") 河套IT TALK94:(原創(chuàng))GPT技術(shù)揭秘:探索生成式模型的訓(xùn)練之道
河套IT TALK94:(原創(chuàng))GPT技術(shù)揭秘:探索生成式模型的訓(xùn)練之道
1. 引言
人工智能和機器學(xué)習(xí),都是由場景和需求驅(qū)動的。找不到運用場景的機器學(xué)習(xí)技術(shù),也沒有生命力。越有挑戰(zhàn)性的場景,越能激發(fā)人們用機器學(xué)習(xí)尋找解決方案的激情和動力。人們總是在問題中尋找解決方案,砥礪前行。
最近在嘗試梳理機器學(xué)習(xí)的相關(guān)內(nèi)容,發(fā)現(xiàn)知識量巨大,信息龐雜,需要梳理一個主線,才能更好理解相關(guān)概念。所以很多研究機器學(xué)習(xí)的技術(shù),都是順著如下的脈絡(luò)來展開的:
1. 我們準(zhǔn)備解決什么問題?
2. 我們準(zhǔn)備按照什么方式進行訓(xùn)練學(xué)習(xí)?
3. 我們準(zhǔn)備選定什么樣的模型來應(yīng)對?
4. 針對模型,我們應(yīng)該采取什么樣特定架構(gòu)或網(wǎng)絡(luò)?
5. 針對這個模型和網(wǎng)絡(luò),我們將采用什么樣的算法?
6. 這個算法有什么優(yōu)勢和劣勢?
這幾個維度的問題解答,相信能涵蓋絕大多數(shù)人對機器學(xué)習(xí)某些特定場景的技術(shù)和知識領(lǐng)域的理解。近期看了很多關(guān)于機器學(xué)習(xí)、自然語言處理以及GPT相關(guān)技術(shù)的文章,有一些心得體會,今天準(zhǔn)備按照上述問題的脈絡(luò),分享給大家,希望能有所幫助。
2. 自然語言處理NLP(Natural Language Processing)
人類,作為智能生物,交流是離不開自然語言的。如何讓機器理解人的語言,并能正常和人類進行語言互動,就成為迫切需要解決的重要問題。不管是文字類,還是語音類,都會存在所謂的語義分析理解、情感分析、機器翻譯問題。從自然語言處理的過程來看,不免要經(jīng)歷:分詞和詞性標(biāo)注、詞法分析、句法分析、實體識別、語義角色標(biāo)注、句法語義分析、情感分析、語法歸納和機器翻譯等等。人類差不多有7000種活躍的語言,其中有文字支撐的,特別是在很多消費電子產(chǎn)品里能正常切換使用的,不過百種。不過這也足夠給自然語言處理帶來巨大的挑戰(zhàn)。不同文化背景,可能意味著完全不同的詞語分割、模糊和引發(fā)歧義的語義、或嚴(yán)格或?qū)捤傻恼Z法靈活性,以及俗語、諺語等等,甚至?xí)砍兜礁鞣N圖形學(xué)和圖像識別的技術(shù)。
3. 大模型(Large language model)
既然是自然語言處理,就一定離不開語言模型。我們現(xiàn)在聽的很多的所謂大模型,就是大型語言模型的簡稱,英文是LLM,也就是 Large language model的縮寫。大模型也沒有什么神秘的,無非就是“大”。目前對于這個多“大”才算是大模型,還沒有一個官方權(quán)威的界定。但經(jīng)驗上來講,大模型通常指的是至少具有數(shù)百萬參數(shù)的深度學(xué)習(xí)模型。而類似GPT-4的參數(shù)已經(jīng)達(dá)到了170萬億的量級。上圖是近年來已有的大模型LLM(大于100億參數(shù))的時間線。黃色標(biāo)記此大模型已經(jīng)開源。
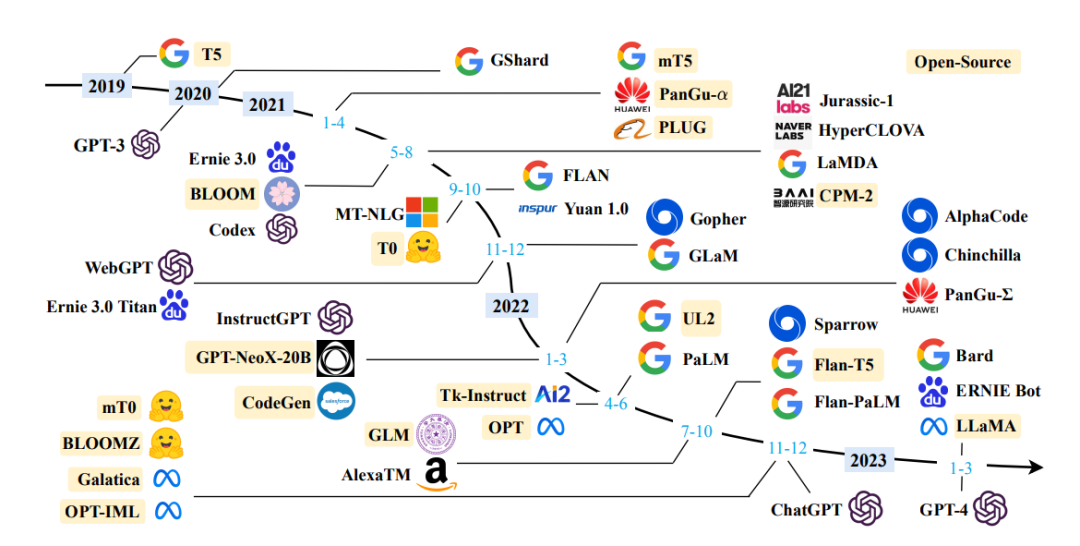
大模型一般是通用模型,在廣泛任務(wù)中表現(xiàn)出色,而且通常大模型已經(jīng)在大型語料庫上進行了“預(yù)訓(xùn)練”。
只要是語言模型,不管是大還是小,其實都是一個基于統(tǒng)計學(xué)的模型。不管人們怎么去包裝,把這個說成是“推理”,但目前的技術(shù)就是建立在概率基礎(chǔ)上的。無非就是根據(jù)給定的輸入文本,預(yù)測下一個可能的單詞或字符序列。通過分析大量的文本數(shù)據(jù),學(xué)習(xí)詞匯的出現(xiàn)概率和上下文之間的關(guān)系,從而能夠生成連貫的文本或評估給定文本的合理性。
4. 大模型的最小單元Token
語言模型最基礎(chǔ)的模型是詞袋模型(Bag-of-Words Model)。作為一種簡化的文本表示方法,將文本看作是一個袋子(或集合)中的詞語的無序集合,忽略了詞語的順序和語法結(jié)構(gòu)。在詞袋模型中,每個文檔或句子被表示為一個向量,向量的每個維度對應(yīng)一個詞語,維度的值表示該詞語在文檔中出現(xiàn)的次數(shù)或其他統(tǒng)計信息。詞袋模型假設(shè)詞語的出現(xiàn)是獨立的,只關(guān)注詞語的頻率和出現(xiàn)情況,忽略了詞語之間的順序和上下文信息。這種模型簡化了文本的表示和處理,常用于文本分類、信息檢索等任務(wù)。但是對于自然語言生成就無能為力了。在此基礎(chǔ)上將連續(xù)的文本流切分成有意義的單元,以便于模型對其進行處理和理解,這就是Token化(Tokenization)。"token"是指文本中的最小單位或基本元素。它可以是一個單詞、一個字、一個字符或其他語言單位,根據(jù)任務(wù)和需求而定。下圖就是GPT-3的標(biāo)記化(Tokenization)示例:

在大模型中,token 的選擇和處理方式往往是根據(jù)具體任務(wù)和訓(xùn)練數(shù)據(jù)來確定的。在訓(xùn)練一個通用模型時,可以使用更粗粒度的 tokenization 方法,如將單詞作為 token。而在某些特定任務(wù),如命名實體識別(Named Entity Recognition)或語言翻譯(Machine Translation)中,可能需要更細(xì)粒度的 tokenization,以便更好地捕捉特定領(lǐng)域或語言的信息。
不同語言的Token也會有很大差別。拿英文和漢語為例,在英語中,通常將單詞作為 token,而在漢語中,單個漢字級別的 tokenization 更為常見。漢語中的詞匯通常沒有復(fù)數(shù)形式、時態(tài)變化或進行時等形態(tài)變化,因此,對于一些任務(wù),如詞性標(biāo)注或命名實體識別,將單個詞作為 token 可能更加合適。而在英語中,單詞的不同形式(如單數(shù)和復(fù)數(shù)、時態(tài)等)可能被視為不同的 token。漢語中的合成詞較為常見,可以通過將多個單字組合而成。因此,在處理漢語時,可能需要將合成詞進行拆分,將其組成部分作為單獨的 token 進行處理。而在英語中,合成詞的形式較少,單詞本身就可以作為一個獨立的 token。在英語中,單詞之間由空格或標(biāo)點符號分隔,因此可以相對容易地進行單詞級別的 tokenization。而在漢語中,字詞之間沒有明確的分隔符,需要進行中文分詞來將連續(xù)的漢字序列劃分為有意義的詞匯。所以在漢字處理上,比英文多了分詞這個步驟。
5. 無監(jiān)督學(xué)習(xí)(Unsupervised learning)
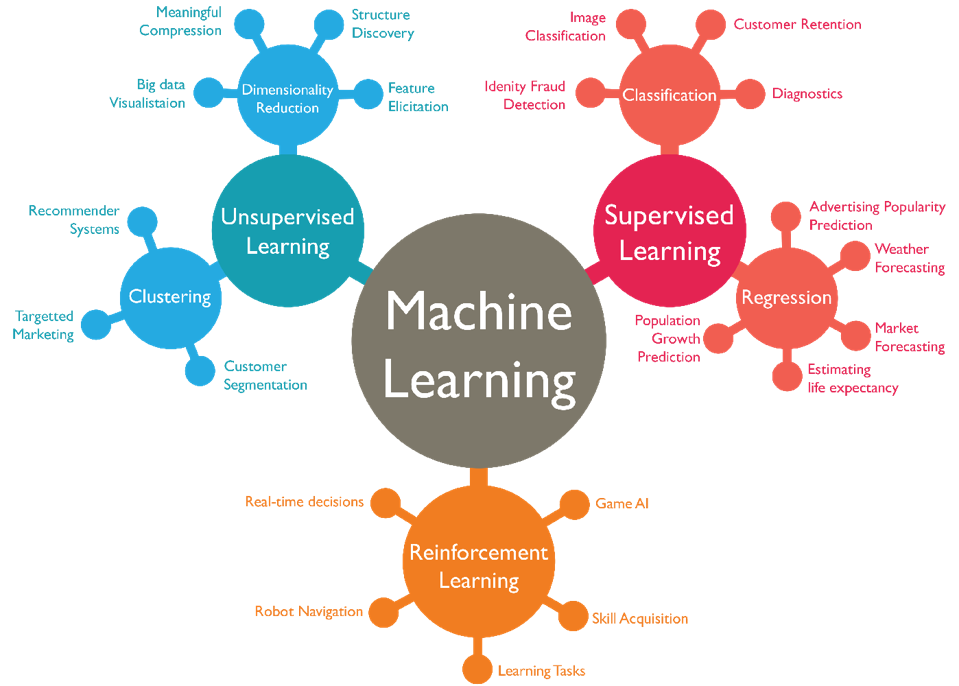
有了模型,我們接下來思考的就是,應(yīng)該用什么方式進行訓(xùn)練?語言模型帶有很強的內(nèi)容生成屬性和靈活性,也就是不存在唯一解。這種模型,就絕對不能采用老是想著最優(yōu)策略的強化學(xué)習(xí)方式。而且,訓(xùn)練這種語言模型,也不適合用通過使用標(biāo)記的訓(xùn)練數(shù)據(jù)來學(xué)習(xí)從輸入到輸出的映射關(guān)系的監(jiān)督學(xué)習(xí)(Supervised learning),因為人類語言信息量太大,標(biāo)記不過來。而最理想的方式就是從未標(biāo)記的數(shù)據(jù)中學(xué)習(xí)數(shù)據(jù)的隱藏結(jié)構(gòu)、模式或分布的無監(jiān)督學(xué)習(xí)(Unsupervised learning)。當(dāng)然,也不排除所謂的同時利用有標(biāo)簽和無標(biāo)簽的數(shù)據(jù)來進行學(xué)習(xí)的半監(jiān)督學(xué)習(xí)(Semi-supervised learning),或者從無監(jiān)督任務(wù)中自動生成標(biāo)簽來進行學(xué)習(xí)。通過設(shè)計任務(wù)或目標(biāo)函數(shù),利用數(shù)據(jù)樣本中的已知信息進行預(yù)測或重構(gòu)的自我監(jiān)督學(xué)習(xí)(Self-supervised learning)。
既然是無監(jiān)督學(xué)習(xí)為主,那么應(yīng)該采用什么樣的網(wǎng)絡(luò)架構(gòu)來學(xué)習(xí)合適呢?
6. 反饋神經(jīng)網(wǎng)絡(luò)(Feedback Neural Networks)
當(dāng)然是神經(jīng)網(wǎng)絡(luò)。最早人們想到的用于語言模型處理的神經(jīng)網(wǎng)絡(luò)是反饋神經(jīng)網(wǎng)絡(luò)(Feedback Neural Networks)。存在反饋連接,信息可以從后續(xù)時間步驟傳遞回前面的時間步驟。可以對動態(tài)系統(tǒng)的行為進行建模和預(yù)測,如控制系統(tǒng)、運動軌跡預(yù)測等。我們必須承認(rèn),在處理時序任務(wù)方面反饋神經(jīng)網(wǎng)絡(luò)著實表現(xiàn)出色,如語音識別、自然語言處理中的語言模型、機器翻譯等。
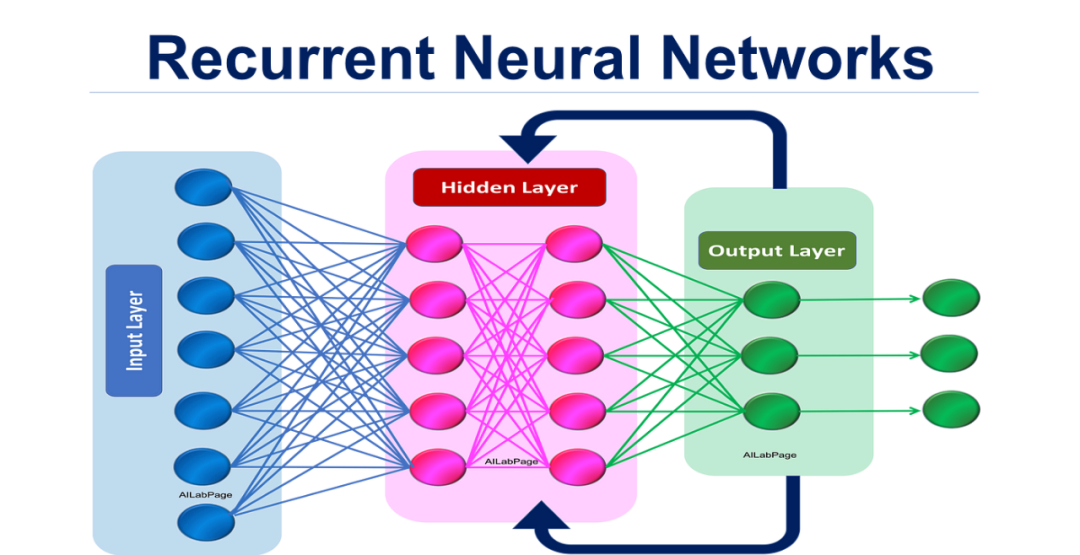
大家一般會想到的反饋神經(jīng)網(wǎng)絡(luò)就是循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks,RNN),是一類具有循環(huán)連接的神經(jīng)網(wǎng)絡(luò),能夠保留先前狀態(tài)的信息,主要由循環(huán)層和激活函數(shù)組成。作為一種遞歸的神經(jīng)網(wǎng)絡(luò),適用于處理序列數(shù)據(jù)的任務(wù),如自然語言處理、語音識別、時間序列分析等。如果用于處理文本,它的核心思想是在處理每個輸入時,將前一個時刻的隱藏狀態(tài)傳遞給當(dāng)前時刻,并結(jié)合當(dāng)前輸入進行計算。這種遞歸的結(jié)構(gòu)使得RNN能夠捕捉到序列中的上下文信息。
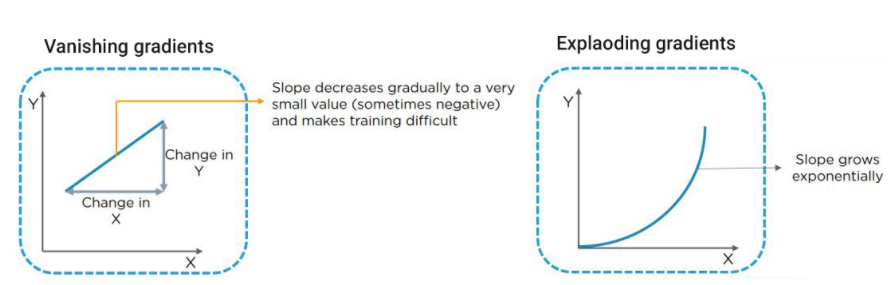
然而,傳統(tǒng)的RNN在處理長序列時會面臨梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)的問題。梯度消失指的是在深層神經(jīng)網(wǎng)絡(luò)中,反向傳播過程中梯度逐漸變小,并最終變得非常接近于零的現(xiàn)象。當(dāng)網(wǎng)絡(luò)層數(shù)較多時,梯度在每一層中都會乘以網(wǎng)絡(luò)參數(shù)的權(quán)重,因此,如果權(quán)重小于1,則梯度會指數(shù)級地逐漸減小,導(dǎo)致在淺層網(wǎng)絡(luò)中梯度無法有效傳遞到較深的層,從而使得較深層的參數(shù)更新緩慢或停止更新,影響網(wǎng)絡(luò)的訓(xùn)練效果。梯度爆炸指的是在深層神經(jīng)網(wǎng)絡(luò)中,反向傳播過程中梯度逐漸增大,并最終變得非常大的現(xiàn)象。當(dāng)網(wǎng)絡(luò)層數(shù)較多時,梯度在每一層中都會乘以網(wǎng)絡(luò)參數(shù)的權(quán)重,如果權(quán)重大于1,則梯度會指數(shù)級地逐漸增大,導(dǎo)致在淺層網(wǎng)絡(luò)中梯度變得非常大,進而導(dǎo)致網(wǎng)絡(luò)參數(shù)更新過大,使得網(wǎng)絡(luò)無法收斂。不管是梯度消失,還是梯度爆炸問題,都會導(dǎo)致深層神經(jīng)網(wǎng)絡(luò)的訓(xùn)練變得困難,甚至無法收斂到有效的結(jié)果。
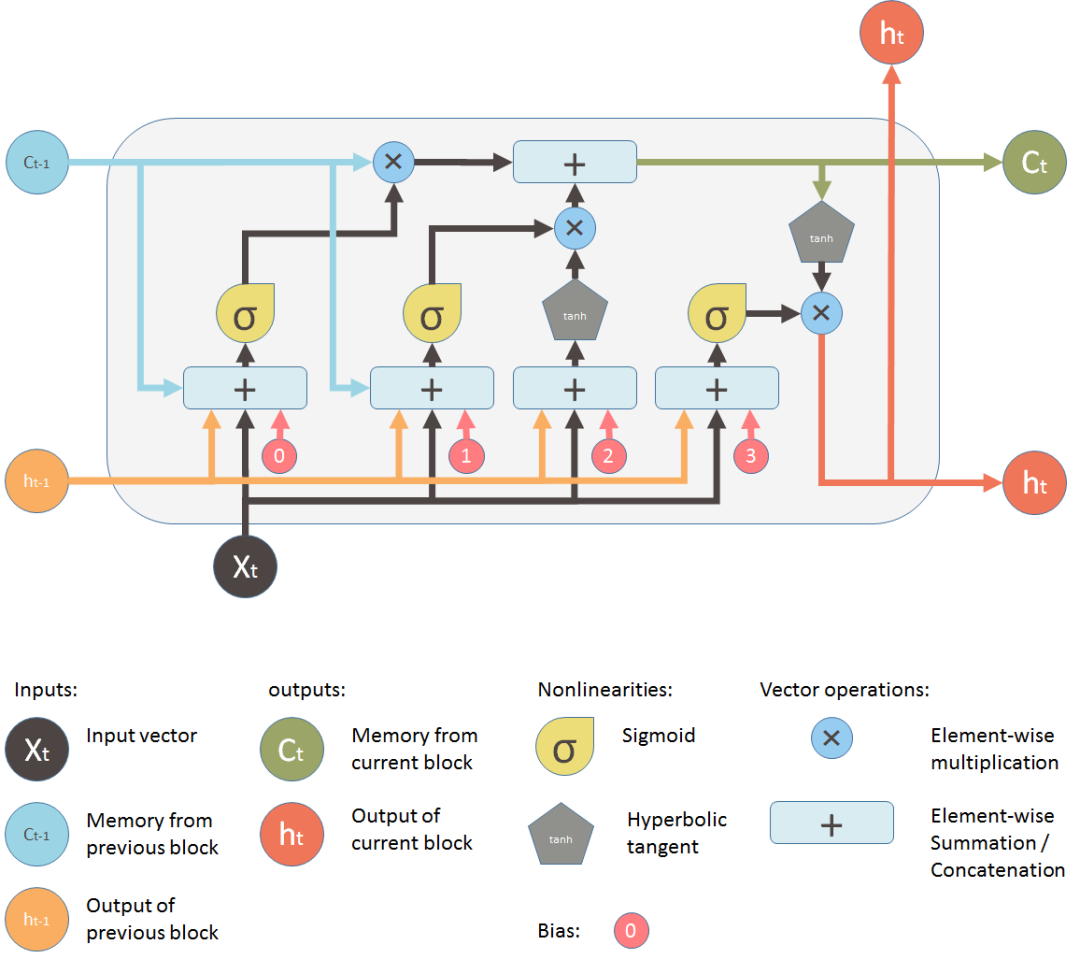
于是人們又改進了循環(huán)神經(jīng)網(wǎng)絡(luò),設(shè)計了一個變體長短期記憶網(wǎng)絡(luò)(Long Short-Term Memory,LSTM),用于解決傳統(tǒng)RNN在處理長期依賴問題上的挑戰(zhàn)。LSTM通過引入門控單元結(jié)構(gòu),可以更有效地處理和記憶長期依賴關(guān)系。LSTM通過引入門控機制來解決梯度消失和梯度爆炸的問題。LSTM單元包含遺忘門(forget gate)、輸入門(input gate)和輸出門(output gate)。LSTM通過這些門的控制,可以有選擇性地遺忘和更新信息,能夠更好地捕捉長期依賴關(guān)系,有助于控制信息的流動和記憶的更新,從而解決了梯度消失和梯度爆炸的問題。
7. Transformer轉(zhuǎn)換器
上述的LSTM看似完美,其實也有硬傷。傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)或長短期記憶網(wǎng)絡(luò)(LSTM)都屬于反饋神經(jīng)網(wǎng)絡(luò)(Feedback Neural Networks),在處理序列數(shù)據(jù)時是逐步進行的,每個時間步依賴于前一個時間步的計算結(jié)果。這種順序計算導(dǎo)致了計算的串行性,無法同時進行多個計算。而且這種局部信息交互的方式可能無法充分利用整個序列中的上下文信息。盡管LSTM緩解了梯度消失或梯度爆炸的問題,但仍然存在一定的限制。
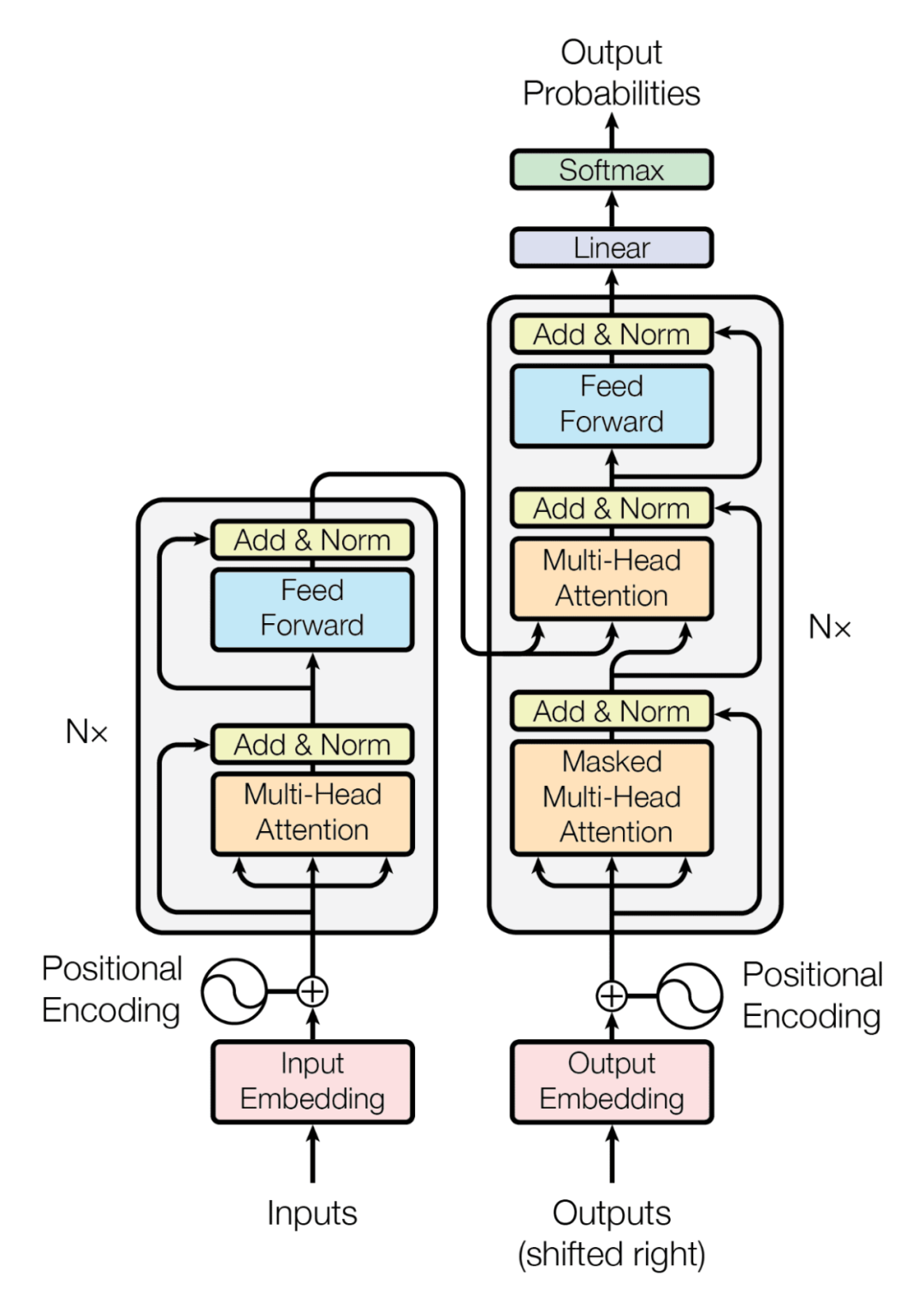
而新的技術(shù)Transformer又打破了僵局。Transformer是前饋神經(jīng)網(wǎng)絡(luò)(Feedforward Neural Networks)。前饋神經(jīng)網(wǎng)絡(luò)中,信息只沿著前向的方向傳遞,沒有循環(huán)連接。適用于各種監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)任務(wù),如分類、回歸、特征提取等。Transformer作為一種基于自注意力機制的模型,用于處理序列數(shù)據(jù),能夠在每個位置對輸入序列的所有位置進行注意力計算。這使得模型能夠根據(jù)輸入序列的不同部分自適應(yīng)地分配注意力權(quán)重,能夠在一個序列中捕捉到不同位置之間的依賴關(guān)系,更加靈活地捕捉關(guān)鍵信息。由于Transformer是基于注意力機制的前饋神經(jīng)網(wǎng)絡(luò),可以在一次前向傳播中同時處理整個序列,因此可以進行更有效的并行計算。這使得Transformer摒棄了傳統(tǒng)的遞歸結(jié)構(gòu),而是采用了并行計算的方式,在處理長序列時更為高效。Transformer由編碼器和解碼器組成,編碼器負(fù)責(zé)將輸入序列編碼成一系列特征表示,解碼器則根據(jù)這些特征表示生成目標(biāo)序列,Transformer通過注意力機制使每個位置都能夠在編碼和解碼階段獲得序列中所有位置的信息,實現(xiàn)了全局的信息交互,能夠更好地捕捉上下文關(guān)系。使得它可以廣泛應(yīng)用于機器翻譯和生成式任務(wù)中。
8. 生成式與訓(xùn)練轉(zhuǎn)換器GPT(Generative Pre-trained Transformer)
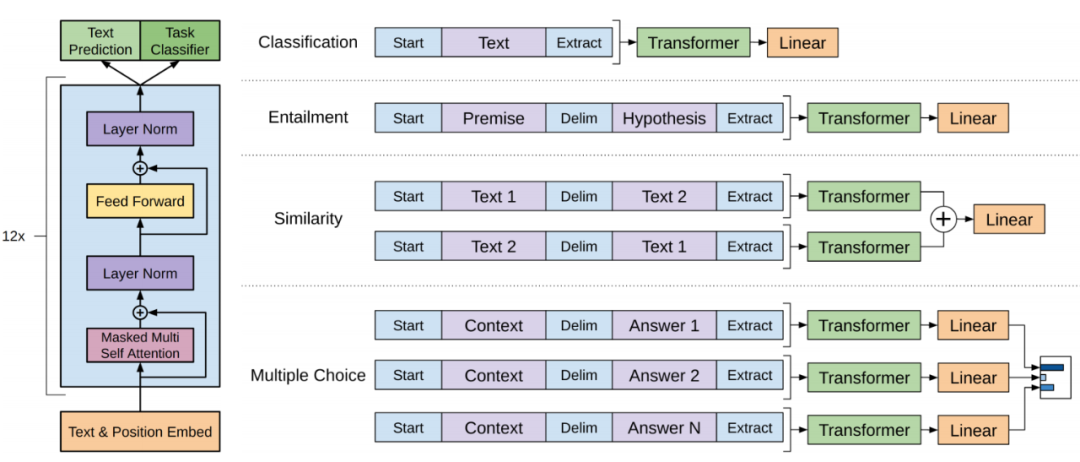
而大家熟知的GPT正是使用了最后這個Transformer技術(shù)。其實這也是GPT名字的由來。GPT是生成式與訓(xùn)練轉(zhuǎn)換器(Generative Pre-trained Transformer)的縮寫。GPT通過對提出的問題進行預(yù)測(Generate)來生成一篇回答。GPT不是在一次預(yù)測中輸出整篇回答,而是首先預(yù)測回答的第一個字,然后將預(yù)測的第一個字與問題連接起來,形成一個延長一個字的輸入句子,并再次輸入給GPT。GPT進行第二次預(yù)測,得到回答的第二個字,然后將這個字續(xù)在輸入句子后,再次輸入給GPT,以此類推。這個過程一直重復(fù)進行,直到GPT預(yù)測出"結(jié)束符"(或達(dá)到約定的最大長度,此時回答過程結(jié)束,GPT生成了一篇完整的回答。這種逐步地一個字一個字生成整篇回答的過程被稱為"自回歸"—— Auto-Regression。在自回歸過程中,GPT進行多次預(yù)測而不僅僅是一次預(yù)測。因此,使用過ChatGPT的用戶可能會發(fā)現(xiàn)它在回答問題時逐字逐字地產(chǎn)生輸出,速度較慢。這是因為大型的GPT模型進行一次預(yù)測(輸出一個字)本身就需要一定的時間。
9. 轉(zhuǎn)換器(Transformer)與注意力(Attention)
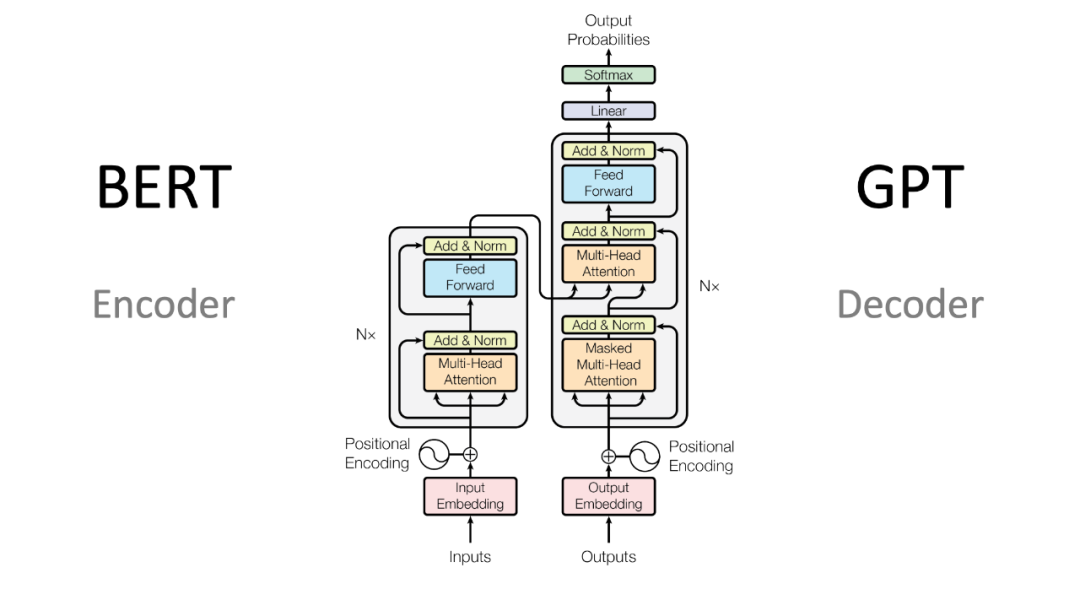
從內(nèi)部實現(xiàn)細(xì)節(jié)來看,輸入句子首先通過一系列堆疊在一起的Transformer組件。下一層Transformer的輸出作為上一層Transformer的輸入。GPT看到的"字"是數(shù)值化的表示,即一組向量。整個語言中有V個字(字表)。GPT為每個字分配一個向量,這些向量也是GPT的參數(shù)。輸入句子中的每個字向量被傳遞給第一個Transformer,它對每個字生成一個向量。可以將這個過程看作是Transformer對每個字向量進行了"變形"。下一層Transformer將其輸出的字向量傳遞給上一層Transformer,直到最頂層的Transformer為句子中的每個字生成一個向量。通過多層Transformer的處理,字向量在傳遞過程中發(fā)生了變化,這些變化可以視為Transformer對字向量進行了"變形"。更重要的是,在這個變形的過程中,每個字的向量融合了上下文中所有字的信息。這就是Transformer中的Attention(注意力)組件的作用。Attention首先利用每個字的向量計算出query向量、key向量和value向量。query向量和key向量指示了這個字與其他字(包括自身)如何相關(guān)聯(lián),而value向量則包含了字本身的含義信息。Attention使用query向量和所有字的key向量計算出對應(yīng)的注意力得分,這個得分表示這個字在多大程度上將注意力分配給其他字。然后,Attention使用這些注意力得分對所有字的value向量進行加權(quán)求和,得到對于該字的輸出向量。可以認(rèn)為,Attention改變了該字的向量,使得變化后的向量通過不同的注意力權(quán)重融合了上下文中所有字的信息。
GPT的全部參數(shù)包括:
-
N個Transformer中組合多個Attention頭的輸出矩陣,以及全連接神經(jīng)網(wǎng)絡(luò)的參數(shù)(包括多個權(quán)重矩陣和偏置向量);
-
每個Transformer中H個Attention頭的Q、K和V矩陣;
-
預(yù)測下一個字的全連接神經(jīng)網(wǎng)絡(luò)的參數(shù)(包括多個權(quán)重矩陣和偏置向量);
-
初始的字向量。
正是這些參數(shù)使得GPT模型具有我們希望它具備的行為。例如,一個Attention頭的Q、K和V矩陣,其中V矩陣對輸入給Attention的字向量進行線性變換,得到該字的value向量,這種線性變換在某種程度上表達(dá)了該字某個方面的含義(抽象)。Q和K矩陣分別對字向量進行線性變換,得到該字的query和key向量,也編碼了該字與其他字相關(guān)聯(lián)的信息。再例如,位于Transformer之上的預(yù)測神經(jīng)網(wǎng)絡(luò),其參數(shù)編碼了如何根據(jù)句子的表示(即最后一個字的向量)來預(yù)測下一個字的信息。
10. GPT是如何訓(xùn)練出來的?
所有這些參數(shù)都是通過“訓(xùn)練”得到的。一開始,這些參數(shù)被初始化為隨機值,此時它們沒有任何含義和功能,GPT也無法很好地預(yù)測下一個字。訓(xùn)練者準(zhǔn)備了一個龐大的語料庫,其中包含許多合法的句子。從合法句子中隨機選擇一部分作為訓(xùn)練樣本,以最后一個字作為標(biāo)簽,將前面的字作為輸入,從而構(gòu)造了一個訓(xùn)練樣本。許多這樣的訓(xùn)練樣本構(gòu)成了訓(xùn)練集。
將訓(xùn)練樣本的句子輸入到GPT中,GPT將預(yù)測下一個字,準(zhǔn)確地說是生成字表中所有字的概率分布。然后將正確的下一個字(標(biāo)簽)與GPT的輸出進行比較,計算出誤差(交叉熵?fù)p失)。接下來,在GPT模型上執(zhí)行反向傳播,使用梯度下降法或其變體更新GPT的所有參數(shù)。
通過逐個樣本地(實際上是一批樣本)進行這一過程的迭代,即“計算誤差+反向傳播+更新參數(shù)”,最終調(diào)整GPT的參數(shù)使誤差最小化。此時,GPT能夠很好地預(yù)測句子的下一個字,訓(xùn)練完成。
通過對GPT技術(shù)的揭秘,今天我們深入了解了生成式模型的訓(xùn)練之道。相信大家能清晰看到從自然語言處理(NLP)到生成式與訓(xùn)練轉(zhuǎn)換器(GPT)的技術(shù)發(fā)展脈絡(luò)。隨著技術(shù)的不斷進步,人們對大模型的期望也在增加。特別是如何處理不同語言和文化背景下的多樣性,克服詞語分割、語義模糊和語法靈活性等挑戰(zhàn),以實現(xiàn)全球范圍內(nèi)的語言處理能力。同時,這種大模型的能力如何擴展到多媒體,多模態(tài)領(lǐng)域以及如何在各種專業(yè)領(lǐng)域發(fā)揮更好的作用,讓人們產(chǎn)生更多的期待。
相信,通過不斷的研究和探索,AIGC大模型將在自然語言處理領(lǐng)域發(fā)揮越來越重要的作用,為人們提供更好的語言交流和理解體驗,進而推動人工智能的發(fā)展邁上新的臺階。
-
開源技術(shù)
+關(guān)注
關(guān)注
0文章
389瀏覽量
8121 -
OpenHarmony
+關(guān)注
關(guān)注
27文章
3835瀏覽量
18171
原文標(biāo)題:河套IT TALK94:(原創(chuàng))GPT技術(shù)揭秘:探索生成式模型的訓(xùn)練之道
文章出處:【微信號:開源技術(shù)服務(wù)中心,微信公眾號:共熵服務(wù)中心】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
?Diffusion生成式動作引擎技術(shù)解析
是否可以輸入隨機數(shù)據(jù)集來生成INT8訓(xùn)練后量化模型?
用PaddleNLP在4060單卡上實踐大模型預(yù)訓(xùn)練技術(shù)

OpenAI即將推出GPT-5模型
OpenAI GPT-5開發(fā)滯后:訓(xùn)練成本高昂
如何訓(xùn)練自己的LLM模型
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸

NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)

使用OpenVINO GenAI API的輕量級生成式AI
大語言模型的預(yù)訓(xùn)練
llm模型和chatGPT的區(qū)別
如何用C++創(chuàng)建簡單的生成式AI模型
生成式AI與神經(jīng)網(wǎng)絡(luò)模型的區(qū)別和聯(lián)系
OpenAI揭秘CriticGPT:GPT自進化新篇章,RLHF助力突破人類能力邊界
利用大模型服務(wù)一線小哥的探索與實踐





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論