd,intengine_id,CMD_ID_NODE*cur_id_node,intport,
intthread_id)
{
get_storer()->store_cmd(engine_id,cmd,cur_id_node,port);
}
TPU-MLIR中的重構修改
分為三部分:BM168X及派生類、BM168XCodeGen
對于BM168X派生類來說,后端工程中添加了很多新的函數(shù),這些函數(shù)主要是將存指令的數(shù)據(jù)結構放入了后端管理,涉及的后端有1684X之后架構的處理器,而1684并不適配新的函數(shù)。這意味著:
存儲指令的數(shù)據(jù)結構需要發(fā)生改變,許多數(shù)據(jù)結構已經(jīng)不需要。如下圖所示:

需要添加新的接口函數(shù),即使獲取指令的方式不同,但是在Codegen過程看到的應該是一樣的行為。

這里傳入的參數(shù)是const char*是為了簡化參數(shù)定義,可以用特定格式字符串來指定后端engine。如gdma1,這里gdma表示GDMA Engine, 0表示第0個GDMA Engine(一個TPU內(nèi)可能有多個相同的engine), 1表示第0號GDMA Engine的第1個線程(每個Engine可能支持多線程)。
對于BM168XCodegen,之前是需要在上面的Code結構體獲取相關的數(shù)據(jù),而修改后須使用新接口,
修改前:auto gdma_ptr = (uint8_t *)(*bm168x)->gdma_buffer.data();修改后:auto gdma_ptr = (uint8_t *)(*bm168x).get_inst_data("gdma0");
并且對于后續(xù)架構處理器的指令生成來說,目前需要存儲sdma和hau的指令,所以相關指令也需要添加入Bmodel。如下圖所示(這里主要用到了FlatBuffer操作):
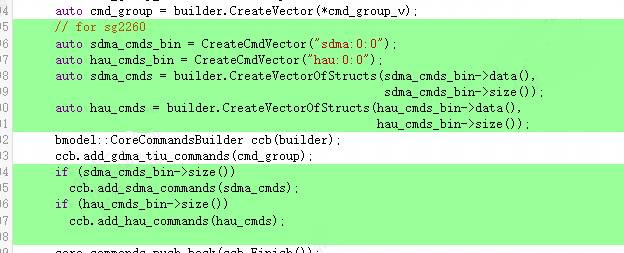
codegen_save
總結
從中可以看出,TPU-MLIR雖然能夠滿足當前TPU上的基本需求,但隨著應用場景的擴展和TPU架構的不斷演進,其需要滿足很多新的要求。這就需要開發(fā)者不斷思考和挖掘新的接口和架構,使其具有一定的擴展性和適應性。歡迎并感謝各位有識之士為TPU-MLIR多提建議,貢獻代碼!
-
代碼
+關注
關注
30文章
4886瀏覽量
70249 -
編譯器
+關注
關注
1文章
1654瀏覽量
49886 -
架構
+關注
關注
1文章
527瀏覽量
25851
發(fā)布評論請先 登錄
GPU架構深度解析

解鎖未來汽車電子技術:軟件定義車輛與區(qū)域架構深度解析
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

如何使用LAX_CODEGEN啟用動態(tài)內(nèi)存分配?
NVIDIA Blackwell數(shù)據(jù)手冊與NVIDIA Blackwell架構技術解析
?Diffusion生成式動作引擎技術解析
classB認證獲取指南中的方案架構看起來都是針對MCU的架構,MPU的沒辦法完全適配,怎么解決?

TPU編程競賽系列|第九屆集創(chuàng)賽“算能杯”火熱報名中!

光纜用tpu外護套用在哪些型號光纜上
STM32CubeMX生成的代碼,是怎樣的HAL架構?

探索設計稿自動生成Flutter代碼的技術方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論