") 什么是 NVLink?
什么是 NVLink?
NVLink 是加速系統(tǒng)中 GPU 和 CPU 處理器的高速互連技術(shù),推動(dòng)數(shù)據(jù)和計(jì)算加速得出可執(zhí)行結(jié)果。
加速計(jì)算是一項(xiàng)曾經(jīng)只有政府研究實(shí)驗(yàn)室中才有的高性能計(jì)算能力。如今,它已成為主流技術(shù)。
銀行、汽車制造商、工廠、醫(yī)院、零售商等機(jī)構(gòu)需要處理和理解的數(shù)據(jù)日益增加,他們現(xiàn)在正在采用 AI 超級(jí)計(jì)算機(jī)來處理這些堆積如山的數(shù)據(jù)。
這些強(qiáng)大、高效的系統(tǒng)如同一條條“超級(jí)計(jì)算高速公路”。它們?cè)诙鄺l并行路徑上同時(shí)傳輸數(shù)據(jù)和計(jì)算,可以瞬間得出可執(zhí)行結(jié)果。
GPU 和 CPU 處理器是“公路”沿途的資源,而快速互連通道是通往它們的“匝道”。 NVLink是加速計(jì)算互連通道的黃金標(biāo)準(zhǔn)。
那么,什么是 NVLink?
NVLink 是 GPU 和 CPU 之間的高速連接通道。它由一個(gè)強(qiáng)大的軟件協(xié)議組成,通常通過印在計(jì)算機(jī)板上的多對(duì)導(dǎo)線實(shí)現(xiàn),可以讓處理器以閃電般的速度收發(fā)共享內(nèi)存池中的數(shù)據(jù)。
如今,第四代 NVLink 連接主機(jī)和加速處理器的速度高達(dá)每秒 900GB/s。
這是傳統(tǒng) x86 服務(wù)器的互連通道——PCIe 5.0 帶寬的 7 倍多。由于每傳輸 1 字節(jié)數(shù)據(jù)僅消耗 1.3 皮焦,因此 NVLink 的能效是 PCIe 5.0 的 5 倍。
NVLink 的歷史
NVLink 最初作為 NVIDIA P100 GPU 的互連通道推出,之后便與每一代新的 NVIDIA GPU 架構(gòu)同步發(fā)展。

2018 年,NVLink 首次亮相便被用于連接兩臺(tái)超級(jí)計(jì)算機(jī)——Summit和Sierra的GPU和CPU,成為了高性能計(jì)算領(lǐng)域的焦點(diǎn)。
這兩套安裝在美國(guó)橡樹嶺國(guó)家實(shí)驗(yàn)室和美國(guó)勞倫斯利弗莫爾國(guó)家實(shí)驗(yàn)室的系統(tǒng)正在推動(dòng)藥物研發(fā)、自然災(zāi)害預(yù)測(cè)等科學(xué)領(lǐng)域的發(fā)展。
帶寬翻倍,繼續(xù)發(fā)展
2020年,第三代NVLink將每個(gè)GPU的最大帶寬翻倍提高至600GB/s,每個(gè)NVIDIA A100 Tensor Core GPU中都有十幾條互連通道。
A100 為全球各地企業(yè)數(shù)據(jù)中心、云計(jì)算服務(wù)和 HPC 實(shí)驗(yàn)室的 AI 超級(jí)計(jì)算機(jī)提供動(dòng)力。
如今,一個(gè)NVIDIA H100 Tensor Core GPU中包含18條第四代NVLink互連通道。這項(xiàng)技術(shù)已承擔(dān)了一項(xiàng)新的戰(zhàn)略任務(wù)——幫助打造全球領(lǐng)先的CPU和加速器。
芯片到芯片互聯(lián)
NVIDIA NVLink-C2C 是一種板級(jí)互連技術(shù),它能夠在單個(gè)封裝中將兩個(gè)處理器連接成一塊超級(jí)芯片。比如它通過連接兩塊 CPU 芯片,使NVIDIA Grace CPU超級(jí)芯片具有144個(gè)Arm Neoverse V2核心,為云、企業(yè)和HPC用戶帶來了高能效性能。
NVIDIA NVLink-C2C 還將 Grace CPU 和 Hopper GPU 連接成 Grace Hopper超級(jí)芯片,將用于處理最棘手的 HPC 和 AI 工作的加速計(jì)算能力集合到一塊芯片中。
計(jì)劃在瑞士國(guó)家計(jì)算中心投入使用的 AI 超級(jí)計(jì)算機(jī) Alps將是首批使用 Grace Hopper 的計(jì)算機(jī)之一。這套高性能系統(tǒng)將在今年晚些時(shí)候上線,用于處理從天體物理學(xué)到量子化學(xué)等領(lǐng)域的大型科學(xué)問題。
Grace CPU 包含 144 個(gè) Arm Neoverse V2 核心,通過 NVLink-C2C 互連。
Grace 和 Grace Hopper 還非常適合用于提升高要求云計(jì)算工作負(fù)載的能效。
例如Grace Hopper是最適合用于推薦系統(tǒng)的處理器。這些互聯(lián)網(wǎng)的經(jīng)濟(jì)引擎需要快速、高效地訪問大量數(shù)據(jù),才能每天向數(shù)十億用戶提供數(shù)萬億條結(jié)果。
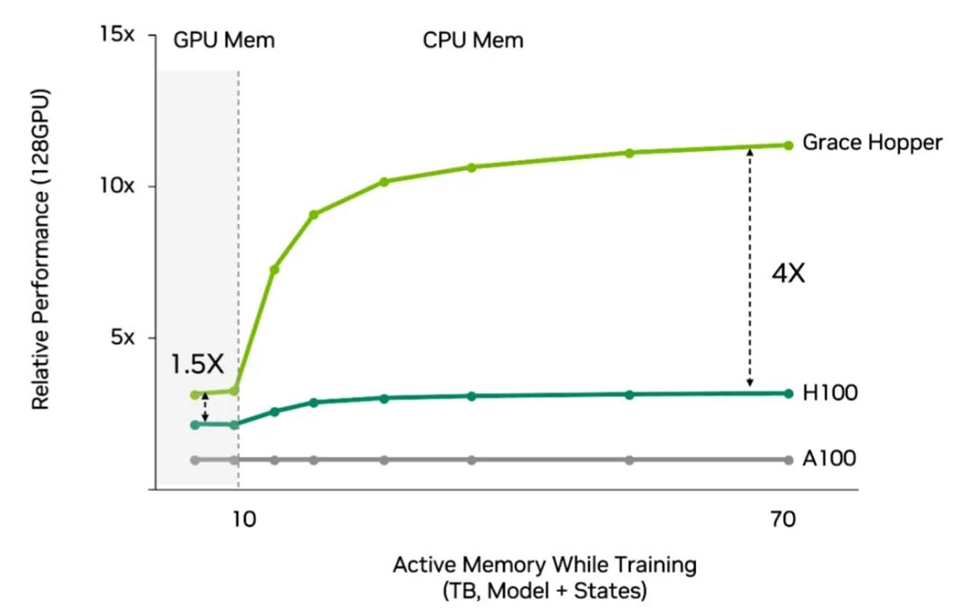
與使用傳統(tǒng) CPU 的 Hopper 相比,采用 Grace Hopper 的推薦系統(tǒng)的性能提高了 4 倍,并且效率更高。
另外,NVLink 還被用于為汽車制造商提供的強(qiáng)大系統(tǒng)級(jí)芯片,包括 NVIDIA Hopper、Grace 和 Ada Lovelace 處理器等。車載計(jì)算平臺(tái) NVIDIA DRIVE Thor 將數(shù)字儀表板、車載信息娛樂、自動(dòng)駕駛、泊車等諸多智能功能統(tǒng)一整合到單個(gè)架構(gòu)中。
“樂高式”計(jì)算鏈路
NVLink 的作用就像是樂高積木的凸粒和凹槽。它是構(gòu)建超級(jí)系統(tǒng)以處理超大型 HPC 和 AI 工作的基礎(chǔ)。
例如,NVIDIA DGX 系統(tǒng)中的八個(gè) GPU 上的 NVLink 通過 NVSwitch 芯片共享快速、直接的連接。它們共同組成了一個(gè) NVLink 網(wǎng)絡(luò),使服務(wù)器中的每一個(gè) GPU 都是一套系統(tǒng)的一部分。
為了獲得更強(qiáng)大的性能,DGX 系統(tǒng)本身可以堆疊成由 32 臺(tái)服務(wù)器組成的模塊化單元,形成一個(gè)強(qiáng)大、高效的計(jì)算集群。
NVLink 是一項(xiàng)關(guān)鍵的技術(shù),它可以讓用戶輕松地將模塊化的 NVIDIA DGX 系統(tǒng)擴(kuò)展成為一個(gè) AI 性能高達(dá) 1 EXAFLOP 的 SuperPOD。
用戶可以利用DGX內(nèi)部的NVLink網(wǎng)絡(luò)與兩者之間的NVIDIA Quantum-2 InfiniBand交換以太網(wǎng),將32個(gè)DGX系統(tǒng)模塊連接成一臺(tái)AI超級(jí)計(jì)算機(jī)。例如,一臺(tái)NVIDIA DGX H100 SuperPOD包含256個(gè)H100 GPU,可提供最高1 EXAFLOP的峰值A(chǔ)I性能。
如要進(jìn)一步提高性能,用戶還可以使用云中的 AI 超級(jí)計(jì)算機(jī),例如微軟Azure使用數(shù)萬個(gè) A100 和 H100 GPU 打造的超級(jí)計(jì)算機(jī)。
審核編輯 黃宇
-
芯片
+關(guān)注
關(guān)注
459文章
52169瀏覽量
436093 -
cpu
+關(guān)注
關(guān)注
68文章
11033瀏覽量
215980 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5240瀏覽量
105768 -
gpu
+關(guān)注
關(guān)注
28文章
4910瀏覽量
130651
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA NVLink 深度解析
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
特斯拉V100 Nvlink是否支持v100卡的nvlink變種的GPU直通?
英偉達(dá)GPU卡多卡互聯(lián)NVLink,系統(tǒng)累積的公差,是怎么解決的?是連接器吸收的?
技嘉發(fā)布的NVLink連接器支持RGB燈光
技嘉發(fā)布全新NVLink連接器:擁有RGB燈光
RTX 3080 PCB上沒有NVLink連接器
GTC2022大會(huì)亮點(diǎn):NVIDIA宣布推出NVIDIA NVLink Switch系統(tǒng)

什么是 NVLink?

一文解析Nvlink的誕生和技術(shù)演進(jìn)歷程
NVLink的演進(jìn)
NVLink的演進(jìn):從內(nèi)部互聯(lián)到超級(jí)網(wǎng)絡(luò)

全面解讀英偉達(dá)NVLink技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論